本系列文章为阅读《现代操作系统》和《Linux 内核设计与实现》所整理的读书笔记,源代码取自 Linux-kernel 2.6.34 版本并有做简化。
概念
如果能把文件看成是一种地址空间,那么就离理解文件不远了。(文件类似虚拟地址空间,相应的磁盘地址对应内存物理地址,通过 inode 来管理映射关系,类似页表的作用)。
文件系统的实现
文件系统存放在磁盘上。多数磁盘划分为一个或多个区,每个分区有一个独立的文件系统。磁盘的 0 号扇区称为主引导记录(MBR),用来引导计算机。在 MBR 结尾是分区表,给出每个分区的起始和结束地址。
文件系统通常包含了超级块(包含文件系统的关键参数)、空闲空间管理、i节点、根目录以及文件存储区。
文件的实现
文件存储的实现关键问题是记录各个文件分别用到哪些磁盘块。
连续分配
最简单的分配方案是把每个文件作为一连串连续数据块存储在磁盘上。
链表分配
链表分配不会有磁盘碎片的问题,顺序读取非常方便,但随即存取却相当缓慢。而且由于指针占了一些字节,磁盘块存储数据的字节数不再是 2 的整数幂。
在内存中采用的链表分配
将每个磁盘块的指针放在内存的一张表中,可以解决上面的两个不足。随机存取虽然依然需要遍历,但不再需要任何磁盘引用。缺点在于整张表必须放在内存,对大磁盘来说(表太大)不太合适。
i 节点
最后一个解决方案是给每个文件赋予一个 i 节点,包含文件属性和文件块的磁盘地址。只有文件打开时,i 节点才会加载到内存。
目录的实现
对于 i 节点系统,目录项只包括文件名和相应的 i 节点号。查找文件名时,可以在每个目录使用散列表来加快查找速度。另外一种方法是将查找结果放入高速缓存。
虚拟文件系统
UNIX 使用虚拟文件系统的概念,关键思想在于抽象出所有文件系统的共有部分,把这部分代码放在单独的一层,该层调用底层的实际文件系统来管理数据。
Linux 中的实现
虚拟文件系统
虚拟文件系统(VPS)作为内核子系统,为用户空间程序提供了文件系统相关的接口。通过虚拟文件系统,程序可以利用标准的 UNIX 文件系统调用对不同介质的不同文件系统进行读写操作。
通用文件系统接口
VFS 使用户可以直接使用 open()、read() 和 write() 这样的系统调用而无需考虑具体文件系统和实际物理介质。
文件系统抽象层
VFS 抽象层定义了所有文件系统都支持的基本的、概念上的接口和数据结构,因此能衔接各种各样的文件系统。
在内核中,除了文件系统本身外,并不需要了解文件系统的内部细节。例如用户空间程序执行如下的操作:
1
write(f, &buf, len);
该代码将 &buf 指针指向的、长度为 len 字节的数据写入文件描述符 f 对应的文件的当前位置。该用户调用首先被一个通用系统调用 sys_write() 处理,sys_write() 函数要找到 f 所在的文件系统对应的写操作,然后执行该操作。
Unix 文件系统
Unix 使用了四种和文件系统相关的传统抽象概念:文件、目录项、索引节点和安装点(mount point)。从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。文件系统的通用操作包含创建、删除和安装等等。在 Unix 中,文件系统被安装在一个特定的安装点上,该安装点在全局层次结构中被称为命名空间,所有的已安装文件系统都作为根文件系统树的枝叶出现在系统中。
Unix 中,目录属于普通文件,它列出包含在其中的所有文件。因此可以对目录执行和文件相同的操作。
Unix 将文件的相关信息和文件本身着两个概念加以区分,例如访问控制权限、大小、拥有者、创建时间等信息。文件相关信息有时被称为索引节点(inode)。
文件系统的控制信息存储在超级块中,超级块是一种包含文件系统信息的数据结构。我们将文件信息和文件系统的信息统称为文件系统数据元。
Unix 文件系统在他们物理磁盘布局中也是按照上述的概念实现的。文件信息按照索引节点形式存储在单独的块中,控制信息集中存储在磁盘的超级块中。
VFS 对象及其数据结构
VFS 采用的是面向对象的设计思路,使用一族数据结构来代表通用文件对象。VFS 中有四个主要的对象类型:
- 超级块对象,代表一个已安装文件系统
- 索引节点对象,代表一个文件
- 目录项对象,代表一个目录项,是路径的一个组成部分
- 文件对象,代表进程打开的文件
超级块对象
各种文件系统都必须实现超级块,该对象用于存储特定文件系统信息,通常对应存放于磁盘特定扇区中的文件系统超级块或文件系统控制块。对于并非基于磁盘的文件系统,它们会在现场创建超级块并保存到内存中。
超级块对象由 super_block 结构体表示,定义在文件 <linux/fs.h> 中。
索引节点对象
索引节点对象包含了内核在操作文件或目录时需要的全部信息,由 inode 结构体表示,定义在文件 <linux/fs.h> 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
struct inode {
struct hlist_node i_hash;
struct list_head i_list; // 索引节点链表
struct list_head i_sb_list; // 超级块链表
struct list_head i_dentry; // 目录项链表
unsigned long i_ino; // 节点号
atomic_t i_count;
unsigned int i_nlink;
uid_t i_uid;
gid_t i_gid;
dev_t i_rdev; // 实际设备标识符
unsigned int i_blkbits; // 以位为单位的块大小
u64 i_version;
loff_t i_size; // 以字节为单位的文件大小
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
struct timespec i_atime; // 最后访问时间
struct timespec i_mtime; // 最后修改时间
struct timespec i_ctime; // 最后改变时间
blkcnt_t i_blocks; // 文件块数
unsigned short i_bytes; // 使用的字节数
umode_t i_mode; // 访问权限
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
struct mutex i_mutex;
struct rw_semaphore i_alloc_sem;
const struct inode_operations *i_op; // 索引节点操作表
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
unsigned long i_state;
unsigned long dirtied_when; // 第一次弄脏数据的时间
unsigned int i_flags; // 文件系统标识
atomic_t i_writecount; // 写者计数
void *i_private; /* fs or device private pointer */
};
目录项对象
VFS 经常需要执行目录相关的操作,例如路径名查找等。路径名查找需要解析路径中的每一个组成部分。为了方便查找操作,VFS 引入目录项的概念。每个 dentry 代表路径中的一个特定部分。在路径中,包括普通文件在内,每一个部分都是目录项对象。
目录项由对象 dentry 结构体表示,定义在文件 <linux/dcache.h> 中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct dentry {
atomic_t d_count; // 使用记账
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
int d_mounted;
struct inode *d_inode; /* Where the name belongs to - NULL is * negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; // dcache中的所有dentry对象都通过d_hash指针域链到相应的dentry哈希链表中。
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,VFS 根据字符串形式的路径名现场创建它。
目录项状态
目录项对象有三种有效状态:被使用、未被使用和负状态。
一个被使用的目录项对应一个有效的索引节点(d_inode 指向相应的索引节点)并表明该对象存在一个或多个使用者(d_count 为正值)。
一个未被使用的目录项对应一个有效的索引节点(d_inode 指向一个索引节点)但 VFS 当前并未使用它(d_count 为 0)。该目录项对象仍然指向一个有效对象,而且被保留在缓存中以便需要时再使用。
一个负状态的目录项没有对应的有效索引节点(d_inode 为 NULL),因为索引节点已被删除或路径不再正确。
目录项缓存
内核将目录项对象缓存在目录项缓存(dcache)中。目录项缓存包含三个主要部分:
- “被使用的”目录项链表:该链表通过索引节点对象中的 i_dentry 项连接相关的索引节点。一个给定的索引节点可能有多个链接,就可能有多个目录项对象,因此用链表来连接。
- “最近被使用的”双向链表:该链表含有未被使用的和负状态的目录项对象。该链表以时间顺序插入,所以链头的节点是最新数据。当内核必须通过删除节点项回收内存时,会从链尾删除节点项。
- 散列表和相应的散列函数用来快速将给定路径解析为相关目录项对象。
文件对象
文件对象表示进程已打开的文件,由结构体 file 表示,定义在文件 <linux/fs.h> 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct file {
/*
* fu_list becomes invalid after file_free is called and queued via
* fu_rcuhead for RCU freeing
*/
union {
struct list_head fu_list; // 文件对象链表
struct rcu_head fu_rcuhead; // 释放后 rcu 链表
} f_u;
struct path f_path; // 包含目录项
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
const struct file_operations *f_op; // 文件操作表
spinlock_t f_lock; /* f_ep_links, f_flags, no IRQ */
atomic_long_t f_count; // 文件对象使用计数
unsigned int f_flags; //打开文件指定的标志位
fmode_t f_mode; // 文件访问模式
loff_t f_pos; // 文件当前的位移量
struct fown_struct f_owner;
u64 f_version;
struct address_space *f_mapping; // 页缓存映射
};
文件对象通过 f_dentry 指针指向相关的目录项对象,目录项会指向相关的索引节点,索引节点会记录文件是否为脏。
文件系统相关的数据结构
struct file_system_type 用来描述每种文件系统的功能和行为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct file_system_type {
const char *name; /* 文件系统的名字 */
int fs_flags; /* 文件系统类型标志 */
/* 从磁盘读取超级块 */
int (*get_sb) (struct file_system_type *, int,
const char *, void *, struct vfsmount *);
/* 终止访问超级块 */
void (*kill_sb) (struct super_block *);
struct module *owner; /* 文件系统模块 */
struct file_system_type * next; /* 链表中下一个 */
struct list_head fs_supers; /* 超级块对象链表 */
};
当文件系统被实际安装时,将有一个 vfsmount 结构体在安装点被创建。该结构体用来代表文件系统的实例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
struct vfsmount {
struct list_head mnt_hash;
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
int mnt_flags;
/* 4 bytes hole on 64bits arches */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
struct mnt_namespace *mnt_ns; /* containing namespace */
int mnt_id; /* mount identifier */
};
进程相关的数据结构
有三个数据结构将 VFS 层和系统进程紧密联系在一起,分别是:files_struct、fs_struct 和 namespace 结构体。
files_structt 结构体定义在文件 <linux/file.h> 中。该结构体由进程描述符中的 files 域指向。所有与每个进程(per-process)相关的信息如果打开的文件和文件描述符都在其中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct fdtable {
unsigned int max_fds;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
struct rcu_head rcu;
struct fdtable *next;
};
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
int next_fd;
struct embedded_fd_set close_on_exec_init;
struct embedded_fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
fd 数组指针指向已打开的文件对象链表,默认情况下指向 fd_array 数组。因为 NR_OPEN_DEFAULT 等于 32,如果一个进程打开的文件对象超过 32 个,内核将分配一个新数组并将 fd 指针指向它。
下图是 APUE 中进程打开文件的图例:
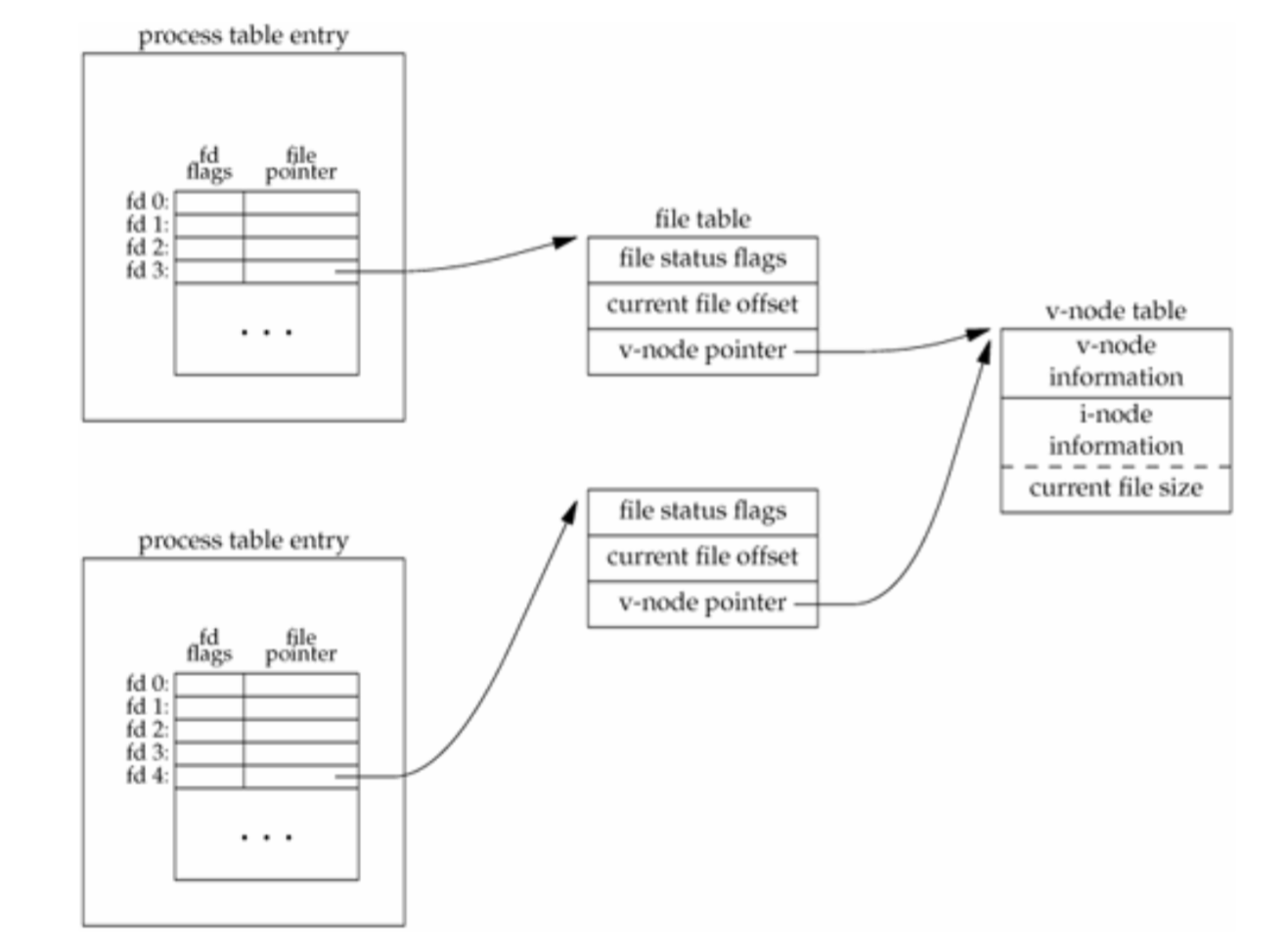
其中 process table entry 表项对应 files_struct 对象,file table 表项对应 file 对象,v-node table 表项可以看成两部分,一部分是文件操作函数的指针,由 file 对象的 f_op 字段指向,另一部分 inode 信息,由 file 对象的 f_dentry 字段指向的目录项对象的 d_inode 关联到相关的 inode 节点:
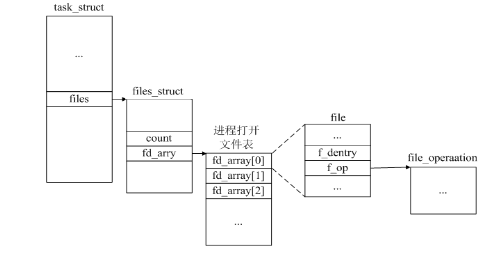
注:上图取自知乎
和进程相关的第二个结构体是 fs_struct。该结构由进程描述符 fs 域指向。它包含文件系统和进程相关的信息,定义在 <linux/fs_struct.h> 中:
1
2
3
4
5
6
7
8
9
10
11
12
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
struct fs_struct {
int users; /* 结构的使用计数 */
rwlock_t lock;
int umask; /* 默认的文件访问权限 */
int in_exec;
struct path root, pwd; /* 根目录和当前目录的目录项对象和安装点对象 */
};
最后一个结构体是 mnt_namespace,定义在 <linux/mnt_namespace.h> 中,由进程描述符中的 namespace 指向。
1
2
3
4
5
6
7
struct mnt_namespace {
atomic_t count; /* 结构的使用计数 */
struct vfsmount * root; /* 根目录的安装点对象 */
struct list_head list; /* 安装点链表 */
wait_queue_head_t poll;
int event;
};
对大多数进程来说,它们的描述符会指向唯一的 files_struct 和 fs_struct 结构体。对于使用克隆标志 CLONE_FILES 或 CLONE_FS 创建的进程,会共享这两个结构体。所以多个进程描述符可能会指向同一个 files_struct 或 fs_struct 结构体。因此每个结构体维护一个 count 域(或 users 域)作为引用计数。
namespace 结构体则不同,默认情况下,所有进程共享同样的命名空间。
https://bean-li.github.io/vfs-inode-dentry/
https://unicornx.github.io/2016/03/20/20160320-lk-vfs/
APUE 对应进程打开文件的图例
块 I/O 层
系统能随机访问固定大小数据片(chunk)的设备被称作块设备。另一种基本的设备类型是字符设备,字符设备按照字符流的方式被有序访问,例如串口和键盘。
解剖一个块设备
块设备中最小的可寻址单元是扇区(sector)。扇区大小一般是 2 的整数倍,最常见的大小是 512 个字节。扇区的大小是设备的物理属性,扇区是所有块设备的基本单元,块设备无法对它还小的单元进行寻址的操作。
最小逻辑可寻址单元是块(block)。块是文件系统的抽象,只能基于块来访问文件系统。虽然物理磁盘寻址是按照扇区级进行的,但内核执行的所有磁盘操作都是按照块进行的。对块大小的要求是:必须是扇区大小的 2 的整数倍,并且要小于页面大小。所以块大小通常为 512 字节、1K 或 4K。
缓冲区和缓冲区头
当块被调入内存时,它要存储在一个缓冲区中。缓冲区相当于磁盘块在内存中的表示。由于内核在处理数据时需要一些相关的控制信息(比如块属于哪一个块设备,对于哪个缓冲区等),所以每个缓冲区都有一个对应的描述符,由 buffer_head 结构体表示,称为缓冲区头,在 <linux/buffer_head.h> 中定义。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
struct buffer_head {
unsigned long b_state; /* buffer state bitmap (see above) */
struct buffer_head *b_this_page;/* circular list of page's buffers */
struct page *b_page; /* the page this bh is mapped to */
sector_t b_blocknr; /* start block number */
size_t b_size; /* size of mapping */
char *b_data; /* pointer to data within the page */
struct block_device *b_bdev;
bh_end_io_t *b_end_io; /* I/O completion */
void *b_private; /* reserved for b_end_io */
struct list_head b_assoc_buffers; /* associated with another mapping */
struct address_space *b_assoc_map; /* mapping this buffer is
associated with */
atomic_t b_count; /* users using this buffer_head */
};
与缓冲区对应的磁盘物理块由 b_blocknr 域索引,该值是 b_bdev 域指明的块设备中的逻辑块号。
与缓冲区对应的内存物理页由 b_page 域表示,另外 b_data 域直接指向相应的块(它位于 b_page 域所指明的页面的某个位置上)。块的大小由 b_size 域表示,所以块在内存中的起始位置在 b_data 处,结束位置在 (b_data + b_size) 处。
bio 结构体
内核中块 I/O 操作的基本容器由 bio 结构体表示,定义在文件 <linux/bio.h> 中。
每个块 I/O 请求都通过一个 bio 结构体表示。每个请求包含了一个或多个块,这些块存储在 bio_vec 结构体数组中。这些结构体描述了每个片段在物理页中的实际位置,并且像 vector 一样被组织在一起。I/O 操作的第一个片段由 b_io_vec 结构体所指向,共有 bi_vcnt 个片段。当块 I/O 层开始执行请求、需要使用各个片段时,bi_idx 域会不断更新,从而指向当前片段。
buffer_head 和 bio 结构体之间存在明显差别。bio 结构体代表的是 I/O 操作,它可以包含内存中的一个或多页;而另一方面,buffer_head 结构体代表的是一个缓冲区,它描述的仅仅是磁盘中的一个块。因为缓冲区头关联的是单独页中的单独磁盘块,所以它可能会引起不必要的分割,将请求按块为单位划分。bio 则不需要连续存储区,也不需要分割 I/O 操作。
请求队列
块设备将它们挂起的块 I/O 请求保存在请求队列中,该队列由 reques_queue 结构体表示,定义在 <linux/blkdev.h> 中,包含一个双向请求链表以及相关控制信息。请求队列表中的每一项都是一个单独的请求,由 request 结构体表示。一个请求可能要操作多个连续的磁盘块,所以每个请求可以由多个 bio 结构体组成。
I/O 调度程序
磁盘寻址是整个计算机中最慢的操作之一,缩短寻址时间是提高系统性能的关键。为了优化寻址操作,内核会在提交任务前先执行合并与排序的预操作。在内核中负责提交 I/O 请求的子系统称为 I/O 调度程序。
I/O 调度程序的工作
I/O 调度程序的工作是管理块设备的请求队列。I/O 调度程序通过合并和排序来减少磁盘寻址时间。
Linus 电梯
第一个 I/O 调度程序被称为 Linus 电梯。当有新的请求加入队列时,会先检查每一个挂起的请求是否可以和新请求合并。Linus 电梯 I/O 调度程序可以执行向前和向后合并。如果合并失败,那就需要寻找可能的插入点。如果找到就插入,如果没合适的位置,那么新请求就被加入到队列尾部。另外如果队列中有驻留时间过长的请求,那么新请求也将被加入到队列尾部,即使插入后还要排序。这是为了避免由于访问相近磁盘位置的请求太多,从而造成访问磁盘其他位置的请求难以得到执行机会。
最终期限 I/O 调度程序
最终期限 I/O 调度程序中,每个请求都有一个超时时间。默认情况下,读请求的超时时间是 500 毫秒,写请求的超时时间是 5 秒。最终期限 I/O 调度请求类似于 Linus 电梯,也以磁盘物理位置次序维护请求队列,这个队列称为排序队列。但同时也会根据请求类型将它们插入到额外队列中。读请求按次序被插入特定的读 FIFO 队列中,写请求被插入到特定的写 FIFO 队列中。一般情况下,调度程序从排序队列头部取出请求,再推入到派发队列中。如果在写/读 FIFO 队列头的请求超时,那么调度程序便从 FIFO 队列中提取请求。
页高速缓存和页回写
页高速缓存是 Linux 内核实现的一种主要磁盘缓存。它主要用来减少对磁盘的 I/O 操作。具体来讲,是通过把磁盘中的数据缓存到物理内存,把对磁盘的访问变成对物理内存的访问。
页高速缓存是由 RAM 中的物理页组成,每一页都对应磁盘多个块。每当内核开始执行一个页 I/O 操作时,首先会检查需要的数据是否在高速缓存中,如果在,则直接使用高速缓存中的数据。
也可以通过块 I/O 缓冲区把独立的磁盘块与页高速缓存联系在一起。通过缓存磁盘块以及缓冲块 I/O 操作,页高速缓存同样可以减少块 I/O 操作期间的磁盘访问量。这种缓存通常称为“缓冲区高速缓存”,也是页高速缓存中的一部分。
页高速缓存
页高速缓存包含了最近被访问过的文件的全部页面,在执行 I/O 操作前,内核会检查数据是否已经在页高速缓存中了,如果在,则不再需要从磁盘读取数据。
address_space 对象
一个物理页可能由多个不连续的物理磁盘块组成,所以在页高速缓存中检测特定数据是否已经被缓存是件非常困难的工作。
Liunx 页高速缓存使用 address_space 结构体描述页高速缓存中的页面。该结构定义在 <linux/fs.h>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
unsigned int i_mmap_writable;/* count VM_SHARED mappings */
struct prio_tree_root i_mmap; /* tree of private and shared mappings */
struct list_head i_mmap_nonlinear;/*list VM_NONLINEAR mappings */
spinlock_t i_mmap_lock; /* protect tree, count, list */
unsigned int truncate_count; /* Cover race condition with truncate */
unsigned long nrpages; /* number of total pages */
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
struct backing_dev_info *backing_dev_info; /* device readahead, etc */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
struct address_space *assoc_mapping; /* ditto */
};
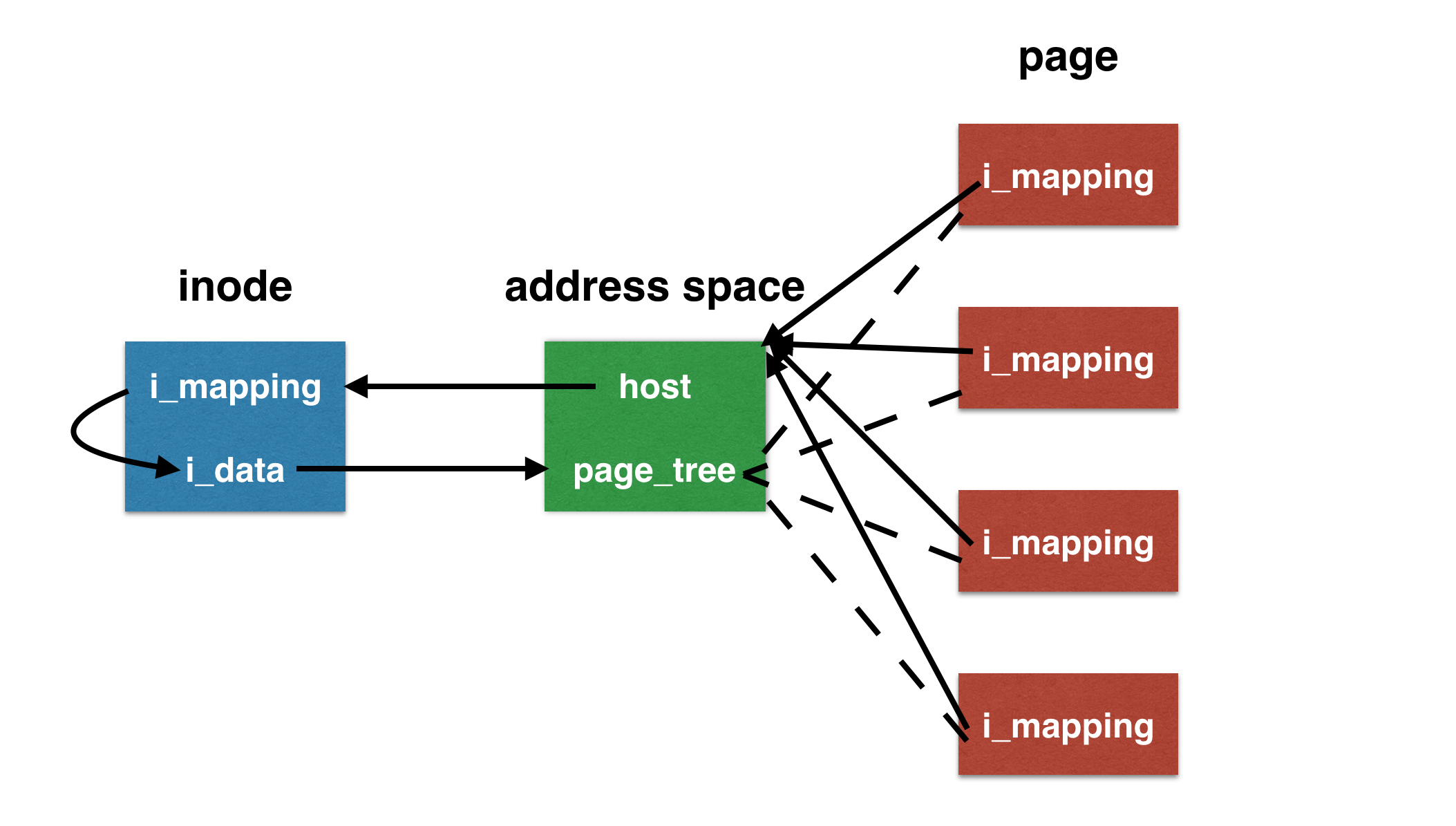
i_mmap 字段是个优先搜索树,它的搜索范围包含了在 address_space 中所有共享和私有的映射页面。address_space 结构往往会和某些内核对象关联。通常会与一个索引节点(inode)关联,这时 host 域就指向该索引节点,该索引节点的 i_mapping 域指向到 address_space 对象,方便查找自身文件数据是否已经缓存。
a_ops 域指向地址空间对象中的操作函数表。
struct page 中有两个字段:mapping 和 index。其中 mapping 指向该页所有者的 address_space,index 字段表示所有者地址空间中以页大小为单位的偏移量。用这两个字段就能在页高速缓存中查找。
页高速缓存通过两个参数:address_space 对象和一个偏移量进行搜索。每个 address_space 对象都有唯一一个基树,保存在 page_tree 结构体中。基树是一个二叉树,只要指定了文件偏移量,就可以在基树中迅速检索到希望的数据。
inode、address space 和 page 三者的关系如下图:
Linux 中的 I/O 机制
Buffered I/O
Buffered I/O 指的是在内核和用户程序之间设置了一层缓冲区,用来提高IO读写的效率:
- 读取:硬盘—>内核缓冲区—>用户缓冲区—>用户程序
- 写回:用户程序—>用户缓冲区—>内核缓冲区—>硬盘
Unbuffered I/O
Unbuffered I/O 没有用户缓冲区,注意内核缓冲区仍然存在:
- 读取:硬盘—>内核缓冲区—>用户程序
- 写回:用户程序—>内核缓冲区—>硬盘
Direct IO
Direct I/O 是真正的什么缓冲区都没有,直接与硬盘交互:
- 读取:硬盘—>用户程序
- 写回:用户程序—>硬盘
使用带有内核缓冲区的 I/O(Buffer I/O 和 Unbuffer I/O),DMA 方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存直接写回到磁盘上,而不能直接在应用程序地址空间和磁盘之间进行数据传输。数据在传输过程中需要在应用程序地址空间和页缓存之间进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
Direct I/O 最主要的优点就是通过减少操作系统内核缓冲区和应用程序地址空间的数据拷贝次数,降低了对文件读取和写入时所带来的 CPU 的使用以及内存带宽的占用。