本文是《Building Knowledge Graph Using Pre-Trained Language Model For Learning Entity-Aware Relationships》的笔记。
摘要
本文提出了一种全面的方法,用于从文本文档中挖掘实体关系并构建知识图谱。本文集中讨论了两种分类方向性实体关系(directional entity relations)的方法。我们在预训练语言模型 BERT 的基础上进行扩展,用于文本分类,并提供实体和方向性信息作为输入,使其成为实体感知(entity-aware)的 BERT 分类器。我们还对所提出的模型进行了消融(ablation)研究,以评估在不同方式提供实体信息的情况下模型的学习能力。我们展示了在业务应用中构建实体关系提取系统的端到端流程。本文提出的技术还针对 SemEval-2010 任务 8 进行了评估,这是一个流行的关系分类数据集。实验结果表明,通过语言模型学习实体感知的关系优于几乎所有先前的最先进模型。
INTRODUCTION
有许多方法可以提取实体之间的关系(例如 feature based 和 kernel-based),这些方法依赖于使用词性标注(part-of-speech tagging,POS tagging)和依存句法分析(dependency parsing)的 NLP 技术栈。这些方法的主要问题是无法捕捉表达相似关系的多种方式。句子的句法和语义特征变化的挑战需要有效的解决方案,以提取实体以及定义关系的上下文。本文提出了一种基于语言模型的解决方案,可以在语境上捕捉实体之间的关系,而不仅仅是句法上的关系。
近年来,研究已经转向了深度网络,这些网络在给定任务的上下文学习中非常有效。针对序列建模或分类任务,提出了各种 RNN、LSTM 和 CNN 的架构。这些模型也被成功地应用于实体关系分类。最近,基于注意力机制的模型成为了大多数 NLP 任务的 SOTA 技术。在过去的几年中,语言模型在这个研究方向上占据了主导地位,其中预训练的语言模型(如 ELMO、GPT、BERT 等)以自监督的方式在大量文本上进行训练,学习文本句子的句法和语义。
本论文展示了两种基于 BERT 的架构,对实体之间的关系分类非常有效。主要贡献如下:
- 提出了两种技术:
- 训练一个完整的 (K*2+1) 分类器,其中 K 是关系类别的数量。我们保留了一个人工类别 ‘Others’,以捕捉那些存在实体但没有我们感兴趣的关系的句子。
- 训练两个分类器,一个用于实体之间方向性预测的二元分类器,另一个用于关系类别预测的 K 分类器,并进一步将结果进行组合。
- 通过消融研究,我们得出了向微调的语言模型(BERT)分类器提供实体信息的最佳格式。
- 在 SemEval 2010 Task 8 数据集上,我们取得了关系分类任务的 SOTA 结果,F1 分数分别为 88.4% 和 89.41%,超过了所有先前的结果。
RELATED WORK
关系提取和知识挖掘的研究范围广泛,从无监督到有监督技术都有尝试。最近,一些研究人员努力探索预训练的语言模型,如 BERT 用于关系提取。Yao 等人训练了一个知识图谱 KG-BERT,以实体和关系描述的三元组作为输入到 BERT。Soares 等人提出了一种方法,在没有任何知识图谱或人类注释者的监督下,通过匹配空白来训练关系表示。Wu 等人提出了将 BERT 的实体嵌入以及句子编码作为输入到多层神经网络进行分类。
尽管这些模型取得了良好的结果,但理想的简单而有效的解决方案是不需要手工制作的特征、依存句法分析或训练多个模型。在第 4 节中,通过实验我们展示了,仅仅通过使用实体感知的原始文本输入微调预训练的语言模型就可以实现这一点,同时在 F1 分数上也获得了相当大的改进。第 5 节写了错误分析和消融研究,以得出提供给模型的文本输入的最佳格式。在下一节中,将讨论两种架构以及整体系统管道设计和知识图谱生成。
PROPOSED METHODOLOGY
A. 系统设计
我们构建了一个流程,该流程从分类中提取预定义的实体及其关系,并填充可搜索、可视化且广泛的知识图谱。
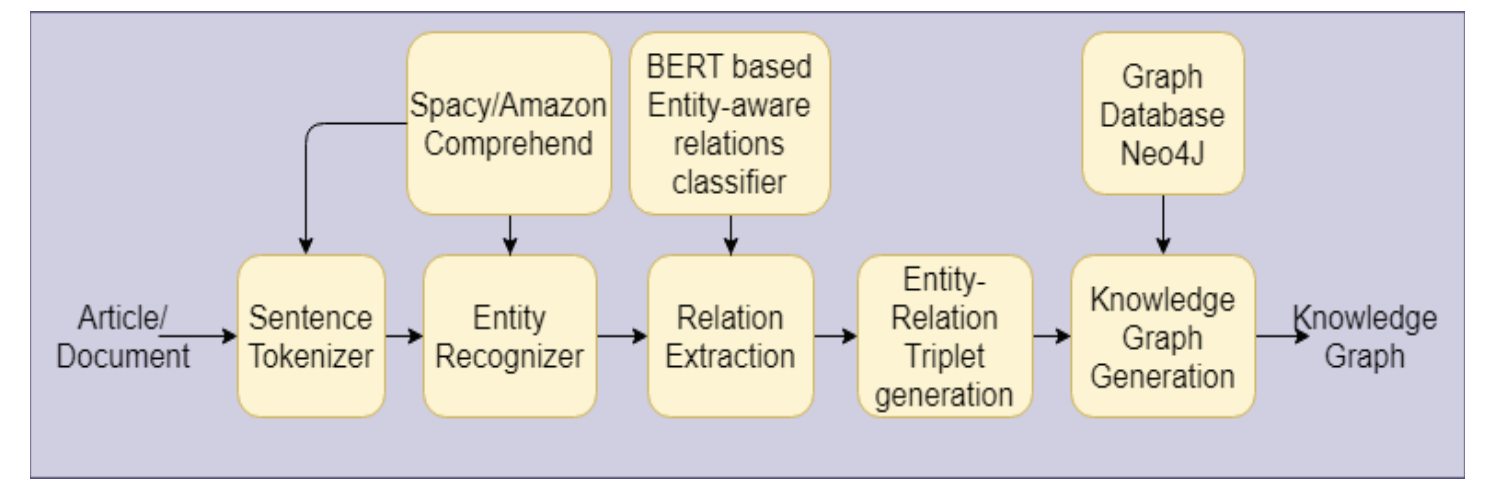
图 1 展示了所提出的关系提取系统的五步流程以及各个组件。给定一篇英文文章或文档,首先调用句子分词器(步骤 1),然后实体识别器(步骤 2)将划定句子中可能的实体,如地点、人或组织。在接下来的步骤(3 和 4)中,运行基于 BERT 的关系分类器,并生成二元实体-关系三元组。一旦系统标记了实体-关系三元组,它就会在图数据库中填充节点和链接,以表示知识图(步骤 5)。
B. 模型架构 - 实体感知的BERT
我们对 BERT 模型进行了微调,以便按照后续小节描述的特定方式提供输入。任何语言模型的构建都有两个训练阶段:通用预训练步骤,然后在自定义数据集上进行微调(通常是有限的数据集任务)。在学习特定领域的情况下,这些模型的预训练也可以作为额外的步骤进行扩展。
(1)输入表示
根据原始的 BERT 论文,一个特殊的分类标记 @[\texttt{CLS}]@ 是输入序列的第一个标记,结束标记是 @[\texttt{SEP}]@。为了明确提供位置信息,我们插入了特殊的符号标记 # 和 $ 来包围实体,从而使其成为一个感知实体的 BERT 分类器。给定一个带有标记实体 (h, t) 的句子:
\[s = \{w_1, ……, <e1>w_h</e1>, …. <e2>w_t</e2>, …w_n\}\]我们将其转换为
\[s = \{[\texttt{CLS}], w1, …, \#w_h\#, …$w_t$, …w_n, [\texttt{SEP}]\}\]例如,一个输入文本序列以以下方式传递给模型:
@[\texttt{CLS}]@ Louise is a director, audit chair and finance #committee# $member$ of a public health board and was a director of AFAANZ for 3 years@[\texttt{SEP}]@
上面的句子是 SemEval 数据集中的一个训练句子,属于 Member-Collection (e2, e1) 关系类别,方向性为 e2 到 e1。
(2)模型架构
我们使用了 Google 的 BERT TensorFlow 实现中的预训练模型 BERT base,并对其进行微调以用于实体-关系分类。图 2 所示的模型架构展示了如何提供输入序列以使其感知实体。
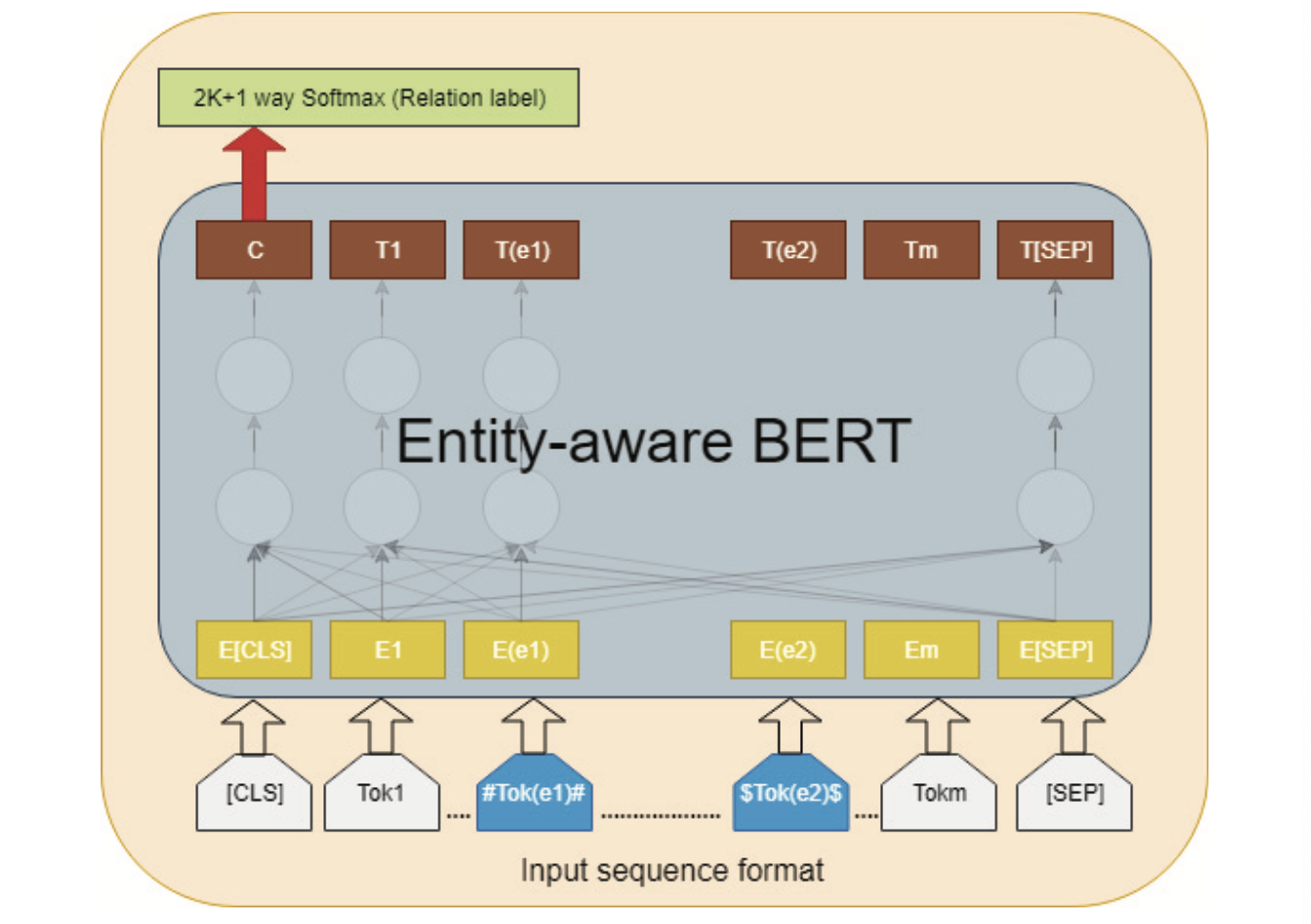
图 2:感知实体的微调 BERT 分类器
特殊分类标记 @[\texttt{CLS}]@ 对应的最终隐藏状态用于分类任务的聚合序列表示(aggregated sequence representation)。在微调过程中引入的分类参数为 @W \in R^{(K*2 +1) × 768}@,其中 @K@ 是关系类别的数量。我们计算一个典型的 softmax 损失来进行分类,即 @\log(softmax(CW^T))@。关系分类的评分函数为:
\[F(r) = softmax(CW^T)\]BERT 的超参数设置如下:
| 超参数 | 值 |
|---|---|
| 最大序列长度 | 64 |
| 训练轮数 | 5 |
| 训练批量大小 | 64 |
| 预热比例 | 0.1 |
| 学习率 | 5e-5 |
| 丢弃率 | 0.1 |
C. BERT based 2-Model Architecture
我们提出了另一种名为 “2-model BERT” 的方法来解决具有方向性的关系分类任务。我们在相同的训练数据上以类似于 section B 中的方式训练了两个基于 BERT 的分类器。第一个分类器学习关系类别,而第二个二分类器在实体带有标记的情况下学习关系的方向性。
2-model 架构如图 3 所示:
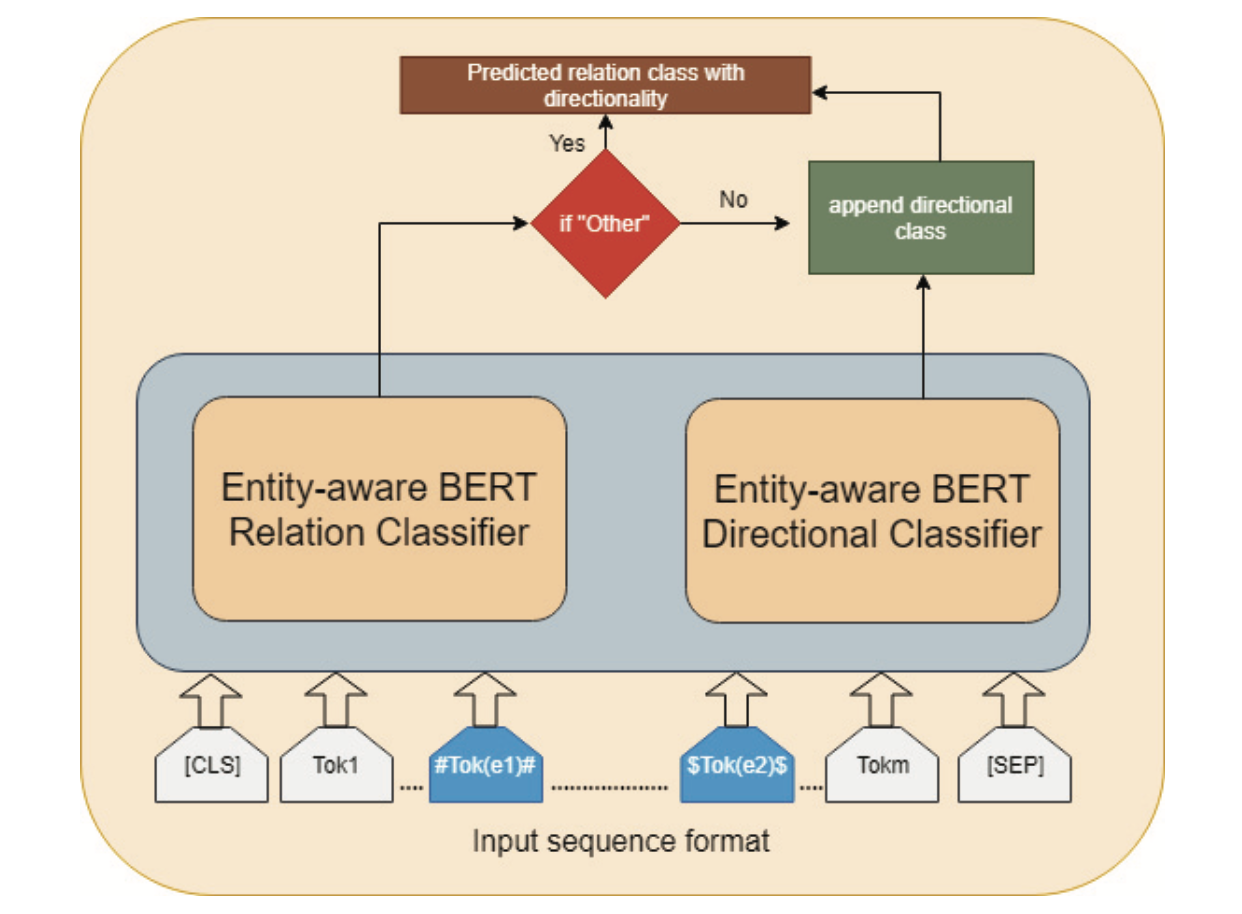
只有当关系分类器预测出某个非 Other 的关系类别时,才会考虑方向性。我们分别检查了两个模型的性能。关系分类模型在 SemEval 2010 数据集上达到了 86.6% 的 F1 分数,方向性分类器达到了 97% 的 F1 分数。此外,在结合关系和方向性分类模型时,我们取得了比大多数先前工作更好、与 SOTA 模型相当的结果。
V. Ablation Studies And Error Analysis A. Effect Of Entity Information
A. Effect of Entity Information
为了理解提供实体信息的重要性,我们以不带实体标记(entity marking,即前面提到的 $ 和 #)的方式运行了方法一的模型((K*2+1)分类器)。实验结果表明,实体标记在学习过程中有很大帮助,因为 BERT 在很大程度上依赖于多头自注意力层。
B. Effect of Entity Markers
进行这些实验的目的是为了理解选择实体标记是否也会影响 BERT 语言模型的学习。通过大量的实验,得出结论:像 $、# 这样的符号标记比字母标记表现得更好。可能的一个原因是,字母标记包围实体时会扭曲语言模型学习到的语言表示。此外,实体周围使用符号标记且不留空隙的表现比留空隙要好。
C. Effect of Training Epochs
在我们实验的数据集中,微调 BERT 的最佳训练轮数为 5。
D. Error Analysis: Where it failed ?
我们检查了模型产生的误分类示例,以了解失败的可能原因。大约 80% 的误分类是错误地将关系预测为人工类 “Other” 或相反。
-
第一种情况:一些被错误预测为 “Other” 类别的示例包含了在训练句子中未出现的单词或上下文短语(用粗体显示)。模型可能无法获取上下文,从而错误地预测了人工类。表 V 展示了一些此类误分类的示例。
-
第二种情况:模型可能通过注意力机制,关注实体之间的介词(prepositional)短语来学习关系类别。例如,”is part of” 短语在训练数据中通常表示 Component-Whole 或 Member-Collection 关系类别。但是,测试集中的一些 “Other” 类别的示例也包含了定义关系的此类短语,这使模型感到困惑(表 VI 展示了一些示例)。
表 V. 误分类示例(预测为 Other)
| #Fish# without the pyloric ceca have digestive enzyme production in the $liver$; and pancreas. | ComponentWhole(e2,e1) | Other |
| The #body# unleashes its extraterrestrial $passenger$, which proceeds to infect the student population at a breakneck pace. | EntityOrigin(e2,e1) | Other |
| These #observations# determine the high spatial resolution stellar $kinematics$ within the nuclei of these galaxies. | MessageTopic(e1,e2) | Other |
| The Postmodernism Generator was written by Andrew C. Bulhak using the Dada Engine, a system for generating random #text# from recursive $grammars$. | ProductProducer(e1,e2) | Ot |
表 VI. 误分类示例(实际为 Other)
| #Danger# is part of the Palestinian journalist’s daily $routine$ | Other | ComponentWhole(e2,e1) |
| The painting shows a historical view of the #damage# caused by the 1693 Catania earthquake and the $reconstruction$ activities. | Other | CauseEffect(e2,e1) |
| The #yeast# is an ingredient for making $beer$. | Other | EntityOrigin(e2,e1) |