本文是 Microsoft GraphRAG 的笔记。
索引
GraphRAG 的索引 pipeline 由工作流、标准和自定义步骤、提示模板以及输入/输出适配器组成。我们的标准管道旨在:
- 从原始文本中提取实体(entities)、关系(relationships)和声明(claims)
- 对实体进行社区检测(community detection)
- 生成多个层次的社区摘要和报告
- 将实体嵌入到图向量空间中
- 将文本块嵌入到文本向量空间中
管道的输出可以以多种格式存储,包括 JSON 和 Parquet。
Key Concepts
Knowledge Model
在默认配置模式下,索引引擎的输出与我们称之为 GraphRAG 知识模型对齐。知识模型作为底层数据存储技术的抽象,为 GraphRAG 系统提供一个通用的交互接口。GraphRAG 索引器的输出将被加载到数据库系统中,GraphRAG 的查询引擎将使用知识模型数据存储类型与数据库进行交互。
DataShaper Workflows
GraphRAG 的索引 pipeline 是建立在开源库 DataShaper 之上的。DataShaper 其中一个核心资源类型是工作流程(Workflow)。工作流程以一序列的步骤来表示,每个步骤都有一个动词名称和一个配置对象。在 DataShaper 中,这些动词模拟了关系概念,如 SELECT、DROP、JOIN 等。每个动词都会对输入的数据表进行转换,并将该表传递到下一个步骤中。

LLM-based Workflow Steps
GraphRAG 的索引 pipeline 在 DataShaper 库提供的标准关系动词之上实现了一些自定义动词,使之能够利用 GPT-4 等 LLM 的强大功能,通过结构化数据丰富文本文档。我们在标准工作流程中利用这些动词来提取实体、关系、声明、社区结构以及社区报告和摘要。
Workflow Graphs
由于数据索引任务的复杂性,需要将数据 pipeline 表示为多个相互依赖的工作流程序列。在 GraphRAG 索引 pipeline 中,每个工作流程可以定义对其他工作流程的依赖关系,从而形成一个有向无环图(DAG)的工作流程,然后用于调度处理。
Dataframe Message Format
工作流之间以及工作流步骤之间的主要通信单元是 pandas.DataFrame 实例。设计的目标是以数据为中心和以表为中心的方式进行数据处理。这使我们能够轻松地对数据进行推理,且可以利用 dataframe-based 生态系统的能力。
LLM Caching
GraphRAG 库的设计考虑了与 LLM 的交互。在使用 LLM API 时常见的问题是由于网络延迟、限流等原因导致的各种错误。因此在 LLM 交互添加了缓存层。当使用相同的输入集(prompt 和 tuning parameters)进行完成请求时,如果存在缓存结果,我们将返回缓存的结果。这使得我们的索引器对网络问题更具韧性,具有幂等性,并提供更高效的终端用户体验。
Indexing Dataflow
The GraphRAG Knowledge Model
知识模型是符合我们数据模型定义的数据输出的规范。可以在 GraphRAG 仓库的 model 文件夹中找到这些定义。以下是提供的实体类型:
- 文档(Document)- 输入系统的文档。它们可以是 CSV 中的单个行或单个 .txt 文件。
- 文本单元(TextUnit)- 需要分析的文本块。文档和文本单元之间可以是一对多的关系或多对多的关系。
- 实体(Entity)- 从文本单元中提取的实体,可以表示人物、地点、事件或提供的其他实体模型。
- 关系(Relationship)- 两个实体之间的关系,这些关系是从协变量生成的。
- 协变量(Covariate)- 提取的声明信息。
- 社区(Community)- 构建实体和关系图后,我们对它们进行分层社区检测,以创建聚类结构。
- 社区报告(Community Report)- 将每个社区的内容汇总成报告,便于阅读和下游搜索。
The Default Configuration Workflow
Phase 1: Compose TextUnits
默认配置工作流程的第一阶段是将输入文档转换为文本单元,即用于图提取技术的文本块。它们还被提取的知识项用作源引用,以便于溯源。
文本块的大小(以标记计数),可以由用户进行配置。默认值为 300 个标记。较大的块会导致输出的保真度降低,并且有意义的参考文本较少。然而,使用较大的文本块可以显著提高处理速度。
分组配置也可以由用户进行配置。默认情况下,我们将文本块与文档边界对齐,这意味着文档和文本单元是严格一对多关系。当文档非常短且我们需要多个文档来组成一个有意义的分析单元时(例如推文或聊天记录),文档和文本单元可以配置为多对多关系。
每个文本单元都会进行文本嵌入(text-embedded),并传递到 pipeline 的下一个阶段。
Phase 2: Graph Extraction
在这个阶段,我们分析每个文本单元并提取我们的图基元:实体、关系和声明。实体和关系由 entity_extract 动词一次性提取,声明则在 claim_extract 动词中提取。然后将结果合并并传递到 pipeline 的后续阶段。
Entity & Relationship Extraction
在图提取的第一步中,我们处理每个文本单元,使用 LLM 从原始文本中提取实体和关系。该步骤输出每个文本单元的子图,包含实体列表(包括实体名称、类型和描述),以及一个关系列表(包括源、目标和描述)。接下来对子图进行合并,具有相同名称和类型的实体会被合并,并把他们的描述保存为列表。具有相同源和目标的关系会被合并,同样的把他们的描述保存为列表。
Entity & Relationship Summarization
现在我们有了一个包含实体和关系的图,每个实体和关系都有一个描述列表,通过 LLM 将这些列表总结为每个实体和关系的简短描述。
Claim Extraction & Emission
最后,作为一个独立的工作流程,我们从源文本单元中提取声明,然后被导出为 Covariates。这一步是可选的,默认情况下是关闭的,这是因为声明提取通常需要进行提示调整。
Phase 3: Graph Augmentation
现在我们有了一个可用的实体和关系图,我们希望了解它们的社区结构,并通过附加信息来增强图。这可以通过两个步骤来完成:社区检测和图嵌入。这些步骤为我们提供了显式(社区)和隐式(嵌入)的方式来理解我们图形的拓扑结构。
Community Detection
我们使用层次 Leiden 算法生成实体社区的层次结构。该方法对社区进行递归聚类,直到达到一个社区大小的阈值。这将使我们能够了解图的社区结构,并提供一种在不同粒度级别上导航和总结图的方式。
Graph Embedding
我们使用 Node2Vec 算法生成我们图的向量表示。这将使我们能够理解图的隐含结构,并提供一个额外的向量空间,以在查询阶段搜索相关概念时使用。
Graph Tables Emission
一旦我们完成了图增强步骤,最终的实体和关系表会对他们的文本字段进行文本嵌入然后导出。
Phase 4: Community Summarization
社区的报告能让我们在图的多个粒度上获得高层次的理解。例如,如果社区 A 是最高级别的社区,我们将获得关于整个图形的报告。如果社区是较低级别的,我们将获得关于一个局部集群的报告。
Generate Community Reports
我们使用 LLM 生成每个社区的摘要。这些报告包含高层概述(executive overview),并引用社区子结构中的关键实体、关系和声明。
Summarize Community Reports
通过 LLM 对每个社区报告进行概括。
Community Embedding
我们通过生成社区报告、社区报告摘要和社区报告标题的文本嵌入,来生成我们社区的向量表示。
Community Tables Emission
导出 Communities 和 CommunityReports 表格。
Phase 5: Document Processing
在工作流的这个阶段,我们为知识模型创建文档表。
Link to TextUnits
我们将每个文档与第一阶段创建的文本单元进行关联。这样我们就可以了解文档与文本单元的关联关系。
Document Embedding
我们使用文档切片的平均嵌入生成文档的向量表示。我们重新切分文档(切片之间无重叠),并为每个切片生成一个嵌入。我们按令牌数量加权计算这些切片的平均值,并将其用作文档嵌入。这使我们理解文档之间的隐含关系,并帮助我们生成文档的网络表示。
Documents Table Emission
将文档表导出到知识模型中。
Phase 6: Network Visualization
我们使用 UMAP 降维操作,生成图形的二维表示。
提示调优
GraphRAG 索引引擎的提示调优包括以下选项:
- 默认提示:开箱即用,只需进行最小配置即可。
- 自动调优:利用输入数据和 LLM 交互来创建适应领域的提示,用于生成知识图谱。强烈建议运行它。
- 手动调优:高级用例。
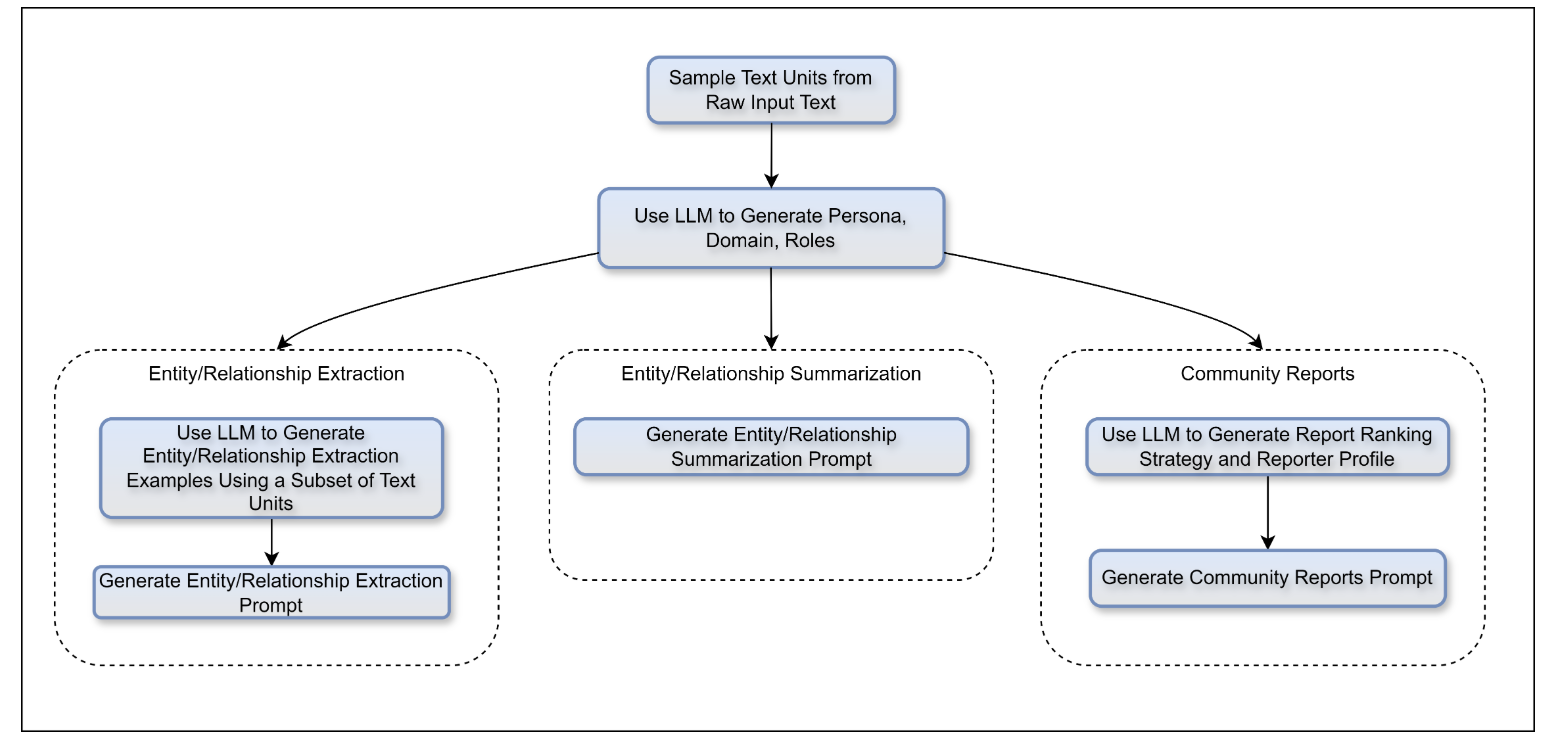
Auto Prompt Tuning
Auto Prompt Tuning 通过加载输入数据,将其分割成块(文本单元),然后运行一系列 LLM 调用和模板替换来生成最终的提示:
Query
查询引擎是 GraphRAG 库的检索模块。它是 GraphRAG 库的两个主要组成部分之一,负责以下任务:
- 局部搜索(Local Search):结合 AI 提取的知识图谱中的相关数据和原始文档的文本块来生成答案。这种方法适用于需要理解文档中提到的特定实体的问题。
- 全局搜索(Global Search):以 Map-Reduce 的方式在所有 AI 生成的社区报告中进行搜索,从中生成答案。
- DRIFT 搜索(DRIFT Search):在搜索过程中包含社区信息,提供更全面的局部搜索选项。利用社区见解将查询细化为详细的后续问题,扩展了 GraphRAG 查询引擎的功能。
- 问题生成(Question Generation):接收用户查询的列表并生成下一个候选问题。这对于在对话中生成后续问题或为调查人员生成深入研究数据集的问题列表非常有用。
Global Search
Whole Dataset Reasoning
基准 RAG 难以应对需要跨数据集聚合信息以组成答案的查询。例如,“数据中有哪些前5个主题?”。因为基准 RAG 依赖于对数据集中语义相似的文本内容进行向量搜索。查询中没有任何指示它找到正确信息的内容。
然而,通过 GraphRAG,我们可以回答这类问题,因为由 LLM 生成的知识图谱的结构展示了整个数据集的结构。这使得私有数据集可以被组织成有意义的语义聚类,并进行预摘要。使用全局搜索方法,LLM 在回答用户查询时使用这些聚类来对主题进行摘要。
Methodology
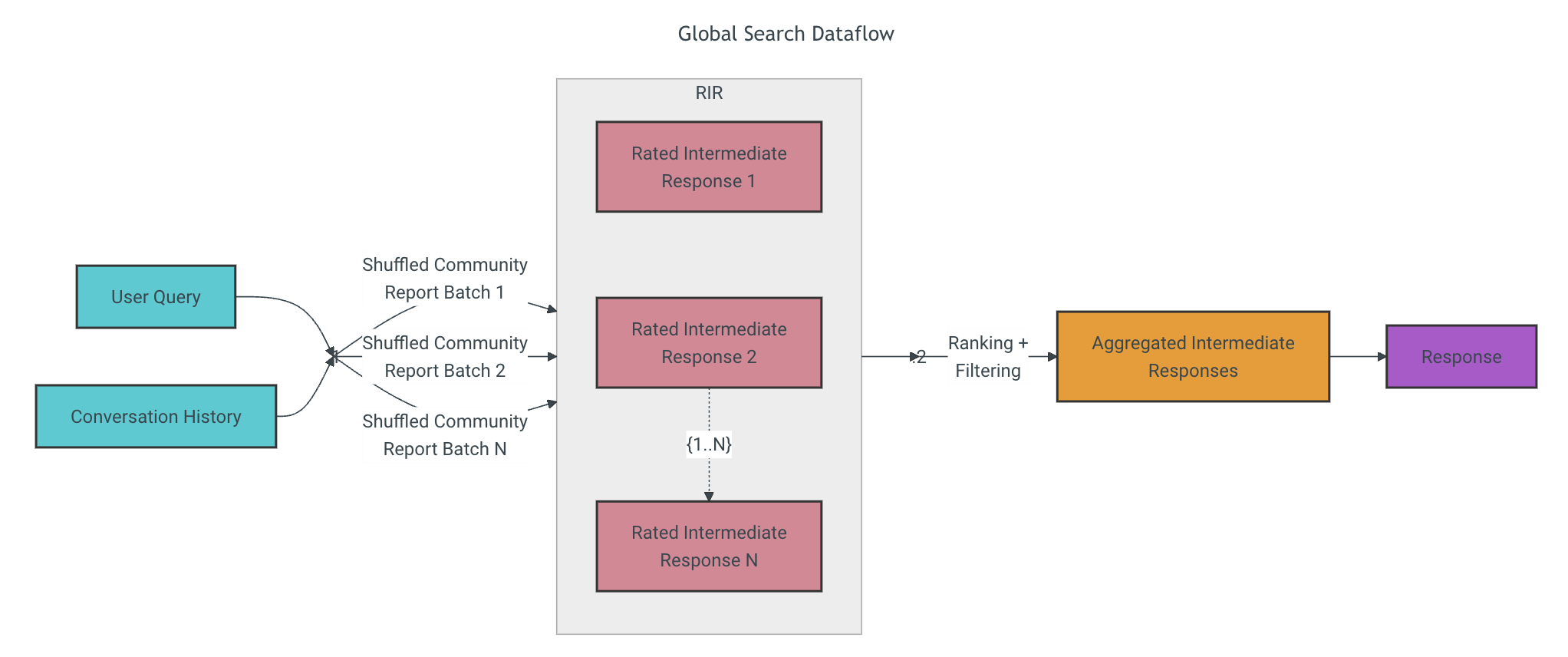
全局搜索方法根据用户查询和(可选的)对话历史,使用 LLM 生成的社区报告集合作为上下文数据,以 Map-Reduce 的方式生成响应。在 Map 步骤中,社区报告被分割成预定义大小的文本块。然后,每个文本块用于生成一个包含一系列要点的中间响应,每个要点都附带一个表示重要性的数值评分。在 Reduce 步骤中,从中间响应中筛选出的最重要的要点并进行汇总,用作生成最终响应的上下文。
全局搜索的响应质量很大程度上取决于选择用于获取社区报告的社区层级。较低级别的层次结构具有详细的报告,往往能够提供更全面的响应,但可能会增加生成最终响应所需的时间和 LLM 资源。
Local Search
Entity-based Reasoning
局部搜索方法在查询时将知识图谱中的结构化数据与输入文档中的非结构化数据相结合,以提供相关实体信息来增强 LLM 上下文。非常适合回答需要理解输入文档中特定实体的问题。
Methodology
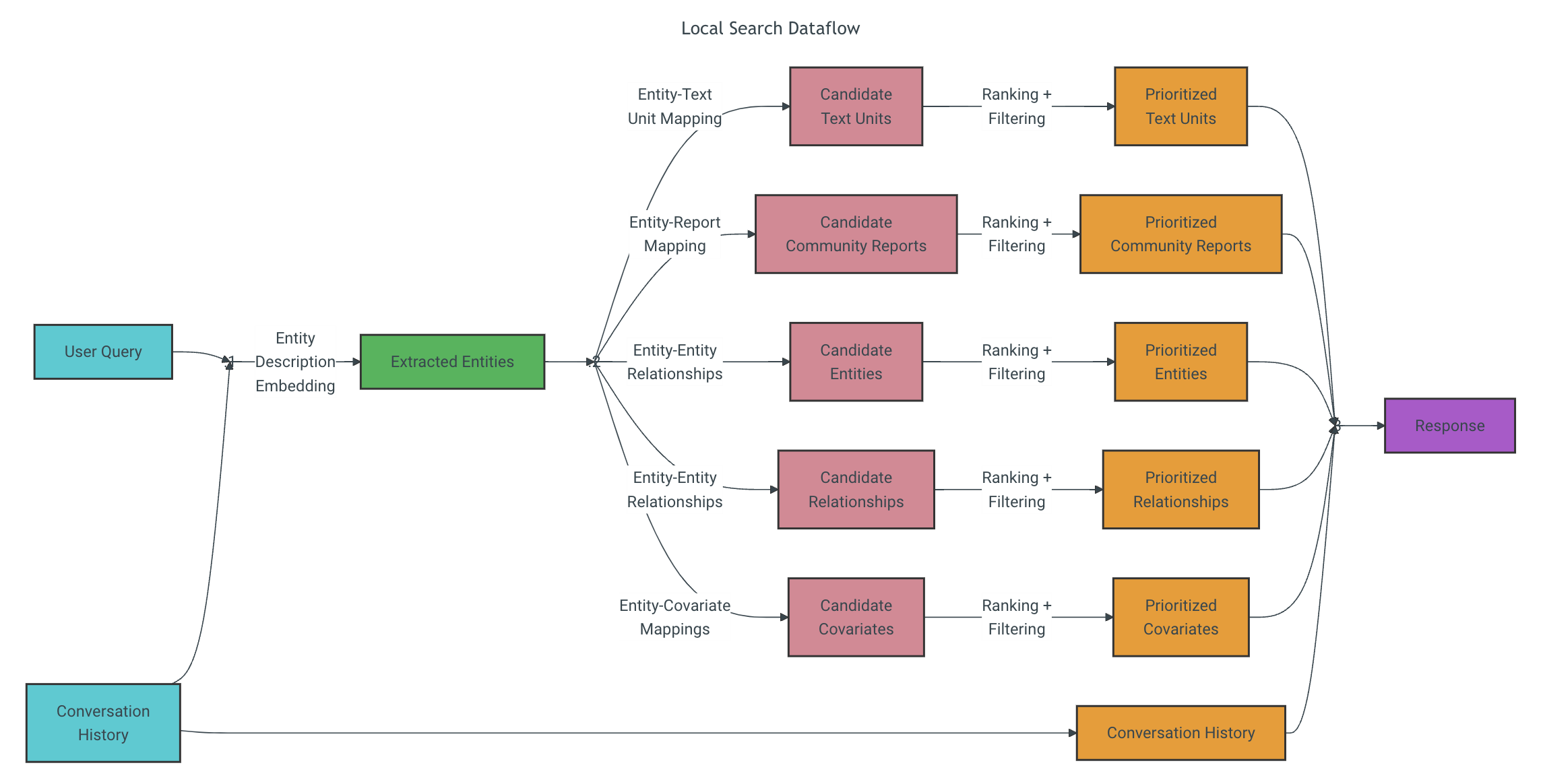
根据用户查询和(可选的)对话历史,局部搜索方法识别出与用户输入在语义上相关的一组知识图谱实体。这些实体作为进入知识图谱的访问点,可以进一步提取相关细节,如连接的实体、关系、实体协变量和社区报告。此外还会从原始输入文档中提取与识别的实体相关的文本块。然后,对这些候选数据源进行优先级排序和过滤,以适应预定义大小的上下文窗口,用于生成对用户查询的响应。
DRIFT Search
Combining Local and Global Search
DRIFT 搜索(Dynamic Reasoning and Inference with Flexible Traversal)结合了全局搜索和局部搜索的特点,在计算成本和质量结果之间平衡。
Methodology

整个 DRIFT 搜索层次结构突出了 DRIFT 搜索过程的三个核心阶段:
- Primer:DRIFT 将用户的查询与最相关的 K 个社区报告进行比较,生成广泛的初始答案和后续问题,以引导进一步的探索。
- Follow-Up:DRIFT 使用局部搜索来细化查询,生成额外的中间答案和后续问题,增强特定性,引导引擎获取丰富的上下文信息。图表中每个节点上的符号显示了算法继续查询扩展步骤的置信度。
- Output Hierarchy:最终输出是一个按相关性排名的问题和答案的层次结构,反映了全局洞察和局部细化的混合,使结果具有适应性和全面性。
Question Generation
Entity-based Question Generation
问题生成方法将知识图谱中的结构化数据与输入文档中的非结构化数据相结合,生成与特定实体相关的候选问题。
Methodology
根据先前用户提出的问题列表,问题生成方法使用与局部搜索相同的上下文构建方法,然后,整合到一个 LLM 提示中,以生成代表数据中最重要或紧急信息内容或主题的候选后续问题。