本系列文章为阅读《现代操作系统》《UNIX 环境高级编程》和《Linux 内核设计与实现》所整理的读书笔记,源代码取自 Linux-kernel 2.6.34 版本并有做简化。
概念
进程即处于运行中的程序,除了程序的代码外,还包括打开的文件、挂起的信号、进程状态、内存地址空间以及用以存储全局变量的数据段等。
执行线程,简称线程,是在进程中活动的对象。每个线程都拥有独立的程序计数器、进程栈和一组进程寄存器。内核的调度对象是线程,而不是进程。
在现代操作系统中,进程提供两种虚拟机制:虚拟处理器和虚拟内存。虚拟处理器提供给进程独享处理器的假象,虚拟内存则提供进程独占内存资源的假象。线程之间可以共享虚拟内存,但拥有各自的虚拟处理器。
创建
在 UNIX 系统中,只有系统调用 fork 可以创建新进程。
使用 fork 创建新进程,子进程从父进程继承了如下属性:
- 实际用户 ID、实际组 ID、有效用户 ID、有效组 ID
- 附属组 ID
- 进程组 ID
- 会话 ID
- 控制终端
- 设置用户 ID 标志和设置组 ID 标志
- 打开的文件描述符(相当于调用了 dup 函数)
- 当前工作目录
- 根目录
- 文件模式创建屏蔽字
- 信号屏蔽和处理函数
- close-on-exec 标志
- 环境
- 共享存储段
- 存储映射
- 资源限制
父子进程区别如下:
- fork 返回值
- 进程 ID 和父进程 ID
- 子进程的 tms_utime、tms_stime、tms_cutime、tms_ustime 的值设置为 0
- 子进程不继承父进程设置的文件锁
- 子进程未处理的 alarm 被清除
- 子进程未处理的信号集被置空
终止
进程终止通常由以下条件引起:
- 正常退出
- 出错退出
- 严重错误
- 被其他进程杀死
当进程终止时,内核会向其父进程发送 SIGCHLD 信号。
层次结构
在 UNIX 中,进程和其子进程共同组成一个进程组。整个系统中,所有进程都属于以 init 为根的一棵树。
进程组是一个或多个进程的集合,通常是在同一个作业中结合起来的。同一个进程组中的各进程接收来自同一终端的各种信号。每个进程组有一个唯一的进程组 ID。每个进程组有一个组长进程,组长进程的进程组 ID 等于其进程 ID。只要进程组中还有进程存在,该进程组就存在。一个进程只能为自己或其子进程设置进程组 ID,在子进程调用了 exec 后,它就无法再更改子进程的进程组 ID。
会话是一个或多个进程组的集合。一个会话可以有一个控制终端,建立与控制终端连接的会话首进程(session leader)被称为控制进程(controlling process)。会话可以有一个前台进程组和多个后台进程组。终端产生的信号都将发送给前台进程组,调制解调器断开连接时,挂断信号将发给控制进程。
孤儿进程组定义为:该组中每个成员的父进程要么是该组的一个成员,要么不是该组所属会话的成员。换句话说,如果该组有一个进程的父进程属于同一会话的另一个组,则该组不是孤儿进程组。POSIX.1 要求向孤儿进程组中处于停止状态的进程发送 SIGHUP 信号,系统对于这种信号的默认处理是终止进程。
为什么需要孤儿进程组的概念:
When a controlling process terminates, its terminal becomes free and a new session can be established on it. (In fact, another user could log in on the terminal.) This could cause a problem if any processes from the old session are still trying to use that terminal.
To prevent problems, process groups that continue running even after the session leader has terminated are marked as orphaned process groups. When a process group becomes an orphan, its processes are sent a SIGHUP signal. Ordinarily, this causes the processes to terminate. However, if a program ignores this signal or establishes a handler for it, it can continue running as in the orphan process group even after its controlling process terminates; but it still cannot access the terminal any more.
状态
进程有以下三种状态:
- 运行态:占用 CPU
- 就绪态:可以执行,等待其他进程执行完
- 阻塞态:需要外部事件触发
进程表
操作系统维护一张进程表,每个进程占用一个表项。该表项包含了进程状态的重要信息。包括程序计数器、堆栈指针、内存分配状况、所打开的文件指针、账号和调度信息,以及其他在进程由运行态转换到就绪态或阻塞态时必须保存的信息,以保证进程随后能再次启动。
下图为一个典型系统中进程表项的关键字段:
| 进程管理 | 存储管理 | 文件管理 |
|---|---|---|
| 寄存器 | 正文段指针 | 根目录 |
| 程序计数器 | 数据段指针 | 工作目录 |
| 程序状态字 | 堆栈段指针 | 文件描述符 |
| 进程状态 | ||
| 优先级 | ||
| 调度参数 | ||
| 进程id | ||
| 父进程 | ||
| 进程组 | ||
| 信号 | ||
| 进程开始的时间 | ||
| 使用cpu的时间 | ||
| 子进程的cpu时间 | ||
| 下次alarm的时间 |
中断
中断的处理和调度过程如下:
- 硬件将程序计数器等压入堆栈
- 硬件从中断向量中加载新的程序计数器
- 汇编语言写的 procedure 保存堆栈中的寄存器等信息,并移除该信息
- 汇编语言写的 procedure 设置新的堆栈
- c 中断服务例程开始执行
- 处理完后,调度程序决定下一个执行的进程
- 返回至汇编代码,恢复即将执行的进程的寄存器等信息,并启动该进程
线程
线程提供共享同一地址空间和数据的能力,并且比进程更加轻量级。
如果多个线程都是 CPU 密集型的,那么并不能得到性能上的增强。但如果存在大量的计算和 IO 处理,那么多线程运行这些活动彼此重叠进行,从而加快应用程序的执行速度。
进程模型基于两种独立的概念:资源分组处理和执行。而线程的引入即是对这两种概念的区分。理解进程的一个角度是,用某种方法把相关资源集中在一起,将资源放在进程中可以更容易的管理。另一个概念是,进程有一个执行线程,通常简写为线程。线程拥有程序计数器用以记录执行的下一条指令,寄存器用以保存当前的工作变量,堆栈用以记录执行历史,其中每一帧保存了一个已调用但还没返回的函数。进程用于把资源集中到一起,而线程则是在 CPU 上被调度执行的实体。
线程有两种主要的实现方法:
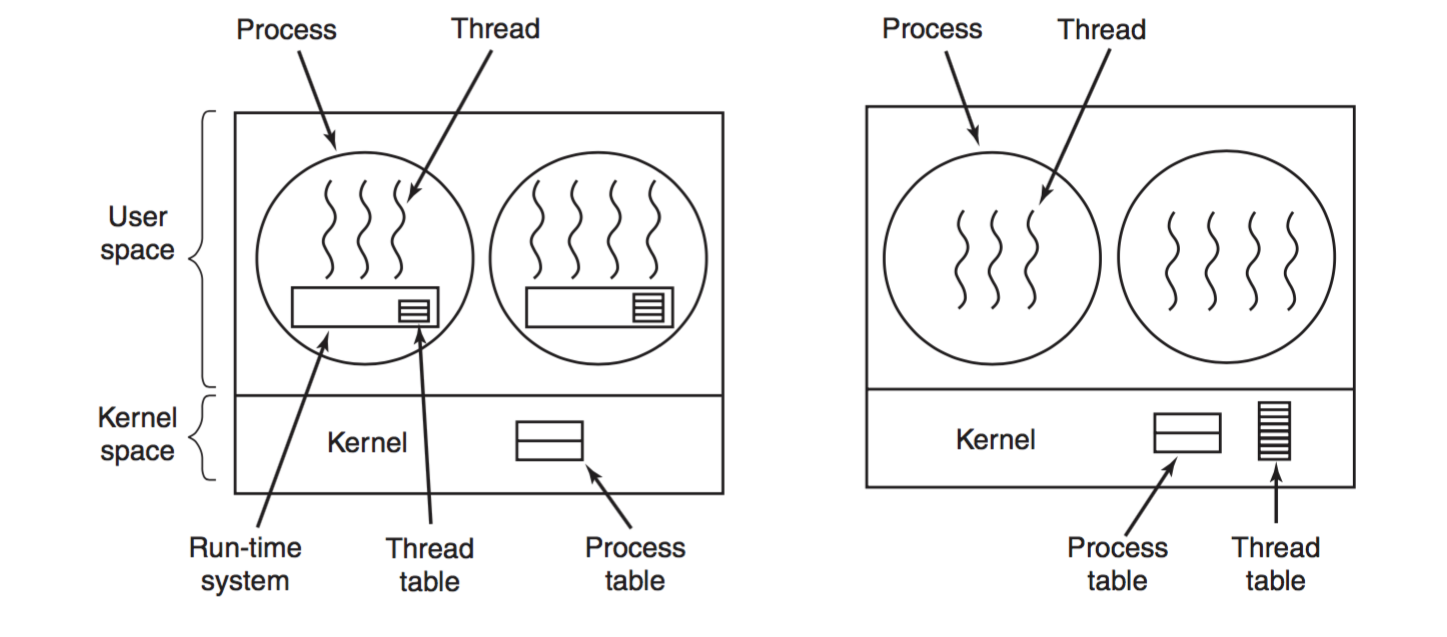
-
用户空间:
把整个线程包放在用户空间中,内核对线程一无所知。从内核的角度即单线程进程。这类实现有同样的通用结构,线程在一个运行时系统之上运行,运行时系统是管理线程的函数集合(pthread_create, pthread_exit, pthread_join 和 pthread_yield 等),如上图左图。
1 2 3 4 5 6 7
在用户空间管理线程时,每个进程需要有专用的线程表,用以跟踪该进程中的线程。线程表记录了线程的属性,如程序计数器、堆栈、寄存器和状态等。该线程表由运行时系统管理。 用户级线程的优点在于保存线程状态和调度都是本地过程,比内核调用更有效率,另外不需要陷阱,不需要上下文切换,也不需要对内存高速缓存进行刷新。 用户级线程还允许每个进程定制自己的调度算法。 用户级线程的问题在于难以实现阻塞系统调用,page faults 引发阻塞,以及没有时钟中断,需要依赖线程自动放弃 CPU。
-
内核空间:
1
内核实现线程的管理,此时便不再需要运行时系统了,如上图右图。在内核中有专门的线程表记录所有线程。与用户级线程类似,内核的线程表保存线程的信息。
系统调用及库函数
进程终止
正常终止包括以下方式:
- 从 main 函数返回
- 调用 exit
- 调用 _exit 或 _Exit
- 最后一个线程从其启动例程中返回
- 从最后一个线程调用 pthread_exit
异常退出有以下方式:
- 调用 abort
- 接收到一个信号
- 最后一个线程对取消请求做出回应
退出函数
1
2
3
4
5
6
#include <stdlib.h>
void exit(int status);
void _Exit(int status);
#include <unistd.h>
void _exit(int status);
_exit 和 _Exit 立即进入内核,而 exit 会先执行些清理工作(exit 函数总执行一个标准 I/O 库的清理关闭操作:对所有打开流调用 fclose 函数,造成输出缓冲区中数据被冲洗)。
三个退出函数都带有一个整型参数,称为终止状态。
Linux 中的实现
进程描述符及任务结构
内核把进程的列表存放在名为任务队列(task list)的双向循环链表中。链表中的每一项类型都为 task_struct ,称为进程描述符(process descriptor)。task_struct 在 32 位机器上大概占用 1.7 KB。
进程描述符包含了进程的所有信息,包括打开的文件,进程地址空间,挂起的信号,进程的状态等等。
task_struct 结构体如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct list_head tasks; // 进程链表
struct mm_struct *mm, *active_mm;
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
pid_t pid;
pid_t tgid;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct *real_parent; /* real parent process */
struct task_struct *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
/* file system info */
struct nameidata *nameidata;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
};
在内核 2.6 之前,task_struct 结构被存储于每个进程的内核栈的底部。2.6 之后,thread_info 结构体存储于内核栈的底部,而 task_struct 为该结构体的成员:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct thread_info {
struct task_struct *task; /* main task structure */
struct exec_domain *exec_domain; /* execution domain */
__u32 flags; /* low level flags */
__u32 status; /* thread synchronous flags */
__u32 cpu; /* current CPU */
int preempt_count; /* 0 => preemptable, <0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ESP of the previous stack in case of nested (IRQ) stacks */
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
PID 是进程的唯一标志,其类型为 pid_t。内核将进程的 PID 存放在各自的 task_struct 结构体中。
注:PID 在内核态和用户态是不同的概念。Linux 中的线程都有各自的 PID,而 getpid() 返回的其实不是 PID,而是 TGID。
stackoverflow 上的解释:
The first and most important thing to realize is that “PID” means different things in kernel space and user space. What the kernel calls PIDs are actually kernel-level thread ids (often called TIDs), not to be confused with pthread_t which is a separate identifier. Each thread on the system, whether in the same process or a different one, has a unique TID (or “PID” in the kernel’s terminology). What’s considered a PID in the POSIX sense of “process”, on the other hand, is called a “thread group ID” or “TGID” in the kernel. Each process consists of one or more threads (kernel processes) each with their own TID (kernel PID), but all sharing the same TGID, which is equal to the TID (kernel PID) of the initial thread in which main runs.
current 宏用于快速定位当前执行的进程的进程描述符,current_thread_info() 的 C 语言实现如下:
1
2
3
4
5
6
7
static inline struct thread_info *current_thread_info(void) __attribute_const__;
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1)); // 按照 THREAD\_SIZE 对齐
}
调用 current_thread_info()->task 返回 task_struct。
进程的当前状态由 task_struct 的 state 字段来表示,分别有以下几种情况:
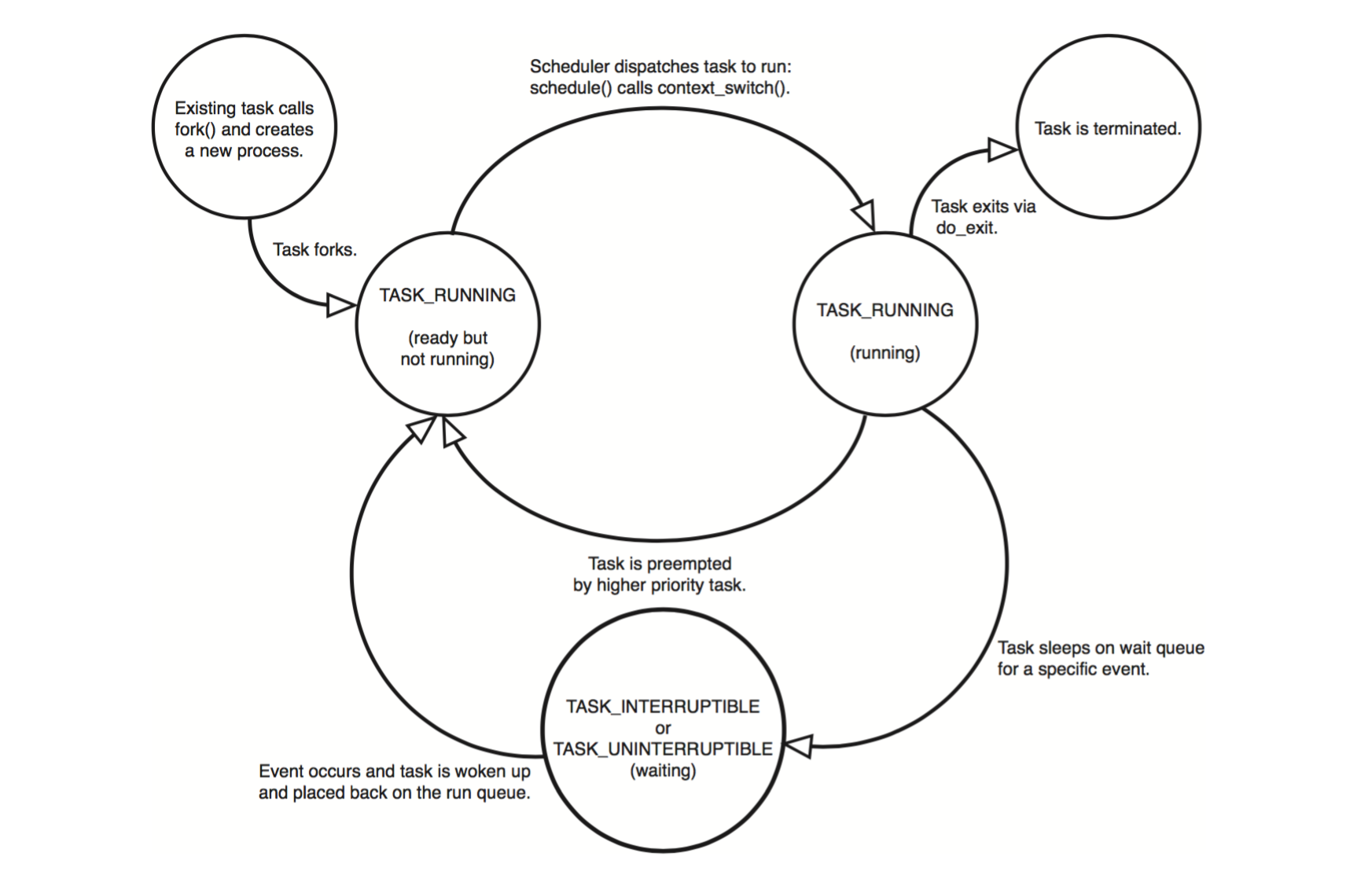
- TASK_RUNNING:进程正在执行或处于可运行的就绪状态。
- TASK_INTERRUPTIBLE:进程正在休眠,等待某个条件发生。当收到信号时进程也会被唤醒。
- TASK_UNINTERRUPTIBLE:和 TASK_INTERRUPTIBLE 类似,但收到信号时进程不会被唤醒。
- __TASK_STOPPED:进程终止,通常发生于进程收到 SIGSTOP, SIGTSTP, SIGTTIN 或 SIGTTOU 信号。
当进程执行了系统调用或触发了异常,它就陷入了内核空间,此时内核“代表进程执行”并处于进程的上下文中。在此上下文中 current 宏是有效的(处于中断上下文的情况下,系统不代表进程执行,此时不存在进程上下文,current 宏也是无效的)。
task_struct 的 parent 字段指向其父进程 task_struct,children 字段为其子进程的链表。因此可以通过下面代码得到父进程的进程描述符:
1
struct task_struct *my_parent = current->parent;
同样,以下代码可以依次访问子进程:
1
2
3
4
5
6
7
struct task_struct *task;
struct list_head *list;
list_for_each(list, ¤t->children) {
task = list_entry(list, struct task_struct, sibling);
/* task now points to one of current’s children */
}
任务队列是双向循环链表,下面代码可以获取链表中的下一个进程:
1
list_entry(task->tasks.next, struct task_struct, tasks)
获取前一个进程:
1
list_entry(task->tasks.prev, struct task_struct, tasks)
进程创建
fork() 通过拷贝当前进程来创建一个子进程。子进程和父进程的区别仅仅在于 PID、PPID 和某些资源和统计量(例如挂起的信号)。exec() 函数负责读取可执行文件并将其载入地址空间开始运行。
Linux 通过 clone() 系统调用实现 fork()。这个调用通过一系列参数标志来指明父子进程需要共享的资源。fork()、vfork() 和 __clone() 库函数都根据各自需要的参数标志去调用 clone(),然后由 clone() 去调用 do_fork()。
do_fork() 完成创建进程中的大部分工作,该函数调用 copy_process() 函数,然后让进程开始运行。copy_process() 的步骤如下:
- 调用 dup_task_struct() 为新进程创建一个内核栈、thread_info 结构和 task_struct。这些值与当前进程相同,此时父子进程的描述符完全相同。
- 检查当前用户所拥有的进程数没有超出资源限制。
- 子进程开始与父进程区别开来,将进程描述符里的大多数成员重新初始化。
- 将子进程的状态置为 TASK_UNINTERRUPTIBLE。(没有找到对应的代码)
- copy_process() 调用 copy_flags() 以更新 task_struct 的 flags 成员,重置 PF_SUPERPRIV 标志位,并设置 PF_FORKNOEXEC 标志位。
- 根据不同的 clone_flags 参数,拷贝或共享打开的文件、文件系统信息、信号处理函数、进程地址空间和命名空间等。一般情况下,同一个进程内的线程共享这些信息。
- 调用 alloc_pid() 为新进程分配一个有效的 PID。
- 最后,copy_process() 做扫尾工作并返回指向子进程的指针。
回到 do_fork() 函数,如果 copy_process() 返回成功,唤醒新创建的子进程并让其投入运行。内核有意选择子进程先执行,如果子进程马上调用 exec() 函数可以避免写时拷贝的额外开销。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
/*
* We set PF_STARTING at creation in case tracing wants to
* use this to distinguish a fully live task from one that
* hasn't gotten to tracehook_report_clone() yet. Now we
* clear it and set the child going.
*/
p->flags &= ~PF_STARTING;
if (unlikely(clone_flags & CLONE_STOPPED)) {
/*
* We'll start up with an immediate SIGSTOP.
*/
sigaddset(&p->pending.signal, SIGSTOP);
set_tsk_thread_flag(p, TIF_SIGPENDING);
__set_task_state(p, TASK_STOPPED);
} else {
wake_up_new_task(p, clone_flags);
}
if (clone_flags & CLONE_VFORK) {
wait_for_completion(&vfork);
}
} else {
nr = PTR_ERR(p);
}
return nr;
}
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
p = dup_task_struct(current);
if (atomic_read(&p->real_cred->user->processes) >=
task_rlimit(p, RLIMIT_NPROC)) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
#ifndef CONFIG_VIRT_CPU_ACCOUNTING
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
#endif
/* copy all the process information */
if ((retval = copy_semundo(clone_flags, p)))
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p)))
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p)))
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p)))
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p)))
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p)))
goto bad_fork_cleanup_signal;
if ((retval = copy_namespaces(clone_flags, p)))
goto bad_fork_cleanup_mm;
if ((retval = copy_io(clone_flags, p)))
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid; // 同一进程内的所有线程的 tgid 相同
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
return p;
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
setup_thread_stack(tsk, orig);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* for overflow detection */
/* One for us, one for whoever does the "release_task()" (usually parent) */
atomic_set(&tsk->usage,2);
atomic_set(&tsk->fs_excl, 0);
return tsk;
}
// x86 下的实现
int arch_dup_task_struct(struct task_struct *dst, struct task_struct *src)
{
*dst = *src;
if (src->thread.xstate) {
dst->thread.xstate = kmem_cache_alloc(task_xstate_cachep,
GFP_KERNEL);
if (!dst->thread.xstate)
return -ENOMEM;
WARN_ON((unsigned long)dst->thread.xstate & 15);
memcpy(dst->thread.xstate, src->thread.xstate, xstate_size);
}
return 0;
}
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
#define setup_thread_stack(p, org) \
*task_thread_info(p) = *task_thread_info(org); \
task_thread_info(p)->task = (p);
static void copy_flags(unsigned long clone_flags, struct task_struct *p)
{
unsigned long new_flags = p->flags;
new_flags &= ~PF_SUPERPRIV;
new_flags |= PF_FORKNOEXEC;
new_flags |= PF_STARTING;
p->flags = new_flags;
clear_freeze_flag(p);
}
void wake_up_new_task(struct task_struct *p, unsigned long clone_flags)
{
unsigned long flags;
struct rq *rq;
int cpu __maybe_unused = get_cpu();
#ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear through hotplug
*
* We still have TASK_WAKING but PF_STARTING is gone now, meaning
* ->cpus_allowed is stable, we have preemption disabled, meaning
* cpu_online_mask is stable.
*/
cpu = select_task_rq(p, SD_BALANCE_FORK, 0);
set_task_cpu(p, cpu);
#endif
/*
* Since the task is not on the rq and we still have TASK_WAKING set
* nobody else will migrate this task.
*/
rq = cpu_rq(cpu);
raw_spin_lock_irqsave(&rq->lock, flags);
BUG_ON(p->state != TASK_WAKING);
p->state = TASK_RUNNING; // 设置成TASK_RUNNING状态
update_rq_clock(rq);
activate_task(rq, p, 0); // activate_task 会把该 task 放入 cpu 的 runqueue
trace_sched_wakeup_new(rq, p, 1);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
#endif
task_rq_unlock(rq, &flags);
put_cpu();
}
/*
* activate_task - move a task to the runqueue.
*/
static void activate_task(struct rq *rq, struct task_struct *p, int wakeup)
{
if (task_contributes_to_load(p))
rq->nr_uninterruptible--;
enqueue_task(rq, p, wakeup, false); // 放入 runqueue
inc_nr_running(rq);
}
vfork() 的实现是通过向 clone() 传递一个特殊标志 CLONE_VFORK 来进行的:
- 在调用 copy_process() 时,task_struct 的 vfork_done 成员被设置为 NULL。
- 在执行 do_fork() 时,如果指定了 CLONE_VFORK 标志位,则 vfork_done 会被设置为指向一个特定地址。
- 子进程先开始执行后,父进程会一直等待,直到子进程通过 vfork_done 指针向他发送信号。
- 进程退出内存地址空间时会调用 mm_release() 函数,该函数会检查 vfork_done 是非为空,如果非空,则向父进程发送信号。
- 返回到 do_fork(),父进程被唤醒并继续执行
1
2
3
4
5
6
7
8
9
10
void mm_release(struct task_struct *tsk, struct mm_struct *mm)
{
struct completion *vfork_done = tsk->vfork_done;
/* notify parent sleeping on vfork() */
if (vfork_done) {
tsk->vfork_done = NULL;
complete(vfork_done);
}
}
线程
Linux 把所有线程都当做进程来实现,每个线程都有唯一隶属于自己的 task_struct,所以在内核中,它看起来就像是一个普通的进程。
线程的创建和普通进程类似,只不过调用 clone() 的时候需要传递参数来指明需要共享的资源:
1
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
下表列举了参数标志及其作用:
| Flag | Meaning |
|---|---|
| CLONE_FILES | Parent and child share open files |
| CLONE_FS | Parent and child share filesystem information |
| CLONE_IDLETASK | Set PID to zero (used only by the idle tasks) |
| CLONE_NEWNS | Create a new namespace for the child |
| CLONE_PARENT | Child is to have same parent as its parent |
| CLONE_PTRACE | Continue tracing child |
| CLONE_SETTID | Write the TID back to user-space |
| CLONE_SETTLS | Create a new TLS for the child |
| CLONE_SIGHAND | Parent and child share signal handlers and blocked signals |
| CLONE_SYSVSEM | Parent and child share System V SEM_UNDO semantics |
| CLONE_THREAD | Parent and child are in the same thread group |
| CLONE_VFORK | vfork() was used and the parent will sleep until the child wakes it |
| CLONE_UNTRACED | Do not let the tracing process force CLONE_PTRACE on the child |
| CLONE_STOP | Start process in the TASK_STOPPED state |
| CLONE_SETTLS | Create a new TLS (thread-local storage) for the child |
| CLONE_CHILD_CLEARTID | Clear the TID in the child |
| CLONE_CHILD_SETTID | Set the TID in the child |
| CLONE_PARENT_SETTID | Set the TID in the parent |
| CLONE_VM | Parent and child share address space |
内核经常需要在后台执行一些操作,这通过内核线程来完成。内核线程和普通进程间的区别在于内核线程没有独立的地址空间(指向地址空间的 mm 指针被设置为 NULL)。内核线程只在内核空间运行,从来不切换到用户空间。内核线程和普通进程一样可以被调度和抢占。
进程终止
进程终止可以由自身调用 exit() 系统调用引起,或接收到不能处理或不能忽略的信号或异常时。进程终止由 do_exit() 完成大部分工作:
- 将 task_struct 中的标志成员设置为 PF_EXITING。
- 调用 del_timer_sync() 删除内核定时器,确保没有定时器在排队也没有定时器处理程序在运行。
- 调用 acct_update_intergrals() 来输出记账信息。
- 调用 exit_mm() 函数释放进程占用的 mm_struct。如果该地址空间没有被共享,则彻底释放它们。
- 设置 exit_code 成员为由 exit() 提供的退出代码。
- 接下来调用 exit_sem() 函数,如果该进程正在排队等候 IPC 信号,则 dequeue。
- 调用 exit_files() 和 exit_fs(),分别递减文件描述符、文件系统数据的引用计数。如果引用计数降为零,则释放资源。
- 调用 exit_notify() 向父进程发送信号,给其子进程重新找养父,并把进程状态设置为 EXIT_ZOMBIE。
- do_exit() 调用 schedule() 函数切换到新的进程。由于处于 EXIT_ZOMBIE 状态的进程不会再被调度,所以 do_exit() 永不返回。
至此,与进程相关的所有资源都被释放,进程不可运行并处于 EXIT_ZOMBIE 状态。它占用的内存就是内核栈、thread_info 结构和 task_struct 结构。此时进程存在的唯一目的就是向父进程提供信息。父进程检索到信息或通知内核那是无关信息后,进程所持有的剩余内存将被释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
NORET_TYPE void do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT
"Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_signals(tsk); /* sets PF_EXITING */
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
tsk->exit_code = code;
exit_mm(tsk);
exit_sem(tsk);
exit_files(tsk);
exit_fs(tsk);
check_stack_usage();
exit_thread();
cgroup_exit(tsk, 1);
exit_notify(tsk, group_dead);
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
preempt_disable();
exit_rcu();
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
schedule();
}
static void exit_mm(struct task_struct * tsk)
{
struct mm_struct *mm = tsk->mm;
struct core_state *core_state;
mm_release(tsk, mm);
if (!mm)
return;
down_read(&mm->mmap_sem);
atomic_inc(&mm->mm_count);
BUG_ON(mm != tsk->active_mm);
/* more a memory barrier than a real lock */
task_lock(tsk);
tsk->mm = NULL;
up_read(&mm->mmap_sem);
enter_lazy_tlb(mm, current);
/* We don't want this task to be frozen prematurely */
clear_freeze_flag(tsk);
task_unlock(tsk);
mm_update_next_owner(mm);
mmput(mm);
}
/*
* Send signals to all our closest relatives so that they know
* to properly mourn us..
*/
static void exit_notify(struct task_struct *tsk, int group_dead)
{
int signal;
void *cookie;
/*
* This does two things:
*
* A. Make init inherit all the child processes
* B. Check to see if any process groups have become orphaned
* as a result of our exiting, and if they have any stopped
* jobs, send them a SIGHUP and then a SIGCONT. (POSIX 3.2.2.2)
*/
forget_original_parent(tsk);
exit_task_namespaces(tsk);
write_lock_irq(&tasklist_lock);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
/* Let father know we died
*
* Thread signals are configurable, but you aren't going to use
* that to send signals to arbitary processes.
* That stops right now.
*
* If the parent exec id doesn't match the exec id we saved
* when we started then we know the parent has changed security
* domain.
*
* If our self_exec id doesn't match our parent_exec_id then
* we have changed execution domain as these two values started
* the same after a fork.
*/
if (tsk->exit_signal != SIGCHLD && !task_detached(tsk) &&
(tsk->parent_exec_id != tsk->real_parent->self_exec_id ||
tsk->self_exec_id != tsk->parent_exec_id))
tsk->exit_signal = SIGCHLD;
signal = tracehook_notify_death(tsk, &cookie, group_dead);
if (signal >= 0)
signal = do_notify_parent(tsk, signal); // 给父进程发信号。如果父进程处理 SIGCHLD 信号,返回 DEATH_REAP
tsk->exit_state = signal == DEATH_REAP ? EXIT_DEAD : EXIT_ZOMBIE;
/* mt-exec, de_thread() is waiting for us */
if (thread_group_leader(tsk) &&
tsk->signal->group_exit_task &&
tsk->signal->notify_count < 0)
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
tracehook_report_death(tsk, signal, cookie, group_dead);
/* If the process is dead, release it - nobody will wait for it */
if (signal == DEATH_REAP)
release_task(tsk);
}
调用 do_exit() 之后,其进程描述符依然被保留。在其父进程获得退出信息或通知内核它并不关注后,子进程的 task_struct 才被释放。
wait() 这一组函数都是通过唯一的系统调用 wait4() 来实现。它的标准动作是挂起调用它的进程,直到其中一个子进程退出。此时函数会返回该子进程的 PID。此外,调用该函数时提供的指针会包含子进程退出时的退出码。
wait 系统调用会调用 do_wait() 函数,其将调用 do_wait_thread() -> wait_consider_task() -> wait_task_zombie() -> release_task()。release_task() 会释放进程描述符,完成以下工作:
- 调用 __exit_signal(),进行最终统计,并调用 _unhash_process(),后者又会调用 detach_pid() 从 pidhash 上删除该进程,同时也从任务列表中删除该进程。
- __exit_signal() 释放僵死进程所占用的剩余资源。
- 如果该进程是线程组的最后一个进程,并且领头进程已经死掉,那么release_task() 就得通知僵死的领头进程的父进程。
- release_task() 调用 put_task_struct() 释放进程内核栈和 thread_info 结构所占的页,并释放 task_struct 所占的 slab 高速缓存。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
void release_task(struct task_struct * p)
{
struct task_struct *leader;
int zap_leader;
repeat:
__exit_signal(p);
zap_leader = 0;
leader = p->group_leader;
if (leader != p && thread_group_empty(leader) && leader->exit_state == EXIT_ZOMBIE) {
BUG_ON(task_detached(leader));
do_notify_parent(leader, leader->exit_signal);
/*
* If we were the last child thread and the leader has
* exited already, and the leader's parent ignores SIGCHLD,
* then we are the one who should release the leader.
*
* do_notify_parent() will have marked it self-reaping in
* that case.
*/
zap_leader = task_detached(leader);
/*
* This maintains the invariant that release_task()
* only runs on a task in EXIT_DEAD, just for sanity.
*/
if (zap_leader)
leader->exit_state = EXIT_DEAD;
}
write_unlock_irq(&tasklist_lock);
release_thread(p);
call_rcu(&p->rcu, delayed_put_task_struct);
p = leader;
if (unlikely(zap_leader))
goto repeat;
}
/*
* This function expects the tasklist_lock write-locked.
*/
static void __exit_signal(struct task_struct *tsk)
{
struct signal_struct *sig = tsk->signal;
struct sighand_struct *sighand;
BUG_ON(!sig);
BUG_ON(!atomic_read(&sig->count));
posix_cpu_timers_exit(tsk);
if (atomic_dec_and_test(&sig->count))
posix_cpu_timers_exit_group(tsk);
else {
/*
* If there is any task waiting for the group exit
* then notify it:
*/
if (sig->group_exit_task && atomic_read(&sig->count) == sig->notify_count)
wake_up_process(sig->group_exit_task);
if (tsk == sig->curr_target)
sig->curr_target = next_thread(tsk);
/*
* Accumulate here the counters for all threads but the
* group leader as they die, so they can be added into
* the process-wide totals when those are taken.
* The group leader stays around as a zombie as long
* as there are other threads. When it gets reaped,
* the exit.c code will add its counts into these totals.
* We won't ever get here for the group leader, since it
* will have been the last reference on the signal_struct.
*/
sig->utime = cputime_add(sig->utime, tsk->utime);
sig->stime = cputime_add(sig->stime, tsk->stime);
sig->gtime = cputime_add(sig->gtime, tsk->gtime);
sig->min_flt += tsk->min_flt;
sig->maj_flt += tsk->maj_flt;
sig->nvcsw += tsk->nvcsw;
sig->nivcsw += tsk->nivcsw;
sig->inblock += task_io_get_inblock(tsk);
sig->oublock += task_io_get_oublock(tsk);
task_io_accounting_add(&sig->ioac, &tsk->ioac);
sig->sum_sched_runtime += tsk->se.sum_exec_runtime;
sig = NULL; /* Marker for below. */
}
__unhash_process(tsk);
/*
* Do this under ->siglock, we can race with another thread
* doing sigqueue_free() if we have SIGQUEUE_PREALLOC signals.
*/
flush_sigqueue(&tsk->pending);
tsk->signal = NULL;
tsk->sighand = NULL;
spin_unlock(&sighand->siglock);
__cleanup_sighand(sighand);
clear_tsk_thread_flag(tsk,TIF_SIGPENDING);
if (sig) {
flush_sigqueue(&sig->shared_pending);
taskstats_tgid_free(sig);
/*
* Make sure ->signal can't go away under rq->lock,
* see account_group_exec_runtime().
*/
task_rq_unlock_wait(tsk);
__cleanup_signal(sig);
}
}
static void __unhash_process(struct task_struct *p)
{
nr_threads--;
detach_pid(p, PIDTYPE_PID);
if (thread_group_leader(p)) {
detach_pid(p, PIDTYPE_PGID);
detach_pid(p, PIDTYPE_SID);
list_del_rcu(&p->tasks); // 没理解 为什么需要是 group_header 才从 tasks_list 上删掉?
list_del_init(&p->sibling);
__get_cpu_var(process_counts)--;
}
list_del_rcu(&p->thread_group);
}
void release_task(struct task_struct *p)
{
struct task_struct *leader;
__exit_signal(p);
zap_leader = 0;
leader = p->group_leader;
if (leader != p && thread_group_empty(leader)
&& leader->exit_state == EXIT_ZOMBIE) {
/*
* If we were the last child thread and the leader has
* exited already, and the leader's parent ignores SIGCHLD,
* then we are the one who should release the leader.
*/
zap_leader = do_notify_parent(leader, leader->exit_signal);
if (zap_leader)
leader->exit_state = EXIT_DEAD;
}
release_thread(p);
}
void detach_pid(struct task_struct *task, enum pid_type type)
{
__change_pid(task, type, NULL);
}
static void __change_pid(struct task_struct *task, enum pid_type type,
struct pid *new)
{
struct pid_link *link;
struct pid *pid;
int tmp;
link = &task->pids[type];
pid = link->pid;
hlist_del_rcu(&link->node);
link->pid = new;
for (tmp = PIDTYPE_MAX; --tmp >= 0; )
if (!hlist_empty(&pid->tasks[tmp]))
return;
free_pid(pid);
}
如果父进程在子进程之前退出,需要给子进程在当前的线程组内找一个进程作为父亲,如果失败,则让 init 做子进程的父进程。forget_original_parent() 调用 find_new_reaper() 来执行寻父过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
static void forget_original_parent(struct task_struct *father)
{
struct task_struct *p, *n, *reaper;
LIST_HEAD(dead_children);
exit_ptrace(father);
write_lock_irq(&tasklist_lock);
reaper = find_new_reaper(father);
list_for_each_entry_safe(p, n, &father->children, sibling) {
struct task_struct *t = p;
do {
t->real_parent = reaper;
if (t->parent == father) {
BUG_ON(task_ptrace(t));
t->parent = t->real_parent;
}
} while_each_thread(p, t);
reparent_leader(father, p, &dead_children);
}
write_unlock_irq(&tasklist_lock);
BUG_ON(!list_empty(&father->children));
list_for_each_entry_safe(p, n, &dead_children, sibling) {
list_del_init(&p->sibling);
release_task(p);
}
}
static struct task_struct *find_new_reaper(struct task_struct *father)
{
struct pid_namespace *pid_ns = task_active_pid_ns(father);
struct task_struct *thread;
thread = father;
while_each_thread(father, thread) {
if (thread->flags & PF_EXITING)
continue;
if (unlikely(pid_ns->child_reaper == father))
pid_ns->child_reaper = thread;
return thread;
}
if (unlikely(pid_ns->child_reaper == father)) {
write_unlock_irq(&tasklist_lock);
if (unlikely(pid_ns == &init_pid_ns))
panic("Attempted to kill init!");
zap_pid_ns_processes(pid_ns);
write_lock_irq(&tasklist_lock);
/*
* We can not clear ->child_reaper or leave it alone.
* There may by stealth EXIT_DEAD tasks on ->children,
* forget_original_parent() must move them somewhere.
*/
pid_ns->child_reaper = init_pid_ns.child_reaper;
}
return pid_ns->child_reaper;
}