最近项目组有在用 protobuf,于是抽空读了些 protobuf 的相关资料。本文总结 protobuf 的编码原理,重点在于其如何实现版本兼容。文中样例及说明都参考了 protobuf 的官方文档。
编码方法的介绍
要了解 protobuf 的编码方式,首先介绍下 Varint 和 ZigZag 这两种编码。
Varint
Varint 编码的优势在于值越小的数字,占用的字节更少。一般 int32 的数字都需要占用 4 个字节。使用 Varint 进行编码则有可能缩减到 1 个字节。反过来,如果是比较大的数字,则可能需要占用 5 个字节。 理解了 Varint 的目的(节省空间),来看看其原理:
Each byte in a varint, except the last byte, has the most significant bit (msb) set – this indicates that there are further bytes to come. The lower 7 bits of each byte are used to store the two’s complement representation of the number in groups of 7 bits, least significant group first.
即是说,Varint 中的每个字节的最高位 bit 有特殊的含义,该位为 1 表示后续的字节也是该数字的一部分,如果该位为 0 则是最后一个字节。其他的 7 个bit都用来表示数字,从最低有效字节开始。
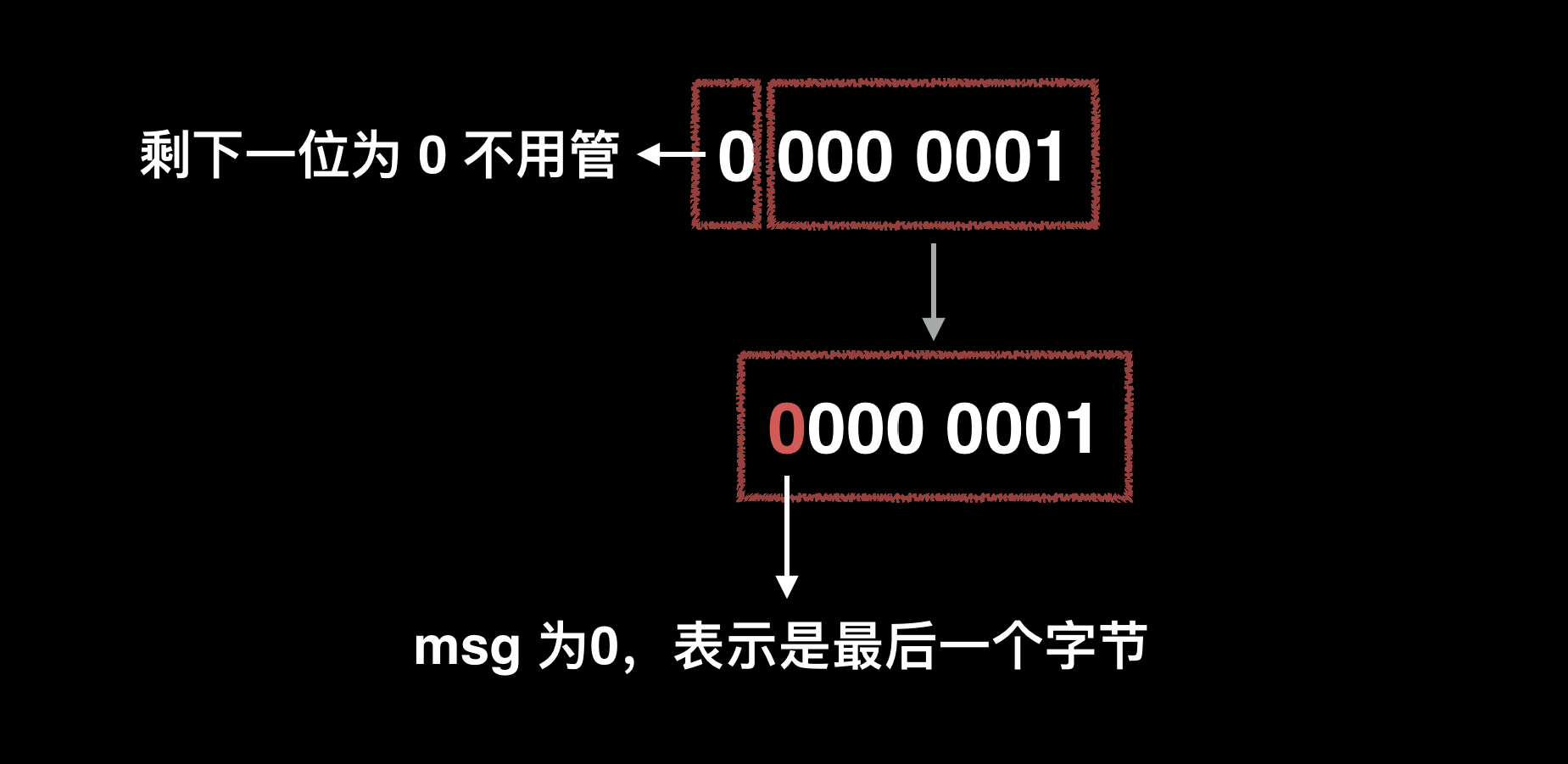
举个例子,1 的二进制表示为 0000 0001。通过 Varint 编码后的二进制表示为 0000 0001,过程如下:
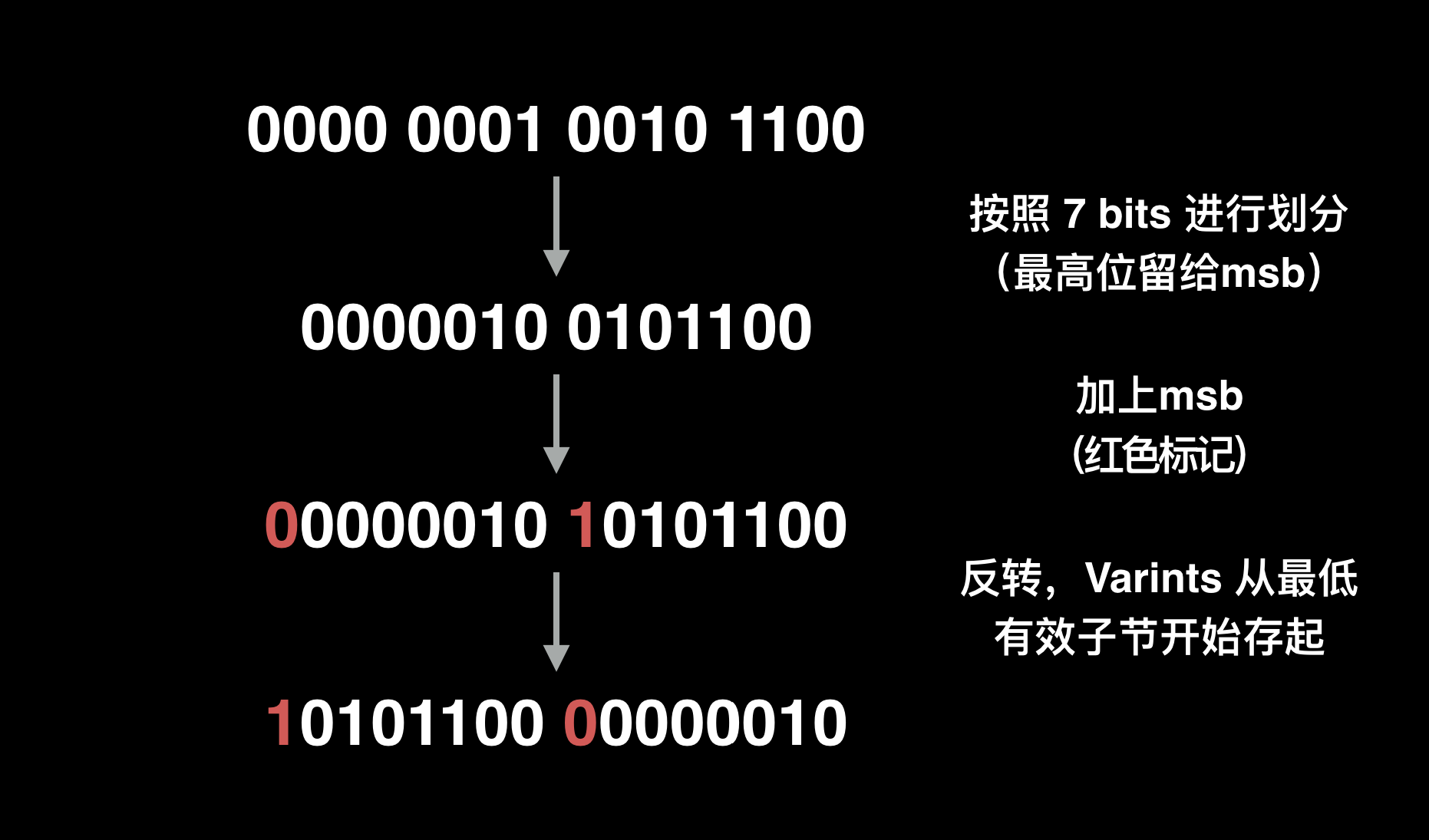
再举个例子,300 的二进制表示为 100101100,通过 Varint 编码后的二进制表示为 10101100 00000010,详细过程如下:
ZigZag
上节介绍了 Varints,我们知道 Varint 在处理小数值的数字很有效,而在处理值较大的数字则占用了多一个子节。对于负数来说,二进制最高有效位为 1,如果用 varint 来编码,无疑要占用比较多的子节。因此我们可以搭配 zigzag 来编码。
ZigZag 编码将有符整型转化成无符的整型,其原理是将最高位的符号位放到最低位(-1 除外),这样大大减少了字节占用。
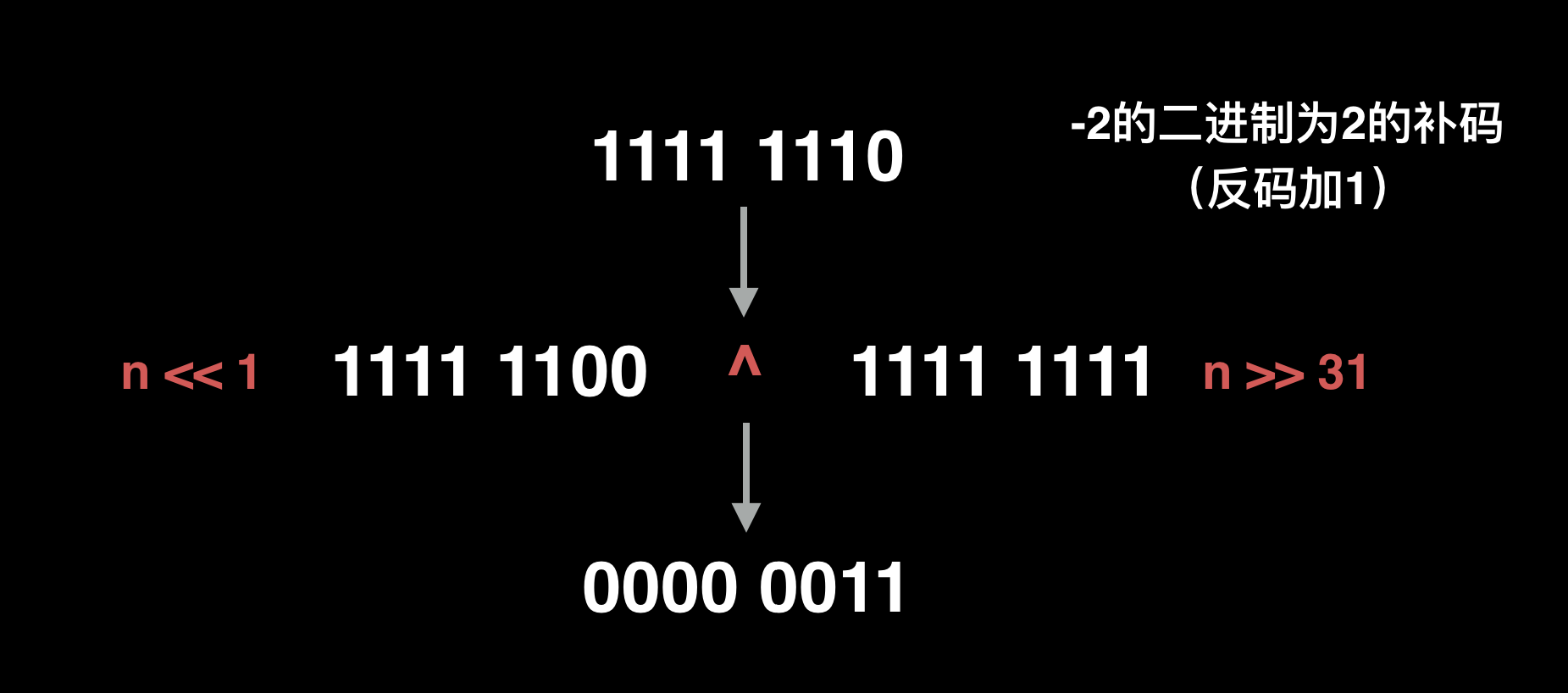
举个例子,-2 的二进制表示为 1111 1110,用zigzag编码,-2 的绝对值为 2,二进制为 0000 0010,将符号位放到最低位,则变成 0000 0011。
公式如下:
- 32 位整型:(n « 1) ^ (n » 31)
- 64 位整型:(n « 1) ^ (n » 63)
Note that the second shift – the (n » 31) part – is an arithmetic shift. So, in other words, the result of the shift is either a number that is all zero bits (if n is positive) or all one bits (if n is negative).
注意这里的位移操作符。如果在位移运算符左边的变量是有符号数,编译产生的汇编指令是算术位移指令,如果该变量是无符号数,编译产生的汇编指令则是逻辑位移指令。对于左移,它们都一样,整个二进制右移,低位补 0;右移则有所区分,算数右移左边补最高符号位,逻辑位移左边补 0。
举个例子,-2 经过 ZigZag 编码后为 3,过程如下:
Protobuf 的编码原理
版本兼容
Protobuf 支持向前向后兼容。向后兼容即升级的解码程序能够正确解析旧版本协议的数据,向前兼容则指旧版本的解码程序能够正确解析新版本协议的数据。如果新的协议新增了字段,旧版本的解析程序是如何自动跳过新字段的呢?
协议,即通信双方约定好的规则。收到数据时,可以根据约定好的规则进行解包。假设我们使用简单粗暴的编解码方法,将结构体定义的成员按类型依此打解包。如下图,我们约定好的协议包括三个字段,类型都为 int32,那解码函数将从接收到的字节流中依次取出 4 个字节并按整型解析。

如果发送方升级了协议,如下图:

很明显,如果旧的解码程序还是按照依次取出 3 个 int32 去解析的话,毫无疑问是错误的(会把结构体 old_message 的成员 d 的值解析成 0x1a )。如果有办法能跳过新增字段,就可以做到兼容,即旧的解码程序能正确解析出旧协议定义的字段,新增字段一律忽略。
Protobuf 采用的方法很简单也很实用,把 tag 和其类型一起打进去字节流,解码程序只要解析出不认识的 tag,就能知道该字段是新协议定义的,再通过其类型可以推断出该字段内容的长度,就能正确的跳过这部分 buffer,继续解析下一个字段。如下图:
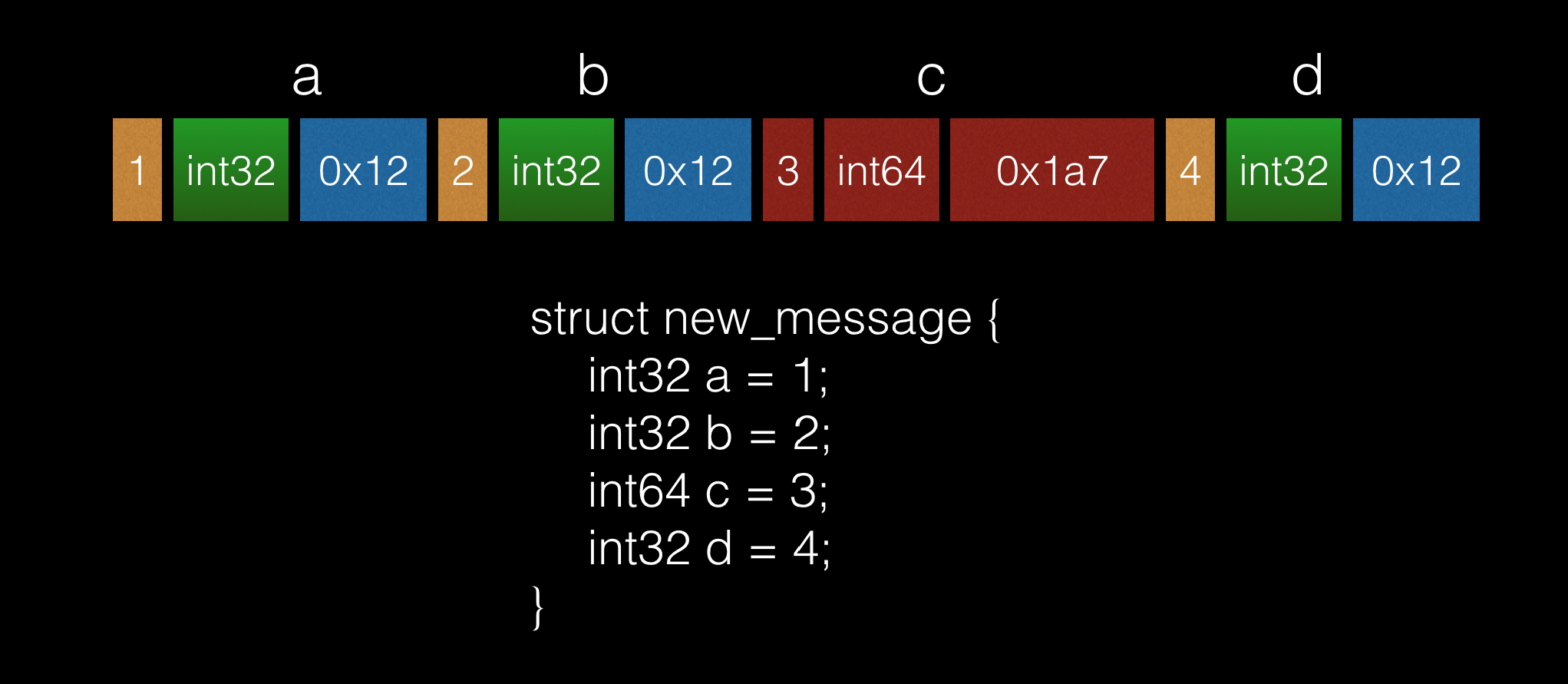
当旧的解码程序解析到 tag 为 3 时,发现在旧协议里找不到该 tag,又从其类型 int 64 知道该 tag 的值占了 8 个字节,于是他跳过这 8 个字节,继续解析剩下的字节流。
实现
Protobuf 的实现中,将每个字段的 key 设为 varint 编码后的 (tag number << 3) | wire_type。即 key 的最低三位表示字段类型,将 key 右移三位后的值表示 tag number。wire_type 如下表格所示:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (deprecated) |
| 4 | End group | groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
如果是 Length-delimited Type,意味着长度不定,这时还需要在 key 后面多写入长度信息(用 varint 编码)。
举个例子:
1
2
3
message Test2 {
required string b = 2;
}
将 b 的值设为 “testing”,protobuf 编码后的字节流为12 07 74 65 73 74 69 6e 67 key 为 0x12,可以算出 tag 值为 2(0x12 » 3), type 为 2 ( 0x12 取最低三位)。下个字节为 0x07 ,该字节表示长度,即长度为 7,因此后续的 7 个字节都为该 tag 的值。
另外 protobuf 还定义了 sint32/sint64 类型。sint32/sin64 类型专门用于编码负数。如果使用 int32/int64 来编码负数, 通过 varint 编码后的 buffer 长达 5/10 个字节。(int32 时占用5个字节,int64时占用10个字节,因为负数的最高位为1,会被当作非常大的整数处理)。
而 sint32/sint64 类型的值会先经过 zigzag 编码,转换成无符号整数,再采用 varint 编码,可以大大减少编码后占用的字节数。
If you use int32 or int64 as the type for a negative number, the resulting varint is always ten bytes long – it is, effectively, treated like a very large unsigned integer. If you use one of the signed types, the resulting varint uses ZigZag encoding, which is much more efficient.
使用建议
- 常用消息字段(尤其是 repeated 字段)的 tag number 尽量分配在 1 ~ 15 之间。tag number 超过 16,key 的编码将占用多一个字节
- 尽可能多的(全部)使用 optional 字段
- 不能修改字段的 tag number
- 不能增删任何 required 字段