本文为论文 Attention Is All You Need 的笔记。
Introduction
在 Transformer 出现之前,主流的序列转换模型基于复杂的循环神经网络或卷积神经网络,通常都包括一个编码器和一个解码器。表现最好的模型是通过注意力机制将编码器和解码器连接起来。这篇论文提出了一种新的简单网络架构 Transformer,仅基于注意力机制,完全摒弃了循环和卷积。
循环模型基于前一个隐藏状态 $h_{t−1}$ 和位置 $t$ 的输入生成一系列隐藏状态 $h_t$ 。这种顺序性使得在训练样本内无法并行化,只能通过批处理的方式来提升训练效率。而当样本序列长度较长时,内存会限制批处理的样本数。
新的模型架构 Transformer 完全摒弃了循环,并完全依靠于注意力机制来建立输入和输出之间的全局依赖关系,因此 Transformer 也支持更高程度的并行化。
Background
在这部分,作者对比了不同模型关联两个位置所需的操作数量随距离的增长关系,这是影响模型学习远距离位置间依赖关系(learn dependencies between distant positions)的关键因素。随着距离的增加,ConvS2S 的操作数是线性增长,ByteNet 则是对数增长。而在 Transformer 模型中为常数,尽管这是以降低有效分辨率为代价的,因为需要对注意力加权的位置进行平均。Transformer 通过使用多头注意力(Multi-Head Attention)来抵消这种效应。
Transformer 中注意力机制用于计算每个位置与其他位置之间的相关性,然后根据这些相关性对不同位置的表示进行加权平均。平均操作会导致位置的多个相关信息被混合在一起,模型无法准确地区分不同位置相关信息的差异。为了解决这个问题,Transformer 引入了多头注意力机制,类似卷积中的多通道,来提高模型的有效分辨率。
自注意力(Self-attention),有时也称为内部注意力(intra-attention),是一种注意力机制,用于关联单个序列中的不同位置,以计算出该序列的表示(relating different positions of a single sequence in order to compute a representation of the sequence)。Transformer 是第一个完全依赖自注意力机制而不是 RNN 或卷积来计算输入和输出表示的转换模型。这种基于自注意力的架构使 Transformer 具有更高的并行化能力,可以更有效地处理长序列,并且能够捕捉到更远距离的依赖关系。
Model Architecture
多数神经序列转换模型都采用编码器-解码器结构。编码器将输入符号表示的序列 $(x_1, …, x_n)$ 映射到连续表示的序列 $z = (z_1, …, z_n)$。给定 $z$,解码器逐元素生成,最终输出序列 $(y_1, …, y_m)$。在每一步中,模型是自回归的,它在生成下一个元素时会将先前生成的元素作为额外的输入。
Transformer 模型也遵循这种架构,使用堆叠的自注意力(stacked self-attention)和逐点全连接层(point-wise, fully connected layers)构成编码器和解码器,分别显示在下图的左半部分和右半部分:
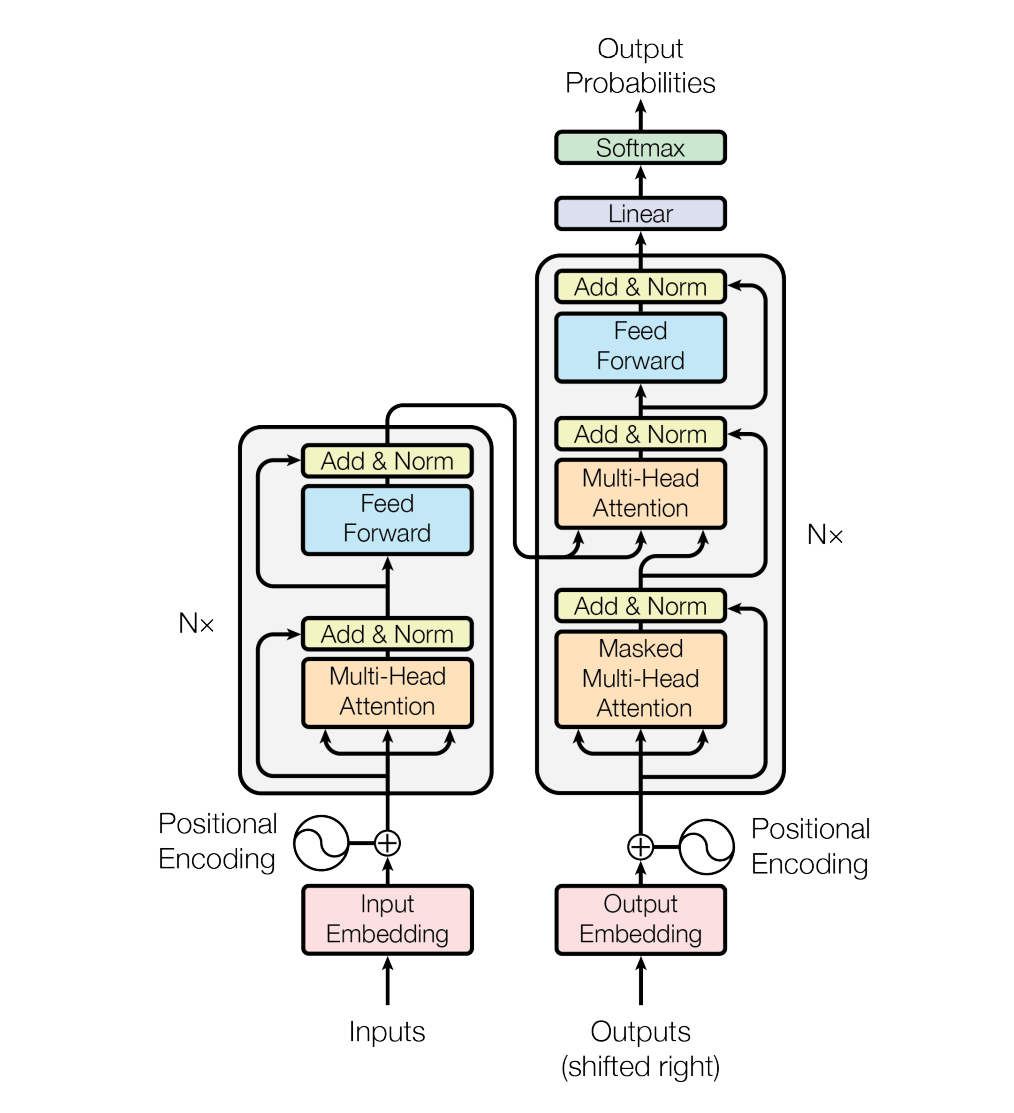
Encoder and Decoder Stacks
Encoder
编码器由 $N = 6$ 个相同的层组成。每个层包含两个子层。第一个子层是多头自注意力(multi-head self-attention)机制,第二个子层是一个简单的逐点全连接前馈(positionwise fully connected feed-forward)网络。每个子层采用残差连接( residual connection),然后进行层归一化(layer normalization)。也就是说,每个子层的输出是 $\text{LayerNorm}(x + \text{Sublayer}(x))$,模型中的所有子层以及 embedding 层的输出维度都是 $d_{model} = 512$。
Decoder
解码器也由 $N = 6$ 个相同的层组成。除了包含了编码器层中的两个子层外,解码器还插入了第三个子层,该子层对编码器的输出执行多头注意力(performs multi-head attention over the output of the encoder stack)。与编码器类似,解码器在每个子层采用残差连接,然后进行层归一化。此外,解码器中的自注意力子层通过掩码防止关注到后续位置(prevent positions from attending to subsequent positions),确保对位置 $i$ 的预测仅依赖于小于 $i$ 的已知输出。
Attention
一个注意力函数可以被描述为将一个查询(query)和一组键-值(key-value)对映射到一个输出(output),其中查询、键、值和输出都是向量。输出(output)由值(value)的加权和计算得出,其中分配给每个值(value)的权重由查询(query)与值(value)相应键(key)的兼容性函数计算得出的。
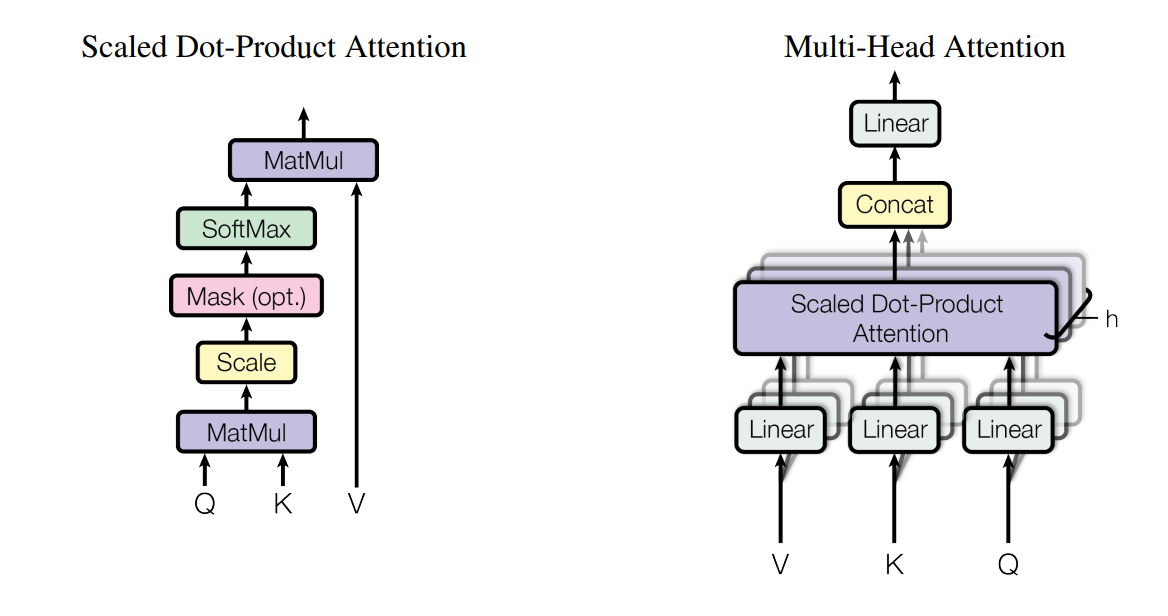
Scaled Dot-Product Attention
最常用的注意力函数是加性注意力和点积注意力。加性注意力使用具有单个隐藏层的前馈网络来计算兼容性函数。虽然在理论复杂度上两者相似,但在实践中点积注意力更快且更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。对于较大的 $d_k$ 值,点积的乘积可能会变得很大,导致softmax 的梯度趋向于零。为了抵消这种效应,我们通过 $\frac{1}{\sqrt{d_k}}$ 对点积进行缩放。
Multi-Head Attention
多头注意力(multi-head attention )允许模型同时关注不同位置的不同表示子空间(different representation subspaces at different positions)中的信息,类似于卷积的多通道:
\[\text{MultiHead}(Q, K, V ) = \text{Concat}(head_1, ..., head_h)W^O \\ \text{ where head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i)\]我们使用了 $h = 8$ 个注意力头,对于每个注意力头,我们使用 $d_k = d_v = d_{model}/h = 64$。由于每个头部的维度减小,总的计算成本与具有完整维度的单头注意力相当。
Applications of Attention in our Model
Transformer 在以下地方中使用了多头注意力:
- 在“编码器-解码器注意力”层中,查询取自前一个解码器层,而键和值取自编码器的输出。这使得解码器中的每个位置都可以关注输入序列中的所有位置
- 编码器包含自注意力层。在该自注意力层中,所有的键、值和查询都来自编码器中前一层的输出。编码器中的每个位置都可以关注编码器前一层中的所有位置
- 解码器中的自注意力层允许解码器中的每个位置关注截止到包括该位置在内的解码器中的所有位置(通过掩码的方式)
Position-wise Feed-Forward Networks
除了注意力子层之外,编码器和解码器中每个层还包含一个全连接前馈网络,对每个位置做单独且相同的处理。这个前馈网络由两个线性变换组成,中间使用 ReLU 激活函数。
\[\text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2\]虽然在不同位置上线性变换是相同的,但是在不同层之间使用的参数是不同的。
Embeddings and Softmax
Transformer 使用学习得到的 embeddings 将输入 token 和输出 token 转换为维度为 $d_{model}$ 的向量。我们还使用常见的线性变换和 softmax 将解码器的输出转换为预测的下一个 token 的概率。
Positional Encoding
由于 Transformer 不包含循环和卷积,为了让模型利用序列的顺序信息,需要注入序列中 token 的相对或绝对位置信息。因此在编码器和解码器栈的底部的输入 embedding 添加了“位置编码(positional encodings)”。位置编码与 embedding 具有相同的维度 $d_{model}$ ,因此可以相加。实现上 Transformer 使用了 sine 和 cosine 函数的不同频率:
\[PE_{(pos,2i)} =sin(pos/10000^{2i/dmodel})\\ PE_{(pos,2i+1)} =cos(pos/10000^{2i/dmodel})\]其中 pos 为位置,i 为纬度,每个维度的位置编码对应一个正弦曲线。作者提到,选择这个函数是因为假设它能够使模型轻松地学习相对位置的注意力,因为对于任何固定的偏移量 k,$PE_{pos+k}$ 可以表示为 $PE_{pos}$ 的线性函数。
Why Self-Attention
这部分说明了采用自注意力机制,而不是卷积或 RNN的理由。除了总计算复杂度和并行度之外,长程依赖关系的学习是序列转换任务的一个关键挑战。影响该学习能力的一个关键因素是前向和后向信号在网络中所需遍历的路径长度。路径越短,学习长程依赖关系就越容易。论文中比较了由不同层类型组成的网络中任意两个输入和输出位置之间的最大路径长度:

自注意力层将所有位置连接起来,只需要执行固定数量的顺序操作,而循环层则需要 O(n) 个顺序操作。当序列长度 n 小于表示维度 d 时,自注意力层比循环层更快。
一个卷积核宽度为 k < n 的单个卷积层无法连接所有输入和输出位置。需要使用 O(n/k) 个卷积层的堆叠,这会增加网络中任意两个位置之间最长路径的长度。相比循环层,卷积层通常更加昂贵,复杂度增加了一个因子 k。可分离卷积可以显著降低复杂度,然而即使在 k = n 的情况下,可分离卷积的复杂度仍然等于自注意力层和逐点前馈层的组合。
实现
以该源码 https://github.com/jadore801120/attention-is-all-you-need-pytorch/tree/master/transformer 为例。
Mask
前面提到“通过解码器中的自注意力子层通过掩码防止关注到后续位置”的掩码逻辑实现如下(get_subsequent_mask函数):
1
2
3
4
5
6
7
8
9
10
11
12
13
def get_subsequent_mask(seq):
''' For masking out the subsequent info. '''
sz_b, len_s = seq.size()
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()
return subsequent_mask
class Transformer(nn.Module):
def forward(self, src_seq, trg_seq):
src_mask = get_pad_mask(src_seq, self.src_pad_idx)
trg_mask = get_pad_mask(trg_seq, self.trg_pad_idx) & get_subsequent_mask(trg_seq)
enc_output, *_ = self.encoder(src_seq, src_mask)
dec_output, *_ = self.decoder(trg_seq, trg_mask, enc_output, src_mask)
解码器层
解码器层总共包含三个子层:
- 子层一(多头自注意力层):查询、键和值都为解码器上一层的输出
- 子层二(多头自注意力层):查询取自子层一的输出,键和值取自编码器的输出
- 子层三(逐点全连接前馈)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class DecoderLayer(nn.Module):
''' Compose with three layers '''
def __init__(self, d_model, d_inner, n_head, d_k, d_v, dropout=0.1):
super(DecoderLayer, self).__init__()
self.slf_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.enc_attn = MultiHeadAttention(n_head, d_model, d_k, d_v, dropout=dropout)
self.pos_ffn = PositionwiseFeedForward(d_model, d_inner, dropout=dropout)
def forward(
self, dec_input, enc_output,
slf_attn_mask=None, dec_enc_attn_mask=None):
dec_output, dec_slf_attn = self.slf_attn(
dec_input, dec_input, dec_input, mask=slf_attn_mask)
dec_output, dec_enc_attn = self.enc_attn(
dec_output, enc_output, enc_output, mask=dec_enc_attn_mask)
dec_output = self.pos_ffn(dec_output)
return dec_output, dec_slf_attn, dec_enc_attn