本文是 《GQA: Training Generalized Multi-Query Transformer Models From Multi-Head Checkpoints》 的笔记。
Google Research Abstract
多查询注意力(Multi-query attention,MQA):只使用单个键值头,大幅加快解码器推理速度。然而,MQA 可能导致质量下降。我们:
- 提出一种方法,使用原始预训练计算量的 5%,将现有的多头语言模型 checkpoint 升级为多查询注意力(MQA)的模型。
- 引入了分组查询注意力(Grouped-query attention,GQA),这是 MQA 的泛化,它使用中间数量(多于一个,少于查询头数量)的键值头。
我们证明了升级后的 GQA 在质量上接近多头注意力(multi-head attention),同时速度与 MQA 相当。
1 Introduction
自回归解码器推理对于 Transformer 模型来说是一个严重的瓶颈,因为在每个解码步骤中,加载解码器权重以及所有注意力键和值会导致内存带宽开销过大(Shazeer, 2019; Pope et al., 2022; de Jong et al., 2022)。通过使用多个查询头但单个键和值头的 MQA,可以大幅减少加载键和值的内存带宽(Shazeer, 2019)。然而,MQA 可能导致质量下降和训练不稳定,并且训练出同时优化质量和推理的单独模型可能并不可行。
本研究包含两个有助于大型语言模型更快推理的贡献:
-
多头注意力(MHA)的检查点升级:我们展示了具有多头注意力(MHA)的语言模型检查点可以通过升级训练(uptrained)(Komatsuzaki et al., 2022)来使用 MQA,并且只需要原始训练计算的一小部分。这提供了一种成本效益高的方法,可以获得快速的多查询以及高质量的 MHA 检查点。
-
分组查询注意力(GQA):我们提出了一种介于多头注意力和多查询注意力之间的插值方法,即分组查询注意力(GQA),每个查询头子组都有单个键和值头。我们展示了升级训练后的 GQA 在质量上接近多头注意力,同时几乎和多查询注意力一样快。
2 方法
2.1 Uptraining
从多头模型生成多查询模型分为两个步骤:首先,转换检查点;其次,进行额外的预训练,使模型适应其新结构。
图 1 展示了将多头检查点转换为多查询检查点的过程。所有头的键和值投影矩阵被平均池化成单个投影矩阵,我们发现这比选择单个键和值头或从头开始随机初始化新的键和值头效果更好。
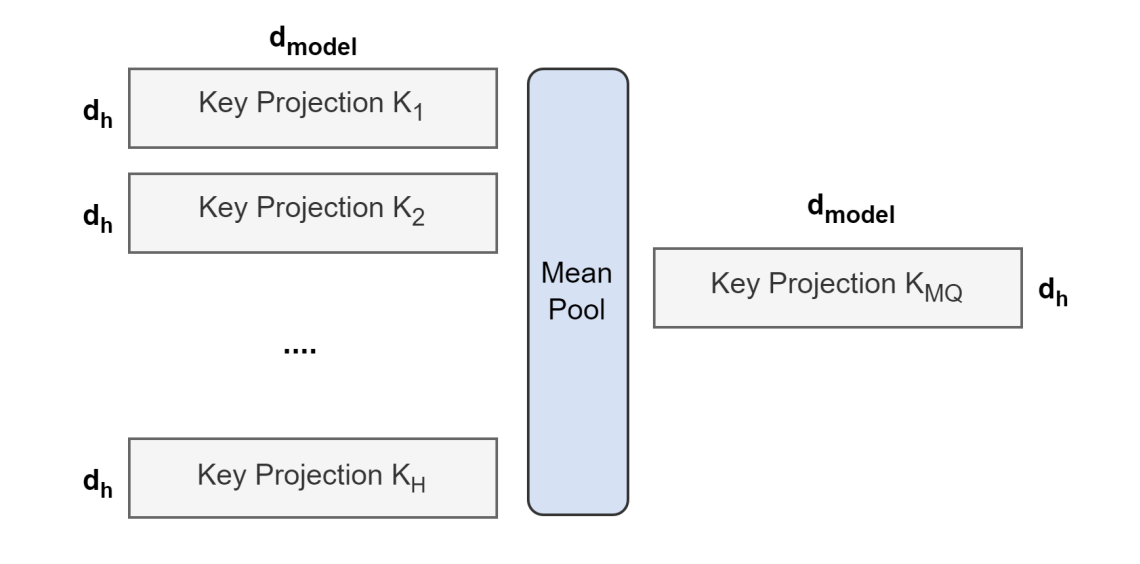 图1:来自所有头部的键和值投影矩阵被平均汇聚成一个单独的头部
图1:来自所有头部的键和值投影矩阵被平均汇聚成一个单独的头部
转换后的检查点随后在相同的预训练配方上进行较小比例 $\alpha$ 的原始训练步骤的预训练。
2.2 分组查询注意力
分组查询注意力将查询头分为 G 组,每组共享一个键头和一个值头。GQA-G 指的是有 G 组的分组查询。GQA-1 只有一组,因此只有一个键头和一个值头,相当于 MQA;而 GQA-H 的组数等于头的数量,相当于 MHA。
图 2 展示了分组查询注意力和多头/多查询注意力的比较。在将多头检查点转换为 GQA 检查点时,我们通过对该组内所有原始头进行平均池化来构造每个组的键头和值头。

图2:多头注意力有 H 个查询、键和值头。多查询注意力在所有查询头之间共享单个键和值头。分组查询注意力则为每组查询头共享单个键和值头,在多头和多查询注意力之间进行插值。
中等数量的组可以产生一个插值模型,其质量高于 MQA 但速度快于 MHA,并且如我们将展示的,代表了一个有利的权衡。从 MHA 到 MQA 将 H 个键头和值头减少到单个键头和值头,减少了键值缓存的大小,因此需要加载的数据量也减少了 H 倍。然而,更大的模型通常会增加头的数量,这导致 MQA 在内存带宽和容量上更激进的削减。GQA 让我们在模型大小增加时保持相同的带宽和容量比例减少。
此外,更大的模型相对较少受到注意力带来的内存带宽开销的影响,因为 KV 缓存随模型维度扩展,而模型的 FLOPs 和参数随模型维度的平方扩展。最后,大型模型的 standard sharding 会按模型分区的数量复制单个键头和值头(Pope et al., 2022);GQA 消除了这种分片的浪费。因此,我们预计 GQA 对于更大的模型来说将呈现一个特别好的权衡。
我们注意到 GQA 无需应用于编码器自注意力层;编码器采用并行计算,因此内存带宽通常不是主要瓶颈。
4 相关工作
本工作旨在通过减少加载键和值时的内存带宽开销(Williams et al., 2009),在解码器质量和推理时间之间实现更好的权衡。Shazeer(2019)首次提出通过多查询注意力来减少这种开销。后续工作表明,多查询注意力特别有助于处理长输入(Pope et al., 2022; de Jong et al., 2022)。
还有许多其他方法被提出来减少键和值以及参数的内存带宽开销。Flash attention 通过避免实现二次注意力分数来结构化注意力计算,从而减少内存并加速训练。Quantization 通过降低精度来减小权重和激活的大小,包括键和值。Model distillation 则在给定精度下减小模型大小,使用从较大模型生成的数据来微调较小的模型。Layersparse cross-attention 消除了构成较长输入主要开销的大多数交叉注意力层。Speculative sampling 提出使用一个较小的模型生成多个候选标记,然后由一个较大的模型并行评分来改善内存带宽瓶颈。
5 总结
局限性
本文重点在于改善加载键和值时的内存带宽开销。当生成较长序列时,内存带宽的开销最为重要,而长序列的质量评估本身就具有难度。例如,在摘要生成任务中,我们使用了 Rouge 评分作为评估指标,但这个指标是有缺陷的,不能反映全部情况;因此很难确定我们所做的权衡是否正确。由于计算资源有限,我们也没有将 XXL GQA 模型与从头开始训练的对比模型进行比较,所以我们不知道增量训练(uptraining)与从头训练(training from scratch)的性能比较。我们只评估了增量训练和 GQA 对编码器-解码器模型的影响。最近 decoder-only 的模型非常流行,由于这些模型没有单独的自注意力(self-attention)和交叉注意力(cross-attention),我们预计 GQA 相比于 MQA 会有更大的优势。