AutoGrad 概念和基础类
这篇文章介绍 PyTorch 自动微分的概念和基础类,总结自以下文章:
- A Gentle Introduction to torch.autograd
- Overview of PyTorch Autograd Engine
- [源码解析]深度学习利器之自动微分(3) — 示例解读
- [源码解析]PyTorch如何实现前向传播
自动微分原理
PyTorch 使用自动微分来计算函数相对于输入的梯度。自动微分可以在给定计算图的情况下计算输入的梯度。自动微分有两种不同的实现方式:前向模式和反向模式。前向模式是在计算函数结果的同时计算梯度,而反向模式则是先评估函数,然后从输出开始计算梯度。通常情况下反向模式是更好的选择,因为输出的数量小于输入的数量,可以实现更高效的计算。
自动微分在一个有向无环图(DAG)中记录了数据(张量)和所有执行的算子(以及生成的新张量)。在这个图中,叶子节点是输入张量,根节点是输出张量。通过从根节点到叶子节点的追踪,可以使用链式法则自动计算梯度。
在前向传播过程中,自动微分同时执行两个操作:
- 运行所请求的算子以计算结果张量
- 在 DAG 中维护算子对应的梯度函数(存储于张量的
grad_fn字段)
当在 DAG 的根节点上调用 .backward() 时,反向传播过程开始,自动微分执行以下操作:
- 通过
.grad_fn计算每个张量的梯度 - 将它们累积到相应张量的
.grad属性中 - 使用链式法则,将梯度传播到叶子张量
以函数 $f(x,y)=\log(x*y)$ 为例,计算图如下:
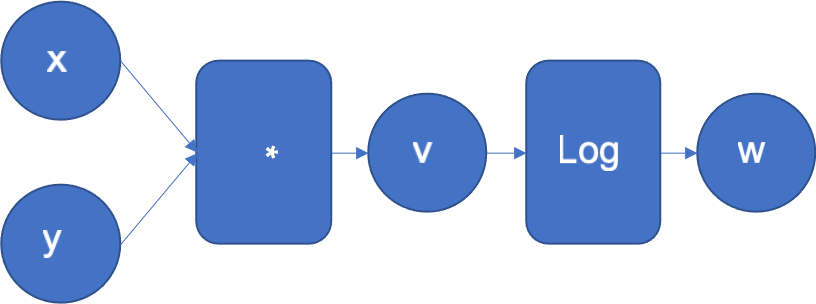
自动微分引擎会执行这个计算图。还会扩展计算图,以计算 $w$ 相对于输入 $x$、$y$ 和中间结果 $v$ 的导数。每当引擎在计算图中执行一个算子时,该算子的导数会被添加到图中,以便稍后在反向传播中执行。
在上面的例子中,当将 $x$ 和 $y$ 相乘得到 $v$ 时,引擎会扩展计算图,使用乘法导数定义来计算乘法的偏导数:$\frac{\partial}{\partial x}g(x,y)= y$ 和 $\frac{\partial}{\partial y}g(x,y)= x$。扩展后的计算图如下图所示。注意:反向图(绿色节点)直到所有前向步骤完成后才会被执行:
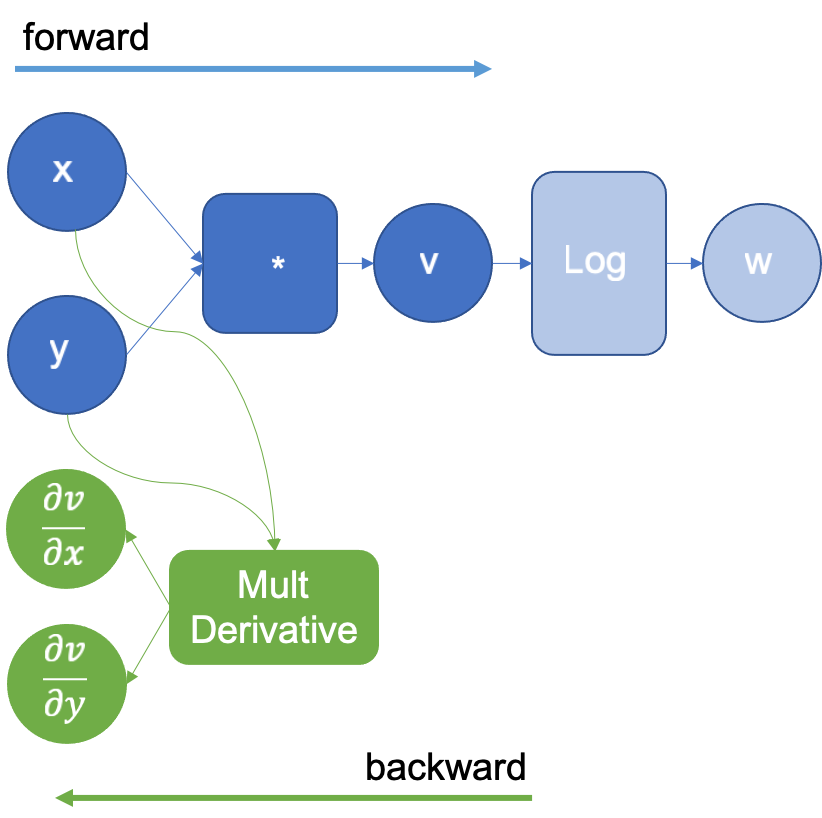
接着,引擎现在计算 $\log(v)$ ,并再次扩展计算图,添加 $\log$ 导数,即 $\frac{1}{v}$。如下图:

在反向传播时该算子将生成结果 $\frac{\partial w}{\partial v}$,并与乘法导数 $\frac{\partial v}{\partial x}$, $\frac{\partial v}{\partial y}$ 相乘(按照链式法则 $\frac{\partial w}{\partial x} = \frac{\partial w}{\partial v}\frac{\partial v}{\partial x}$),生成导数 $\frac{\partial w}{\partial x}$ 和 $\frac{\partial w}{\partial y}$。
原始的计算图会扩展了一个新的虚拟变量 $z$,它与 $w$ 相同。$z$ 相对于 $w$ 的导数是 1,因为它们是同一个变量,这个技巧允许我们应用链式法则来计算输入的导数。在前向传播完成后,我们开始进行反向传播,通过为 $\frac{\partial z}{\partial w}$ 提供初始值 $1.0$:
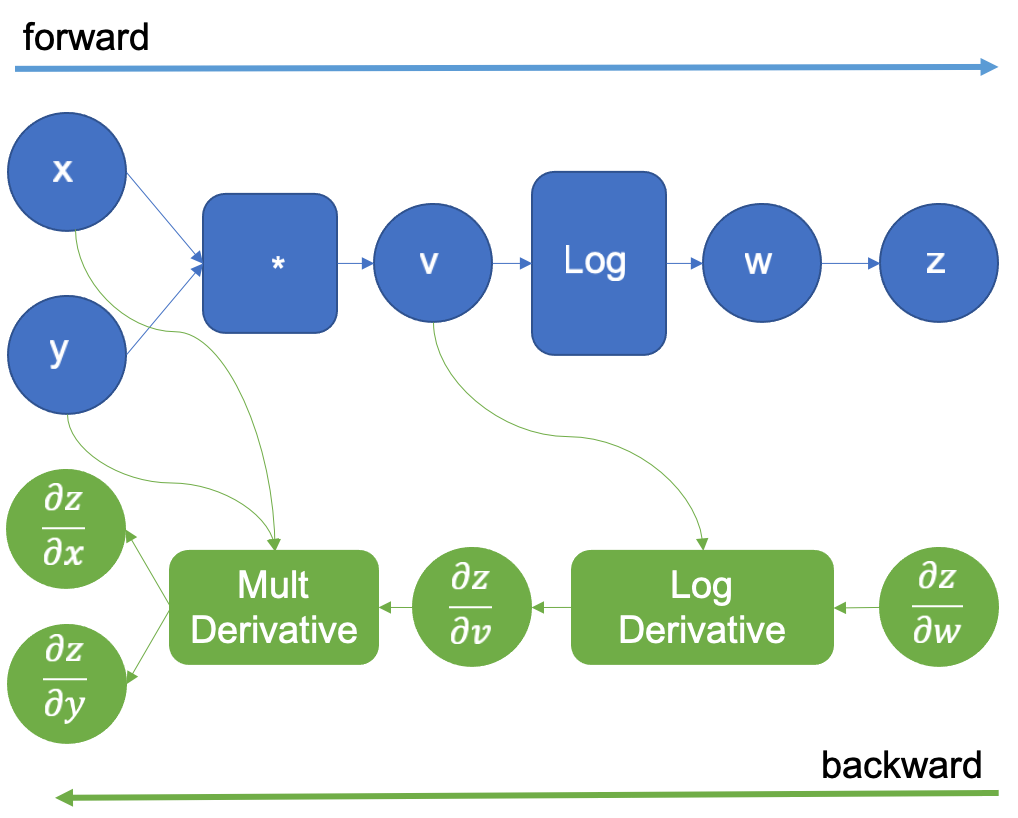
然后,按照绿色图执行 LogDerivative $\frac{1}{v}$,并将其结果乘以 $\frac{\partial z}{\partial w}$ ,由链式法则得到梯度 $\frac{\partial z}{\partial v}$。接下来,乘法导数以相同的方式执行,最终得到所需的导数 $\frac{\partial z}{\partial x}$ 和 $\frac{\partial z}{\partial y}$。
PyTorch 示例
示例一
代码
1
2
3
4
5
6
7
8
9
10
11
import torch
a = torch.tensor(2., requires_grad=True)
b = torch.tensor(6., requires_grad=True)
O = 3*a**3
P = b**2
Q = O - P
external_grad = torch.tensor(1.)
Q.backward(gradient=external_grad)
print(a.grad)
print(b.grad)
输出
1
2
tensor(36.)
tensor(-12.)
分析
由 $Q = 3a^3 - b^2$,$Q$ 对 $a$ 的偏导 $\frac{∂Q}{∂a} = 9a^2$ ,对 $b$ 的偏导 $\frac{∂Q}{∂b} = -2b$。
由 $a = 2$,$b=6$,可得 $\frac{∂Q}{∂a} = 9a^2 = 36$,$\frac{∂Q}{∂b} = -2b=-12$。
从输出可以观察到 a.grad 输出为 36,b.grad 输出为 -12,可以看到偏导数存于张量的 grad 字段。
示例二
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import torch
a = torch.tensor(2., requires_grad=True)
b = torch.tensor(6., requires_grad=True)
O = 3*a**3
P = b**2
Q = O - P
grads = torch.autograd.grad(Q, [a, b])
print(grads[0])
print(grads[1])
print(Q.grad_fn)
print(Q.grad_fn.next_functions)
print(O.grad_fn)
print(O.grad_fn.next_functions)
print(P.grad_fn)
print(P.grad_fn.next_functions)
print(a.grad_fn)
print(b.grad_fn)
输出
1
2
3
4
5
6
7
8
9
10
tensor(36.)
tensor(-12.)
<SubBackward0 object at 0x7fd8af6b0240>
((<MulBackward0 object at 0x7fd8af6b0d30>, 0), (<PowBackward0 object at 0x7fd8af6b02b0>, 0))
<MulBackward0 object at 0x7fd8af6b0d30>
((<PowBackward0 object at 0x7fd8af6b02b0>, 0), (None, 0))
<PowBackward0 object at 0x7fd8af6b02b0>
((<AccumulateGrad object at 0x7fd8af6b0d30>, 0),)
None
None
分析
对应 DAG 图:
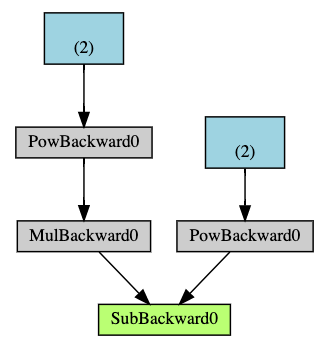
可以看出,张量的 grad_fn 字段存储的是生成该张量的函数的梯度函数,例如 $Q$ 是由减法运算得出,则其 grad_fn 为 SubBackward。grad_fn 的 next_functions 为列表,表示该 grad_fn 的计算结果需要输出到哪些梯度函数。Q.grad_fn 的 next_functions 为 MulBackward 和 PowBackward,即表示 Q.grad_fn 的输出将作为 MulBackward 和 PowBackward 的输入,逐层传递,这样就可以通过链式法则来计算 $\frac{∂Q}{∂a}$ $\frac{∂Q}{∂b}$ 。
总结如下图:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
+---------------------+ +----------------------+
| SubBackward0 | | PowBackward0 |
| | Edge | | Edge
| next_functions +-----+--------> | next_functions +----------> ...
| | | | |
+---------------------+ | +----------------------+
|
|
| +----------------------+
| Edge | MulBackward0 |
+--------> | | Edge
| next_functions +----------> ...
| |
+----------------------+
Python 类映射的 C++ 类
计算图由节点(Node)和边(Edge)组成:
- 节点:即算子
- 边:算子之间的流向关系
Variable
Variable 就是 Tensor,只是为了向后兼容,才保留这个名字。Variable 是节点间流动的数据。
https://github.com/pytorch/pytorch/blob/main/torch/csrc/autograd/variable.h
1
2
3
4
5
6
7
8
9
/// `Variable` is exactly the same as `Tensor` (i.e. we have `using Variable =
/// at::Tensor`). This means you can perform all the usual mathematical and
/// other operations you can perform on `Tensor`s also on `Variable`s.
///
/// The only reason we are keeping the `Variable` class is backward
/// compatibility with external user's legacy C++ frontend code. Our intention
/// is to eliminate the `Variable` class in the near future.
using Variable = at::Tensor;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
///~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/// Variable
///~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/// A `Variable` augments a `Tensor` with the ability to interact in our
/// autograd machinery. Conceptually, `Variable`s travel along `Edge`s between
/// `Node`s in the autograd graph. A `Variable` can either be a leaf, like a
/// weight in a neural network, or an interior variable, when it is the result
/// of an operation between variables. Every `Variable` also stores another
/// `Variable` called its `grad` (gradient). If the variable is a leaf, its
/// gradient will be accumulated into this variable.
///
/// Gradient Edges
///~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/// Furthermore, `Variable`s have the notion of a `gradient_edge`, which is the
/// edge in the autograd graph that connects the variable to a particular input
/// of the gradient function that will be invoked with the variable during the
/// backward pass. More precisely, this gradient function can be one of two
/// things:
/// 1. A `grad_fn`, if the variable is in the interior of the graph. This is the
/// gradient of the function that produced the variable.
/// 2. A `grad_accumulator`, if the variable is a leaf, which accumulates a
/// scalar gradient value into its `grad` variable.
Variable 沿着 Edge 在 Node 之间流动。Variable 可以是叶子节点,例如神经网络中的权重,也可以是内部变量(变量之间的运算结果)。
Variable 中自动微分的相关信息存储于 AutogradMeta 结构中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// AutogradMeta
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
/// Each `Variable` has one unique `AutogradMeta` struct, which stores autograd
/// metadata fields that are necessary for tracking the Variable's autograd
/// history. As an optimization, a Variable may store a nullptr, in lieu of a
/// default constructed AutogradMeta.
struct TORCH_API AutogradMeta : public c10::AutogradMetaInterface {
Variable grad_;
std::shared_ptr<Node> grad_fn_;
std::weak_ptr<Node> grad_accumulator_;
};
Node
https://github.com/pytorch/pytorch/blob/main/torch/csrc/autograd/function.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// Node
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// A `Node` is an abstract class that represents an operation taking zero
// or more input `Variable`s and producing zero or more output `Variable`s. All
// functions in PyTorch's autograd machinery derive from this class and
// override its `apply` method. Instances of such subclasses will then be
// invokeable via the call operator.
// Nodes in the Autograd Graph
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// When viewing the autograd system as a graph, `Node`s are the vertices or
// nodes, connected to each other via (directed) `Edge`s, which themselves are
// represented via (`Node`, input_nr) pairs. `Variable`s are the outputs to
// and inputs of `Node`s, and travel between these edges during execution
// of the graph. When two or more `Edge`s (from different sources) point at the
// same input to a `Node`, the values produced along all of these edges are
// implicitly summed prior to being forwarded to the target `Node`.
// Hierarchy
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// Subclasses usually represent differentiable functions as well as their
// gradient operators.
// Interface
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
// The most important method on `Node` is the call operator, which takes in
// a list of variables and produces a list of variables.
struct TORCH_API Node : std::enable_shared_from_this<Node> {
edge_list next_edges_;
};
Node 是一个抽象类,表示接受零个或多个输入 Variable 并产生零个或多个输出Variable 的算子。PyTorch 自动微分机制中的所有函数都是从这个类派生的,并重写了它的 apply 方法。
Node 通过(有向)的 Edge 相互连接,Edge 由 <Node,input_nr>对表示。
Edge
https://github.com/pytorch/pytorch/blob/main/torch/csrc/autograd/edge.h
1
2
3
4
5
6
7
8
9
10
11
12
13
/// Represents a particular input of a function.
struct Edge {
Edge() noexcept : function(nullptr), input_nr(0) {}
Edge(std::shared_ptr<Node> function_, uint32_t input_nr_) noexcept
: function(std::move(function_)), input_nr(input_nr_) {}
/// The function this `Edge` points to.
std::shared_ptr<Node> function;
/// The identifier of a particular input to the function.
uint32_t input_nr;
};
每条边代表了节点的一个特定输入。
Python 和 C++ 类的映射关系如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
+--------------------------------------------+ +------------------------------+
| SubBackward0 | | PowBackward0 |
| | | | Edge
| | | next_functions +----------> ...
| next_functions[0] = (PowBackward0, 0) +----------> | |
| | +------------------------------+
| |
| | +-------------------------------+
| next_functions[1] = (MulBackward0, 0) +----------> | MulBackward0 |
| | | | Edge
| | | next_functions +----------> ...
+--------------------------------------------+ | |
+-------------------------------+
^
|
|
| Python
+--------------------------------------------------------------------------------------------------------+
| C++
|
v
+---------------------------------------------+ +----------------------+ +------------------+
| SubBackward0 | | Edge 1 | | PowBackward0 |
| +-------------------------> | | | |
| | | | function +----------> | |
| + | | | | |
| next_edges_ = [Edge 1, Edge 2] | | input_nr = 0 | | |
| + | +----------------------+ +------------------+
| | |
| | |
+---------------------------------------------+ +----------------------+ +------------------+
| | Edge 2 | | MulBackward0 |
| | | | |
+----------------> | function +----------> | |
| | | |
| input_nr = 0 | | |
| | | |
+----------------------+ +------------------+