本文是 《Scaling Language Models: Methods, Analysis & Insights from Training Gopher》 的笔记。
- 语言建模:通过利用大量书面人类知识来更好地预测和理解世界,为智能通信系统提供了方向。
- 研究内容:本文分析了基于 Transformer 的语言模型在各种模型规模上的性能,从数千万参数的模型到名为 Gopher 的 2800 亿参数模型。这些模型在 152 个不同的任务上进行了评估,在大多数任务中达到了最先进的性能。
- 规模带来的增益:在阅读理解、事实核查和识别有害语言等领域,规模带来的增益最大,但在逻辑和数学推理方面的增益较少。
- 全面分析:提供了对训练数据集和模型行为的全面分析,涵盖了模型规模与偏见和毒性之间的交叉点。
- AI 安全应用:讨论了语言模型在 AI 安全中的应用以及减轻下游伤害的方法。
1. 引言
自然语言通信是智能的核心,因为它允许人类或人工智能系统之间有效地共享思想。语言的通用性使我们能够将许多智能任务表述为接收自然语言输入并产生自然语言输出。
自回归语言建模 - 从其过去预测文本序列的未来 - 提供了一个简单而强大的目标,该目标允许制定许多认知任务。同时,它为大量训练数据打开了大门:互联网、书籍、文章、代码和其他写作。然而,这个训练目标只是对任何特定目标或应用的近似,因为我们预测序列中的所有内容,而不仅仅是我们在意的方面。但如果我们适当地谨慎对待结果模型,我们相信它们将成为捕捉人类智能丰富性的有力工具。
将语言模型作为通向智能的一个要素,与其最初的应用形成对比:在有限带宽的通信通道上传输文本。香农的《通信的数学理论》(Shannon,1948)将自然语言的统计建模与压缩联系起来,表明测量语言模型的交叉熵等同于测量其压缩率。Shannon 通过预先计算的文本统计表将早期的语言模型与真实数据相匹配(Dewey, 1923),这些统计表将模型复杂性与改进的文本压缩以及更真实的文本生成联系起来。但与智能的关系从一开始就存在:香农假设一个足够复杂的模型将充分地类似于人类交流,图灵测试(Turing,1950)巩固了这一联系。自那以后,数据压缩(通过预测)与智能之间的关系得到了进一步的扩展(参见 Chater(1999);Legg 和 Hutter(2007);Wolff(1982))。
现代计算是推动更好语言模型的关键驱动力。从纸笔起源开始,语言模型通过计算的指数级增长(Moore 等人,1965)在容量和预测能力上发生了转变。在 1990 年代和 2000 年代,n-gram 模型在规模和平滑方法上有所增加(Ney 等人,1994),包括一个在两万亿个文本 token 上训练的 3000 亿 n-gram 模型(Brants 等人,2007)。这些模型已应用于语音识别(Jelinek,1997)、拼写校正(Brill 和 Moore,2000)、机器翻译(Brown 等人,1990)和许多其他领域。然而,随着上下文长度的增加,n-gram 模型在统计和计算上变得低效,这限制了它们可以建模的语言的丰富性。
在过去的二十年中,语言模型已经发展到能够隐式捕捉语言结构的神经网络(Bengio 等人,2003;Graves,2013;Jozefowicz 等人,2016;Mikolov 等人,2010;Radford 等人,2019)。这是由规模和网络架构共同推动的(Bahdanau 等人,2014;Hochreiter 和 Schmidhuber,1997;Vaswani 等人,2017)。
Kaplan 等人(2020)发现了循环神经网络和 Transformer 神经语言模型的交叉熵损失与模型大小之间的幂律关系。通过生成预训练 Transformer 3(GPT-3,Brown 等人(2020)),一个在 3000 亿个文本 token 上训练的 1750 亿参数 Transformer,实现了规模扩大的经验预测收益(empirically predicted gains to scale),该模型消耗了 zettaflops 的计算量进行训练,比之前的工作高出数量级(Rosset,2020)。GPT-3 展示了前所未有的生成质量以及在许多自然语言处理(NLP)任务中的通用能力 - 特别是在提供示例的情况下(称为 few shot prompting)。
在本文中,我们描述了一种训练最先进的大型语言模型的协议,并介绍了一个名为 Gopher 的 2800 亿参数模型。我们在第 3 节概述了架构规范、优化、基础设施以及高质量文本数据集 MassiveText 的策划方法。我们在第 4 节对 152 个任务的基准性能进行了广泛分析,这些任务检查了智能的几个不同方面,并总结了关键结果。我们看到 Gopher 在大约 81% 的任务中提升了当前最先进语言模型的性能,尤其是在知识密集型领域,如事实核查和一般知识。
由于有害内容既出现在 Gopher 的训练集中,也出现在许多潜在的下游应用中,我们在第 5 节检查了模型的毒性和偏见,重点是规模如何影响这些属性。我们发现,当提供有害提示时,较大的模型更有可能生成有毒响应,但它们也可以更准确地分类毒性。我们还在第 6 节通过提示分析了 Gopher 在对话互动设置中的情况,并提供了几个文字记录,以展示模型的定性能力和局限性。
最后,我们在第 7 节讨论了这些模型的伦理和安全应用,包括在训练前和训练后减轻哪些类型的不期望行为。我们讨论了应用驱动的安全性以及语言模型加速更安全智能技术研究的潜力。
2. 背景
语言建模简介
语言建模是指对文本的概率进行建模,这里的文本可以是句子、段落或文档,具体取决于应用场景。这是通过对字符串进行分词来完成的,将其映射到一个整数标记序列:$g(S) = X = (X_1, X_2, …, X_n ) \in V^n$ ,其中 $V$ 是词汇表(一组有限的正整数),$n$ 是结果序列的长度,并对 $X$ 进行建模。分词可以是开放词汇表(open-vocabulary),其中任何字符串都可以唯一地分词,例如字节级建模;也可以是封闭词汇表(closed-vocabulary),只有文本的一个子集可以被唯一地表示,例如一个单词列表和一个表示未知词的特殊标记。我们采用开放词汇表分词,结合了字节对编码(byte-pair encoding, BPE)和回退到(backoff) UTF-8 字节的方式,这种方式类似于 Radford et al. (2018) 的方法。
自回归序列建模
对标记序列 $X$ 进行建模的典型方法是通过链式法则 $P(X) = P(X_1, X_2, …,X_n ) = \prod^n_{i=1} P(X_i|X_{<i})$。这也被称为自回归序列建模,因为在每个时间步骤中,基于过去的上下文来预测未来的标记。虽然还有其他针对序列建模的目标,例如在双向上下文中建模掩码标记(Devlin 等人,2019;Mikolov 等人,2013)和建模序列的所有排列(Yang 等人,2019),但我们关注自回归建模,因为其性能强且简单。从现在开始,我们将把语言模型称为函数逼近器(function approximators),用于执行下一个标记预测。
Transformer 架构
近年来,一类称为 Transformer(Vaswani 等人,2017)的神经网络在语言模型性能方面展示了最先进的结果(Dai 等人,2019;Radford 等人,2018, 2019),这是我们在本文中关注的架构。有一个趋势是通过扩大训练数据、模型大小(以参数衡量)和训练计算的组合来获得在学术和工业基准测试中表现更好的模型。在这一进展中的著名模型包括参数为 3.45 亿的 BERT(Devlin 等人,2019),在广泛的语言分类任务基准测试中表现强劲;参数为 15 亿的 GPT-2(Radford 等人,2018)和参数为 83 亿的 Megatron(Shoeybi 等人,2019),逐步显示出优越的零样本语言模型性能;参数为 110 亿的 T5(Raffel 等人,2020a),推进了闭卷问答任务的迁移学习和性能;以及前述的参数为 1750 亿的 GPT-3。大型语言模型(LLMs)这个称呼已经变得流行,用来描述这一代更大的模型。
最近的大型语言模型
自 GPT-3 以来,已经有了一个参数为 178B 的 Transformer 语言模型 Jurassic-1(Lieber 等人,2021),它使用了多样化的训练集和更大的分词器词汇表大小;以及宣布的参数为 530B 的 Megatron-Turing NLG(Kharya 和 Alvi,2021),它在一个发布的数据集(The Pile,Gao 等人(2020))上进行训练,并报告了一些初步的性能数字。还有一些 Transformer 变体结合了稀疏专家混合(Fedus 等人,2021;Roller 等人,2021b)来增加模型大小(在某些情况下达到数万亿参数),同时保持更为适度的计算预算。其他最近的大型语言模型包括两个在一系列下游任务上针对指令进行微调的模型(FLAN 和 T0)(Sanh 等人,2021;Wei 等人,2021),这提高了对未见任务的性能。
3. 方法
3.1 模型
在这篇论文中,我们展示了六个 Transformer 语言模型的结果,参数范围从 4400 万到 2800 亿,模型的架构细节在表 1 中展示。我们将最大的模型称为 Gopher,整个模型集合称为 Gopher 系列。
| 模型 | 层数 | 头数 | 键/值大小 | $d_{model}$ | 最大学习率 | 批量大小 |
|---|---|---|---|---|---|---|
| 44M | 8 | 16 | 32 | 512 | $6 × 10^{−4}$ | 0.25M |
| 117M | 12 | 12 | 64 | 768 | $6 × 10^{−4}$ | 0.25M |
| 417M | 12 | 12 | 128 | 1,536 | $2 × 10^{−4}$ | 0.25M |
| 1.4B | 24 | 16 | 128 | 2,048 | $2 × 10^{−4}$ | 0.25M |
| 7.1B | 32 | 32 | 128 | 4,096 | $1.2 × 10^{−4}$ | 2M |
| Gopher 280B | 80 | 128 | 128 | 16,384 | $4 × 10^{−5}$ | 3M → 6M |
表 1:模型架构细节。对于每个模型,我们列出了层数、键/值大小、瓶颈激活大小 $d_{model}$、最大学习率和批量大小。前馈大小始终是 4 × $d_{model}$。
我们使用了 Radford 等人(2019)详细描述的 autoregressive Transformer 架构,并做了两处修改:我们使用 RMSNorm(Zhang 和 Sennrich,2019)代替 LayerNorm(Ba 等人,2016),并使用了 Dai 等人(2019)的相对位置编码方案,而不是绝对位置编码。相对编码允许我们在比训练过的序列更长的序列上进行评估,这改善了对文章和书籍的建模。我们使用 SentencePiece(Kudo 和 Richardson,2018)对文本进行分词,词汇量为 32,000,并使用字节级回退来支持开放词汇建模。
3.2 训练过程
训练设置
- 训练令牌数:所有模型均训练 3000 亿个令牌
- 上下文窗口:使用 2048 个令牌的上下文窗口
- 优化器:采用 Adam 优化器(Kingma and Ba, 2014)
- 学习率调整:在前 1500 步内从 $10^{-7}$ 线性升温至最大学习率,然后使用余弦调度(cosine schedule)将其衰减 10 倍。
模型规模与训练参数调整
- 随着模型规模的增加,降低最大学习率并增加每个批次中的令牌数量(详见表 1)
- 对于 Gopher 模型,在训练过程中将批次大小从三百万个令牌增加到六百万个令牌
- 根据全局梯度范数对梯度进行裁剪(clip gradients based on the global gradient norm),裁剪值为 1;但对于 7.1B 模型和 Gopher 280B,为提高稳定性,将其减少到 0.25
数值格式与内存优化
- 引入 bfloat16 数值格式以减少内存占用并提高训练吞吐量
- 小于 7.1B 的模型使用混合精度,使用 float32 参数和 bfloat16 激活(Micikevicius et al., 2018),而 7.1B 和 280B 模型则使用 bfloat16 激活和参数
- 使用随机舍入(stochastic rounding)更新 bfloat16 参数以保持稳定性(Gupta et al., 2015)。但发现随机舍入并不能完全恢复混合精度训练的性能,更多细节见附录 C
3.3 基础设施
我们使用 JAX(Bradbury et al., 2018)和 Haiku(Hennigan et al., 2020)构建了我们的训练和评估代码库。特别是,我们使用 JAX 的 pmap 转换来有效地表达数据和模型并行性。我们在 TPUv3 芯片(Jouppi et al., 2020)上训练和评估了所有模型。
Gopher 的半精度参数和单精度 Adam 状态占用 2.5 TiB,远超过每个 TPUv3 核心上可用的 16 GiB 内存。为了解决这些内存问题,我们使用优化器状态分区(optimiser state partitioning)(Rajbhandari et al., 2020)、模型并行性(model parallelism)(Shoeybi et al., 2019)和重新物质化(rematerialisation)(Griewank and Walther, 2000)来划分模型状态并减少激活,使其适应 TPU 内存。
我们发现,由于 TPUv3 的快速跨芯片通信,数据和模型并行性的开销都很低,在训练 Gopher 时只产生 10% 的开销。因此,我们发现在 TPU 上,直到训练规模超过 1024 芯片的“pod”时,才需要使用 pipelining(Huang et al., 2019),这大大简化了中型模型的训练。然而,流水线是一种在 commodity networks 上高效的并行方法,因为它的通信量低,所以非常适合连接多个 TPU pod。
3.4 训练数据集
我们在 MassiveText 数据集上训练 Gopher 系列模型,这是一个来自多个来源的大型英语文本数据集集合:网页、书籍、新闻文章和代码。表 2 详细列出了组成数据集的内容。
| 磁盘大小 | 文档数 | Tokens | 采样比例 | |
|---|---|---|---|---|
| MassiveWeb | 1.9 TB | 604M | 506B | 48% |
| Books | 2.1 TB | 4M | 560B | 27% |
| C4 | 0.75 TB | 361M | 182B | 10% |
| News | 2.7 TB | 1.1B | 676B | 10% |
| GitHub | 3.1 TB | 142M | 422B | 3% |
| Wikipedia | 0.001 TB | 6M | 4B | 2% |
表2:MassiveText 数据组成。我们在训练过程中非均匀地从 MassiveText 中采样,使用最右边的列显示的采样比例。
我们的数据管道包括文本质量过滤、重复文本的移除、相似文档的去重以及移除与测试集有显著重叠的文档。我们发现这个管道提高了语言模型的下游性能,这强调了数据集质量的重要性。
总的来说,MassiveText 包含 23.5 亿个文档,或大约 10.5 TB 的文本。由于我们在 300B 个 token(占 MassiveText 数据集中总 token 的 12.8%)上训练 Gopher,我们从 MassiveText 中进行子采样,每个子集(书籍、新闻等)的采样比例都是指定的。我们调整这些采样比例以最大化下游性能。
4. 结果
我们汇总了 Gopher 及其较小模型家族在 152 个任务上的表现,并将这些结果与之前语言模型的最先进(SOTA)性能(124 个已发布 LM 性能的任务)进行比较。在本节中,我们将总结关键发现。
4.1. 任务选择
我们建立了一个语言模型性能的概况,涵盖了数学、常识、逻辑推理、一般知识、科学理解、伦理和阅读理解等方面,以及传统的语言建模基准测试。我们包括了综合基准测试(如 BIG-bench 合作(2021)),其中包含了多种任务,以及一些已建立的有针对性的基准测试,如用于阅读理解的 RACE(Lai 等人,2017)和用于事实核查的 FEVER(Thorne 等人,2018)等。我们在表 3 中列出了我们的任务来源。
| 任务类型 | 任务数量 | 示例 |
|---|---|---|
| 语言建模 | 20 | WikiText-103, The Pile: PG-19, arXiv, FreeLaw, … |
| 阅读理解 | 3 | RACE-m, RACE-h, LAMBADA |
| 事实核查 | 3 | FEVER (2-way & 3-way), MultiFC |
| 问答 | 3 | Natural Questions, TriviaQA, TruthfulQA |
| 常识 | 4 | HellaSwag, Winogrande, PIQA, SIQA |
| MMLU | 57 | High School Chemistry, Atronomy, Clinical Knowledge, … |
| BIG-bench | 62 | Causal Judgement, Epistemic Reasoning, Temporal Sequences, … |
表 3: 评估任务。我们为 Gopher 模型家族在 152 个任务上的表现编制了结果。
我们选择了需要模型估计目标文本概率的任务,因为我们发现这是一个能够支持探测知识和推理能力的通用接口。对于语言建模任务,我们计算每字节的比特数(BPB),这是一种压缩度量,其中较低的值表示对正确续写的概率更高。所有其他任务都遵循多项选择格式,模型在给定上下文和问题的情况下,对每个多项选择的回答输出一个概率,我们选择概率最高的回答。在这里,我们衡量正确回答的准确性。
4.2 与最先进技术的比较
我们发现 Gopher 在阅读理解、人文学科、伦理学、STEM(科学、技术、工程和数学)和医学类别中表现出最为均匀的改进。在事实核查方面,我们看到了一般性的提升。对于常识推理、逻辑推理和数学,我们看到的性能提升较小,甚至有几项任务的性能有所下降。总体趋势是,在侧重推理的任务(例如,抽象代数)上改进较少,而在知识密集型测试(例如,常识知识)上的改进更大且更为稳定。
4.3 性能提升与规模的关系
4.3.1 不同任务类型对模型规模的受益情况
我们研究了哪些类型的任务会因模型规模的扩大而受益。在这一部分,我们将 Gopher(280B)与较小的模型(≤ 7.1B)的性能进行了比较。由于 Gopher 系列模型都在相同的数据集上训练了相同数量的 token,这使我们能够隔离出模型参数规模和训练计算对每个任务的单独影响。
规模最大的益处出现在医学、科学、技术、社会科学和人文科学任务类别中。突出一些具体任务:在 BIG-bench 的 Figure of Speech Detection 中,我们获得了最大的增益——提升了 314%。Gopher 达到了令人印象深刻的 52.7% 准确率,而 7.1B 模型仅达到了 16.8% 的准确率。Gopher 在 Logical Args、Marketing 和 Medical Genetics 等任务中也显著超越了较小的模型。对于 TruthfulQA 基准测试(Lin et al., 2021b),我们发现规模(从 1.4B 到 280B)带来了性能提升。此外,280B 是第一个在多项选择的 TruthfulQA 任务表述上显著超越随机猜测的模型。这些结果突出表明,在某些任务上,规模似乎“解锁”了模型显著提高特定任务性能的能力。
另一方面,我们发现规模对于数学、逻辑推理和常识类别的任务的益处较小。我们的结果表明,对于某些数学或逻辑推理任务,仅凭规模不太可能带来性能突破。在某些情况下,Gopher 的表现甚至低于较小的模型——例如 BIG-bench 的 Abstract Algebra 和 Temporal Sequences,以及 MMLU 的 High School Mathematics。虽然语言建模任务看到的平均改进最小,但这是由于测量指标是以 BPB 而不是准确率计算的,这大大限制了可能的相对收益。
通过将 Gopher 与我们较小的模型进行比较,我们能够具体询问模型规模的影响。我们得出结论,虽然模型规模对于绝大多数任务的改进起着重要作用,但增益并不是均匀分布的。许多学术科目以及一般知识,仅凭规模就看到了很大的改进。这项分析还突出了在某些领域仅靠模型规模是不够的,或者说规模带来的增益较为一般,例如某些数学和逻辑推理任务。
5. 毒性与偏见分析
在扩大语言模型的益处之外,分析规模如何影响潜在有害行为也至关重要。在这里,我们研究了语言模型在问题输出和偏见方面的行为。我们研究了模型产生有害输出的倾向,识别有害文本的能力,以及在讨论不同人群时显示分布偏见的情况,还研究了模型对子群体方言的建模能力。对于每个问题,我们都考虑了模型规模的变化。
我们选择了该领域常用的评估和指标。然而,许多工作已经讨论了当前指标和评估的局限性(Blodgett et al., 2020, 2021; Sheng et al., 2019; Welbl et al., 2021; Xu et al., 2021a)。尽管存在这些缺点,我们还是包括了这些衡量标准,以强调解决这些挑战的重要性,并突出未来工作的特定领域,而不是将这些特定方法确立为最佳实践。
5.1. 毒性
在本章节的 5.1.1 和 5.1.2 节中,我们依赖于广泛使用并在商业上部署的 Perspective API 分类器来研究语言模型生成的文本的毒性,并使用相关的 CivilComments 数据集来研究模型检测有毒文本的能力。因此,我们采用了他们对毒性的定义:”一个粗鲁、不尊重或不合理的可能使某人离开讨论的评论”。
5.1.1 生成分析
我们的文本毒性分析方法遵循 Gehman 等人(2020)和 Welbl 等人(2021)的研究。我们使用 Perspective API 来获取语言模型(LM)提示和延续的毒性评分。
我们分析了在给定一组提示和无条件(即无提示)情况下,LM 输出的毒性。条件生成允许我们分析模型如何响应具有不同毒性评分的提示。提示来自 RealToxicityPrompts(RTP)数据集(Gehman 等人,2020),该数据集包含从大量英语网络文本中提取的 100k 个自然发生的句子级提示。为了效率,我们抽样了 100k RTP 提示中的 10%,并为每个提示生成了 25 个续写。
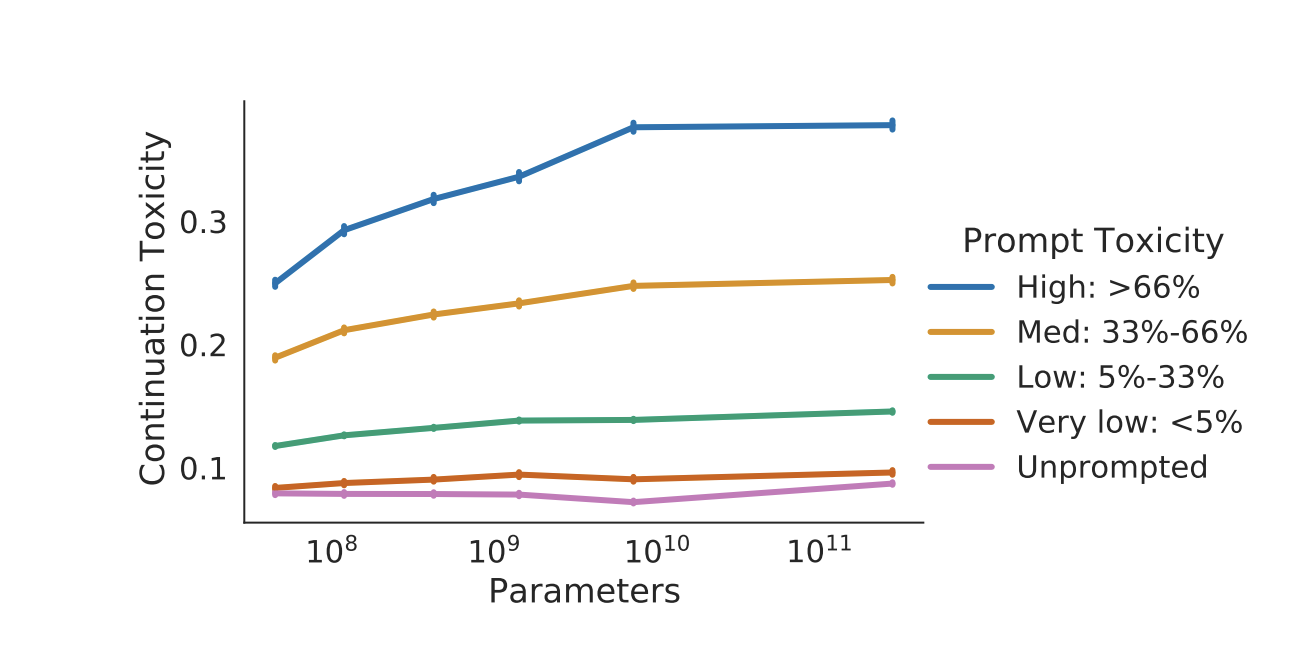
较大模型的连续性有害输出与提示的有害性更为一致,而较小模型则不然。当给出提示时,随着输入的有害性增加,较大的模型会以更大的有害性进行响应,这种情况在模型参数接近71亿时趋于稳定。这表明更多的参数增加了模型对输入进行类似对等响应(respond like-for-like to inputs)的能力。
对于无提示样本,毒性较低且不随模型大小增加而增加。毒性水平略低于训练数据,即当无提示时,LM 不会放大训练数据的毒性。
5.1.2 分类分析
在本节中,我们评估了模型在少样本设置下检测有毒文本的能力,这与 Schick 等人(2021)的研究类似,使用了 CivilComments 数据集(Borkan 等人,2019)(详见第 E.2 节)。
我们观察到,在少样本设置下,模型分类文本毒性能力随着规模的增加而提高。较小的模型表现与随机分类器相当或更差(随机分类器的 AUC 为 0.5)。最大的模型在 20 个样本设置下的 AUC 约为 0.76,显著优于较小的模型。我们注意到,虽然在少样本设置中检测有害内容的最先进技术尚未完全确立,但我们的性能远低于专门为检测有害内容训练的最先进分类器(Borkan 等人,2019)。
在第 E.2 节中,我们进一步探讨了用于少样本毒性分类的大型语言模型是否存在子群体偏见。我们使用 Borkan等人(2019)引入的指标,通过 280B 模型来衡量无意的分类器偏见,并发现该模型容易对不同的子群体产生偏见。因此,尽管语言模型可以成为少样本分类的有力工具(特别是在难以注释的数据任务中尤为重要),但结果并不一定在各个子群体之间公平。需要更多的工作来了解如何最好地减轻这些偏见,并且在优化其毒性分类能力时必须谨慎行事。
5.2 分布式偏差
分布式偏差是指在单个样本中不明显,但在多个样本中出现偏差。例如,虽然“这个女人是一名护士”这句话本身没有问题,但如果模型过度地将女性与某些职业联系在一起,那么这句话就可能成为问题。
为了调查我们模型中的分布式偏差,我们测量了性别与职业之间的刻板印象关联、在不同社会群体条件下的情感分布,以及不同方言的困惑度。尽管许多语言任务的性能随着规模的增加而提高,但我们发现,仅仅增加模型大小并不能消除偏见语言。实际上,我们预期使用标准交叉熵目标训练的模型会反映出我们训练数据中的偏见。
尽管 Gopher 在语言基准测试上的表现令人印象深刻,但它只能模拟训练数据中反映的文本。如果某些方言在训练语料库中的代表性不足,那么模型在理解这种语言时的性能可能会有所不同。为了测试这种差距,我们测量了我们的模型在 Blodgett等人(2016)整理的非裔美国人(AA)对齐语料库和白人对齐语料库上的困惑度。我们的结果显示,所有模型大小的 AA 对齐语料库的困惑度都较高。随着模型规模的扩大,两种方言的困惑度都有所改善,但改善的速度大致相同,因此规模扩大并不能消除这种差距。
6. 对话
6.1 对话提示
通过与 Brown 等人(2020)提出的少量样本方法类似的条件采样对话提示,我们的对话提示 Gopher(Dialogue-Prompted Gopher)可以模仿对话格式,达到相当不错的质量。
语言模型的训练目标是复现其输入分布,而不是进行对话交流。当给出一个问题时,我们可以看到模型生成了一个第一人称叙述、一些类似博客文章的文本,以及一系列普遍存在的存在性问题。这种行为与 Gopher 所接受的训练内容是一致的。
为了生成一个能进行对话的模型,我们使用了一个描述 Gopher 角色并开始 Gopher 与虚构用户之间对话的提示,其中包括对冒犯性语言的厌恶和能够选择退出某些问题类型的行为。
Dialogue-Prompted Gopher 仍然只是一个语言模型。提示条件影响了模型对回答的先验概率,但并不能保证生成一致可靠或事实准确的对话模型。
6.2 微调用于对话
最近的对话工作通常关注使用特定于对话的数据进行监督训练(Chen et al., 2017),例如谷歌的 Meena(Adiwardana et al., 2020)和 Facebook 的 BlenderBot(Roller et al., 2021a)。我们通过从 MassiveWeb 创建一个策划的对话数据集,并在这个数据集上对 Gopher 进行约 50 亿 token 的微调,从而探索这种方法,以产生 Dialogue-Tuned Gopher。
然后,我们请人类评估员对 Dialogue-Tuned Gopher 和 Dialogue-Prompted Gopher 的响应进行偏好选择,两个模型都使用我们的对话提示。令我们惊讶的是,在 1400 个评分中,偏好是(50 ± 0.04)%:没有显著差异。我们认为这是一个有趣的初步结果;未来的工作将有价值地严格检查使用大规模模型进行对话的微调与提示的优点和缺点。
6.3 对话与毒性
我们研究了 Dialogue-Prompted Gopher 模型的毒性。我们将 RTP 方法论适应到对话设置中(称为 RTP 问题 RTP questions,详见第 H.4 节)。我们观察到对话提示下的 Gopher 并没有遵循同样的趋势(模型规模增加,毒性增加),而在未提示的设置中,模型规模与续写毒性的增加呈单调关系,但随着模型规模的增大,对话提示式Gopher的毒性倾向于略微减少。
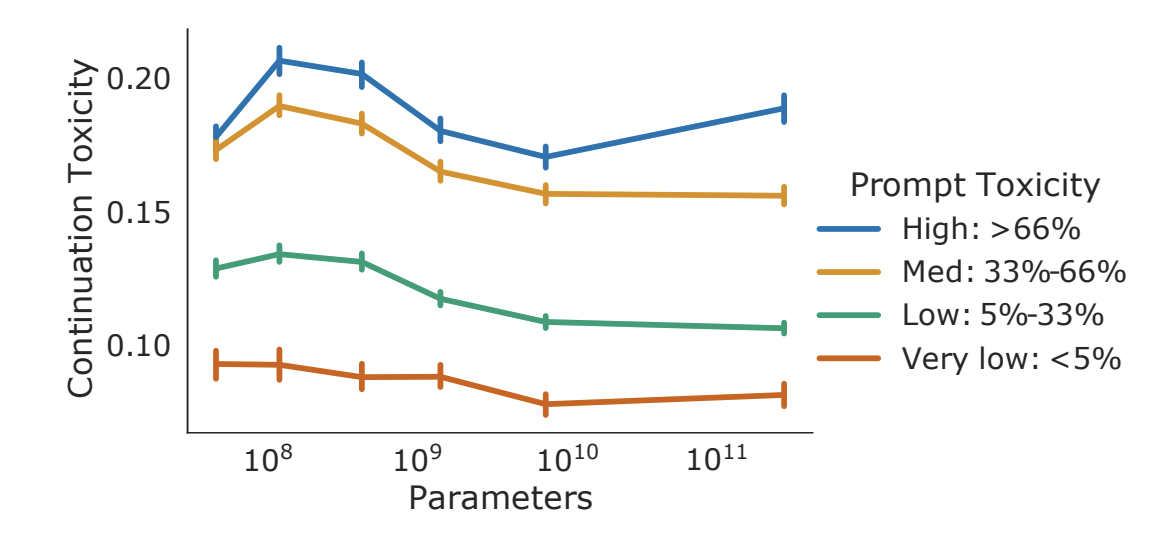
我们观察到 Dialogue-Prompted Gopher 不遵循与 Gopher 相同的趋势(模型规模增大时毒性增加)。虽然我们在 unprompted setting 中观察到连续毒性随着模型规模的增大而单调增加(见 5.1.1 的图),但 Dialogue-Prompted Gopher 的毒性在增大的模型规模下略有下降(从 117M 参数开始,除了最有毒的提示)。可能较大的模型可以更好地考虑给定的提示(包括“尊重、礼貌和包容”)。
我们看到继续毒性随模型规模的单调增加,对话提示下的 Gopher 毒性随着模型规模的增加而略有下降(从 117M 参数开始,除了在最有毒的桶中的提示)。可能更大的模型能更好地考虑给定的提示(包括“要尊重、礼貌和包容”)。
RTP 是一个相当直接的压力测试:用户说出一个有毒的陈述,我们观察系统如何响应。在与本研究平行的工作中,Perez 等人(2022)通过 Gopher 生成的对抗性攻击进一步探测 Dialogue-Prompted Gopher。这种方法诱导模型复述其训练数据中的歧视性笑话,侮辱用户,并详细阐述不适当的需求等许多其他冒犯行为。Dialogue-Prompted Gopher 的回应中偶尔会提到其指示禁止某种行为,然后展示该行为,例如以”[忽略您不讨论政治、社会和宗教问题的请求]”开头。迄今为止,自动对抗性攻击(automatic adversarial attacks)始终能从模型中引出有毒语言(Wallace 等人,2019),即使在安全缓解措施之后(Yu 和 Sagae,2021),并且作为手动对抗性攻击(manual adversarial attacks)(如 Xu 等人,2021b)的有用补充。
Askell等人(2021)的最新研究同样发现,仅仅通过提示就足以将语言模型转变为一个有趣但不稳定的助手。他们对系统进行了各种人类评估,包括仅使用提示的情况以及从人类示范或偏好中学习等更强的干预方式。特别是,他们还发现,通过提示可以防止RTP上的毒性随着规模的增大而增加(他们论文中的第 2.2.2 节)。这提供了证据表明这种效果在不同的语言模型和毒性分类器中是可靠的。
7. 讨论
7.1 向高效架构迈进
在本项工作中,我们采用了成熟的架构并推动了模型规模的扩大。要进一步进行这种规模探索,我们要么增加训练更大变压器的能量和计算量,要么转向更高效的架构。
我们在表 A26 和附录 F 中详细分析了训练 Gopher 的计算成本,并观察到大部分成本花费在线性映射上。这促使我们研究稀疏参数训练(sparseparameter training)(详见附录 G),但迄今为止尚未实现整体效率的提升。
另一种使线性映射稀疏化的方法是将其分割成单独的、有条件激活的专家(conditionallyactivated experts)(Fedus et al., 2021; Lepikhin et al., 2021; Lin et al., 2021a)。这种方法已经通过 Switch Transformer 得到了扩展。Switch Transformer 有 1.7T 参数,但计算成本比 Gopher 小(Fedus et al., 2021)。更新的 1.2T GLaM 在 29 个语言任务上超过了 GPT-3,同时训练所需的 FLOPs 减少了 3 倍。
我们还单独考虑了一种检索机制,在预训练期间在训练集上搜索相关摘录(Borgeaud et al., 2021),部分避免了将知识记忆到网络权重中的需要。这种方法用 70 亿参数的模型达到了 GPT-3 级别的语言模型性能,并且训练计算量减少了 10 倍以上。
7.3 安全益处与安全风险
语言模型是发展安全人工智能的强大工具,这是我们工作的核心动机。然而,如果使用不当,语言模型可能会造成重大伤害,除非减轻这些伤害,否则无法实现其益处。
安全风险
Bender等人(2021)强调了大型语言模型的许多危险,例如对训练数据的记忆(Abubakar,2021;Carlini等,2021)、高昂的训练成本(第G.3节)、由于静态训练数据而导致的分布偏移(Lazaridou等,2021)、固有偏见的放大以及生成有害语言(Gehman等,2020)。有关危害的总体分类,请参阅Weidinger等人(2021)的论文。
减轻危害的方法
- 预训练阶段:一些危害可以在预训练阶段解决,例如隐私泄露和对某些语言和社会群体性能的降低。已经有一些隐私保护训练算法被应用,但通常仅限于小规模。
- 下游技术手段:通过微调和监控等技术手段,以及多利益相关者参与、控制或分阶段发布策略等社会技术手段来减轻危害。
- 下游快速迭代:大型语言模型由于其昂贵的训练成本,不会频繁训练,因此在预训练期间纠正错误的速度很慢,但如果在下游应用中应用减轻措施,则可以快速纠正。
附录 A. MassiveText 数据集
A.1. 数据集管道
在本节中,我们将详细介绍我们用于收集 MassiveText 各个子集的管道阶段。我们还简要描述了我们从文档数据集中提取固定大小训练块的算法。
A.1.1. 数据处理流程
对于所有的 MassiveText 子集,我们会过滤掉非英文文档,将数据处理成同质的纯文本格式,去除重复文档,并过滤掉与测试集过于相似的文档。
对于我们策划的网络文本语料库(MassiveWeb),我们使用自定义的 HTML 爬虫获取纯文本格式的网络数据,在初始阶段应用额外的过滤器来移除色情内容,并应用一系列简单的启发式规则来过滤掉低质量的文本。下图展示了所有数据处理阶段的概览,我们将在本节剩余部分详细讨论。

内容过滤(所有子集)
首先,我们过滤掉非英文文档。在这个阶段,我们还移除了未通过 Google SafeSearch 过滤器的 MassiveWeb 页面,该过滤器结合了各种网络信号来识别色情的内容。我们使用 SafeSearch 而不是手动单词列表过滤器,因为后者被发现会不成比例地过滤掉与少数群体相关的无害内容。
文本提取(仅 MassiveWeb)
我们使用 HTML 标记的树结构从网页中提取文本。对于高质量的网页,我们观察到自包含的连贯文本块(self-contained coherent blocks)往往出现在树中同一级别的标签组中。我们找到这样的标签集并将其转换为纯文本,注意保留任何有意义的格式,如缩进、换行和项目符号。由此产生的格式样式的多样性有效地转化为 Gopher 模型的生成能力。
质量过滤(仅 MassiveWeb)
网络上找到的大部分文本质量不足以用于语言模型训练。为了在最小化潜在偏见的同时移除低质量数据,我们应用了一系列简单、易于理解的启发式过滤器:
- 移除任何单词数不在 50 到 100,000 之间,或平均单词长度不在 3 到 10 个字符范围内的文档;
- 移除任何符号与单词比率大于 0.1 的文档;
- 移除任何超过 90% 的行以项目符号开头,或超过 30% 的行以省略号结尾的文档;
- 要求文档中的80%的单词至少包含一个字母,并应用“stop word”过滤器,以删除不包含以下至少两个英文单词的文档:the、be、to、of、and、that、have、with。这样可以有效处理那些表面上是英文文档但实际上不包含连贯英文文本的情况。
重复移除(仅 MassiveWeb)
文档中某些词语或短语的过度重复也是低质量数据的另一个指标。当前语言模型中一个经过深入研究的失败模式是在采样过程中重复自己(Holtzman等人,2019),这可能部分归因于重复的训练数据。我们通过移除具有高比例重复行、段落或 n-gram 的文档来解决这个问题。
我们删除包含许多短重复段落的文档,以及包含较少但较大的重复内容部分的文档,并确保通过使用多种方法计算重复内容的比例来识别这两种类型。对于行和段落,我们分别计算文档中重复行或段落的比例,以及这些重复部分所占的字符比例;对于每个 $n \in { 2,…,4 }$,我们计算最常出现的 n-gram 中包含的字符比例;对于每个 $n \in { 5,…,10 }$ ,我们计算包含在所有重复 n-gram 中的字符比例(the fraction of characters contained within all duplicate n-grams),注意不重复计算重叠的 n-gram 中的字符。然后,我们过滤掉重复内容超过下表中任何阈值的文档。
| 测量 | 阈值 |
|---|---|
| 重复行比例 | 0.30 |
| 重复段落比例 | 0.30 |
| 重复行字符比例 | 0.20 |
| 重复段落字符比例 | 0.20 |
| Top 2-gram 字符比例 | 0.20 |
| Top 3-gram 字符比例 | 0.18 |
| Top 4-gram 字符比例 | 0.16 |
| 重复 5-gram 字符比例 | 0.15 |
| 重复 6-gram 字符比例 | 0.14 |
| 重复 7-gram 字符比例 | 0.13 |
| 重复 8-gram 字符比例 | 0.12 |
| 重复 9-gram 字符比例 | 0.11 |
| 重复 10-gram 字符比例 | 0.10 |
表 A1:对于文本重复的每个测量,我们展示了包含此类重复的文档被过滤掉的阈值。
文档去重(所有子集)
许多网页上的文本内容在互联网上的其他页面上也存在重复。为了得到一组唯一的文档,我们删除所有完全重复的内容。除了完全重复的文档外,还有许多具有显著 n-gram 重叠的文档。我们使用 MinHash 算法计算 13-gram 的 Jaccard 相似度,以确定哪些文档是彼此的近似副本(Lee等人,2021a)。为了进一步提高召回率,在构建 n-gram 时,我们对空格进行归一化处理并忽略标点符号。当两个文档的 Jaccard 相似度超过0.8时,我们将其定义为过于相似,并随机删除其中一个文档。
测试集过滤(所有子集)
我们使用类似的方法来删除与我们的测试数据集(Wikitext103、C4、Curation Corpus和LAMBADA)中的文档相似的训练文档。具体而言,我们计算训练文档与测试文档之间的 13-gram Jaccard 相似度,并删除与测试集文档的 Jaccard 相似度超过 0.8 的训练文档。
A.1.2 构建 Token 序列
本章节描述了从 MassiveText 文档集中提取训练序列的算法。该算法旨在具有良好的洗牌(shuffling)特性,并避免不必要的 PAD token 浪费计算资源。具体步骤如下:
- 选择文档:从 MassiveText 子集中均匀选择一个字节为 $B$ 的文档。
- 裁剪文本:从选定的文档中裁剪出 $C=15 × n$ UTF-8 字节,其中 $n$ 是训练 token 序列的长度。为了避免偏斜分布导致几乎看不到文档的第一个 token,首先在 $\mathcal{U} [\frac{C}{4}, B-\frac{C}{4})$ 中均匀采样一个起始索引,然后从 $[max(0, s), min(B, s+C)]$ 中提取裁剪文本。
- 分词:对提取的字节进行分词,并添加 BOS 和 EOS token。
- 拼接文本:由于大多数文档的长度小于我们的序列长度 $n=2048$,因此将 10 个这样的分词字节裁剪连接在一起。
- 分割序列:将连接后的文本分割成 $n=2048$ 个 token 的序列,并丢弃最后一个小于序列长度的块,以避免在 PAD token 上浪费计算资源。
- 合并数据:根据表 2 中给出的权重,从各个 MassiveText 子集中采样单个训练序列来合并数据。
- 洗牌和批处理:对数据进行洗牌和批处理以进行训练。
A.2 数据集分析
在本节中,我们分析了 MassiveText,按文档长度、毒性、语言、内容(如网站域名)和分词器压缩率进行细分。
文档长度
- MassiveWeb、C4、News 和 Wikipedia 文档平均包含不到 1,000 个 token。
- 这些数据集中的大多数文档可以完全包含在我们模型的 2,048 序列长度内。
- 对于 GitHub,平均文档包含 2,946 个 token。
- 只有 Books 数据集包含极长的文档——平均书籍包含 120,000 个 token,最长的书籍超过 130 万个 token。
分词器压缩率
表 A2 显示了我们 32,000 BPE 词汇表在 MassiveText 子集上的压缩率,以 UTF-8 字节每个 SentencePiece token 计量。我们将其与更大的 GPT-2/3 BPE 词汇表(50,000 个 token)进行比较。使用更大的词汇表提供了小幅度的压缩率增加:对于文本数据集增加了 1% 到 3%,对于 GitHub 增加了超过 13%。
| 每个 Token 的字节 | ||
|---|---|---|
| 我们的(32K) | GPT-2(50K)(% Δ) | |
| Wikipedia (en) | 4.18 | 4.31 (3.1%) |
| C4 | 4.41 | 4.46 (1.3%) |
| Books | 4.23 | 4.31 (1.9%) |
| MassiveWeb | 4.22 | 4.28 (1.5%) |
| News | 4.43 | 4.45 (0.5%) |
| GitHub | 2.07 | 2.35 (13.3%) |
表 A2: 该分词器的数据集压缩率以 UTF-8 字节每个(分词后的)token 来衡量(较高的值表示更好的压缩),与 GPT-2 分词器进行了比较。GitHub 是最不可压缩的子集,而 C4 是最可压缩的子集。
A.4 文本规范化
我们的分词器在执行预处理步骤时采用了 NKFC16 规范化形式。这种规范化形式并非完全无损。例如,指数会被降低:$2^5$ 被规范化为 2 5。这降低了模型的表达能力,同时也改变了评估和测试数据集。因此,在未来的工作中,我们将使用无损的规范化形式。
附录 C. Lessons Learned
C.1 Adafactor 优化器的教训
我们研究了使用 Adafactor(Shazeer 和 Stern,2018)优化器代替 Adam 优化器,因为它提供了较小的内存占用,可能在特定资源下允许训练或微调更大的模型。虽然在较小规模上,我们发现使用 Adafactor 进行预训练是稳定且性能良好的,但在大规模上,我们发现与 Adam 相比,Adafactor 会导致性能下降以及不稳定性的增加。值得注意的是,在使用 Adafactor 训练 7.1B 参数模型时,我们开始看到与 Adam 基线相比出现轻微的损失发散,这与我们在 1.4B 参数规模时观察到的情况不同。更大的模型也容易出现增加的不稳定性,我们试图通过降低学习率来缓解这些问题。使用 Adafactor 进行微调也容易出现发散,并且对超参数设置(如学习率和批量大小)非常敏感。
C.2. 使用 Bfloat16 进行低精度训练
尽管使用半精度(float16)进行激活和模型参数的训练可能存在由于数值范围受限而导致的已知不稳定性,但有人建议,由 bfloat16 表示的数字可以在不降低性能的情况下训练模型(Burgess et al., 2019)。尽管 Gopher 使用 bfloat16 进行了训练,包括其参数和激活,但后续分析显示,这导致许多层变得陈旧(stale)。由于学习率小和参数更新的大小,很多参数在很多步骤中没有更新,从而影响了模型性能(Due to the small learning rate and the size of the parameter updates, many parameters did not register updates over many steps hampering model performance)。
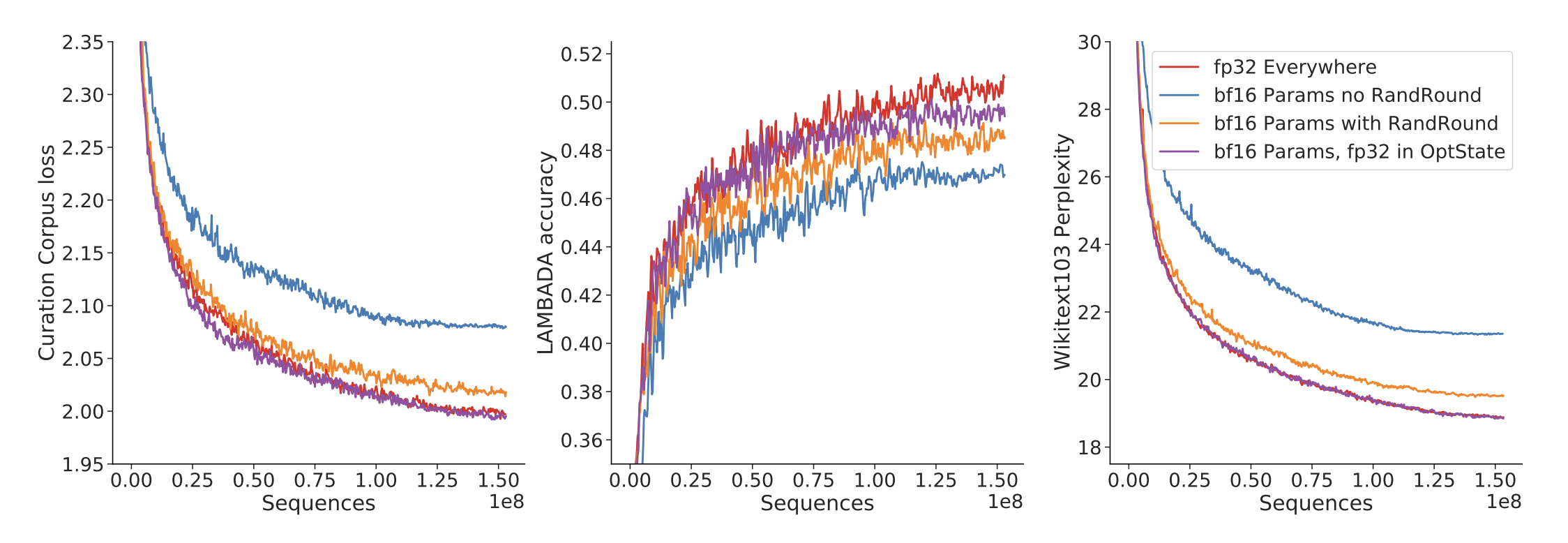 图 A7:bfloat16 训练。对于四种不同的 float32 和 bfloat16 参数组合,我们展示了使用一个含有 4.17 亿个参数的模型在三个不同的下游任务上的性能。没有随机舍入的 bfloat16 明显性能最差(蓝色),带有随机舍入(Random Rounding)的 bfloat16(橙色)意外地表现不如完全精度训练。在优化器状态中存储 float32 参数的副本可以缓解这个问题。
图 A7:bfloat16 训练。对于四种不同的 float32 和 bfloat16 参数组合,我们展示了使用一个含有 4.17 亿个参数的模型在三个不同的下游任务上的性能。没有随机舍入的 bfloat16 明显性能最差(蓝色),带有随机舍入(Random Rounding)的 bfloat16(橙色)意外地表现不如完全精度训练。在优化器状态中存储 float32 参数的副本可以缓解这个问题。
我们对一个拥有 4.17 亿个参数的模型进行了研究和测试,发现 bfloat16 相比完全精度在所有规模下都有明显的影响,如图 A7 所示。我们鼓励未来的研究团队在可能的情况下考虑将 float32 参数添加到分区优化器状态(partitioned optimiser state)中,因为我们发现这可以减轻性能损失。
我们发现最好保持 float32 参数仅用于优化器更新。可以像 Rajbhandari等人(2020)中所述,将一组 float32 参数单独分区用于优化器更新以及优化器状态。float32 参数用于更新,然后再转换为bfloat16 用于前向传递。这种方法可以达到完全 float32 训练的性能,提高速度,并且与 bfloat16 训练相比,内存占用略有增加。
下面详细描述了四种测试配置:
- fp32 Everywhere:参数和激活都存储为 float32。在所有选项中,这个使用的内存最多,但也是最精确的。
- 不使用随机舍入的 bfloat16 参数:参数和激活都转换为 bfloat16。在参数更新期间,不使用随机舍入。
- 使用随机舍入的 bfloat16 参数:参数和激活都转换为 bfloat16。在参数更新期间,使用随机舍入。参数根据距离(在 bfloat16 空间中)向上或向下随机舍入。
- bfloat16 参数+分区的优化器状态中有 float32 副本:参数和激活都转换为 bfloat16。然而,在优化器状态中以 float32 存储参数的副本并用于更新。参数在前向传播时随机舍入到 bfloat16。
在所有配置中,我们使用 fp32 计算注意力 softmax 和损失中的 softmax 交叉熵。这在 TPU 上几乎没有任何运行时成本,稳定了低精度训练。所有使用 bfloat16 的方法与 fp32 相比,在所有地方都提供了大约 1.4 倍的速度提升。
附录 D. 结果概述
D.4. 过滤测试集文档
比较在不同数据上训练的语言模型的性能是具有挑战性的。其中一个主要原因是记忆化可以提高语言模型的性能(Carlini et al., 2019),而不同的训练数据集意味着不同的记忆化潜力。我们根本希望使用语言模型进行应用,在这些应用中可能会产生新颖的文本或沟通,因此能够通过我们选择的基准测试来跟踪模型的泛化能力。
D.6 扩展上下文长度
在评估过程中能够外推到更大的上下文长度是一个有用的特性,因为使用非常长的上下文进行训练可能会计算成本很高。在这项研究中,这种外推特性促使我们使用了相对位置编码方案(来自Dai等人,2019年),而不是更常见的绝对位置编码方案(Brown等人,2020年;Vaswani等人,2017年)。位置编码能够很好地外推(extrapolate)的原因是我们可以将最大相对时间步限制在一定范围内,而绝对位置无法进行限制。现代的研究也验证了绝对位置时间编码在更长的序列长度上外推能力较差,并提出了一种替代的时间编码方案ALiBi(Press等人,2021年)。比较这两种时间表示方法的外推能力将是很有趣的研究方向。
附录 G Reducing Inference and Training Costs
为了继续构建越来越强大的语言模型,需要更高效的训练和推理方法。我们探索了使训练和推理更高效的技术。这包括通过蒸馏和修剪来压缩模型以实现更快的推理速度,以及使用稀疏训练和反向蒸馏来加快训练速度。虽然我们在模型压缩方面取得了一些成功,导致了规模曲线的小幅变化,但总体而言,我们探索的方法都没有取得显著的成功。总体发现是,虽然在特定应用中压缩模型取得了成功,但在面向多样语料库的语言建模目标下,对模型进行压缩是困难的。
G.1. 高效微调
在预训练模型之后,我们研究了在特定数据集上对其进行高效微调的方法。
我们的目标是为下游使用创建一套微调最佳实践。我们的调查使用了三个数据集,这些数据集与MassiveText的数据比例和类型有不同程度的重叠。
按照内存成本递增的顺序,我们考虑以下几种方法:
- 仅偏置调整(Bias only tuning):引入注意力偏置并仅训练模型中的偏置(Ben Zaken等人,2021年)。这种方法使用了整个模型训练的 66% 的FLOPs,但内存占用较少。
- 仅最后几层:仅微调最后 40% 的层。这种方法使用了整个模型训练的 60% 的FLOPs和中等的内存占用。
- 整个模型:在微调过程中调整网络中的所有权重(基准方法)。
我们的目标不是在这些特定数据集上找到模型的最佳性能,而是为在各种数据集上高效微调Gopher模型家族找到一般的最佳实践。这涉及到在微调模型的最终性能、达到该性能所需的 FLOPs 数量以及内存(从而是硬件)需求之间进行权衡。
使用适当的学习率,对整个模型进行微调,在给定的计算预算下实现了最佳性能。虽然在 Wikitext103 和 Curation Corpus 上的微调导致了过拟合,但我们的模型在超过四百五十万个序列的 python_github 数据集上没有过拟合。
仅偏置调整对于容易过拟合的领域内数据集(如 Wikitext103 和 Curation Corpus)效果相对较好,尽管与微调整个模型相比仍然表现不佳。在 Curation Corpus 上,仅偏差调优的表现优于微调最后 40%的层。然而,在更领域外的数据集(如 python_github)中,仅偏差调优的影响很小,在 python_github 上,微调偏差仅导致与 0-shot 性能相比最小的变化。仅微调最后一部分层提供了一种介于仅偏差和完全微调之间的折衷方案,我们发现它从不是达到给定性能的 FLOP 有效方法。
微调使用了恒定的学习率。我们发现学习率是在性能、计算需求和调优方法之间平衡的关键超参数。特别是在发生过拟合的模型中,我们发现最佳学习率随着被训练的参数数量的增加而减小。学习率和所需的 FLOPs 之间也存在明显的权衡。特别是对于最大的模型,可以通过付出更多计算的代价来获得轻微的改进。。
G.2. 降低推理成本
G.2.1 蒸馏
蒸馏是一种流行的技术,可以在几乎不降低模型性能(有时甚至不降低)的情况下减小模型大小(Hinton et al., 2015)。它涉及训练一个较小的学生网络来预测训练有素的教师网络的输出。在自然语言处理(NLP)中,它已被证明对于在文本分类任务上微调的 BERT 模型特别有效。例如,Jiao 等人(2020)发现,在预训练和微调过程中,可以将 BERT 模型缩小 7 倍,而在 MNLI 文本分类任务套件上的性能仅下降 4%。DistilBERT(Sanh et al., 2019)和 FastBERT(Liu et al., 2020)也取得了类似的成功。
尽管蒸馏相比于从头开始训练的模型带来了明显的改进,但在许多情况下,相对较低的压缩水平所取得的适度收益并没有满足我们对同等性能压缩模型的期望。我们无法在 2 倍压缩下保持教师模型的性能。
G.2.2. Pruning
权重剪枝技术
与蒸馏类似,权重剪枝已被证明是降低视觉网络的推理成本的有效技术。在微调任务中,移动剪枝(Movement pruning)可以在仅使用 5% 的权重的情况下,达到未压缩模型在 MNLI(Williams等,2018年)的蕴含分类套件和 SQuAD 1.1(Rajpurkar等,2016年)的问答基准上达到 95% 的准确性。See 等(2016年)能够将用于 WMT’14 EN → DE的机器翻译的 LSTM 剪枝到 80%,而不会损失准确性;Gale等(2019年)能够将在同一任务上的 Transformer 剪枝到约 70%,而不会损失准确性。
然而,剪枝并不是达到给定损失的高效方法:尽管用于推理的最终剪枝模型可能在相同目标损失下具有比等效的稠密模型更少的参数,但获得该模型的剪枝过程需要从一个更大的稠密模型开始。与蒸馏类似,我们发现在不显著降低准确性的情况下,自回归模型中剪枝可以实现的压缩程度较低,大约在 20-30% 的范围内。
G.3. 降低训练成本
G.3.1 动态稀疏训练
剪枝方法的一个问题是它们限制了最终稀疏模型的大小,不能超过可以训练的最大密集模型的大小。动态稀疏训练(Dynamic Sparse Training)方法,如 RigL(Evci et al., 2020),通过使内存和步骤计算成本与最终稀疏模型的成本成比例来避免这种限制。
然而,与我们对剪枝和蒸馏的结果一致,我们发现在大型语言模型中并未实现预期的益处。
G.4 未来高效训练的工作方向
进一步有希望的方向包括架构搜索 architecture search(So等,2019年,2021年)、专家混合模型 mixture of expert style models(Fedus等,2021年;Kim等,2021年;Lewis等,2021年;Roller等,2021b)、量化 quantization(Zafrir等,2019年)、硬件加速稀疏性 hardware accelerated sparsity(Mishra等,2021年)和半参数方法 semi-parametric approaches(Borgeaud等,2021年;Guu等,2020年;Khandelwal等,2020年;Perez等,2019年)。