本系列文章是对 MIT 6.824 课程的学习笔记。
Introduction
本课程涵盖以下主题:
- RPC、线程、并发控制
- 性能
- 容灾:Availability, Durability. replicated servers 是不错的选择。
- 一致性:replica如何保持一致? Consistency 和 Performance 不可兼得
MapReduce
Map funciton 接收 input pair 处理生成一系列的 intermediate key/value pairs。MapReduce 库将相同 intermediate key 的 intermediate values 打包起来传给 Reduce function。
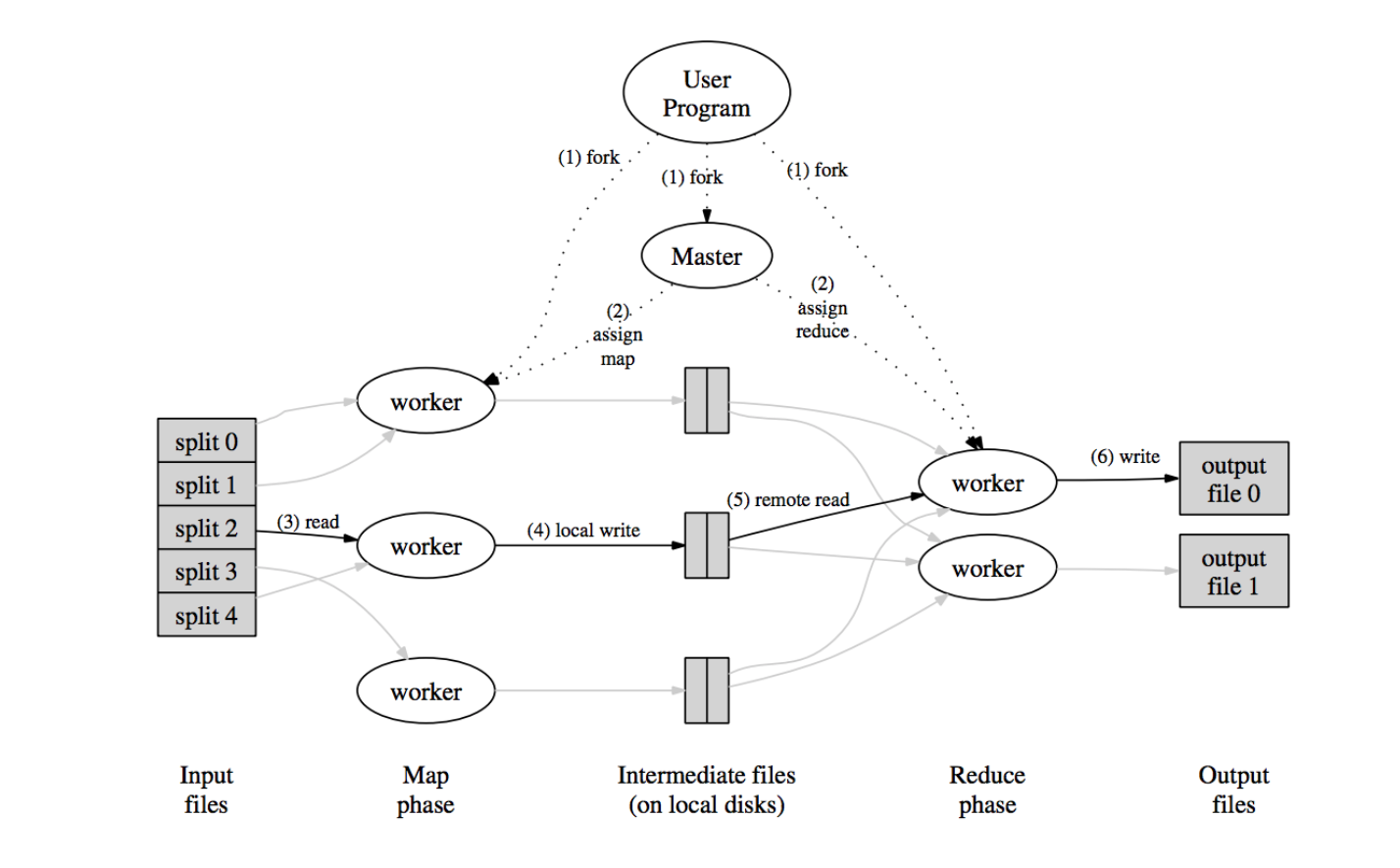
Reduce function 接收 intermediate key 和与其关联的一系列 intermediate values。Reduce function 将这些 intermediate values 合并成更小的 values set。The intermediate values are supplied to the user’s reduce function via an iterator。
Map Reduce function 的输入输出参数通常如下:
- map (k1,v1) → list(k2,v2)
- reduce (k2,list(v2)) → list(v2)
容错:worker 挂掉,重跑任务。master挂掉?直接暂停,由用户决定是否重跑。
MR re-runs just the failed Map()s and Reduce()s. MR requires them to be pure functions:
- they don’t keep state across calls,
- they don’t read or write files other than expected MR inputs/outputs,
- there’s no hidden communication among tasks.
So re-execution yields the same output.
重跑如何保持一致:
Rely on atomic commits of map and reduce task outputs 细节?
不确定性?
实现一个精简map reduce
RPC
Better RPC behavior: “at most once”
idea: server RPC code detects duplicate requests, returns previous reply instead of re-running handler
如何检测重复的请求?
- Client 在每个请求都带上唯一的 Request ID,重试时使用相同的 Request ID:
1
2
3
4
5
6
7
server:
if seen[xid]:
r = old[xid]
else
r = handler()
old[xid] = r
seen[xid] = true
Request ID 如何保证唯一?
- 请求 id 包含客户端 ip,以区分不同客户端
Server 端何时可以删掉保存的请求 id?
- unique client IDs, per-client RPC sequence numbers, client includes “seen all replies <= X” with every RPC, much like TCP sequence #s and acks (客户端带上 ack_req_id,服务端可以把 <= ack_req_id 的请求 id 都删掉)
- only allow client one outstanding RPC at a time arrival of seq + 1 allows server to discard all <= seq
- client agrees to keep retrying for < 5 minutes, server discards after 5+ minutes
Server 应该把 Dupliate Request 信息写入磁盘,也应该同步到 replica。万一 server crash 或者重启,才不会丢失。
GFS
GFS 重新审视了传统文件系统的设计,并总结了以下几点:
- 组件挂掉是常态事件,因此文件系统必须集成监控、错误侦测、容灾以及自动恢复的机制
- 几 GB 的大文件很普遍。
- 随机写的场景非常少。一旦写入完成,文件通常只会被顺序读取
- co-designing the applications and the file system API benefits the overall system by increasing our flexibility(不理解,是说简化 API 的设计么?)
GFS 集群由单一 master 和多个 chunkserver 构成,可同时被多个 client 访问。文件被划为固定大小的 chunks。每个 chunk 在创建时由 master 分配一个不可修改且全局唯一的 chunk handle 标记。chunkservers 以 linux 文件形式保存 chunks,读写 chunks 时client 指定 chunk handle 和 byte range。每个 chunk 被复制多份以实现 reliability。
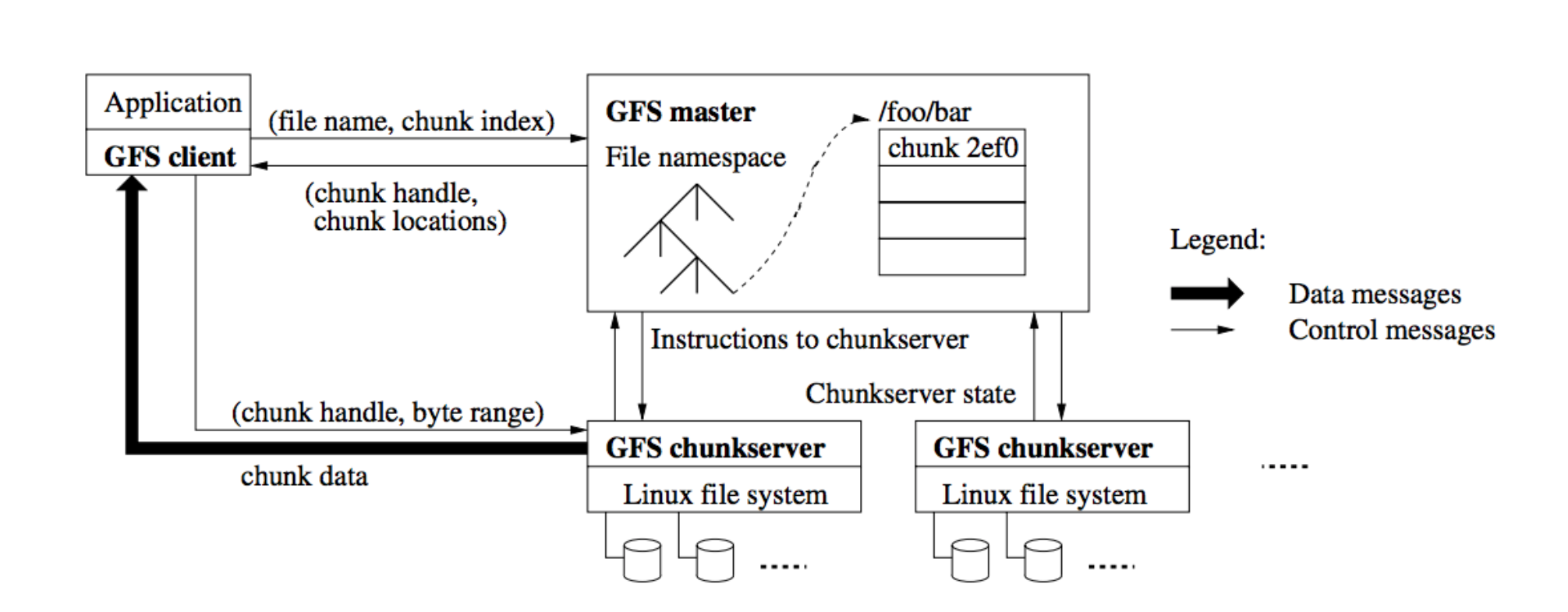
Master 维护整个文件系统的 metadata,包括命名空间,访问控制,文件到 chunks 的映射和 chunks 所在的位置。Master 还管理系统范围内的活动,例如 chunk 租用管理, orphaned chunk 的回收,以及 chunks 在 chunkservers 之间的迁移。Master 使用心跳信息周期地和每个 chunkserver 通讯,发送指令并收集 chunkserver 的状态信息。
Client 和 master 的通信只涉及元数据,所有的数据操作都直接和 chunkservers 通信。
Master 主要保存下面三种元数据:
- 文件和 chunk 的命名空间
- 文件到 chunk 的映射关系
- chunk 复本的位置
前两种通过 logging mutations 持久化。chunk 复本的位置则是启动时 master 向每个 chunkserver 询问的。
容灾:通过 snapshot 和 logging mutations。
一致性:
- A file region is consistent if all clients will always see the same data, regardless of which replicas they read from.
- A region is defined after a file data mutation if it is consistent and clients will see what the mutation writes in its entirety.
GFS 通过以下措施确保被修改的文件 region 是已定义的,并且包含最后一次修改操作写入的数据:
- chunk 的所有副本的修改操作顺序保持一致
- 使用 chunk 的版本号来检测副本是否有效
为了应对记录追加的 at-least-once 特性,readers 可以使用下面的方法来处理 padding 和重复的 record。Writers (应用层 writer)在每条写入的记录中都包含了额外的信息例如 Checksum,用来验证它的有效性。Reader 使用 Checksum 识别和丢弃额外的 padding 和记录片段。应用程序还可以用记录的唯一标识符来过滤重复 record。
GFS 使用租约(lease)来保证多个副本间变更顺序的一致性。Master 节点给其中一个 replica 分配 chunk 租约,该 replica 变成 primary。Mutations 的顺序由 primary 决定。
Master 维护了每个 chunk 的版本号,用以分辨出过时的 replicas。 每次 master 下发新的 lease 都会提升 chunk 的版本号。当 chunkserver 上报自身 chunk 集合和相关的版本号时,master 就可以检测出失效的 replica。
Fault-Tolerant Virtual Machines
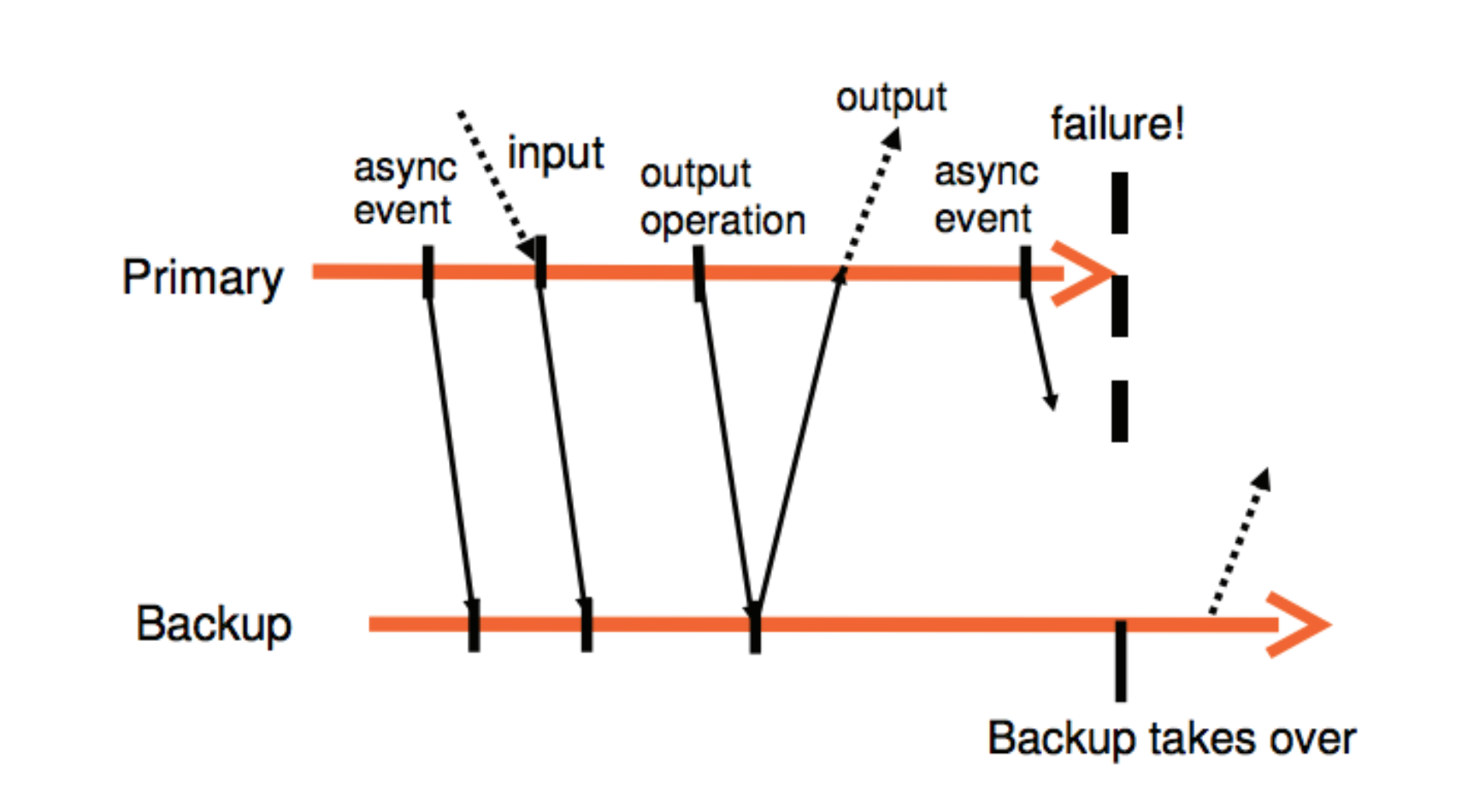
实现容错系统最常见的一种方法是主备方法,备机必须与主机保持接近一致。实现主备一致的一个普遍的做法是将主机状态的变化都同步给备机,包括 CPU、内存、I/O,但这种方式需要大量的带宽。另一种方式是将服务器建模成 deterministic state machine,如果输入相同,那最终的状态也会相同。通过同步输入序列的方式,对带宽的要求远低于同步状态的方式。
Primary VM 的输入将通过 logging channel 同步给 backup VM。backup 的输出会被 hypervisor 丢弃,只有 primary VM 的输出会返回给客户端。
Log all hardware events into a log: clock interrupts, network interrupts, i/o interrupts, etc.
-
For non-deterministic instructions, record additional info
e.g., log the value of the time stamp register
on replay: return the value from the log instead of the actual register
-
Replay: delivery inputs in the same order at the same instructions
if during recording delivered clock interrupt at nth instruction executed during replay also delivers the clock interrupt at the nth instruction
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continu executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world.
要满足 Output Requirement,所有的输出都必须延迟直到 backup VM 收到和该输出相关联的信息以便其可以回放。确保 Output Requirement 的一个简单的做法是给每个 output 操作创建一个特殊的log entry,当 backup VM 接收并 ack 该 log entry 时 primary VM 才会输出结果。
FT 使用 UDP 发送心跳包来检测 server 是否存活。另外 FT 还会通过监控从 primary 发往 backup 的流量的方式来检测。
为了避免 split-brain 的问题,在切换主的时候,需要在 shared storage 上执行原子的 test-and-set 操作,执行成功的才能升为 primary。