本文是《LLMs For Knowledge Graph Construction And Reasoning: Recent Capabilities And Future Opportunities》的笔记。
摘要
本文对大型语言模型(LLMs)在知识图谱(KG)构建和推理方面的能力进行了全面的定量和定性评估。我们在八个不同的数据集上进行了实验,涵盖了实体和关系提取、事件提取、链接预测和问答四个代表性任务,从而深入探讨了 LLMs 在构建和推理领域的性能。根据我们的实证研究结果,我们发现表明 GPT-4 等语言模型(LLMs)更适合作为推理助手,而不是少样本信息提取器(few-shot information extractors)。具体来说,尽管 GPT-4 在知识图谱构建相关的任务中表现良好,但在推理任务中表现更为出色,在某些情况下甚至超过了微调模型。此外,我们的研究还探讨了 LLMs 在信息提取方面的潜在泛化能力,提出了一个虚拟知识提取任务,并开发了相应的 VINE 数据集。基于这些实证发现,我们进一步提出了AutoKG,一种基于多代理的方法,利用 LLMs 和外部资源进行知识图谱的构建和推理。
1 Introduction
知识图谱(KG)是由实体、概念和关系组成的语义网络,可以推动各种场景下的应用。构建知识图谱通常涉及多个任务,如命名实体识别(Named Entity Recognition,NER)、关系抽取(Relation Extraction,RE)、事件抽取(Event Extraction,EE)和实体链接(Entity Linking,EL)。此外,链接预测(Link Prediction,LP)是知识图谱推理的关键步骤,对于理解构建的知识图谱至关重要。这些知识图谱在问答(QA)任务中也占据核心地位,特别是在基于问题上下文进行推理时,涉及关系子图的构建和应用。本文实证研究了大型语言模型(LLMs)在知识图谱领域的潜在应用性,以 ChatGPT 和 GPT-4 为例。研究从评估 LLMs 的基本能力开始,进而探索可能的发展方向,旨在加深我们对 LLMs 的理解,并为知识图谱领域引入新的视角和方法。
Recent Capabilities
实体和关系抽取以及事件抽取对于知识图谱构建任务至关重要。它们在将大量实体、关系和事件数据组织成结构化表示方面起着关键作用,构成了构建和丰富知识图谱的基础要素。同时,作为知识图谱推理的核心任务,链接预测旨在揭示实体之间的潜在关系,从而丰富知识图谱。我们深入研究了 LLMs 在基于知识的问答任务中的应用,以全面了解它们的推理能力。鉴于这些考虑,我们选择这些任务作为代表,用于评估知识图谱构建和推理。如图 1 所示,我们的初步调查针对大型语言模型在上述任务中 zero-shot 和 one-shot 的能力。这个分析旨在评估这些模型在知识图谱领域的潜在用途。实证研究结果表明,像 GPT-4 这样的 LLMs 在 few-shot 信息提取方面的效果有限,但作为 inference assistant 表现出相当高的能力水平。
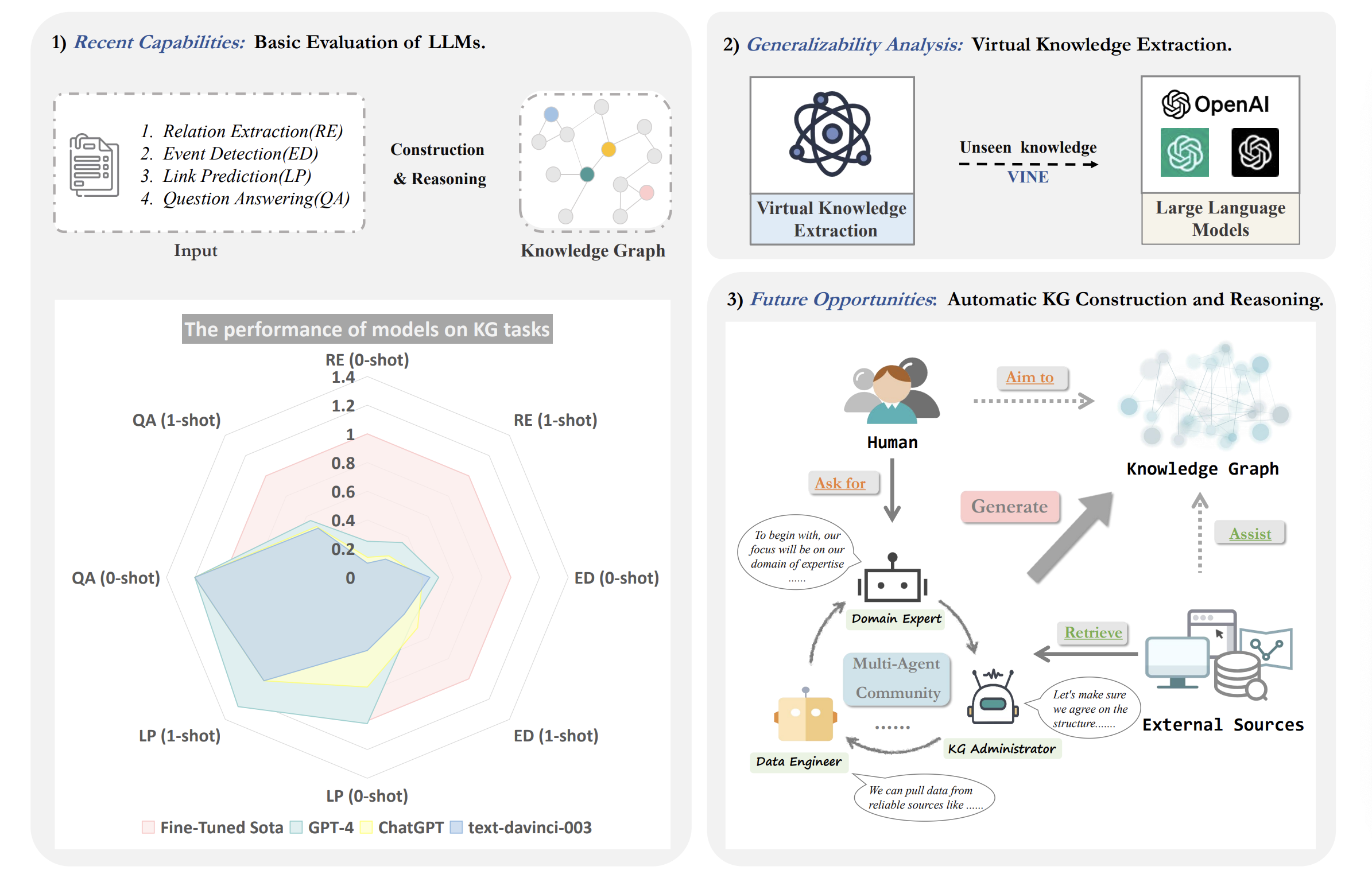
图1:我们工作的概述。有三个主要组成部分:1)基本评估:详细说明了我们对大型模型(text-davinci-003、ChatGPT 和 GPT-4)在 zero-shot 和 one-shot 设置下的评估,使用完全监督的最先进模型的性能作为基准;2)虚拟知识提取:对 LLM 在构建的 VINE 数据集上的虚拟知识能力进行检查;3)自动知识图谱:提出利用多个代理来促进知识图谱的构建和推理。
Generalizability Analysis: Virtual Knowledge Extraction
为了深入探讨 LLMs 在信息抽取任务中的行为,我们设计了一个名为虚拟知识抽取(Virtual Knowledge Extraction)的独特任务,旨在评估 LLMs 泛化和抽取不熟悉知识的能力。这项工作旨在辨别观察到的任务性能提升是由于 LLMs 内部庞大的知识库,还是由于指令调整(instruction tuning)和基于人类反馈的强化学习(RLHF)所带来的强大泛化能力。
Future Opportunities: Automatic KG Construction and Reasoning
鉴于大型模型的显著泛化能力,我们选择利用它们来协助知识图谱的构建。与较小的模型相比,这些 LLMs 减少了潜在的资源浪费,并在新颖或数据稀缺的情况下表现出显著的适应能力。然而,需要认识到它们对 prompt 工程的强烈依赖以及知识截止的固有限制。因此,研究人员正在探索交互机制,使 LLMs 能够访问和利用外部资源,以进一步提高它们的性能。
在此基础上,我们引入了 AutoKG 的概念——通过多代理通信实现自主知识图谱构建和推理。在这个框架中,人类的角色被减少,多个通信代理各自发挥作用。这些代理与外部资源互动,协作完成任务。
总结贡献
- 我们评估了包括 ChatGPT 和 GPT-4 在内的 LLMs,在八个基准数据集上评估它们在知识图谱构建和推理方面的 zero-shot 和 one-shot 性能,从而初步了解它们的能力。
- 我们设计了一个新颖的虚拟知识抽取任务,并构建了 VINE 数据集。通过在 VINE 数据集上评估 LLMs 的性能,我们进一步证明了像 GPT-4 这样的 LLMs 具有强大的泛化能力。
- 我们引入了自动知识图谱构建和推理的概念,称为 AutoKG。利用 LLMs 内部的知识,我们使多个 LLMs 代理能够通过迭代对话协助这一过程,为未来的研究提供了见解。
2 近期 LLMs 在知识图谱构建与推理中的能力
2.1 评估原则
在本研究中,我们对以 GPT-4 为代表的 LLMs 进行了全面评估,并特别分析了 GPT-4 与 GPT 系列中其他模型(如 ChatGPT)之间的性能差异和提升。主要的研究领域是模型在 zero-shot 和 one-shot 任务中的表现,因为这些任务可以揭示模型在数据有限条件下的泛化能力。由于我们研究中的一些实验依赖于数据集随机抽样的子集,因此需要注意的是,由于这种抽样方法,结果可能存在变化。我们故意选择 zero-shot 和 one-shot 任务,而不是需要更多示例的任务,因为它们更好地测试了模型在数据稀疏场景中的适应性和实际应用。利用评估结果,我们的目标是探索模型在特定任务中卓越表现背后的原因,并确定潜在的改进领域。最终,我们的目标是为这些模型的未来发展提供有价值的见解。
2.2 知识图谱构建与推理
2.2.1 设置
在实体和关系抽取、事件抽取任务中,我们使用了 DuIE2.0、SciERC、Re-TACRED 和 MAVEN 数据集。在链接预测任务中,我们使用了 FB15K-237 和 ATOMIC 2020 数据集。最后,在问答任务中,我们使用了 FreebaseQA 和 MetaQA 数据集。
2.2.2 总体结果
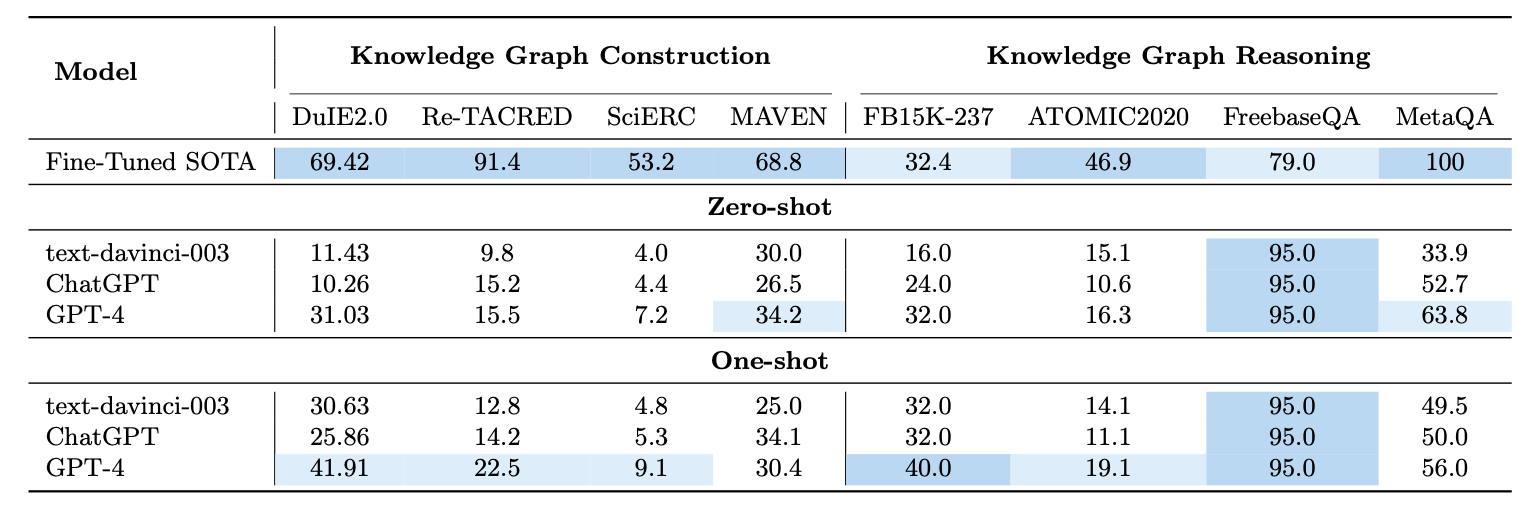
表 1:知识图谱构建和知识图谱推理任务。
实体和关系提取
我们对 DuIE2.0、ReTACRED 和 SciERC 进行了实验,每个数据集的测试/验证集中包含了 20 个样本,涵盖了数据集中存在的所有关系类型。在每个数据集上,我们使用 PaddleNLP LIC2021 IE 2、PL-Marker 和 EXOBRAIN 作为基准线。为了评估模型的性能,我们使用标准的 micro F1 score 进行报告。如表 1 所示,与 ChatGPT 相比,GPT-4 在零样本和一样本任务中表现相对较好,尽管其性能尚未超过完全监督的小型模型。
- Zero-shot:GPT-4 zero-shot 的表现在所有测试的数据集上显著提高。具体来说,在图 2 中的 Re-TACRED 示例中,ChatGPT 未能提取出目标三元组,相比之下,GPT-4 给出了正确答案 “org:alternate names”,突显了其优秀的语言理解能力。
- One-shot:文本指令的优化已被证明可以提高语言模型的性能。在图 2 所示的 DuIE2.0 的情境中,GPT-4 从关于 George Wilcombe 与洪都拉斯国家队的关联的陈述中辨别出了隐含的关系。这种准确性归因于 GPT-4 的广泛知识库,它有助于推断 George Wilcombe 的国籍。然而,也观察到 GPT-4 在处理复杂句子时遇到了挑战,prompt 的质量和关系的歧义等因素会影响结果。

图2:ChatGPT 和 GPT-4 在 RE 数据集上的示例。 (1) 在 SciERC 数据集上的 zero-shot 情况 (2) 在 Re-TACRED 数据集上的 zero-shot 情况 (3) 在 DuIE2.0 数据集上的 one-shot 情况
事件提取
为了简化,我们在 MAVEN 的 20 个随机样本上进行了事件检测实验,涵盖了所有事件类型。使用 Fscore 指标,将 GPT-4 的性能与现有的最先进(State-of-the-Art,SOTA)模型以及其他 GPT 系列模型进行了基准测试。根据我们的结果,GPT-4 在超越 SOTA 方面表现不稳定,GPT-4 和 ChatGPT 在不同场景下相互超越。
-
Zero-shot:如表 1 所示,GPT-4 的表现优于 ChatGPT。对于句子 “Now an established member of the line-up, he agreed to sing it more often.”,ChatGPT 生成了 “Becoming a member” 的结果,而 GPT-4 则识别出了两个额外的事件类型:”Agree or refuse to act” 和 “Performing”。值得注意的是,在这个实验中,ChatGPT 经常提供单一事件类型的答案。相比之下,GPT-4 通过把握复杂的上下文信息,能够在这些句子中识别出多个事件类型。
-
One-shot:ChatGPT 的性能显著提高,而 GPT-4 略微下降。同时,我们观察到在 one-shot 设置下,当 GPT-4 无法识别出正确答案时,它往往会产生更多错误的回答。我们推测这可能源于数据集中的隐含类型指示(implicit type indication)。

图3:事件抽取、链接预测和问答任务的示例
链接预测
链接预测任务涉及在两个不同的数据集 FB15k-237 和 ATOMIC2020 上的实验。前者是一个包含 25 个实例的随机样本集,而后者代表了所有可能关系的 23 个实例。在各种方法中,表现最好的微调模型分别是 C-LMKE(BERT-base)和 COMET(BART)。
-
Zero-shot:如表 1 所示,GPT-4 在 FB15k-237 上的 hits@1 分数接近 SOTA 水平。关于 ATOMIC2020,尽管 GPT-4 仍然超过了其他两个模型,但在 bleu1 分数方面,GPT-4 的表现与微调 SOTA 之间仍存在相当大的差距。在零样本上下文中,可以观察到 ChatGPT 在面对链接预测歧义时,往往会避免立即提供答案,而是选择寻求更多上下文数据。这种谨慎的方法与 GPT-4 倾向于直接回应形成对比,表明它们在推理和决策策略上可能存在差异。
-
One-shot:指令文本优化已被证明有助于提高 GPT 系列在链接预测任务中的性能。实证评估表明,one-shot GPT-4 在两个数据集上的结果都有所提高,能够在三元组中准确预测尾实体。在图 3 的示例中,目标 $[\texttt{MASK}]$ 是 Primetime Emmy Award。在零样本设置中,GPT-4 未能理解关系,导致错误响应 Comedy Series。然而,当加入示例时,GPT-4 成功识别出目标。
问答
我们使用两个流行的知识库问答数据集 FreebaseQA 和 MetaQA 进行评估,每个数据集随机抽取 20 个实例。在 MetaQA 中,我们根据其数据集表示进行抽样。对于这两个数据集,采用 AnswerExactMatch 作为评估指标。
-
Zero-shot:如表 1 所示,ChatGPT 和 GPT-4 在 FreebaseQA 上的表现相同,超过了之前的完全监督 SOTA 16%。且没有观察到 GPT-4 相对于 ChatGPT 有优势。然而,在 MetaQA 上,LLMs 与监督 SOTA 之间仍存在较大差距,可能是由于多答案问题和 LLM 输入 token 限制。尽管如此,GPT-4 比 ChatGPT 高出 11.1 分,这表明 GPT-4 在更具挑战性的 QA 任务上优于 ChatGPT。具体来说,在图 3 的示例中,GPT-4 正确回答了 MetaQA 中的一个多跳问题,得出了 1999 和 1974 两个发行日期,突显了其在多跳 QA 任务上相对于 ChatGPT 的优越性能。
-
One-shot:我们通过从训练集中随机抽取一个示例作为上下文示例进行了实验。表 1 中的结果表明,只有 text-davinci-003 从提示中受益,而 ChatGPT 和 GPT-4 的性能都出现了下降。这可以归因于臭名昭著的对齐成本(alignment tax),即模型为了与人类反馈对齐而牺牲了一些上下文学习能力。
2.2.3 知识图谱构建与推理的对比
实验表明,在 KG 构建和推理方面,LLMs 的推理能力比构建能力更强。由于量化和比较推理与构建能力存在挑战性,我们通过测量 LLMs 与当前最先进(SOTA)方法之间的性能差异来评估 LLMs 在这些任务中的相对能力。较大的性能差异表明表现较差。
尽管 LLMs 的表现非常出色,但在 zero-shot 和 one-shot 下,它们在知识图谱构建方面仍未超过当前的最先进模型,这表明了从稀疏数据中提取信息的局限性。相反,在 FreebaseQA 和 FB15K-237 数据集上,所有 LLMs 在 one-shot 下,以及 GPT-4 在 zero-shot 下,都达到了或接近 SOTA 的性能。此外,它们在其他数据集上也表现出相对良好的性能,这进一步突显了它们在知识图谱推理任务中的适应性。
知识图谱构建任务的内在复杂性可能是导致这种性能差异的原因。此外,LLMs 强大推理性能可能归因于它们在预训练过程中接触到相关知识。
2.2.4 通用领域与特定领域
在本研究中,我们评估了以 GPT-4 为代表的大型语言模型在不同知识领域的性能,确保在通用和专业背景下都进行了平衡评估。我们采用了与 2.2.3 中描述的性能差异评估类似的一致方法来评估相对任务能力。所选的基准测试 SciERC 和 Re-TACRED 分别代表科学领域和通用领域。尽管 Re-TACRED 比 SciERC 的七种关系类型展示了更广泛的关系类型范围,但 GPT-4 和 ChatGPT 在专业化的 SciERC 数据集上的表现都不如 Re-TACRED,这表明它们在特定领域数据方面的局限性。
有趣的是,当给一个示例时,GPT-4 在 SciERC 上的性能提升没有在 ReTACRED 上那么显著。具体来说,在我们的实验中,我们注意到 LLMs 在识别和理解 SciERC 数据集中的专业术语方面存在挑战。我们假设,在专业化数据集上表现不佳可能是由于这些模型主要在大量通用语料库上进行训练,因此缺乏足够的特定领域专业知识。
2.3 讨论:为什么 LLM 在某些任务上表现不尽如人意?
我们的实验强调了 GPT-4 在跨域知识提取方面的能力,尽管其性能并未超过微调模型。这一观察结果也与之前的研究相符。值得注意的是,在评估八个数据集上的大型模型时,我们发现结果可能受到多种因素的影响:
- 数据集质量:以知识图谱构建任务为例,数据集噪声可能导致歧义。复杂的上下文和潜在的不准确标签也可能对模型评估产生负面影响。
- 指令质量:模型性能显著受到指令语义深度的影响。通过提示工程找到最佳指令可以提高性能。通过提供相关样本的“上下文学习”方法还可以进一步改善结果。
- 评估方法:当前的方法可能并不完全适用于评估像 ChatGPT 和 GPT-4 这样的大型模型的能力。数据集标签可能无法捕捉所有正确的回答,涉及同义词的答案可能无法被准确识别。
2.4 讨论:LLMs 是记忆了知识还是真的具有泛化能力?
根据先前的研究洞察,大型模型擅长从少量信息中迅速提取结构化知识。这一观察引发了关于 LLMs 性能优势来源的问题:是由于在预训练阶段使用的庞大量文本数据使模型获得了相关知识,还是归因于它们强大的推理和泛化能力?
为了探索这个问题,我们设计了虚拟知识提取任务,针对 LLMs 泛化和提取不熟悉知识的能力。与传统的基准测试不同,该任务关注的是评估模型在面对它们以前未遇到的信息时的表现,而不是仅仅依赖于预训练期间积累的知识。现有的数据集大多包含 LLMs 熟悉的实体,可能来源于它们的预训练语料库,因此在提取任务中可能已经包含了这些语料库中已编码的关系。为了解决这些数据集的限制,我们引入了 VINE,这是一个专门为虚拟知识提取量身定制的新数据集。
在 VINE 中,我们制造了现实中不存在的实体和关系,将它们构建成知识三元组。然后我们指示模型提取这些合成知识,将这个过程的效率作为衡量 LLMs 管理虚拟知识能力的指标。我们基于 Re-TACRED 的测试集构建了 VINE,主要是用未见过的实体和关系替换原始数据集中的现有实体和关系,从而创建独特的虚拟知识场景。

图4:虚拟知识提取中使用的提示。蓝色框是示例,粉色框是相应的答案。
2.4.1 数据收集
考虑到像 GPT-4 这样的大型模型的训练数据集非常庞大,我们很难找到它们无法识别的知识。因此,我们以 2021 年 9 月之前的 GPT-4 数据为基础,从《纽约时报》在 2022 年和 2023 年组织的两个竞赛中选取了一部分参与者的回应作为我们的数据来源。为了增强数据源的多样性,我们还通过随机生成字母序列来创造新词。这是通过生成长度在 7 到 9 个字符之间的随机序列(包括 26 个字母和空格符号 “ “),并随机添加常见的名词后缀来完成构建的。
2.4.2 初步结果
在我们的实验中,我们随机选择了十个句子进行评估,确保它们涵盖了所有关系。在学习了两个相同关系的示例后,我们评估了 ChatGPT 和 GPT-4 在这些测试样本上的性能。值得注意的是,GPT-4 成功提取了 80% 的虚拟三元组,而 ChatGPT 的准确率仅为 27%。
在图 4 中,我们为大型模型提供了一个由虚拟关系类型和虚拟头尾实体组成的三元组——[Schoolnogo, decidiaster, Reptance] 和 [Intranguish, decidiaster, Nugculous],以及相应的示例。结果表明,GPT-4 有效地完成了虚拟三元组的提取。
因此,我们初步得出结论,GPT-4 表现出相对较强的泛化能力,并且可以通过指令快速获得提取新知识的能力,而不是仅仅依赖于相关知识的记忆。
3 Future Opportunities: Automatic Kg Construction And Reasoning
LLMs 在 KG 构建和推理方面的优势明显,它们不仅优化了资源利用,而且在适应性方面优于小型模型,特别是在不同的应用领域和数据有限的环境中。然而,尽管 LLMs 的能力令人印象深刻,但研究人员也发现了一些局限性,例如与人类偏好的不一致和幻觉。进一步改进模型的回答需要复杂的用户任务描述和丰富的交互环境,因此,人们对交互式自然语言处理(interactive natural language processing, iNLP)和智能代理(intelligent agents)的研究越来越感兴趣。
这种进展的一个显著例子是 AutoGPT,它可以独立生成 prompt 并执行事件分析、编程和数学运算等任务。同时,Li 等人深入探讨了代理之间自主合作的潜力,并引入了一种名为角色扮演的新型合作代理框架。
根据我们的研究结果,我们提议使用沟通智能代理(communicative intelligent agents)进行知识图谱构建,利用分配给多个代理的不同角色,基于彼此的共同知识协作完成知识图谱任务。考虑到在预训练阶段大型模型中存在的知识截断,我们建议引入外部资源来辅助任务完成。这些资源可以包括知识库、现有的知识图谱和互联网检索系统等。我们将其命名为 AutoKG。
我们在 CAMEL 中采用了角色扮演的方法。如图 5 所示,我们将知识图谱助手代理指定为”顾问”,将知识图谱用户代理指定为”知识图谱领域专家”。在接收到 prompt 和分配的角色后,任务指定代理(task-specifier agent)提供详细的描述以澄清概念。随后,知识图谱助手和知识图谱用户在多方环境中合作完成指定的任务,直到知识图谱用户确认任务完成。同时,引入了一个网络搜索角色,以帮助知识图谱助手在互联网上进行搜索。
 图5:AutoKG 的示意图,它通过使用 GPT-4 和基于 ChatGPT 的沟通代理,将知识图谱构建和推理相结合。图中省略了具体的操作过程,直接提供了结果。
图5:AutoKG 的示意图,它通过使用 GPT-4 和基于 ChatGPT 的沟通代理,将知识图谱构建和推理相结合。图中省略了具体的操作过程,直接提供了结果。
需要注意,尽管有 AutoKG 的协助,构建的知识图谱的结果仍需要手动评估和验证。此外,使用 AutoKG 仍然存在三个重要的挑战,需要进一步的研究和解决:
- API使用受最大 token 限制:目前使用的 gpt-3.5-turbo 受到最大 token 限制的约束,这影响了 KG 的构建。
- 人机交互效率:完全自主的机器操作缺乏即时错误纠正的人类监督,然而每一步都引入人类参与将大幅增加时间和劳动力成本。
- LLMs 的幻觉问题:鉴于 LLMs 产生非事实信息的倾向,必须审查它们的输出,可以通过与标准答案比较、专家审查或通过半自动算法来实现。