本文是《Autokg: Efficient Automated Knowledge Graph Generation For Language Models》的笔记。
摘要
通过语义相似性搜索将大型语言模型(LLM)与知识库链接的方法往往无法捕捉到复杂的关系动态。为了解决这些限制,我们引入了 AutoKG,一种轻量级高效的自动知识图谱(KG)构建方法。对于一个由文本块组成的知识库,AutoKG 首先使用 LLM 提取关键词,然后使用图拉普拉斯学习(graph Laplace learning)评估每对关键词之间的关系权重。我们采用了一种混合搜索方案,结合向量相似性和基于图的关联,以丰富 LLM 的响应。初步实验表明,与语义相似性搜索相比,AutoKG 提供了更全面和相互连接的知识检索机制,从而增强了 LLM 在生成更有深度和相关性的输出方面的能力。
I. 引言
大型语言模型在大量多样化的语料库上经过严格的预训练,因此在各种自然语言处理(NLP)任务中表现出色,从语言理解到条件和无条件文本生成。然而,它们的部署面临重大挑战。一方面,LLMs 倾向于产生“幻觉”,提供了似是而非的预测。另一方面,LLMs 的黑盒特性损害了可解释性和事实准确性,经常导致错误的陈述,尽管在训练过程中记忆了事实。
自然语言中的知识可以从可检索的数据库中外部获取,从而减少幻觉并增强 LLMs 的可解释性。系统可以使用神经网络生成的密集查询和文档向量来评估与信息查询的语义相似性,通过计算相关概念之间的嵌入向量相似性。
除了语义相似性信息检索,还有两种先进的方法特别具有变革性:像“思维链”提示这样的提示工程,以及知识图谱(KGs)的整合。“思维链”提示通过生成解释和预测路径,并通过知识检索进行交叉验证,为高级推理提供了一个框架。知识图谱为 LLMs 提供了一种结构化和高效的方式来解决其在事实准确性和推理方面的局限性。知识图谱不仅提供了各种应用所需的准确和明确的知识,而且以其符号推理能力而闻名,可以产生可解释的结果。这些图是动态的,随着新知识的增加而不断演化,并且可以根据特定领域的要求进行专门化。
在这项研究中,我们重点关注自动化知识图谱(KG)生成技术以及与 LLMs 的整合。与这两个任务相关的大部分工作都严重依赖神经网络的持续训练,这既难以应用,也不够灵活以进行即时更新。LLMs 的最新进展使我们对自动生成 KG 和将 LLMs 与 KG 整合的问题有了更简单的思考。像 ChatGPT1、BARD2 和 LLAMA 这样的最先进的 LLMs 展示了令人印象深刻的推理能力。在提供足够的信息的情况下,它们可以独立执行有效的推理。这一观察结果表明,我们有机会简化 KG 的结构:也许传统 KG 中复杂的关系模式可以简化为基本的关联强度指示器。因此,特定的关系通过与 KG 相关的语料库块隐含地传达给模型。此外,我们可以直接在提示中提供检索到的关键词和相关的语料库,而无需训练网络让 LLMs 理解检索到的子图结构。
受到这些想法的启发,本研究做出了以下贡献:
- 我们引入了 AutoKG,一种基于文本块构建的知识库的创新自动化知识图谱生成方法。AutoKG 避免了训练或微调神经网络的需求,利用预训练的 LLMs 提取关键词作为节点,并应用图拉普拉斯学习来评估这些关键词之间的边权重。输出是一个简化的知识图谱,其中边缺乏属性和方向性,只具有表示节点之间相关性的权重。
- 我们提出了一种混合搜索策略,与提示工程相结合,使大型 LLMs 能够有效利用生成的知识图谱中的信息。该方法同时基于嵌入向量和知识图谱中最相关的相邻信息,搜索语义相关的语料库。
与传统的知识图谱相比,这里构建的知识图谱是简化版本,传统的知识图谱通常由三元组形式的关系组成。首先,AutoKG 中的节点不是通常意义上的实体,它们更像是抽象的关键词。这些关键词可以代表实体、概念或任何作为搜索基础的内容。此外,AutoKG 使用无向边而不是传统知识图谱中具有特定语义含义的有向边,这些无向边只有一个权重值。节点关键词是通过 LLMs 从知识库中提取的,而图结构是通过算法推导得出的。这样的知识图谱可以仅用关键词列表和稀疏邻接矩阵高效地存储。
II. 自动知识图谱生成
在本节中,我们介绍了我们提出的方法 AutoKG,用于自动知识图谱(KG)生成。我们假设 LLM 已经预训练,并且有一个相应的向量嵌入模型。具体来说,我们采用了 OpenAI 的 gpt-4 或 gpt-3.5-turbo-16k 作为 LLM,以及 text-embedding-ada-002 作为嵌入模型。
考虑一个涉及外部知识库的场景,该知识库由离散的文本块组成。AutoKG 构建了一个 KG,其中节点代表从外部知识库中提取的关键词。这些节点之间的边带有一个单一的非负整数权重,表示连接的关键词之间的关联强度。AutoKG 包含两个主要步骤:提取关键词(对应于图中的节点)和建立这些关键词之间的关系(由图中的边表示)。值得注意的是,预训练的 LLM 仅在整个过程的关键词提取步骤中使用。图 1 是 KG 构建的流程图。
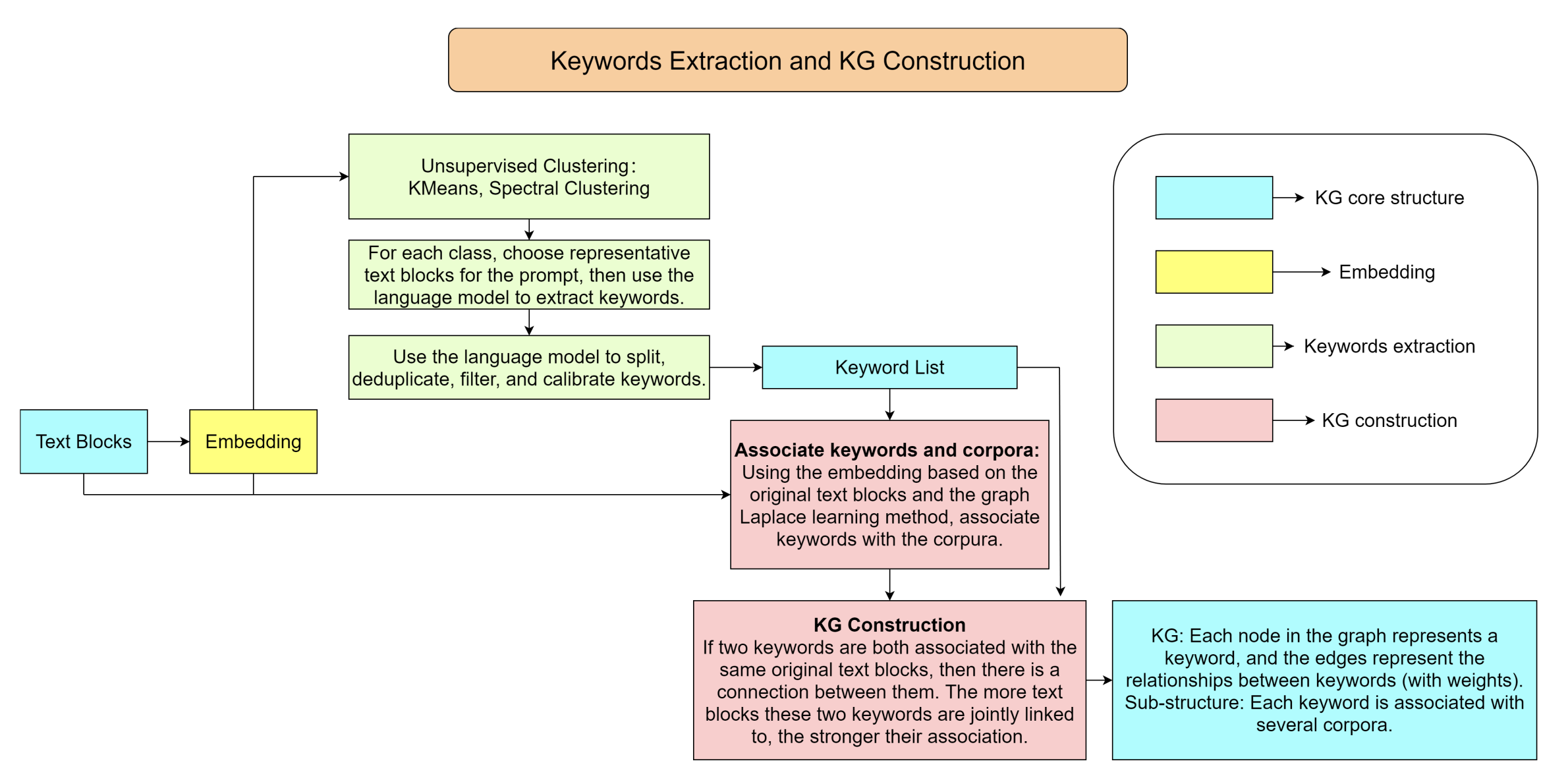
图1:知识图谱构建过程的流程图。该图展示了构建知识图谱所涉及的不同步骤。蓝色方块代表知识图谱的核心组件,黄色方块表示嵌入过程,绿色方块关注关键词提取,红色方块对应关键词与语料库之间以及关键词之间的关系建立。
A. 关键词提取
外部知识库表示为 $X = \{x_1, x_2, …, x_N\}$,其中每个 $x_i$ 是最大长度为 $T$ 个 token 的文本块,表示为字符串。这些文本块对应的嵌入向量封装在 $V = \{v(x_1), v(x_2), …, v(x_N)\} ⊂ R^d$ 中,其中 $v$ 是从字符串到 $R^d$ 的嵌入投影。我们使用无监督聚类算法和 LLMs 的帮助从知识库 $X$ 中提取关键词。

算法 1 概述了关键词提取过程。该算法以所有文本块及其对应的嵌入向量 $X$ 和 $V$ 为输入,以及预定义参数:$n$ 为聚类数,$c$ 为要选择的文本块数,$l_1$、$l_2$ 为关键词提取参数。此外,算法还利用参数 $m$ 来指定采样的先前关键词数量。两种无监督聚类算法,K-means 聚类和谱(spectral)聚类,被应用于对知识库进行聚类。对于每个识别出的聚类,我们采样 $2c$ 个文本块,其中 $c$ 个最接近聚类中心,$c$ 个随机选择,以捕捉全局和中心信息。该算法中 LLM 被使用了两次。首先由参数 $l_1$ 和 $l_2$ 的指导从 $2c$ 个文本块的选择中提取关键词,同时避免采样的 $m$ 个先前关键词。其次,相同的 LLM 被用来过滤和精炼提取的关键词。
这些应用的提示构建严格遵循表 I 中概述的格式。关键词提取的一个具体提示示例在附录中给出。具体来说,每个提示是通过连接任务信息、输入信息、附加要求和输出来形成的。需要注意的是,在每个任务中,与任务信息和附加要求相对应的提示部分的长度是固定的。
| ID | 任务信息 | 输入信息 | 额外要求 | 输出 |
|---|---|---|---|---|
| 1 | 关键词提取 | 1.采样的文本块 2.采样的先前关键词 |
1.避免使用先前的关键词 2.输出最多 $l_1$ 个关键词 3.每个输出关键词最多 $l_2$ 个token |
提取到的关键词 |
| 2 | 精炼关键词 | 最初提取的关键词 | 浓缩、去重、拆分和删除 | 精炼的关键词 |
| 3 | 对查询的响应 | 1.原始查询 2.相关文本块 3.相关关键词 |
指示用于搜索文本和关键词的方法:直接,通过关键词,或通过KG邻接搜索 | 最终响应 |
表1:不同任务的 Prompt 构建
对于处理关键词提取的任务 1,最大输入长度设置为 $2cT + m(l_2 + 1)$,其中 $T$ 代表单个文本块的 token 长度。注意,当考虑到逗号等潜在分隔符时,每个关键词的长度最多可以为 $l_2 + 1$ 个 token。同样,最大输出长度为 $l_1(l_2 + 1)$,其中 $l_1$ 是关键词的最大数量,$l_2$ 是每个关键词的最大 token 长度。由于任务 1 对两种聚类方法生成的 $n$ 个聚类各应用一次,因此任务 1 的总最大 token 使用量为 $2n(2cT +(m+l_1)(l_2+1))$。这个过程最多产生 $2nl_1$ 个提取的关键词。对于涉及过滤和精炼关键词的任务 2,输入和输出的最大长度都受公式 $2nl_1(l_2 + 1)$ 的约束。
总结来说,关键词提取过程的 token 最大使用量 $M_{tokens KG}$ 为
\[M_{\rm tokens\ KG}=2n(2cT+(m+2l_{1})(l_{2}+1))+L_{F} \ \ (1)\]其中 $L_F$ 是任务信息和附加要求部分的固定总 token 长度。
B. 图结构构建
在本节中,我们将详细介绍如何基于第二节 A 部分提取的关键词构建知识图谱(KG)。具体来说,我们确定关键词之间是否存在边以及如何为这些边赋权。我们提出了一种基于图上标签传播(label propagation on the graph)的方法,这一步不需要任何大型语言模型的参与。
首先,我们创建一个图 $G^t = (X , W^t)$,其中 $X$ 是作为图 $G^t$ 节点的文本块集合,$W^t$ 是边的权重矩阵。$W^t_{ij}$ 由相应的嵌入向量 $\bf v_i$ 和 $\bf v_j$ 之间的相似性决定。定义相似性函数:
\[w(\mathbf{v}_{i},\mathbf{v}_{j})=\exp\left(-{\frac{\angle(\mathbf{v}_{i},\mathbf{v}_{j})^{2}}{\sqrt{\tau_{i}\tau_{j}}}}\right),\]其中 $∠(v_i, v_j ) = arccos(\frac{v_i^\top v_j}{||v_i||~||v_j||})$ 是特征向量 $v_i$ 和 $v_j$ 之间的角度。归一化常数 $τ_i$ 基于与 $K$ 个最近邻的相似性得出(即 $τ_i = ∠(v_i, v_{iK})$),其中 $v_{iK}$ 是 $v_i$ 的第 $K$ 个最近邻)。
为了计算效率,我们通过考虑每个顶点的 $K$ 个最近邻(KNN)来构建一个稀疏权重矩阵 $W_t$。设 $x_{i_k},k = 1, 2, . . . , K$ 是根据角度相似性 $x_i$ 的 $K$ 个最近邻(包括 $x_i$ 本身)。通过以下方式定义稀疏权重矩阵:
\[\bar{W}^{t}_{ij}=\left\{\begin{array}{rl}w({\bf v}_{i},{\bf v}_{j}),&j=i_{1},i_{2},\ldots,i_{K},\\ 0,&\mbox{otherwise}.\end{array}\right.\]$K$ 的选择是为了确保相应的图 $G^t$ 是连通的,经验上 $K = 30$。我们通过对称化稀疏权重矩阵来获得最终的权重矩阵 $W^t$,通过重新定义 $W^t_{ij} := (\bar{W}^t_{ij} + \bar{W}^t_{ji})/2$。注意 $W^t$ 是稀疏的、对称的和非负的(即 $W^t_{ij} ≥ 0$)。
接下来,我们利用构建在文本块上的图 $G^t = (X , W^t)$ 来建立关键词知识图谱 $G^k = (K, W^k)$。这里,$K$ 是关键词集合,$W^k$ 是边的权重矩阵。在这个矩阵中,$W^k_{ij}$ 量化了关键词 $k_i$ 和 $k_j$ 之间的关联强度。重要的是,这种关联不是语义上的,而是反映在整个知识库的语料库中。具体来说,$W^k_{ij}$ 对应于同时与两个关键词 $\bf k_i$ 和 $\bf k_j$ 相关联的文本块的数量。
算法 2 建立了关键词和文本块之间的关系。核心思想是选择一组最接近关键词的文本块作为正数据,另一组最远的作为负数据。然后我们利用基于我们之前为文本块构建的图结构 $G^t = (X , W^t)$ 的图拉普拉斯学习。图拉普拉斯学习是一种基于图的半监督学习方法,利用解函数 $u : X → [0, 1]$ 的调和性质(harmonic property)将标签值从一部分标记节点扩散到其他未标记节点。被分类为正侧(节点函数值 $u ≥ 0.5$)的文本块被认为与关键词相关联。

关键词 $\bf k_i$ 和 $\bf k_j$ 之间的关联权重 $W^k_{ij}$ 定义如下:
\[W^k_{ij} = W^k_{ji} = |X^{k_i} ∩ X^{k_j}|\]通过此,我们完成了基于关键词的KG $G^k$ 的构建,它是建立在文本块图 $G^t$ 之上的。
D. Remarks
在生成整个知识图谱的过程中,有几个要点需要考虑:
- 尽管关键词是从文本块的聚类中提取出来的,但在建立关键词与文本块之间的关系时,我们并没有考虑之前的聚类结果。这是因为同一个关键词可能包含在多个聚类中。
- 在构建关键词之间的关系时,我们没有将关键词的嵌入向量纳入图拉普拉斯学习过程中。做出这个决定的原因有两个:首先,在选择不同的关键词时,我们不需要更新图结构;其次,从经验上讲,关键词的嵌入向量往往与文本块的嵌入向量相距甚远。因此,将它们纳入拉普拉斯学习的初始标签数据可能是没有意义的。
我们的方法在关键词提取和关系构建方面都大大优于传统方法。传统技术的主要缺点是它们依赖于固定的词集,导致大量相关信息的丢失,并且常常产生过于局限的见解。在关键词提取方面,我们的方法利用了大型语言模型的能力,允许对与主题更为核心的关键词进行精炼,而不仅仅是高频术语。在关系构建方面,我们的策略是基于所有文本块图的宏观算法。这种方法包含了来自整个文本块知识库的信息,与从局部距离派生的关系相比,提供了更全面的视角。
III. 混合搜索:结合知识图谱和语言模型
在本节中,我们提出了一种基于第二节生成的知识图谱的混合搜索方法。对于给定的查询,使用这种混合搜索策略的搜索结果不仅包括与查询语义相关的文本块,还包括从 KG 中获取的额外关联信息。这些补充数据为模型提供更详细和深入的推理,以便进一步分析。结合 KG 可以捕捉不同实体之间的复杂关系,从而丰富查询的上下文理解。
在我们提出的混合搜索方法中,我们设计了一个多阶段的搜索过程,结合了直接的文本块搜索以及由 KG 指导的关键词搜索。这个过程在算法 3 中有详细说明。首先,我们通过计算与给定查询嵌入向量最接近的文本块来进行初步搜索。然后,我们转向 KG,识别与查询最接近的关键词,并找到与这些关键词相关的文本块。最后基于 KG 中的权重矩阵,识别出上一步的关键词有最强关联的额外关键词,并相应地搜索相关的文本块。该算法不仅返回一组与查询高度相关的文本块,还返回一组与查询紧密相关的关键词。随后,检索到的信息被整合到提示中,以增强 LLM 对原始查询的响应。有关提示构建的详细信息,可以参考表 I 中的任务 3。附录中提供了一个具体的提示示例。重要的是,在提示构建过程中可以采用自适应方法,以确保不超过 LLM 的最大标记限制。

Iv. Experiments And Results
我们采用定性方法而不是数值指标来评估我们方法的实验性能。首先,我们提供一个简单的例子来解释为什么我们的 AutoKG + 混合搜索方法比基于语义向量相似性搜索的方法有优势。接下来,我们基于本文的所有 40 个参考文献和查询过程中使用的 KG 的相关子图,提供一个详细的例子。最后,我们从理论和实践两个角度比较混合搜索和语义向量相似性搜索的效率。
A. 一个简单的例子:为什么我们需要知识图谱?
考虑一个包含详细描述名为 Alex 的个体一天生活的文本块及相关信息的简单知识库。核心叙述是 Alex 早上离开家后,去 Cafe A 买了杯咖啡,然后乘公交车去 Company B 上班。知识库中穿插着许多细粒度的信息,比如 Alex 在咖啡馆与咖啡师的对话、点咖啡的细节、在公交车上的对话,以及在工作场所的对话等。这里的兴趣点在于模型如何回答这个问题:“Alex 早上离开家的时候下雨了吗?”。
假设知识库中没有直接回答这个问题的内容,也没有关于天气的信息。我们旨在比较使用我们的方法检索到的信息与通过语义相似性搜索检索到的信息的回答。在知识库中,有两条间接信息暗示了天气状况:
- 与 Cafe A 相关:“许多人在外面的广场上聊天喝咖啡。”
- 与 Company B 相关:“Company B 楼下的洗车店今天生意兴隆。”
这两个片段都微妙地表明没有下雨。
鉴于问题主要是关于 Alex 和天气的,通过语义相似性向量搜索从知识库中检索到的信息只有关于 Alex 的(因为没有关于天气的直接信息)。搜索结果主要概述了他一天中的活动。即使增加搜索条目,也大多会检索到其他杂项细节,如他的咖啡订单和对话。不幸的是,这些细节并不包含任何推断当天天气的线索。
另一方面,使用 AutoKG 和混合搜索方法会产生不同的结果。在知识图谱生成过程中,我们提取了 Alex、Cafe A 和 Company B 等关键词。使用混合搜索,初始步骤使用输入问题检索关键词 Alex。然后,邻接搜索识别 Cafe A 和 Company B 作为相关关键词。随后,基于这些关键词寻找文本块,从而识别出隐含的与天气相关的信息。这个例子说明了混合搜索的实用性。仅凭语义相似性可能缺乏跨主题连接。它倾向于检索给定问题范围内的许多细节。当使用 AutoKG 方法构建的知识图谱进行搜索时,检索到的信息的广度和多样性得到了增强。此外,先前的工作已经轻易证实了 GPT-4 在提供线索的情况下进行有效推理的能力。
从附录中与 GPT-4 的对话记录来看,当给定关于今天天气的线索时,GPT-4 可以准确推断出今天没有下雨。然而,当仅提供来自语义相似性向量搜索的关于 Alex 的信息时,它无法对今天的天气做出任何预测。
B. 使用文章引用的示例
我们提供了一个具体的示例,利用了本文引用的 42 个参考文献中的内容。使用上述概述的混合搜索方法对生成的知识图谱进行交互式查询。知识图谱的生成和后续的查询过程都使用了 gpt-3.5-turbo-16k 模型,以最小化成本。这 40 个参考文献在分段后包含了 5,261 个文本块,每个文本块的长度都不超过 201 个标记。对于关键词提取过程,根据算法 1,参数设置为:n = 15,c = 15,l1 = 10,l2 = 3,m = 300。对于算法 2,我们使用参数 n1 = 5 和 n2 = 35。
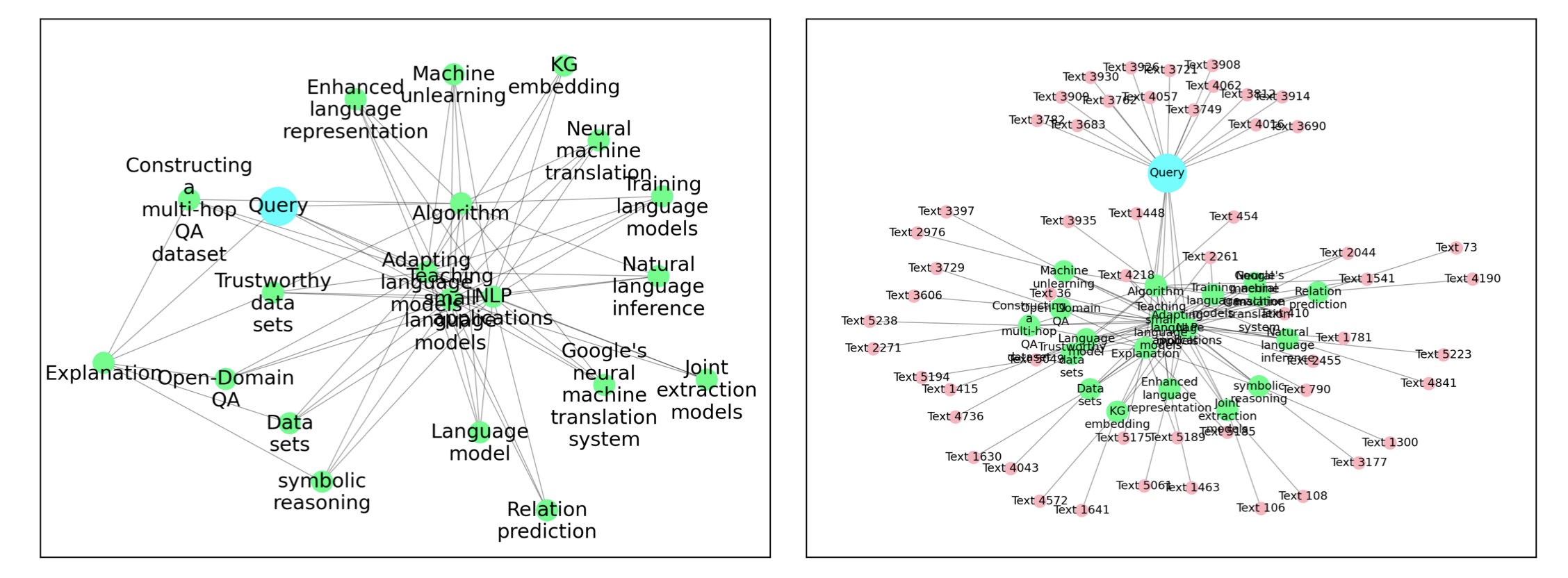
构建的知识图谱包含 461个节点(提取的关键词),其邻接矩阵包含 40,458 个非零元素。图中度最高的节点与 289 个邻居相连。有 353 个节点的度小于 92,这是最大可能度数 460 的 20%。整个知识图谱构建过程大约耗时十分钟。除了调用 OpenAI API 之外,所有计算都在搭载 Intel i9-9900 的 CPU 上进行。关键词提取和知识图谱构建各自需要大约五分钟。对于后续的混合搜索(算法 3 中描述的),我们使用参数($s^t_0 = 15, s^k_1 = 5, s^t_1 = 3, s^k_2 = 3, s^t_2 = 2$),并通过自适应方法确保输入提示保持在不超过 10,000 个标记的长度。响应的最大长度设置为 1024。作为一个说明性的例子,当查询:“请详细介绍 PaLM,并告诉我相关的应用。”时,在混合搜索期间的临时知识图谱结构如图 2 和图 3 所示。这两个图像表示同一个知识图谱的子图,其中输入查询以蓝色节点表示。左侧的图像(图2)仅展示了关键词节点(绿色),而右侧的图像(图3)包括了额外检索到的文本块(粉色节点)。显示的边是直接从查询中检索到的相似关键词之间的边(在左图中显示为内圈节点),以及连接这些相似关键词与通过邻接搜索获得的关键词之间的边(连接左图中的内圈和外圈)。虽然外圈关键词之间可能存在边,但为了清晰起见,在可视化中省略了它们。模型生成了一个较长的响应,附录中有展示。
所有相关的代码和测试用例都可以在 https://github.com/wispcarey/AutoKG 上找到。
V. 结论
本文解决了将大型语言模型(LLMs)与知识库链接时语义相似性搜索方法所面临的固有挑战。我们的方法 AutoKG 提出了一种精细且高效的自动化 KG 构建策略。与传统 KG 相比,AutoKG 的创新架构提供了一个轻量级且简化的 KG 版本,将重点从特定实体转移到更抽象的关键词,并使用加权无向边来表示关键词之间的关联。基于生成的 KG,我们的方法通过混合搜索策略为 LLMs 提供了一个更加互联和全面的知识检索机制。通过这样做,我们确保模型的响应不仅在质量上更丰富,而且从更多样化的信息节点中获得洞察。
我们在实验评估中对 AutoKG 进行了混合搜索测试。由于数据集的限制,我们的测试主要是定性的。结果突出了我们方法与典型的语义相似性搜索 RAG 方法相比的优势。总之,AutoKG 为将知识库与 LLMs 结合提供了一个有价值的步骤。它在计算上轻量级,并为 LLM 应用中的更详细交互铺平了道路。此外,我们的混合搜索和语义向量相似性搜索具有相同数量级的时间复杂性。
Appendix Dialogues With Llm
Dialogue With Gpt-4 For Section Iv-A
如果我们仅提供通过语义向量相似性搜索检索到的信息,GPT-4 无法回答问题。用户请求如下:
1
2
3
4
5
6
回答问题:“Alex 今天早上离开家时下雨了吗?” 提供以下信息:
1. Alex 早上离开家后,去 Cafe A 买咖啡,然后乘公交车去 Company B 上班;
2. Alex 在 Cafe A 买了一杯冰美式咖啡;
3. Alex 和 Coffee Shop A 的员工谈论了他们是否计划开分店;
4. Alex 因为没有按时完成工作在公司 B 被老板批评。
在这种情况下,GPT-4 无法根据提供的信息回答问题。
如果我们提供了基于AutoKG的混合搜索检索到的天气线索信息,GPT-4可以完成推理并正确回答问题:
1
2
3
4
根据以下信息回答问题:“Alex早上离开家时下雨了吗?”
1. 早上离开家后,Alex去咖啡馆A买咖啡,然后乘公交车去B公司上班;
2. 咖啡馆A外的广场上有很多人在聊天喝咖啡;
3. B公司楼下的洗车店今天生意兴隆。
GPT-4回答:
1
根据提供的信息,早上Alex离开家时很可能没有下雨。线索是“许多人在咖啡馆A前的广场上聚集,喝咖啡聊天”,这表明户外环境宜人,不是下雨天气的典型特征。此外,洗车店生意非常好,这表明可能是晴天,因为洗车店在雨天通常会比较冷清。
Appendix Prompt Examples
Task: Keyword Extraction
此提示需要以下预设变量:
'main topic':知识库的高层次主题;'l1':提取的关键词的最大数量;'l2':每个关键词的最大长度;'language':输出关键词的语言;'previous keywords':之前已提取的关键词列表。
一旦从某个簇中采样到文本块,我们使用以下提示进行关键词提取:
关键词提取提示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
You are an advanced AI assistant, specializing in analyzing
various pieces of information and providing precise
summaries. Your task is to determine the core theme in
the following series of *-separated information fragments,
which are delimited by triple backticks. Ensure your answer
focuses on the topic and avoids including unrelated content.
DO NOT write complete sentences.
You should obey the following rules when doing this task:
1, Keywords in your answer should related to the topic
’main topic’; 2, Your answer should include at most ’l1’
keywords; 3, Each keyword should be at most ’l2’ words
long; 4, avoid already appeared theme keywords, marked
inside hi; 5, Write your answer in ’language’; 6, Separate
your output keywords with commas (,); 7, Don’t include any
symbols other than keywords.
Information:’ ’ ’text blocks’ ’ ’
Please avoid the following already appeared theme terms:
h’previous keywords’i
Your response:
Task: Incorporation between KGs and LLMs
对于给定的查询 $q$,我们根据混合搜索算法(算法 3)搜索与其相关的文本块 $X_{final}$ 和关键词 $K_{final}$。给定一个预设的输出语言变量 ‘language’,我们使用以下提示来提供从知识图谱和原始知识库检索到的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
I want you to do a task, deal with a query, or answer a
question with some information from a knowledge graph.
You will be given a set of keywords directly related to a
query, as well as adjacent keywords from the knowledge
graph. Relevant texts will be provided, enclosed within triple
backticks. These texts contain information pertinent to the
query and keywords.
Please note, you should not invent any information. Stick to
the facts provided in the keywords and texts. These additional
data are meant to assist you in accurately completing the
task. Your response should be written in ’language’.
Avoid showing any personal information, like Name, Email,fan
WhatsApp, Skype, and Website in your polished response.
Keywords information (directly related to the query or
find via the adjacent search of the knowledge graph): Kfinal
Text information: ’ ’ ’ Xfinal ’ ’ ’
Your task: q
Your response: