PyTorch 的 dispatch 机制比较复杂,在深入源码之前,建议先学习 Let’s talk about the PyTorch dispatcher 这篇文章,对源码中各个类的角色有初步的了解。本文是对该文章的精简翻译,图片也取自该文章。
背景
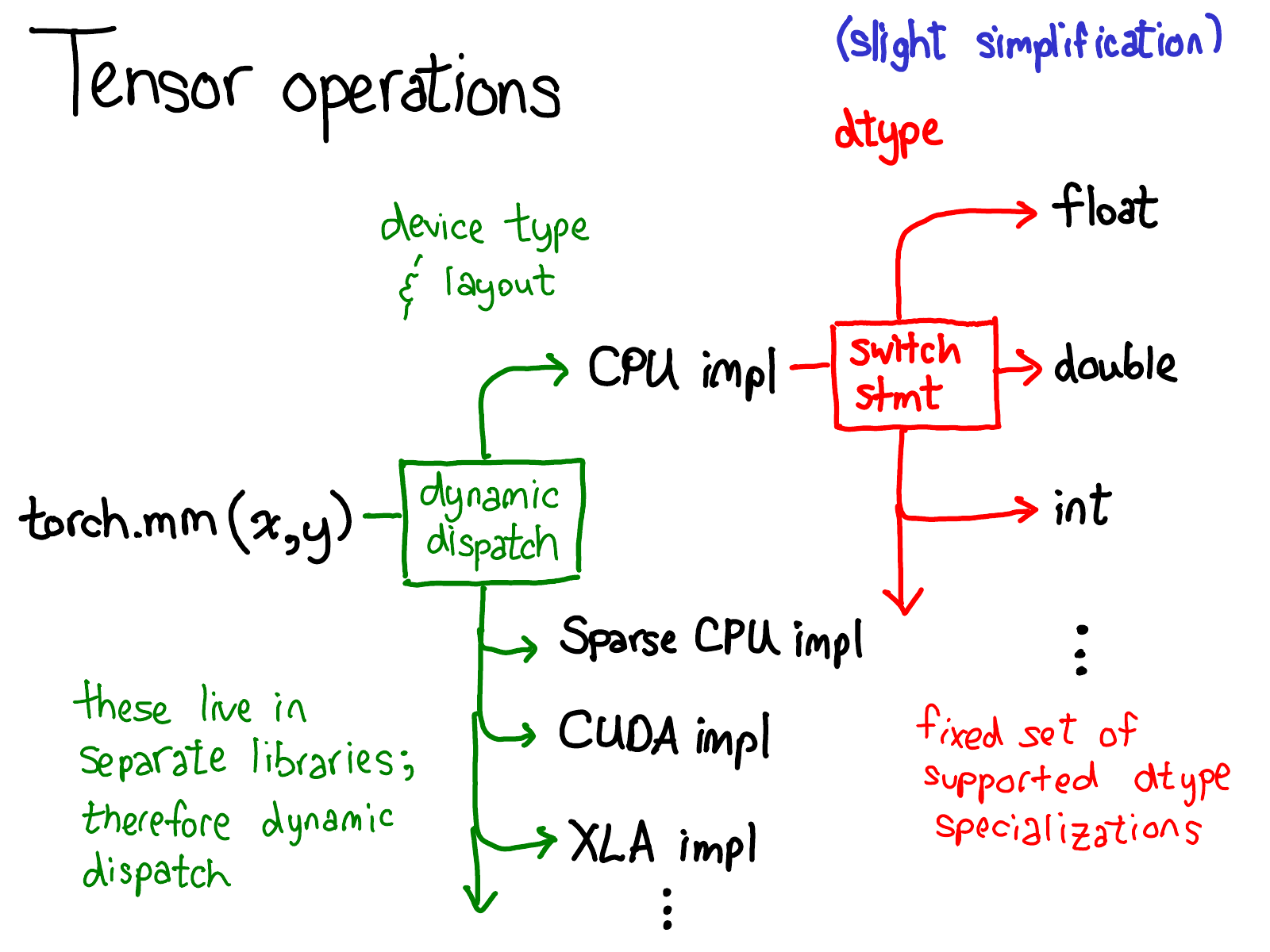
当调用torch.mm时,会发生两次 dispatch:
- 第一次 dispatch 基于 input tensor 的设备类型和 layout 进行的,以确定要调用的特定实现。这是一个动态调度,类似于 c++ 中调用虚函数,不同内核的实现可能存在于不同的库中,例如 libcaffe2.so 和 libcaffe2_gpu.so
- 第二次 dispatch 基于所涉及的数据类型(dtype)进行的,这个调度只是一个简单的 switch 语句(静态调度),用于支持内核选择的任何数据类型。实现浮点数乘法的 CPU 代码(或者可能是 CUDA 代码)与整数乘法的代码是不同的
Dispatcher & DispatchKeySet
Dispatcher:reimplemented vtables
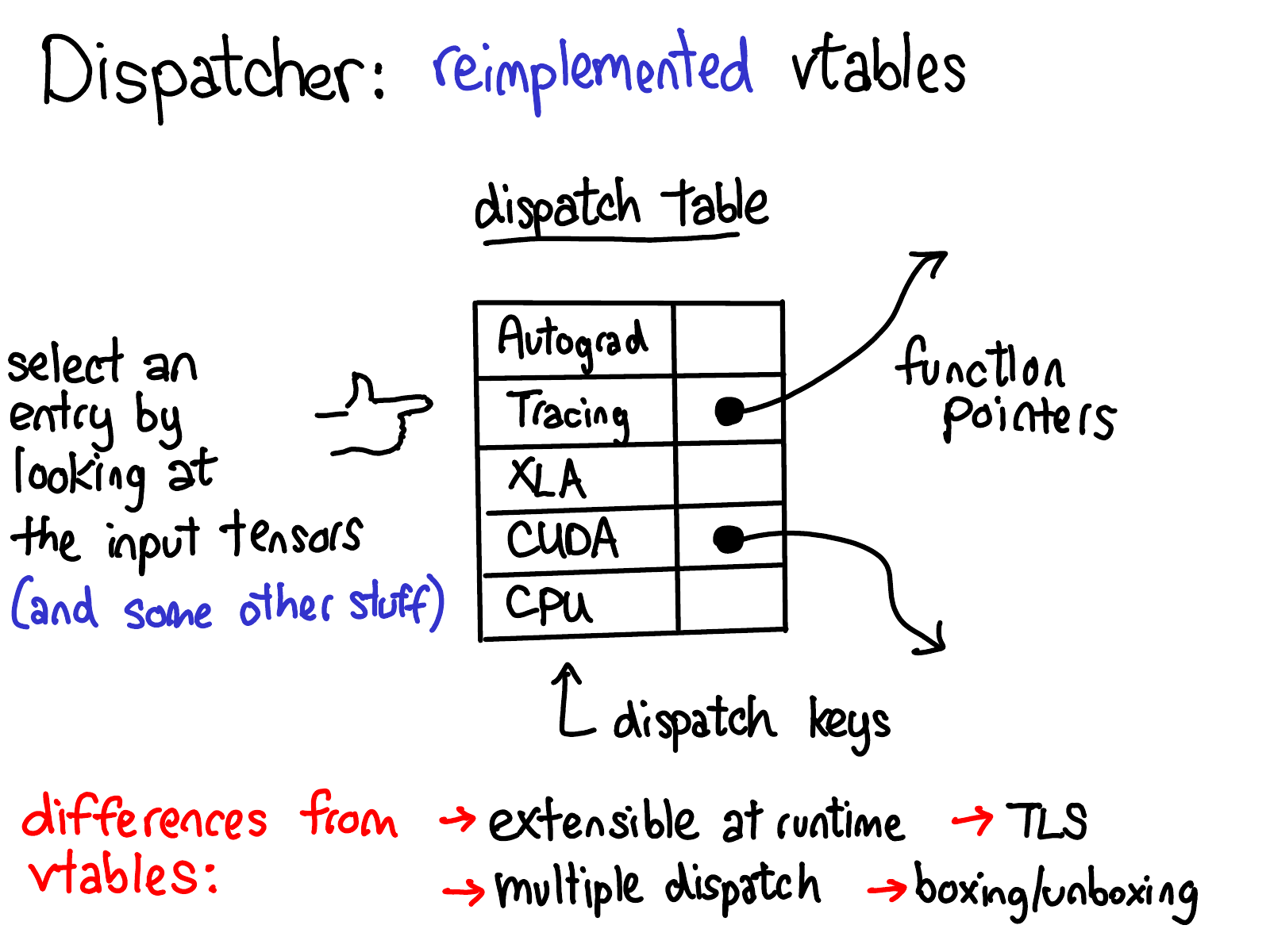
对于每个 operator,dispatcher 维护一个函数指针表(dispatch table),为每个 dispatch key 提供相应的实现。从图表中,可以看到 dispatch key 有 CPU、CUDA、XLA 以及 autograd、tracing 等。Dispatcher 的任务是基于输入张量和其他一些信息计算出一个调度键(dispatcher key),然后间接跳转到表中指向的函数。
这里的实现类似于 C++ 虚函数表,但有下面几点不同:
- Dispatch table 是针对每个 operator 分配的,而虚函数表是针对每个类分配的。这意味着可以通过分配一个新的调度表来简单地扩展支持的操作符集。在 PyTorch 中,大部分的可扩展性在于定义新的操作符(而不是新的子类)因此采用的是 dispatch table 的实现方式而不是虚函数表的实现方式
- Dispatch key 的计算考虑了 operator 的所有参数(multiple dispatch)以及线程本地状态(TLS)。这与虚函数表不同,虚函数表只关注 this 对象
DispatchKeySet
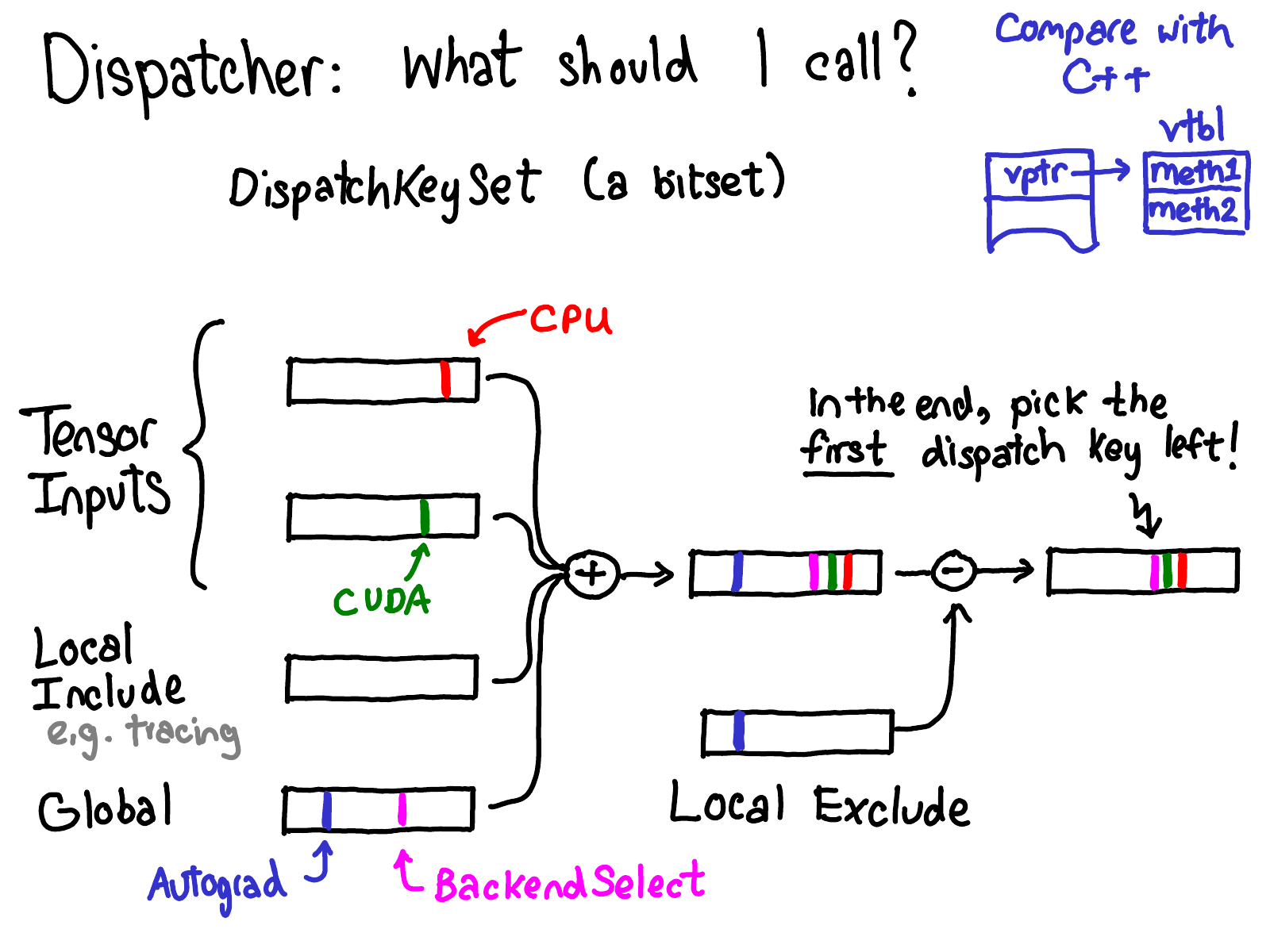
PyTorch 中使用 dispatch key set 对 dispatch key 的计算进行抽象。Dispatch key set 是 dispatch key 的位集合(bitset)。PyTorch 将以下来源的 dispatch key set 进行合并,得到最终的调度键集合。然后选择集合中的第一个 dispatch key(dispatch key 按某种优先级隐式排序)作为调度目标:
- 每个 input tensor 都会贡献一个 dispatch key set,这些调度键可能是 CPU,告诉 PyTorch 所涉及 tensor 是 CPU tensor,应该由 dispatch table 上的 CPU handler 处理
- 本地包含集(local include set),用于“模态”功能,例如追踪,它与任何张量都没有关联
- 全局集(global set),包含始终被考虑的 dispatch keys
除此之外还有一个本地排除集(local exclude set),用于从调度中排除 dispatch key。一个常见的模式是某个处理程序处理一个 dispatch key,然后通过本地排除集将该 dispatch key 屏蔽,这样后续就不会再处理该 dispatch key。
Operator Registration
有三种注册 operator 的方式,如下图:

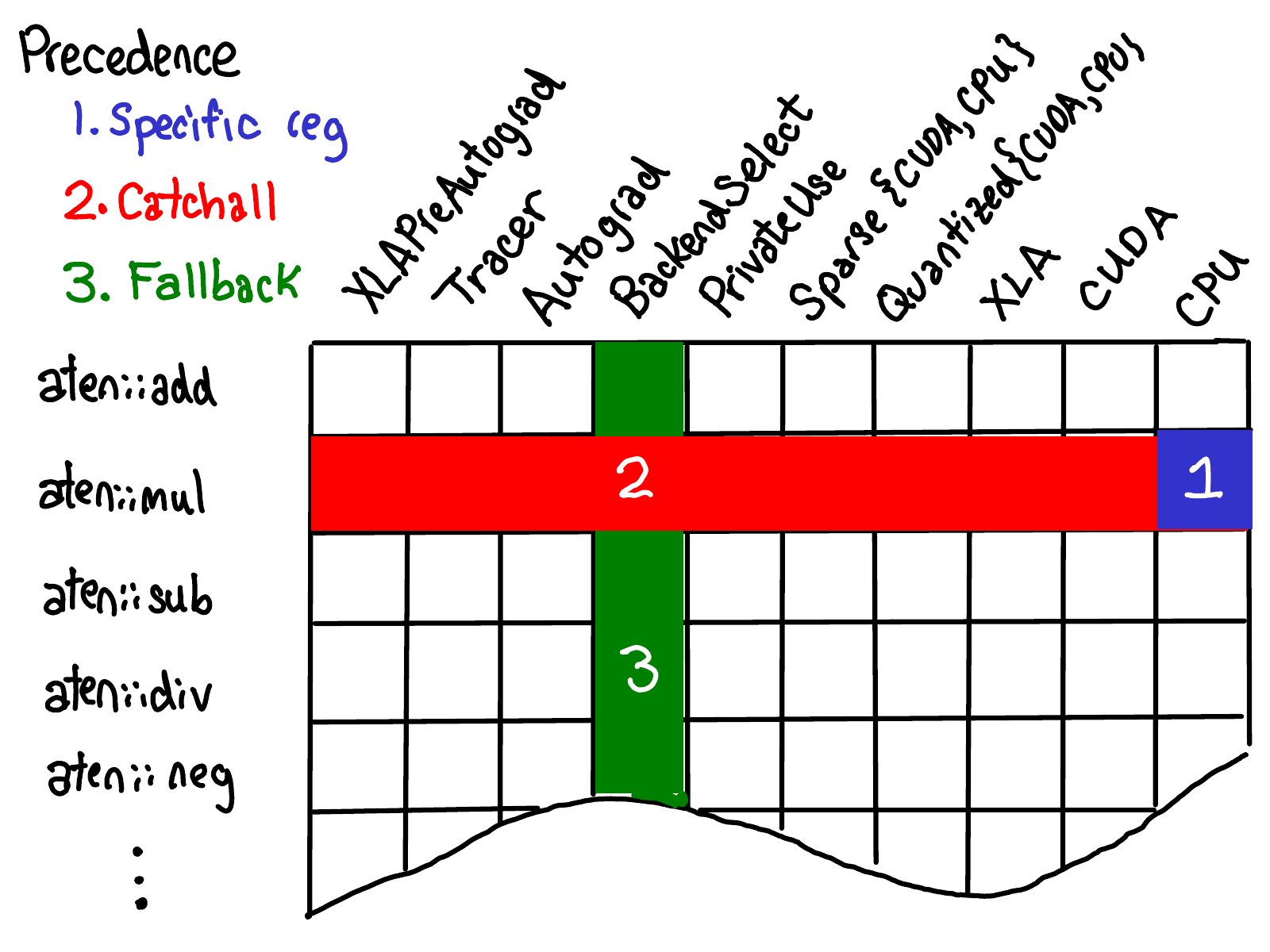
为了方便说明,可以用网格的形式来可视化 dispatch table:
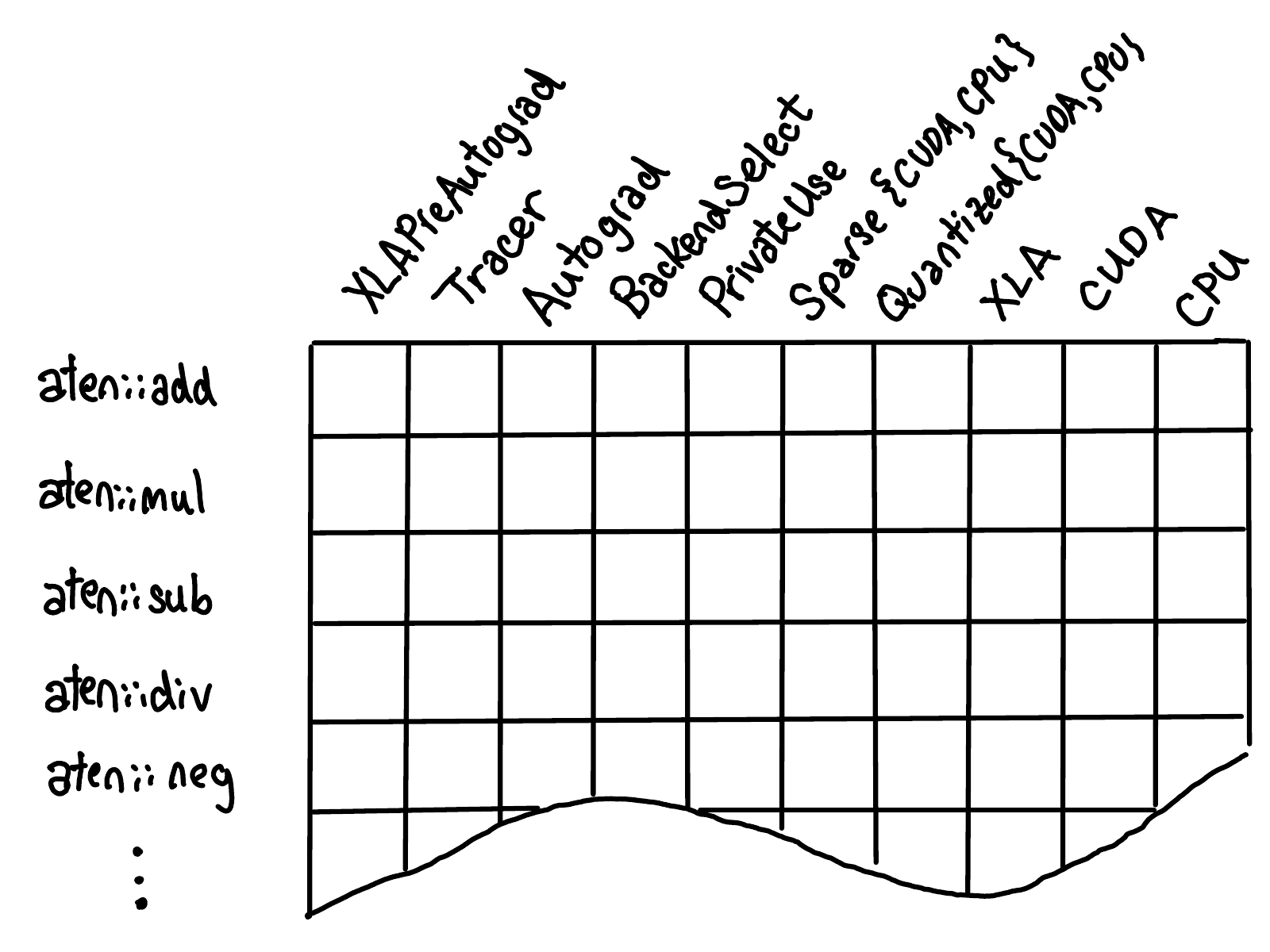
纵轴是 PyTorch 中支持的 operator,横轴是 dispatch key。operator 的注册过程即在这两个轴上填充对应的 implementation 单元格。
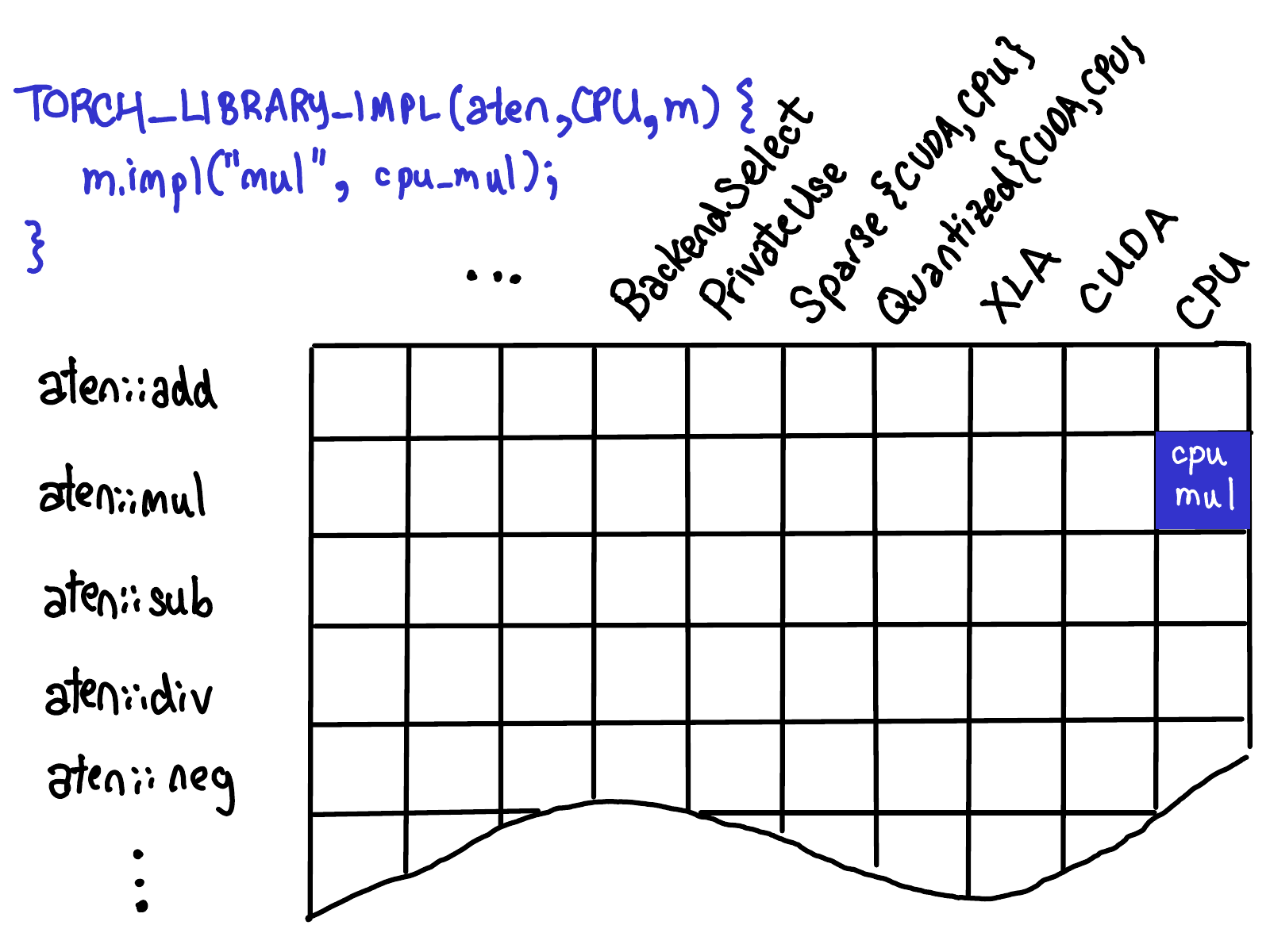
当在特定的调度键上为单个运算符注册一个内核时,如下图的蓝色部分:
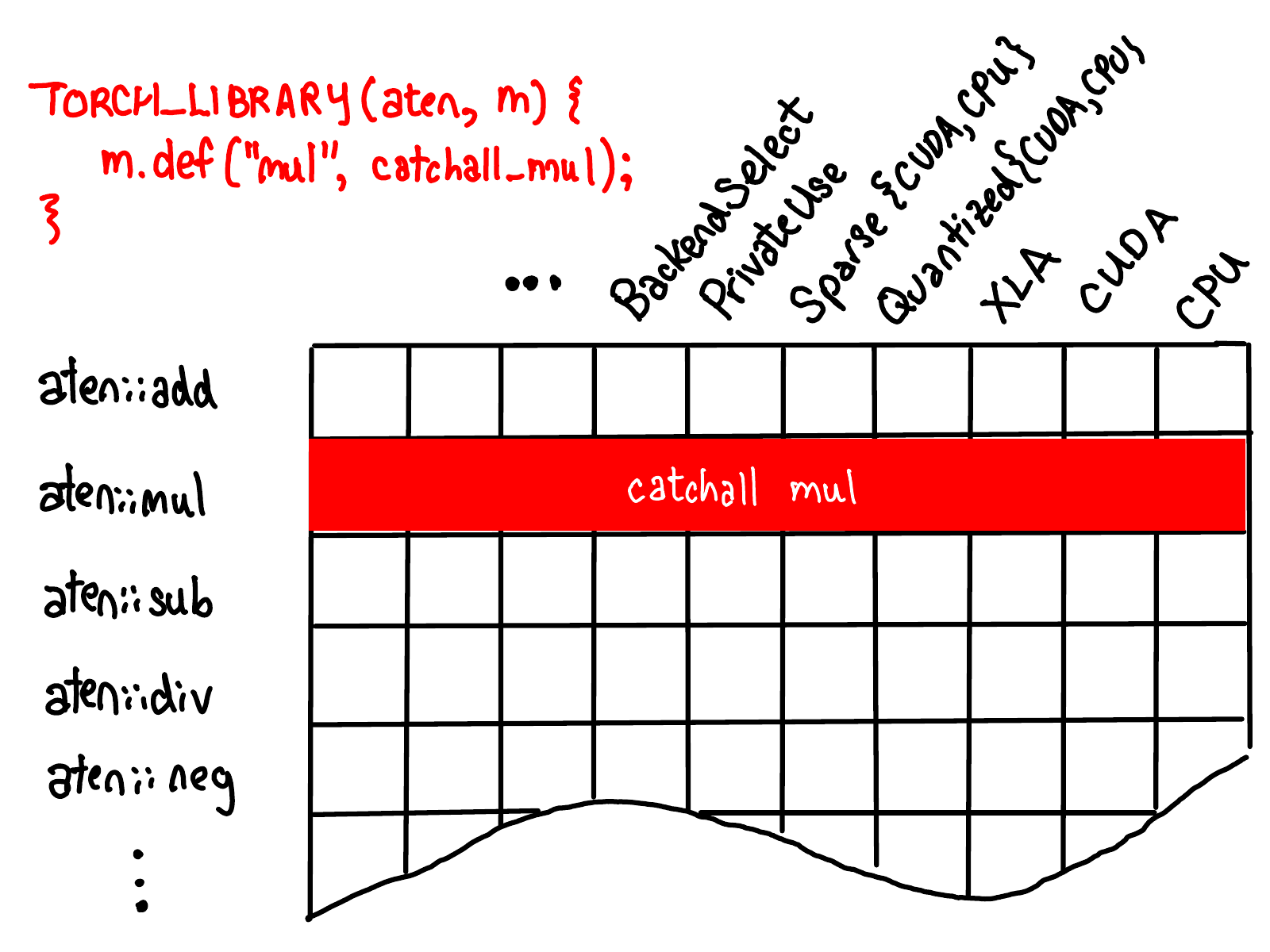
当将一个 kernel 注册为 operator 的 ”catch-all“ kernel,用于处理该 operator 的所有调度键时,会用一个内核填充整个运算符的一行,如下图的红色部分:
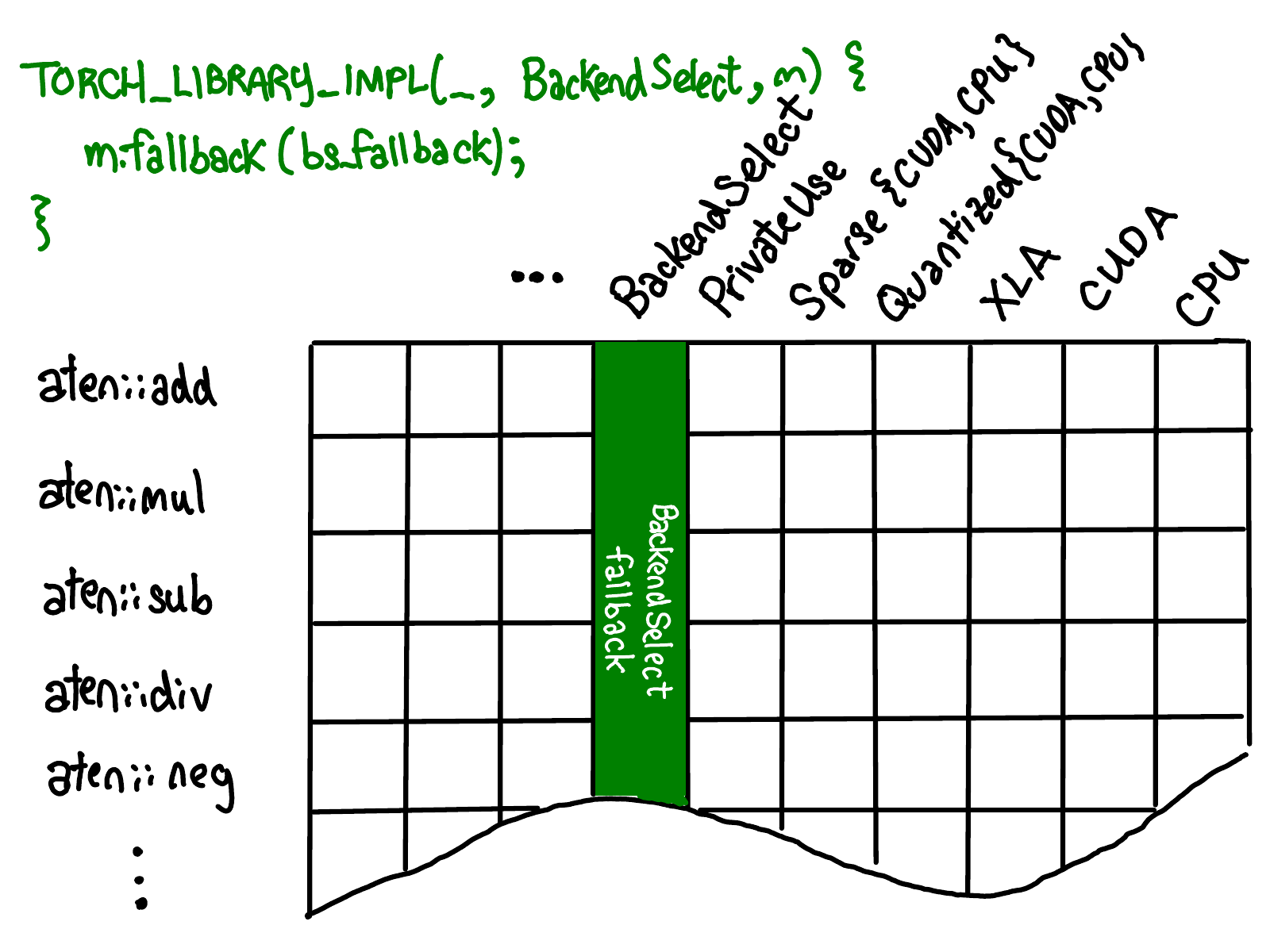
当将一个 kernel 注册为单个 dispatch key 的 fallback 时,会填充该调度键的整列,如下所示的绿色部分:
这三种的优先级如下:
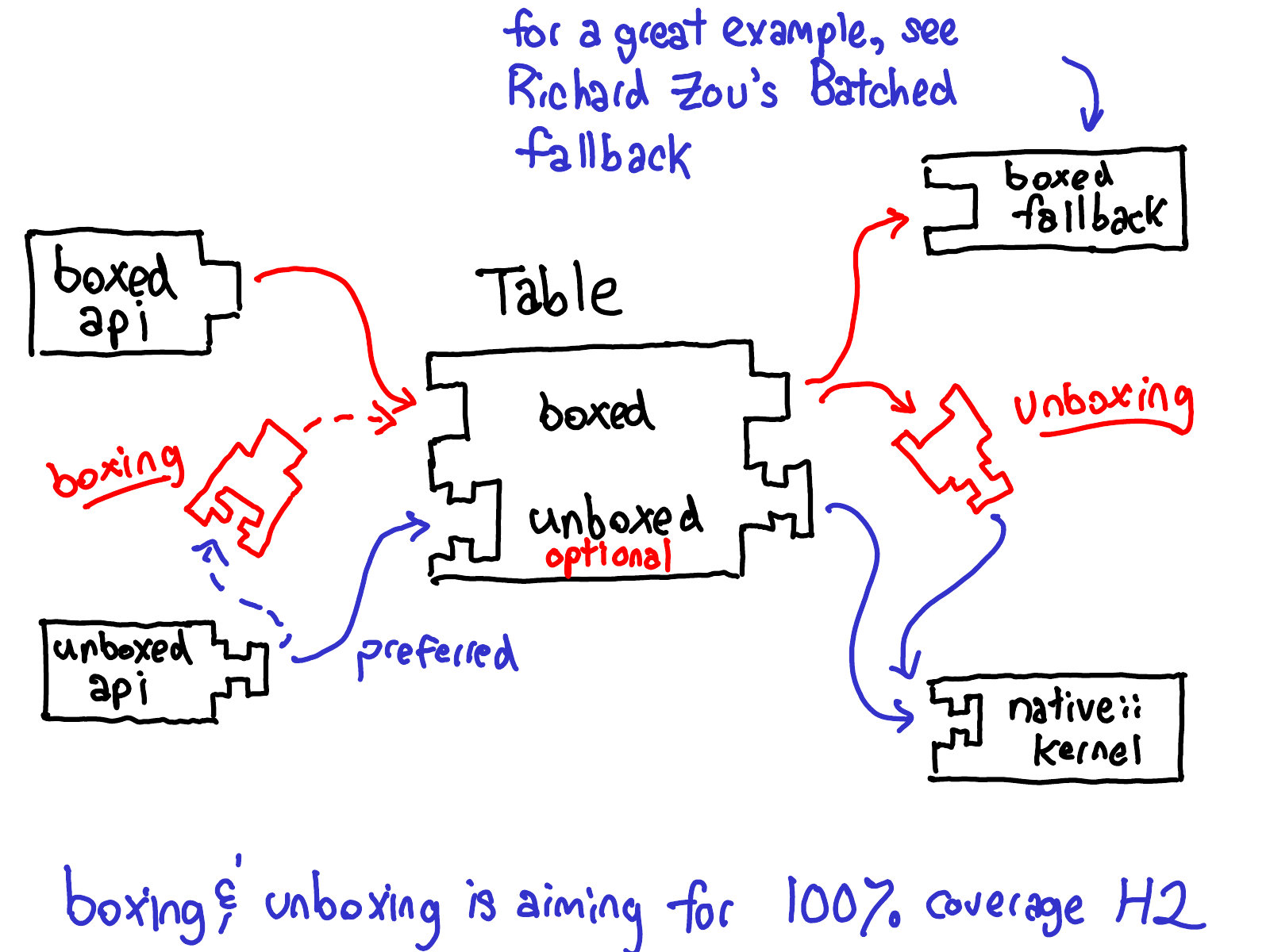
Boxing & Unboxing
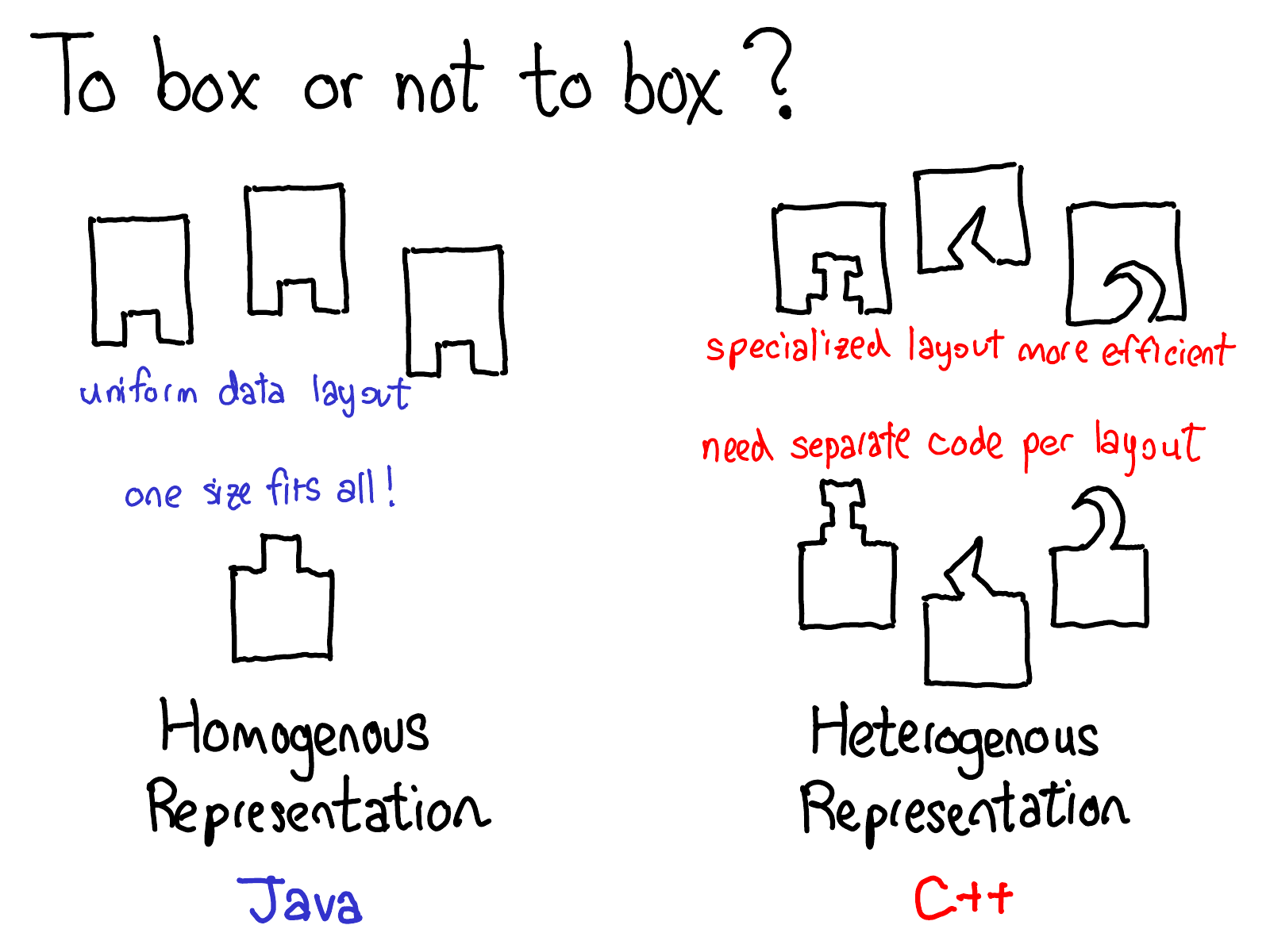
装箱(boxed)或同质(homogenous)是一种数据表示,其中所有的对象类型都具有相同的布局。同质表示在代码中易于处理:数据具有某种常规布局,可以编写对任何类型的数据进行多态操作的函数。
非装箱(unboxed)或异质(heterogenous)允许对象具有不同的布局。缺点是不能轻松地编写一个可以对许多类型的对象进行多态操作的单个函数。在 C++ 中可以通过使用模板来解决这个问题:如果需要一个函数能够处理多种类型,C++ 编译器会为每种使用的类型创建一个专门的函数副本。
在 PyTorch 中通过 IValue 来实现了同质布局。IValue 由 payload 和 tag 构成:
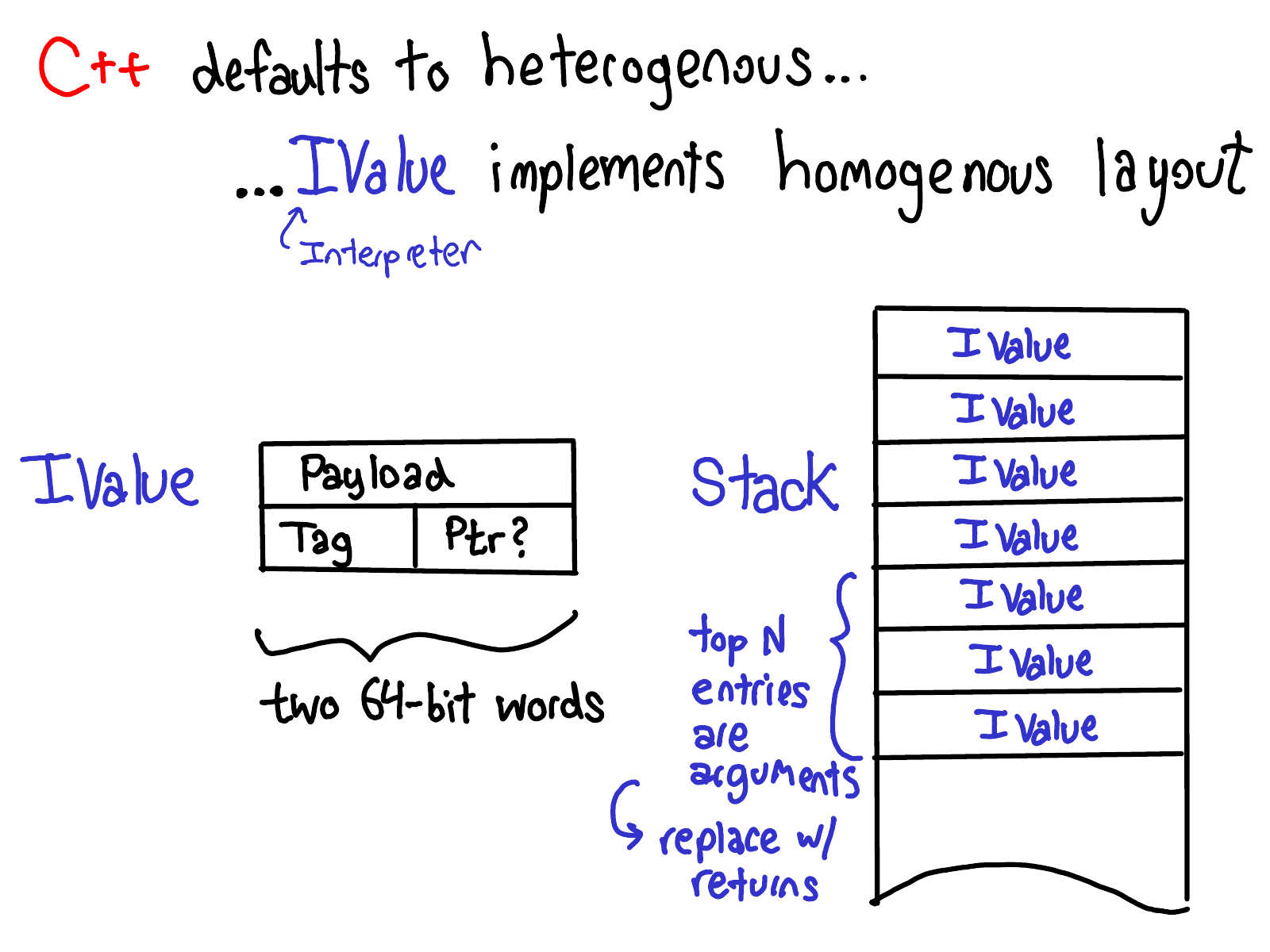
这意味着在 PyTorch 中,我们有两种函数调用方式:C++ 非装箱方式和使用 IValue 的装箱方式。调用可以来自非装箱API(直接 C++ 调用)或装箱 API(来自 JIT 解释器);同样,内核可以通过直接 C++ 函数(非装箱)的方式实现,也可以通过装箱 fallback 实现(fallback 必须是装箱,因为在所有运算符上是多态的)。
PyTorch 中通过装箱适配器(boxing adapter )来实现从 unboxed API 到 boxed fallback 的调用,采用 C++ 模板来实现。
相反的,PyTorch 也提供了非装箱适配器(unboxing adapter) 来实现从 boxed API 到 unboxed kernel 的调用。总结如下图: