这篇文章正式介绍下我之前用 Python 实现的分布式任务框架 Elric,包括其API,架构,周边能力以及实现细节。
读者可以先阅读之前的这篇文章《Python实现的分布式任务调度系统》来了解Elric的起源和早期设计的思想。
一. 简介
Elric 是一个 Python 实现的简单的分布式任务框架。Master-Worker 架构,Worker 向 Master 提交任务和执行 Master 下发的任务。支持多种任务类型:即时任务,周期任务,crontab 任务和定时任务。 其实现参考了 Apscheduler,Elric 的部分逻辑参考了 Apscheduler, 部分代码(trigger)取自 Apscheduler。
二. API
Master
-
初始化和启动 Master
启动 Master 很简单,样例代码如下:
1 2 3 4 5 6 7 8
import os os.environ.setdefault('ELRIC_SETTINGS_MODULE', 'settings') # 设置 settings.py from elric.master.rqextend import RQMasterExtend rq_Master = RQMasterExtend() rq_Master.start()
Worker
-
初始化和启动 Worker
Worker 的构造函数稍微复杂一些:
1
def __init__(self, name, listen_keys=None, Worker_num=2, timezone=None, logger_name='elric.Worker')
- name:Worker 的名字,不同用途的 Worker 应该取不同的名字。
- listen_keys:Worker 监听的任务队列名,类型为 list。
- Worker_num:Worker 的进程池数。
-
timezone:时区,默认为 local。
启动 Worker 将会开始从监听的任务队列里取任务来执行,初始化和启动 Worker 的样例代码如下:
1 2 3 4 5 6 7 8
import os os.environ.setdefault('ELRIC_SETTINGS_MODULE', 'settings') # 设置 settings.py from elric.worker.rqueue import RQWorker rq_Worker = RQWorker(name='test', listen_keys=['job1', 'job2']) rq_Worker.start()
上述代码初始化一个名字为 test 的 Worker,它将从 job1,job2 这两个任务队列中取下任务来执行。
-
提交任务
提交任务的接口如下:
1 2
def submit_job(self, func, job_key, args=None, kwargs=None, trigger=None, job_id=None, replace_exist=False, need_filter=False, **trigger_args)
- func:提交该任务需要执行的函数。
- job_key:该任务将提交的任务队列名。
- args:提交的函数执行所需要的位置参数。
- kwargs:提交的函数执行所需要的命名参数。
- trigger:提交任务的执行时间信息,date 为定时任务,cron 为 crontab 任务、interval 为周期任务,为空则为即时任务。
- job_id:提交任务的id,用于调试和去重。如果没有提供将自动生成一个随机id。
- need_filter:是否去重。Master 使用 (job_key,job_id) 唯一标记一个任务。如果 need_filter 为 True,submit_job 时会 Master 会检查去重模块 dupefilter 是否有(job_key,job_id)任务成功执行的记录,如果已存在则被过滤。该特性主要用于爬虫。
去重
Elric 支持任务去重,通常这个特性用于爬虫,比如爬取过的页面无需再次爬取时,可以通过设置 need_filter 为 True 来实现:
1
2
3
blog_url = 'https://masutangu.com/'
rq_worker = RQWorker(name='crawler', listen_keys=['crawl_blog', ])
rq_worker.submit_job(crawl_blog, 'crawl_blog', args=[blog_url], job_id=blog_url)
任务执行完成后,Master 的 dupefilter 模块会标记(’crawl_blog’,’https://masutangu.com/’ )任务已经执行成功。之后如果 Master 再次接收到任务,会到 dupefilter 模块查询是否有相应的记录,如果存在则直接过滤该任务,不再下发。
配置
settings.py 文件的配置信息如下:
- DISTRIBUTED_LOCK_CONFIG:Master分布式锁的相关配置。
- JOB_QUEUE_CONFIG:任务队列的相关配置。
- FILTER_CONFIG:去重的相关配置。
- JOB_STORE_CONFIG:任务存储的相关配置。
- LOGGINGF_CONFIG:日志的相关配置。
配置由环境变量设置,可以在代码中使用os.environ.setdefault('ELRIC_SETTINGS_MODULE', 'settings'),或通过命令行设置环境变量export ELRIC_SETTINGS_MODULE=settings来指定使用的settings.py,方便管理。
样例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import os
os.environ.setdefault('ELRIC_SETTINGS_MODULE', 'settings') # 设置 settings.py
from elric.worker.rqueue import RQWorker
def wapper_job():
print 'run first job'
rq_Worker.submit_job(nest_job, 'job1', args=['hi i am nested job'])
def nest_job(welcome):
print welcome
def test_job(language=None):
print 'my favorite language is {language}'.format(language=language)
def test_date_job():
print 'hello i am date job'
def test_cron_job():
print 'hello i am crontab job'
if __name__ == '__main__':
# 初始化名字为 test 的 Worker ,监听 'job1' 和 'job2' 这两个任务队列
rq_worker = RQWorker(name='test', listen_keys=['job1', 'job2'])
# 向 Master 提交任务,该任务将由 Master 在 2015-07-17 21:13:30 这个时间点通过 'job1' 任务队列下发给 Worker ,Worker 拿到后将执行 test_date_job 函数
rq_worker.submit_job(test_date_job, 'job1', trigger='date', run_date='2015-07-17 21:13:30')
# 向 Master 提交任务,该任务将每隔30秒由 Master 通过 'job1' 任务队列下发给 Worker ,Worker 拿到后将执行 wapper_job 函数
rq_worker.submit_job(wapper_job, 'job1', trigger='interval', seconds=30)
# 向 Master 提交任务,该任务为即时任务(没有提供trigger),将马上由Master 通过任务队列 'job2' 下发给 Worker ,Worker 拿到后将执行 test_job 函数
rq_worker.submit_job(test_job, 'job2', kwargs={'language': 'python'})
# 向 Master 提交任务,该任务将在每分钟的第7秒由 Master 通过 'job2' 任务队列下发给 Worker ,Worker 拿到后将执行 test_cron_job 函数
rq_worker.submit_job(test_cron_job, 'job2', trigger='cron', second=7)
# 启动 Worker,如果 'job1' 或 'job2' 有任务则拉取下来执行
rq_worker.start()
完整的demo可见https://github.com/Masutangu/Elric/tree/master/example
三. 架构
Elric 架构图如下:
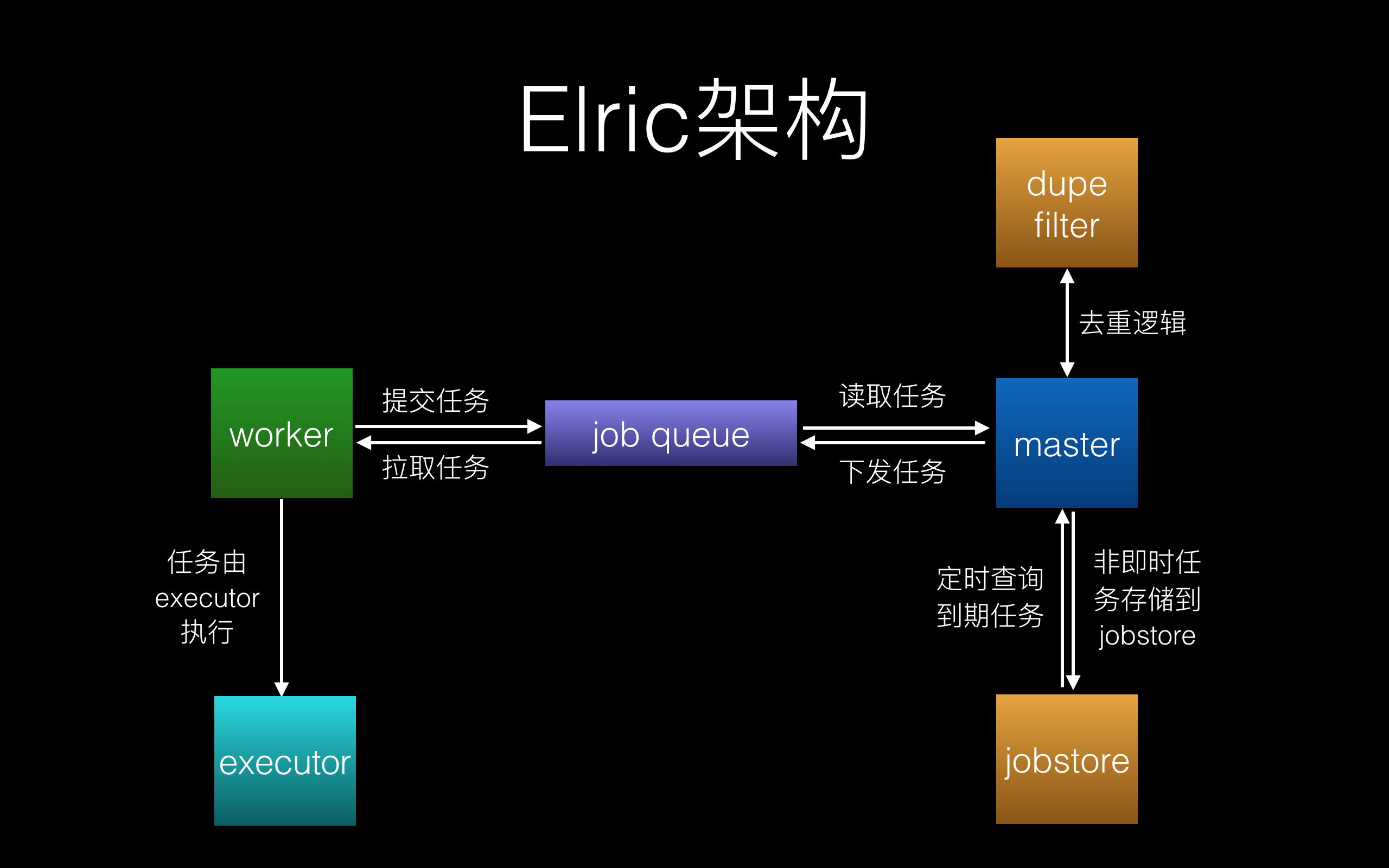
运转流程如下(包含部分实现细节):
- Worker 调用 submit_job 提交任务,该任务将存放在任务队列的 ‘elric_submit_channel’ 队列中,等待 Master 处理。同时启动 Worker,Worker 将监听其感兴趣的任务队列,比如 ‘job1’ 队列。
- Master 从任务队列 ‘elric_submit_channel’ 中拉取 Worker 提交的任务,然后做如下处理:
-
去重处理:
首先判断任务的 need_filter 是否为 True,如果为 True,则由 dupefilter 模块去重,已经执行过的将被过滤掉。为 False 则跳过该步骤。
-
非即时处理:
如果任务不是即时任务( trigger 不为空),则将该任务存储到任务存储 jobstore 中,Master 有另一线程定时扫描 jobstore 取出到期任务来下发。如果为即时任务,则跳过该步骤。
-
任务下发:
将即时任务或到期任务下发到相应的任务队列,例如放到名为 ‘job1’ 的任务队列。
-
- Worker 监听到 ‘job1’ 任务队列有新任务,取出后交给 executor 来执行。
四. 周边能力
任务的执行结果存放在 mongodb ,为了方便使用者查询和定位问题,我提供了一个简单粗糙的 web 服务:ElricStats,通过他可以方便的查询每个任务执行的时间和结果。
五. 实现细节
Master的分布式锁
为了支持多机器部署Master,在某些操作需要有锁的机制来保证原子性,比如在查询 jobstore 并取出到期任务下发时,简化代码如下:
1
2
3
4
5
6
7
8
9
for job_id, job_key, serialized_job in self.jobstore.get_due_jobs(now):
# 将任务下发到任务队列
self._enqueue_job(job_key, serialized_job)
# 获取任务的下次执行时间,并更新到 jobstore
job = Job.deserialize(serialized_job)
last_run_time = Job.get_serial_run_times(job, now)
job.next_run_time = Job.get_next_trigger_time(job, last_run_time[-1])
self.update_job(job)
如果在这个操作没有加锁保证原子性,将有可能下发重复的任务。这里我采用了redis实现的分布式锁来解决这个问题。其原理利用了 redis 的 setnx 命令,详细可以查看这篇文章《Distributed locks with Redis》。
我把分布式锁封装成 Context Managers 的形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class distributed_lock(object):
def __init__(self, **config):
self.config = config
self.dlm = redlock.Redlock([config['server'], ],
retry_count=config['retry_count'],
retry_delay=config['retry_delay'])
self.dlm_lock = None
def __enter__(self):
while not self.dlm_lock:
self.dlm_lock = self.dlm.lock(self.config['resource'], 1000)
if self.dlm_lock:
break
else:
time.sleep(self.config['retry_delay'])
def __exit__(self, type, value, traceback):
self.dlm.unlock(self.dlm_lock)
self.dlm_lock = None
这样就可以使用 with statement 来管理:
1
2
3
4
5
6
7
8
9
10
with distributed_lock(**DISTRIBUTED_LOCK_CONFIG):
for job_id, job_key, serialized_job in self.jobstore.get_due_jobs(now):
# 将任务下发到任务队列
self._enqueue_job(job_key, serialized_job)
# 获取任务的下次执行时间,并更新到 jobstore
job = Job.deserialize(serialized_job)
last_run_time = Job.get_serial_run_times(job, now)
job.next_run_time = Job.get_next_trigger_time(job, last_run_time[-1])
self.update_job(job)
六. 后续优化
Elric 目前来说还比较粗糙,后续有时间我希望对下面这几个方面做些优化:
- 配置规范化:目前我的配置文件 settings.py (包括logging模块)的实现并不规范,后续希望参考 Django 的做法来实现配置管理。
- 防雪崩机制优化:目前防雪崩机制比较简单,在任务队列满的时候 Master 会缓存一部分任务。后期改造成在下发的任务里带上任务的下发时间,Worker 取到任务后如果发现任务已经过期一段时间则直接抛弃。