本文是《Bertnet: Harvesting Knowledge Graphs With Arbitrary Relations From Pretrained Language Models》的笔记。
摘要
自动构建包含多样化新关系的知识图谱对于知识发现和广泛应用至关重要。以往基于众包(crowdsourcing)或文本挖掘的 KG 构建方法通常受限于预定义的一小部分关系,这是由于人工成本或文本语料库的限制。最近的研究提出使用预训练语言模型(LMs)作为隐式知识库,接受带有提示的知识查询。然而,这种隐式知识缺乏完整符号化 KG 的许多理想属性,如易于访问、导航、编辑和质量保证。在本文中,我们提出了一种新方法,从预训练 LMs 中收集大规模的任意关系的 KGs。通过最小关系定义的输入(a prompt and a few shot of example entity pairs),就能在庞大的实体对空间中高效搜索,提取所需关系的多样化且准确知识。我们开发了一种有效的搜索和重新评分(search-and-rescore)机制,以提高效率和准确性。我们将该方法部署到不同的 LMs 中,收获了超过 400 个新关系的 KGs。广泛的人工和自动评估表明,我们的方法能够提取多样化且准确的知识,包括复杂关系的元组(例如,“能够做 A 但不擅长 B”)。生成的知识图谱作为对源语言模型的符号化解释,还揭示了对语言模型知识能力的新见解。
1. 引言
符号化知识图谱(Symbolic knowledge graphs)是一种强大的工具,用于索引关于实体及其关系的丰富知识,对于信息访问、决策制定以及改进机器学习都非常有用。
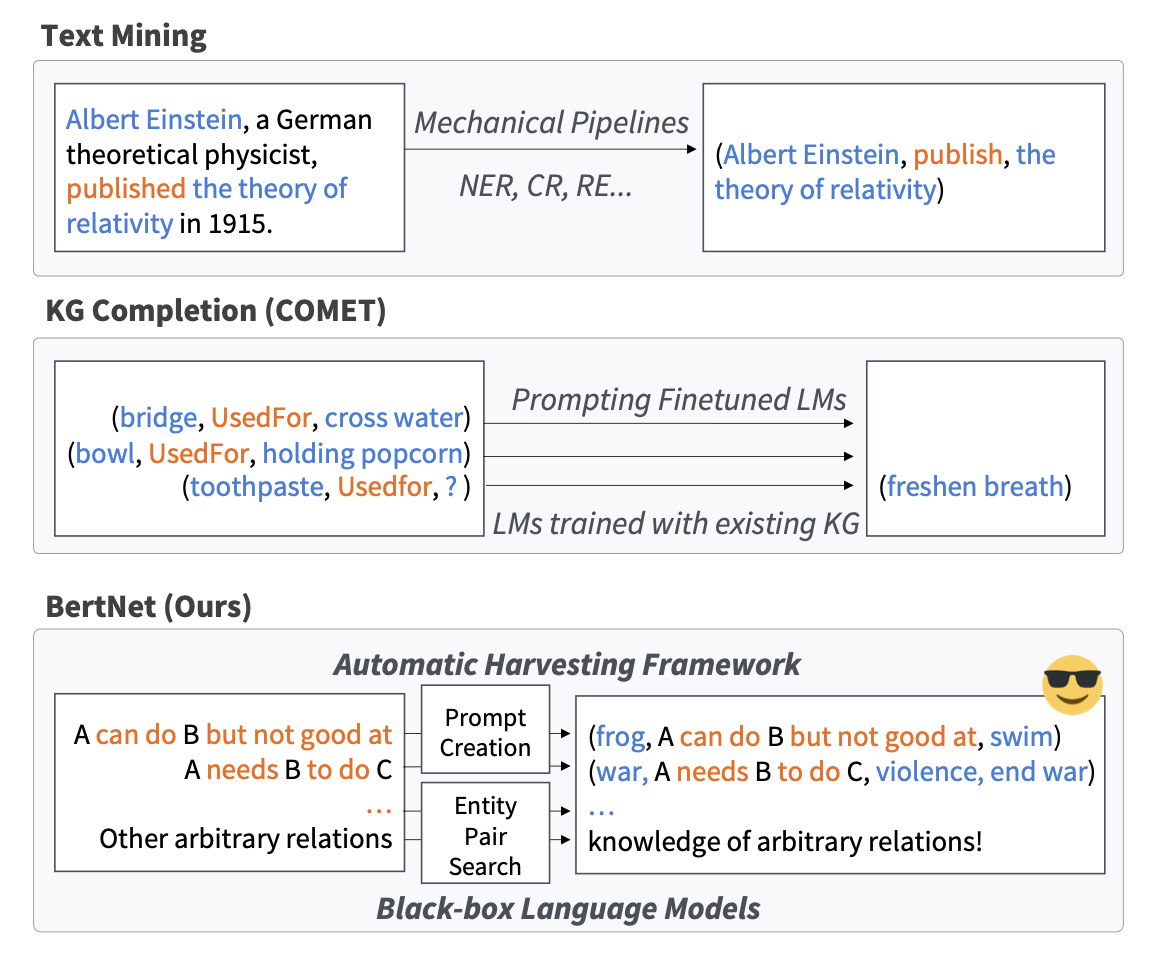
图 1:不同的知识获取示例范式。文本挖掘 提取文本中明确提到的关系知识。知识图谱补全 生成尾部实体以补全预先存在的关系知识。我们的方法能够从语言模型(LMs)中获取任意新关系的知识。
长期以来,构建包含多样化关系的知识图谱以全面表征实体之间的结构一直是人们的愿望。传统的基于众包的方法往往只覆盖有限的关系集,例如 ConceptNet 仅包含 34 种关系的小集合。基于文本挖掘的流行方法也有类似的限制,因为文本理解模型通常只能识别训练数据中包含的预定义关系集。存在一些开放模式的文本挖掘方法(例如,基于句法模式 syntactic pattern),然而提取的关系仅限于文本中明确陈述的那些,无法涵盖未提及或与语料库中的文本没有完全匹配的关系。同样,知识图谱补全(KGC)方法也仅限于预先存在的关系(见图1)。
另一方面,大型语言模型(LMs),如 BERT 和 GPT-3 已被发现在其参数中隐含了大量的知识。最近的研究尝试通过使用任意提示查询 LMs 来将 LMs 作为灵活的知识库(例如,”Obama was born in “ 对应的答案是 “Hawaii”)。然而,这种基于隐式查询的知识缺乏完整知识图谱(如 ConceptNet)的许多理想特性,包括易于访问、浏览甚至编辑,以及由于符号性质而具有的知识质量保证。符号知识蒸馏(Symbolic Knowledge Distillation,SKD)从 GPT-3 中显式提取知识库。然而,该方法完全依赖于 GPT-3 的强大上下文学习能力,因此不适用于其他语言模型如 BERT 和 ROBERTA。此外,其使用在现有知识图谱上训练的质量鉴别器可能会限制其对训练数据中未包含的新关系的泛化能力。
在本文中,我们提出了一种从任意预训练 LMs 中收集大量任意新关系的知识图谱的新方法。给定用户最小关系定义的输入,包括一个提示和一些示例实体对,我们的方法自动在 LMs 中搜索以提取关于所需关系的大量高质量知识。为了确保在庞大的实体对空间中的搜索效率,我们设计了一种有效的搜索和重新评分策略。我们还适应了之前的提示重述机制(prompt paraphrasing mechanism),并结合我们新的重新评分策略进行提示加权,从而实现一致和准确的结果知识。
我们将我们的方法应用于一系列不同容量的 LMs,如 ROBERTA、BERT 和 DISTILBERT。特别是,我们获取了超过 400 种新关系的知识(比 ConceptNet 关系的数量级多),这些关系在现有的知识图谱和以前的提取方法中都不可用。广泛的人工和自动评估表明,我们的方法成功提取了多样化的准确知识,包括复杂关系(如 “A 能够做,但不擅长 B”)和三元关系(如 “A 可以在 C 做 B”)的元组。有趣的是,由此产生的知识图谱也作为源 LMs 的符号解释,揭示了它们在模型大小、预训练策略和蒸馏等因素方面的知识能力的新见解。
2 相关工作
知识图谱构建
知识图谱构建通常需要大量的人力工作。最近,自动知识库构建(AKBC)作为一个研究重点,涌现了各种方法(在表1中总结)。基于文本挖掘的方法旨在从文本中提取知识。典型的信息抽取系统由几个子任务组成,如共指消解、命名实体识别和关系抽取。一些关于常识知识提取流程基于语言模式,并涉及复杂的工程,如语料库选择、术语聚合、过滤等。最近的尝试还利用 LMs 进行 AKBC。COMET 是一个生成式 LM,给定头实体和关系,训练预测尾实体。West 等人将 GPT-3 中的知识提炼为一个生成式 LM。Brown 等人通过用示例提示 GPT-3 生成了 $ATOMIC_{10x}$ 来教授学生模型。然而,这种方法需要 GPT-3 强大的少样本学习能力,并不适用于大多数 LMs。据我们所知,我们的框架是第一个仅从 LM 中提取知识构建 KG 的方法(以最小的关系定义作为输入)。这种新的范式也可以看作是将(预训练的)神经模型作为监督来优化符号化的知识图谱,这颠覆了使用符号知识来学习神经网络的传统问题。
| 方法 | 模块(s) | 结果 | 任意关系 |
|---|---|---|---|
| 文本挖掘 (Zhang et al., 2020a; Nguyen et al., 2021) | NER, CR, RE, etc. | KG | ✗ |
| LAMA (Petroni et al., 2019), LPAQA (Jiang et al., 2020) | LMs | 尾部实体 | ✓ |
| COMET (Bosselut et al., 2019) | Finetuned GPT-2 | 尾部实体 | ✗ |
| 符号知识蒸馏 (West et al., 2022) | GPT-3 | KG | ✓ |
| BertNet (ours) | LMs | KG | ✓ |
表 1:自动知识提取工作的分类。与其他类别的方法相比,我们的方法从任何 LMs 中提取完整的显式知识图谱的任意新关系。
LMs 作为知识库
另一条研究线路是将 LMs 用作知识库(例如 LAMA)。这些工作也被称为事实探测(factual probing),因为它们衡量了 LMs 中编码的知识量。通常,这是通过提示方法和利用掩码 LM 预训练任务来实现的。LPAQA 提出使用文本挖掘和释义(paraphrasing)来查找和选择提示,以优化对单个或少数正确尾实体的预测,而不是像我们的框架那样广泛预测所有有效的实体对。我们的框架与这些工作的不同之处在于,我们的目标是明确地收集知识图谱,而不是在简化的设置中衡量知识。
LMs 的一致性
一致性对于 LMs 来说是一个重要的挑战,强调在推理会话中不应产生冲突的预测。例如,模型在具有不同表面形式但含义相同的输入下应该表现出不变性。在我们的框架中,为每个关系提取的实体对被强制要求在多样的提示集下保持一致,并通过几个评分项进行规范化。
3 从预训练语言模型中提取知识图谱
本节介绍了从给定的预训练语言模型中提取关系知识图谱的框架,其中 LM 可以是任意填空模型,如 BERT、ROBERTA、BART 或 GPT-3(带有适当指令)。KG 由一组形式为 $⟨HEAD~ENTITY(h), RELATION(r), TAIL~ENTITY(t)⟩$ 的知识元组组成。我们的方法利用 LM 对于每一个给定的关系 $r$ 自动收集大量适当的实体对 $(h_1, t_1),(h_2, t_2),…,$。这比传统的 LM 探测任务更具挑战性,后者通常在给定一个头实体和关系下预测单个尾实体或少量有效尾实体。
我们用于提取特定关系的知识三元组的方法,例如图 2 所示的 “potential_risk”,只需要定义关系的最小输入信息。这包括一个初始提示如 “The potential risk of A is B” 和少量的示例实体对如 $⟨EATING~CANDY, TOOTH~DECAY⟩$。提示提供了关系的整体语义,而示例实体对澄清了可能的歧义。对于现有 KG 中未包含的新关系,要求像以前的知识探测或提示优化方法中那样大量的示例实体对(例如数百个)是不切实际的。相比之下,我们的方法只需要少量的示例实体对,例如在我们的实验中仅需 2 个,这些可以很容易地由用户收集或编写。
在以下部分中,我们将描述我们方法的核心组件,即自动创建具有置信权重(confidence weights)的多样化提示(§3.1)和高效搜索以发现一致的实体对(§3.2),这些实体对组成了所需的 KG。图 2 展示了整体框架。
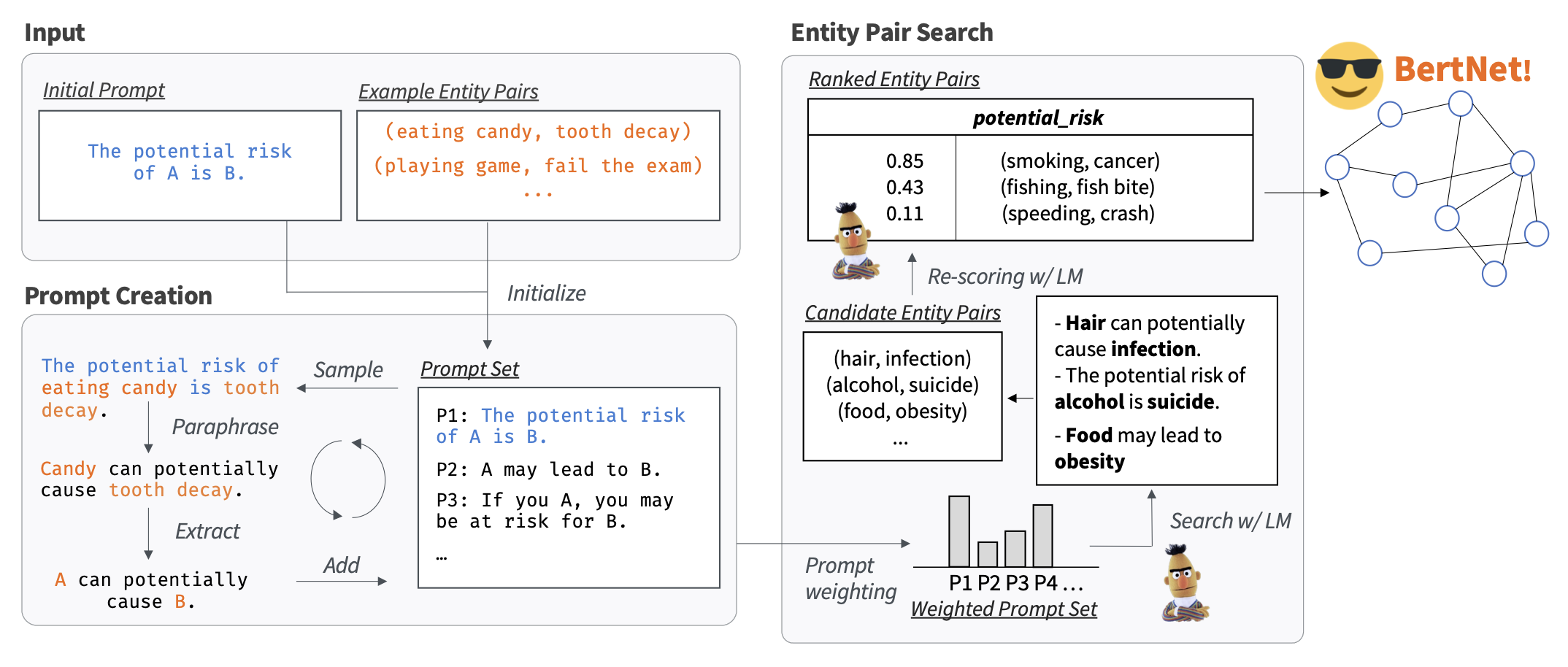
图2:知识收集框架的概述。给定关系的最小定义作为输入(初始提示和少量示例实体对),该方法首先自动创建一组以多种方式表达关系的提示(§3.1)。这些提示带有置信分数。然后,我们使用 LM 在大量的候选实体对中进行搜索,然后重新评分/排序,得到前几个实体对作为输出的知识(§3.2)。
3.1 创建多样化的加权提示
我们的自动化方法利用输入信息,特别是初始提示和几个示例实体对,生成一组语义一致但语言多样的提示,用于描述感兴趣的关系。生成的提示被赋予置信度权重,以准确衡量后续步骤(§3.2)中知识的一致性。
为了生成期望关系的多样化提示,我们首先从示例集中随机选择一个实体对,并将其插入初始提示中形成一个完整的句子。然后,这个句子通过一个现成的文本释义模型(text paraphrase model),生成多个具有相同含义的释义句子。通过移除实体名称,每个释义句子都会生成一个新的提示,描述所需的关系。为了确保关系的广泛表达,我们只保留那些在编辑距离(edit distance)上彼此不同的提示。通过不断对新创建的提示进行释义,直到收集到至少 10 个关系的提示。
自动提示生成可能不精确,导致提示无法准确传达预期的关系。为了缓解这个问题,我们提出了一种重新加权方法,该方法利用兼容性分数来校准每个提示在后续知识搜索步骤中的影响。具体来说,我们通过考虑单个实体以及整个实体对,在语言模型(LM)下评估新提示与示例实体对的兼容性。这使我们能够确定每个提示的适当权重,并提高知识搜索过程的精确度。形式上,实体对 $(h, t)$ 与提示 $p$ 之间的兼容性分数可以写为:
\[f_{LM}(⟨h, t⟩, p) = \alpha \log P_{LM}(h, t | p) + \\ (1 − \alpha) min \\\{\log P_{LM}(h | p), \log P_{LM}(t |p, h)\\\} \ (1)\]第一项是在语言模型分布 $P_{LM}$ 下的联合对数似然,第二项是给定提示(和其他实体)的最小个体对数似然,$\alpha$ 是一个平衡因子(在我们的实验中,$\alpha = 2/3$)。我们计算每个创建的提示在所有示例实体对上的平均兼容性得分,然后提示的权重被定义为所有提示的 softmax 归一化得分。
3.2 高效搜索一致性知识
在根据第 3.1 节中描述的步骤获得的提示集合和相应的置信权重之后,我们继续搜索与所有提示一致的实体对。为了指导搜索过程并评估搜索到的实体对 $(h^{new}, t^{new})$ 的兼容性,我们重复使用先前定义的提示/实体对兼容性函数(公式1),并直观地将一致性定义为其与各种提示的兼容性的加权平均,即
\[consistency((h^{new}, t^{new})) = \sum_p w_p·f_{LM}((h^{new}, t^{new}), p) \ \ (2)\]其中 $w_p$ 是提示权重,求和是在上述所有自动创建的提示上进行的,因此与所有提示兼容的实体对被认为是一致的。
基于一致性准则,我们开发了一种高效的搜索策略来寻找一致的实体对。一种直接的方法是枚举所有可能的实体对,计算它们各自的一致性得分,并选择具有最高得分的前 K 个实体对作为结果知识。然而,由于词汇表的大小 $V$ 很大(例如,ROBERTA 的 $V = 50,265$),以及枚举过程的高时间复杂度(即使每个实体只包含一个标记,时间复杂度仍为 $O(V^2)$),这种方法可能计算成本很高。
为了克服这个限制,我们提出了一种适当的近似方法,以实现更高效的搜索和重新评分方法。具体而言,我们首先使用在不同提示之间加权平均(类似于公式 2)的最小个体对数似然(minimum individual log-likelihoods,即兼容性得分公式 1 中的第二项)来找出一大批候选实体对。使用最小个体对数似然使我们能够应用修剪策略,例如维护一个堆并在每个单独的搜索步骤中消除排名在前 K 之外的实体。一旦我们收集到大量的候选提案,我们使用公式 2 中的完整一致性得分对它们进行重新排序,并选择前 K 个实例作为输出知识。算法伪代码如下:

我们使用最小标记对数似然(minimum token log-likelihoods,MTL)而不是完整的方程 2,这使我们能够应用剪枝策略。举例来说,当我们搜索 100 个实体元组时,我们维护一个最小堆来跟踪实体元组的 MTL。该堆的最大大小为 100,堆顶可以用作未来搜索的阈值,因为它是第 100 个最大的 MTL:当我们搜索新的实体元组时,一旦发现任何时间步的对数似然低于阈值,我们可以立即剪枝连续搜索,因为这意味着该元组的 MTL 永远不会超过堆中的任何现有元组。如果找到一个新的实体元组而没有被剪枝,我们将弹出堆并推入新元组的 MTL。直观地说,剪枝过程确保了搜索中生成的元组部分对于给定的提示是合理的。
对于复杂关系的泛化
大多数现有的知识图谱或知识库包含将两个实体连接起来的谓词关系,例如,“A 能够做 B”。然而,许多现实生活中的关系更加复杂。我们的方法具有灵活性,并且可以轻松扩展以提取关于这些复杂关系的知识。我们在实验中通过探索两种情况来证明这一点:
-
高度定制的关系:具有特定而复杂的含义,例如“A 能够做 B,但不擅长”。这种复杂的知识通常很难以大规模的方式由人类编写。我们的自动方法在只给出初始提示和一些容易收集的示例实体(例如⟨DOG,SWIM⟩,⟨CHICKEN,FLY⟩等)的情况下,自然地支持获取这种知识;
-
涉及多于两个实体的 N 元关系:例如“A 可以在 C 处做 B”。我们的方法可以直接扩展以处理 N 元关系,通过相应地推广兼容性得分和搜索策略来适应多于两个实体。
4 实验
为了评估我们的框架,我们从各种语言模型中提取了多种新关系的知识,并进行了人类评估。然后,我们对框架中的提示创建和评分函数进行了更深入的分析。最后,通过将我们的框架作为解释语言模型中存储的知识的工具,我们对黑盒模型的知识容量做出了一些值得关注的观察。
4.3 分析自动提示创建
为了评估自动创建提示的效果,我们在以下几种设置下比较了生成的知识图谱:
- MultiPrompts:使用第 3 节描述的全框架,在知识搜索中使用自动创建的多样化提示。
- Top-1 Prompt:为了消除多个提示集成的效果,我们评估了仅使用权重最大的提示(第3.1节)进行知识提取的变体。
- Human Prompt:为了进一步理解自动创建提示的有效性,我们评估了使用每个关系的初始提示的变体。
- AutoPrompt(Shin et al., 2020):通过优化训练集中尾实体预测的可能性来学习提示。为了适应我们的设置,我们将其调整为优化示例实体对上的兼容性得分(公式 1)。
| 方法 | 准确率 | 拒绝率 |
|---|---|---|
| AUTOPROMPT | 0.33 | 0.47 |
| HUMAN PROMPT | 0.60 | 0.27 |
| TOP-1 PROMPT(Ours) | 0.69 | 0.23 |
| MULTI PROMPTS(Ours) | 0.73 | 0.20 |
我们对每个关系收集了1000个元组,并进行了人工注释。注释结果显示在上面表格中。我们的 TOP-1 PROMPT 显著提高了准确率,比 HUMAN PROMPT 高出 9%,证明了我们的提示搜索算法在生成高质量提示方面的有效性。MULTI-PROMPTS 进一步提高了准确率,额外提高了 4%,表明多样化提示的组合更好地捕捉了关系的语义。然而,使用 AUTOPROMPT 优化的提示的方法导致的准确率低于使用人类或搜索提示的方法。这可以归因于用于学习期望关系的有效提示的示例知识元组数量不足。
根据上述结果,我们进一步研究了创建的提示如何影响框架中的后续评分模块。具体而言,我们研究了由提示参数化的评分函数(scoring function parameterized by the prompts)的精确度和召回率,以查看自动创建的提示(§3.1)是否带来了一致性评分(§3.2)在知识准确性(精确度)和覆盖范围(召回率)方面的更好平衡。为了与其他仅限于特定关系集的评分方法进行比较,这个实验使用了来自ConceptNet和LAMA数据集的现有术语进行了实施。
我们使用来自 ConceptNet 和 LAMA 的知识元组作为正样本,并使用 Li 等人(2016年)中的相同策略合成相同数量的负样本,通过随机替换真实知识元组中的实体或关系。每个评分函数根据得分从高到低对样本进行排名。然后,我们可以计算在不同截断点处的正样本的精确度和召回率,并为每种方法绘制精确度-召回率曲线。
结果表明使用多个提示进行评分始终能够达到最佳性能,其次是 Top-1 提示,然后是人工编写的提示。这一发现与之前的实验结果一致,验证了我们评分函数设计的有效性。我们的框架也优于其他 baseline,例如 ConceptNet 上的 COMET 和 LAMA 上的 LPAQA。尽管这些方法使用标注数据进行训练,但它们仅优化了在给定查询的情况下完成尾实体的任务,而不是对实体对进行评分,这对从 LMs 中提取 KGs 至关重要。
4.4 不同语言模型的知识分析
生成的知识图谱可以被视为语言模型的符号化解释。我们从 5 种不同的语言模型中提取知识图谱,并提交给人类注释评估。结果表格如下:
| 源语言模型 | 准确率 | 拒绝率 |
|---|---|---|
| DISTILBERT | 0.67 | 0.24 |
| BERT-BASE | 0.63 | 0.26 |
| BERT-LARGE | 0.70 | 0.22 |
| ROBERTA-BASE | 0.70 | 0.22 |
| ROBERTA-LARGE | 0.73 | 0.20 |
更大的语言模型是否编码了更好的知识?
BERT 和 RoBERTa 的大版本与基础版本有相同的预训练语料库和任务,但在模型架构方面更大,层数(24 v.s. 12)、注意力头数(16 v.s. 12)和参数数量(340M v.s. 110M)都有所增加。BertNet-large 和 RoBERTaNet-large 的准确率分别比它们的基础版本高出约 7% 和 3%,表明更大的模型确实编码了比基础模型更好的知识。
更好的预训练是否带来更好的知识?
RoBERTa 使用与 BERT 相同的架构,但采用更好的预训练策略,如动态掩码、更大的批量大小等。在我们框架中生成的对应知识图谱中,RoBERTaNet-large 的表现优于 BertNet-large(0.73 v.s. 0.70),RoBERTaNet-base 也优 于BertNet-base(0.70 v.s. 0.63),表明 RoBERTa 中更好的预训练促进了更好的知识学习和存储。
知识蒸馏过程中知识真的被保留了吗?
DistilBERT 是通过蒸馏 BERT-base 训练的,它减少了后者 40% 的参数。有趣的是,知识蒸馏过程反而提高了结果知识图中约 4% 的准确率。这应该归因于知识蒸馏过程可能消除了教师模型中的一些噪声信息。