本系列文章是对 MIT 6.824 课程的学习笔记。
Raft
Introduction
Raft 是用于管理复制日志的一致性算法。为了方便理解,Raft 将一致性算法分解为几个关键模块:Leader 选举、日志复制和安全性,同时通过更强的一致性来减少需要考虑的状态。
一致性算法允许一组机器像一个整体一样工作,即使其中一些机器挂掉。一致性算法在构建大规模可信赖系统中扮演重要的角色。
Raft 和许多一致性算法类似,但他也有自己的新特性:
-
Strong leader
Raft 使用比其他一致性算法更强的 leadership 形式。举例来说,log entries 只能从 leader 发往其他 server。
-
Leader election
Raft 使用随机 timer 来选举 leader,简洁地解决了冲突的问题。
-
Membership changes
Raft 使用 joint consensus 的方式来处理成员变化的问题。在变迁的过程中,两个不同的配置可以共存,以此来实现在变迁过程中集群仍然能持续运转。
Replicated state machines 通常用 replicated log 实现。一致性算法起的作用是保证多个 replicas 上的 replicated log 一致。
实际系统中使用的一致性算法通常有下列特性:
-
安全性保证(绝对不会返回一个错误的结果)
在非拜占庭错误情况下,网络延迟、分区、丢包、冗余和乱序等错误都可以保证不返回错误的结果。
-
可用性
集群中只要大多数的机器可运行并且能够相互通信、和客户端通信,服务就可用。
-
不依赖时序来保证一致性
-
通常情况下,小部分 slow servers 不会影响系统整体的性能
Raft basics
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tells servers when it is safe to apply log entries to their state machines
Raft 在任何时候都保证以下的特性:
-
Election Safety: at most one leader can be elected in a given term.
-
Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries.
-
Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
-
Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
-
State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Raft 中每个 server 在任意时刻都处于 leader、follower、candidate 这三种状态之一。Followers 被动的接收 leader 或 candidate 的请求,leader 处理所有客户端请求,candidate 则起了选举 leader 的角色。
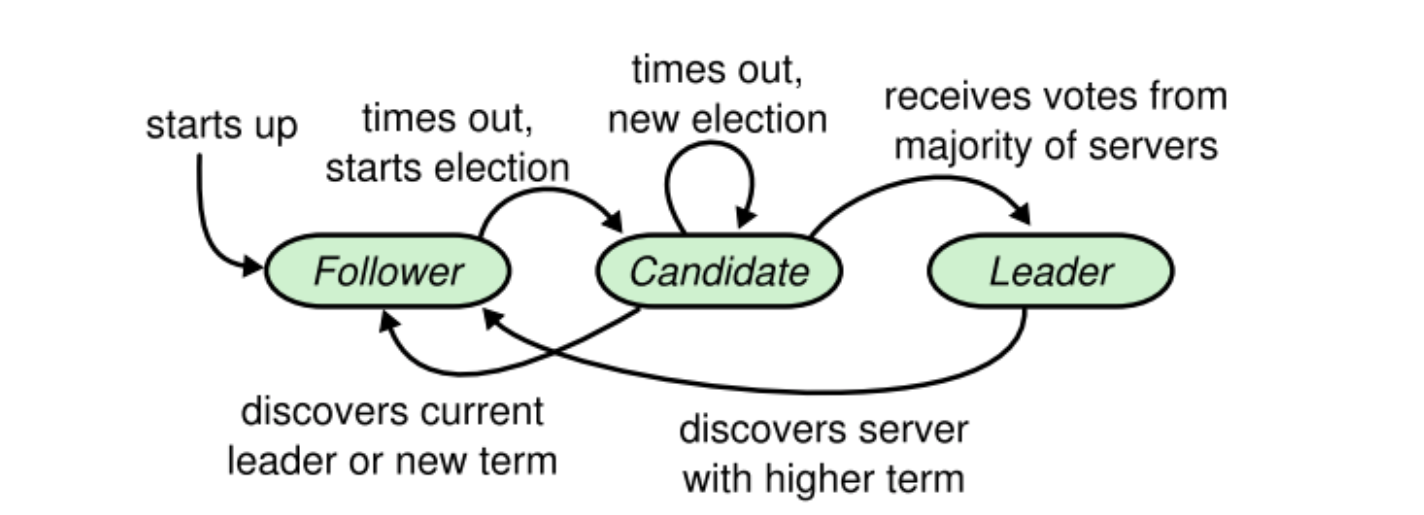
Raft 把时间划分为任期(Terms),并保证每个任期内只有一个 leader。
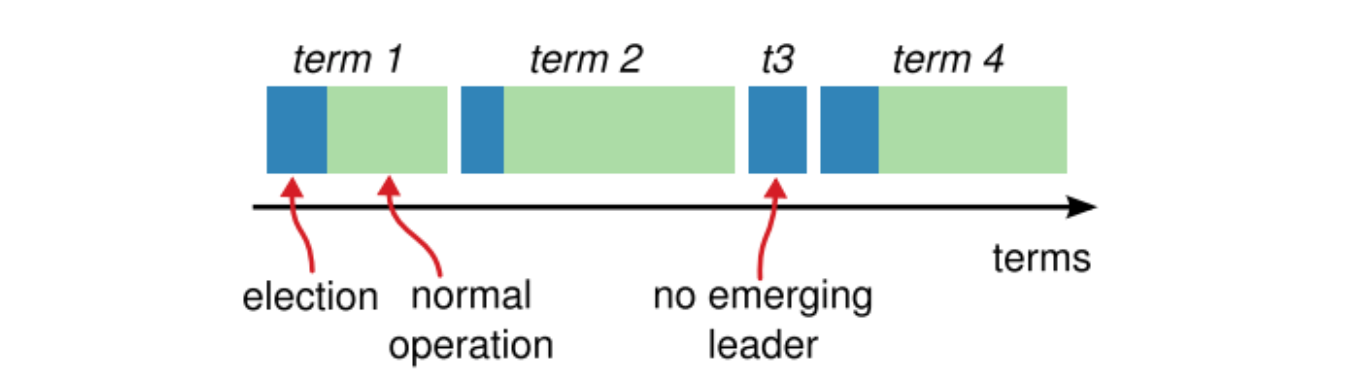
Terms act as a logical clock in Raft, and they allow servers to detect obsolete information such as stale leaders. Each server stores a current term number, which increases monotonically over time. Current terms are exchanged whenever servers communicate
Raft 服务器之间使用 RPC 进行通信,RequestVote RPC 用于选举,AppendEntries 用于 leader 向 followers 复制日志和心跳。
Log replication
Raft 的日志机制维护下面两个特性:
- If two entries in different logs have the same index and term, then they store the same command.
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
Safty
在任何 leader-based 的一致性算法中,leader 都必须存储所有已经提交的日志条目。Raft 使用了一种简单的办法,保证之前任期中已经提交的日志都会出现在新的 leader 中,不需要将这些日志传给新的 leader。这意味着日志的传送是单向的从 leader 发往 followers,并且 leader 从不覆盖本地已经存在的日志。
Raft 在投票过程中只允许包含全部已提交日志的 server 当选 leader。Raft 通过比较日志中最后一条日志条目的索引值和任期来判断哪份日志更新。任期大的日志更加新,如果任期相同,那么日志索引值更大的新。
Leader 不能断定之前任期里的日志条目被保存到大多数服务器上的时候就一定已经提交了。(请看论文的 figure 8)Raft 永远不会通过计算副本数目的方式提交一个之前任期内的日志条目。只有当前任期里的日志条目是通过计算副本数目的方式被提交。一旦当前任期的日志条目以这种方式被提交,那么由于日志匹配特性,之前的日志条目也都会被间接的提交。
Timing and availability
Raft 要求系统满足以下时间限制:
1
broadcastTime ≪ electionTimeout ≪ MTBF
BroadcastTime 指的是并行发送 RPCs 给集群中的其他服务器并接收到响应的平均时间。MTBF 是单台服务器两次故障之间的平均时间。
Raft 的 RPCs 通常耗时在 0.5ms 到 20ms 之间。因此 electionTimeout 最好处于 10ms 到 500ms 之间。
Cluster membership changes
为了保证配置修改机制的安全,在转换的过程中同一个任期中任何一个时间点都不能出现超过一个 leader。
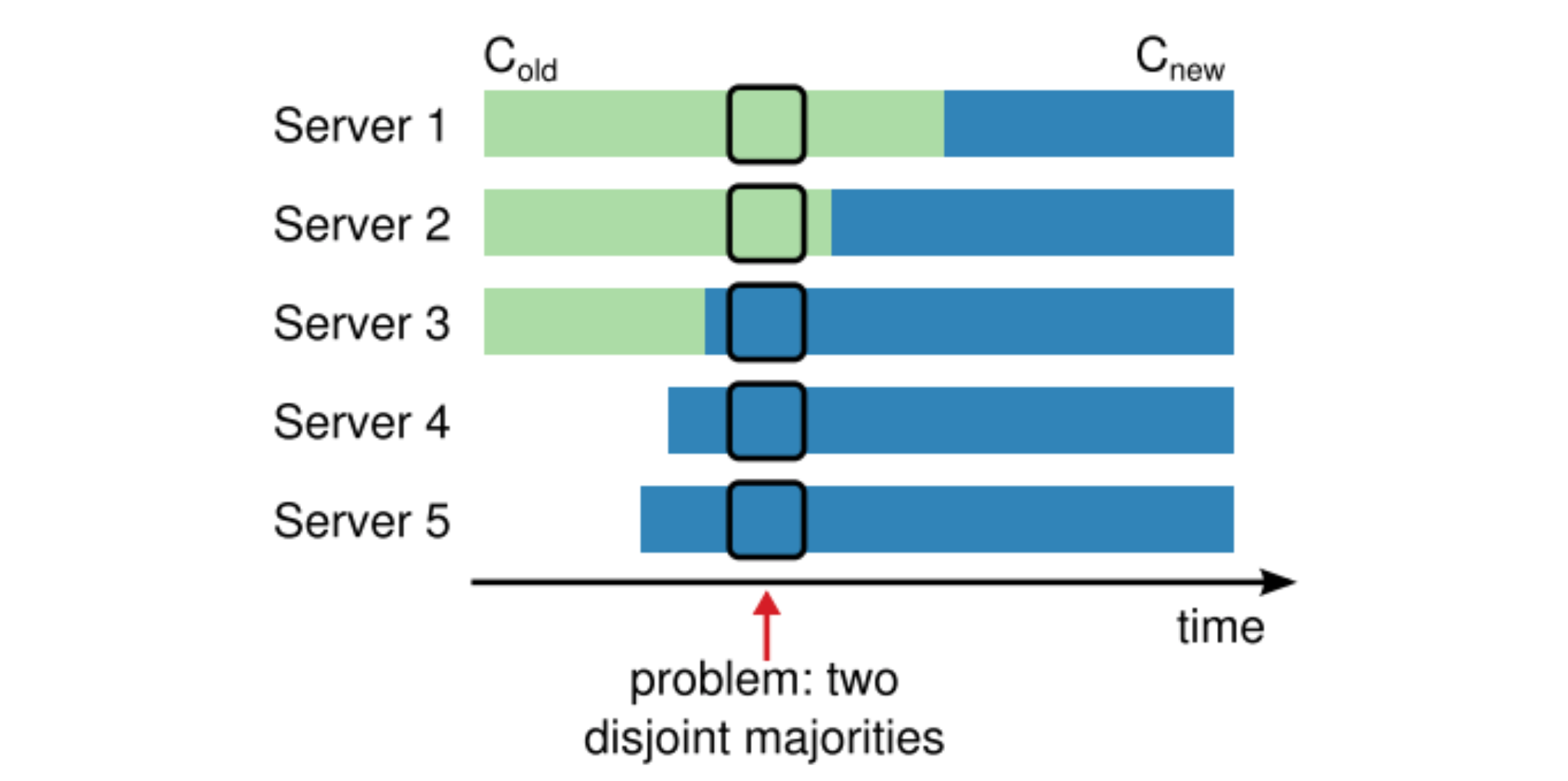
Raft 使用 two-phase 的方式来保证安全性。集群首先切换到过渡的配置,我们称其为 joint consensus。一旦 joint consensus 被提交,集群再切换到新的配置。Joint consensus 是新老配置的结合:
- 日志条目被复制给集群中新、老配置的所有服务器
- 新、旧配置的服务器都可以成为领导人
- Agreement (for elections and entry commitment) 需要分别在两种配置上获得大多数的支持
集群配置以特殊的日志条目保存在 replicated log 中来存储和通信,下图展示了配置转换的过程。一旦一个服务器将新的配置日志条目添加到本地日志中,它就会用这个配置来做决定(服务器总是使用最新的配置,无论该配置是否已经被提交)。这意味着 leader 要使用 C-old,new 的规则来决定日志条目 C-old,new 什么时候需要被提交。
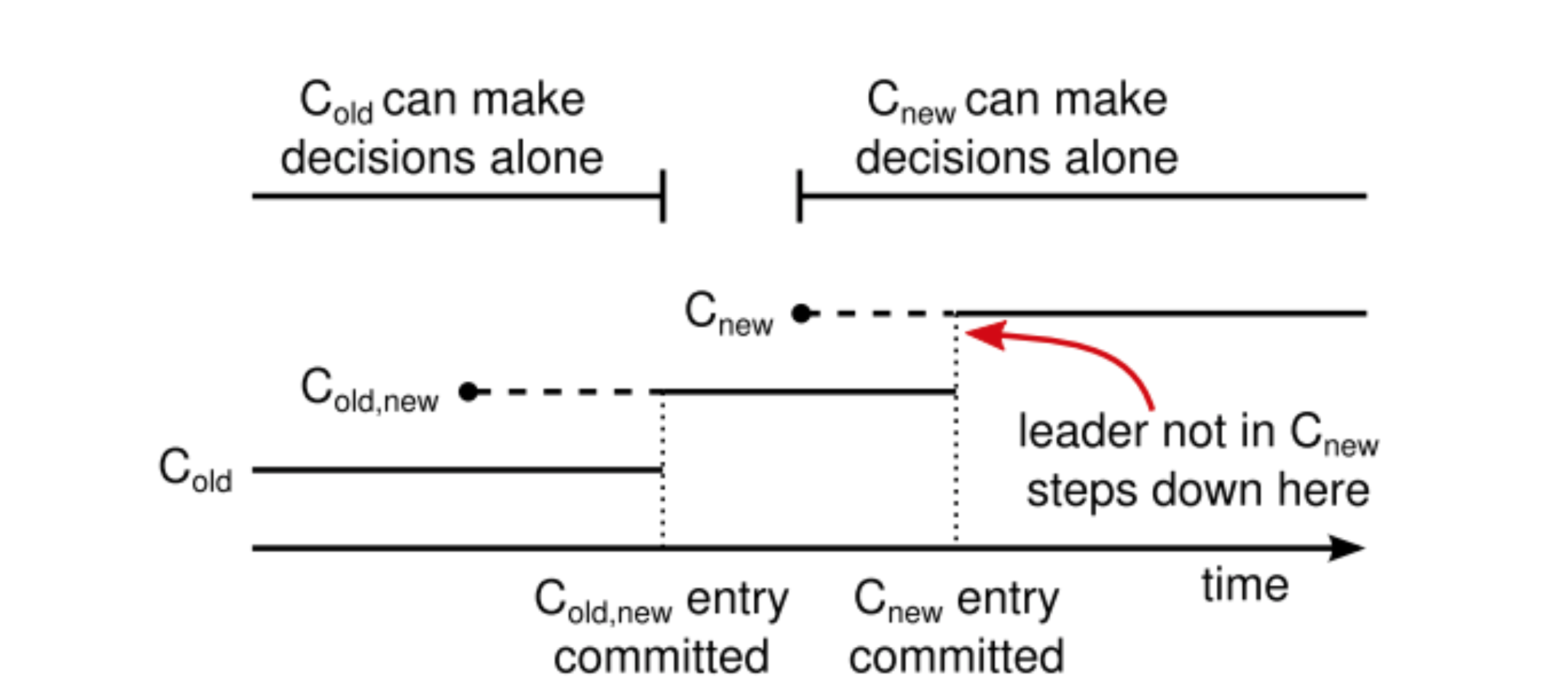
一旦 C-old,new 被提交,那么无论是 C-old 还是 C-new 都不能单独做出决定,并且 Leader Completeness 的特性保证了只有拥有 C-old,new 日志条目的服务器才有可能被选举为 leader。这时 leader 创建一条 C-new 配置的日志条目并复制给集群就是安全的了,每个服务器在见到新的配置的时候就会立即生效。当新的配置在 C-new 的规则下被提交,不在新的配置内的服务器就可以关闭了。
Client interaction
Raft 的目标是要实现 linearizable semantics(each operation appears to execute instantaneously, exactly once, at some point between its invocation and its response) 但 Raft 是可能执行同一条命令多次的。解决方法是客户端对于每一条指令都赋予一个唯一的序列号,状态机记录每条指令最新的序列号和相应的响应。如果接收到一条指令其序列号已经被执行了,那么就立即返回响应,无需重复执行指令。
只读的操作可以直接处理而不需要写入日志,但可能返回脏数据。Raft 采用额外的机制在不写入日志的情况下保证读操作的正确性:
- Leader 必须知道最新的被提交日志。Raft 中通过 leader 在任期开始的时候提交一个空白的日志条目到日志中去来实现。
- Leader 在处理只读的请求之前需要检查自己是否已经被废黜了。Raft 中通过让 leader 在响应只读请求之前,先和集群中的大多数节点交换一次心跳信息来处理这个问题。
Conclusion
Raft makes a few design choices that sacrifice performance for simplicity:
-
Raft follower rejects out-of-order AppendEntries RPCs
Rather than saving for use after hole is filled. Might be important if network re-orders packets a lot And makes leader->follower RPC pipelining harder
-
Snapshotting is wasteful for big slowly-changing states
A slow leader may hurt Raft, e.g. in geo-replication
Experience suggests these have a big effect on performance:
- Disk writes for persistence
- Message/packet/RPC overhead
- Need to execute logged commands sequentially
- Fast path for read-only operations
Appendix
https://thesecretlivesofdata.com/raft/
https://thesquareplanet.com/blog/students-guide-to-raft/