本文是《Deepseek-V2: A Strong, Economical, And Efficient Mixture-Of-Experts Language Model》的笔记。
Abstract
我们介绍了 DeepSeek-V2,这是一个强大的混合专家(Mixture-of-Experts,MoE)语言模型,具有经济高效的训练和推理特性。DeepSeek-V2 采用了创新的架构,包括多头潜在注意力(Multi-head Latent Attention,MLA)和 DeepSeekMoE。MLA 通过将 KV cache 压缩为潜在向量,确保了高效的推理过程,而 DeepSeekMoE 通过稀疏计算实现了以经济的成本训练强大模型的能力。与DeepSeek 670 亿相比,DeepSeek-V2 实现了显著更强的性能,同时节省了 42.5% 的训练成本,将 KV cache 减少了 93.3%,并将最大生成吞吐量提升了 5.76 倍。我们在一个高质量和多源语料库上对 DeepSeek-V2 进行了预训练,该语料库包含 81 万亿个标记,并进一步进行了监督微调(Supervised Fine-Tuning,SFT)和强化学习(Reinforcement Learning,RL)以充分发挥其潜力。评估结果显示,即使只有 210 亿个激活参数,DeepSeek-V2 及其 chat 版本仍然在开源模型中取得了顶尖的性能。
架构
DeepSeek-V2 基本上仍然采用 Transformer 架构,其中每个 Transformer 块由一个注意力模块和一个前馈神经网络(FFN)组成。然而,对于注意力模块和 FFN,我们设计并采用了创新的架构。
对于注意力模块,我们设计了 MLA,该模块利用低秩键值联合压缩(low-rank key-value joint compression)来消除推理时键值缓存的瓶颈,从而支持高效的推理。对于 FFNs,我们采用了 DeepSeekMoE 架构,这是一种高性能的 MoE 架构,能够在经济成本下训练出强大的模型。
多头潜在注意力:提升推理效率
传统的 Transformer 模型通常采用多头注意力(MHA),但在生成过程中,其庞大的 kv cache 会成为限制推理效率的瓶颈。我们设计了一种创新的注意力机制,称为多头潜在注意力(MLA)。MLA 比 MHA 实现了更好的性能,且需要的 kv cache 量明显更少。
预备知识:标准多头注意力
标准 MHA 首先通过三个矩阵 $W_Q,W_K, W_V \in \mathbb{R}^{d_h n_h \times d}$ 分别生成 $q_t, k_t, v_t \in \mathbb{R}^{d_h n_h}$:
\[\begin{align*} q_t &= W^Q h_t, \\ k_t &= W^K h_t, \\ v_t &= W^V h_t. \end{align*}\]其中嵌入维度为 $d$,注意力头数为 $n_h$,每个头的维度为 $d_h$,第 $t$ 个令牌在注意力层的输入为 $h_t \in \mathbb{R}^d$。然后,$q_t$、$k_t$ 和 $v_t$ 将被切分为 $n_h$ 个头进行多头注意力计算:
\[\begin{align*} [q_{t,1}; q_{t,2}; \ldots; q_{t,n_h}] &= q_t, \\ [k_{t,1}; k_{t,2}; \ldots; k_{t,n_h}] &= k_t, \\ [v_{t,1}; v_{t,2}; \ldots; v_{t,n_h}] &= v_t, \\ \end{align*}\] \[\begin{align*} o_{t,i} &= \sum_{j=1}^t \text{Softmax}_j\left(\frac{q^T_{t,i} \cdot k_{j,i}}{\sqrt{d_h}}\right) v_{j,i}, \\ u_t &= W^O[o_{t,1}; o_{t,2}; \ldots; o_{t,n_h}]. \end{align*}\]其中 $q_{t,i}$、$k_{t,i}$ 和 $v_{t,i}$ 分别表示第 $t$ 个令牌在第 $i$ 个注意力头的查询、键和值;$W^O \in \mathbb{R}^{d\times d_h n_h}$ 为输出投影矩阵。在推理过程中,为了加速推理,所有的键和值都需要被缓存,因此多头注意力需要为每个 token 缓存 $2n_hd_hl$ 个元素。在模型部署中,庞大的 kv cache 是限制最大 batch size 和序列长度的重要瓶颈。
低秩键-值联合压缩
MLA 的核心是对键和值进行低秩联合压缩以减少 kv cache:
\[\begin{align*} {\mathbf{c}}_{\mathrm{t}}^{K V}=W^{D K V}{\bf h}_{t}, \tag{9} \\ {\mathbf{k}}_{\mathrm{t}}^{C}=W^{U K}{\mathbf{c}}_{\mathrm{t}}^{K V}, \tag{10} \\ {\mathbf{v}}_{\mathrm{t}}^{C}=W^{U V}{\mathbf{c}}_{\mathrm{t}}^{K V} \tag{11}, \end{align*}\]其中 $\mathbf{c}^{KV}_\mathrm{t} \in \mathbb{R}^{d_c}$ 是键和值的压缩潜在向量;$d_c(≪ d_hn_h)$ 表示 KV 压缩维度;${W}^{D K V} \in \mathbb{R}^{d_c \times d}$ 是下投影矩阵;${W}^{U K}, {W}^{U V} \in \mathbb{R}^{d_h n_h \times d_c}$ 分别是键和值的上投影矩阵。
在推理过程中,MLA 只需要缓存 $\mathbf{c}_\mathrm{t}^{KV}$,因此其 KV 缓存只有 $d_cl$ 个元素,其中 $l$ 表示层数。此外,在推理过程中,由于 $W^{UK}$ 可以被吸收到 $W^Q$ 中,$W^{UV}$ 可以被吸收到 $W^Q$ 中,我们甚至不需要计算用于注意力的键和值。
注:这里的“吸收”的意思如下,将矩阵乘法展开,可以用 $\left(\boldsymbol{W}^Q{}^{\top}\boldsymbol{W}^{UK}\right)$ 替换 $W^Q$:
\[\begin{equation}\boldsymbol{q}_t^{\top} \boldsymbol{k}_t{} = \left(\boldsymbol{W}^Q\boldsymbol{h}_t\right)^\top \left(\boldsymbol{W}^{UK} \boldsymbol{c}_t^{KV}\right){} = \left(\boldsymbol{h}_t^{\top}\boldsymbol{W}^Q{}^{\top}\right) \left(\boldsymbol{W}^{UK}\boldsymbol{c}_t^{KV}\right) = \boldsymbol{h}_t^{\top}\left(\boldsymbol{W}^Q{}^{\top}\boldsymbol{W}^{UK}\right)\boldsymbol{c}_t^{KV} \end{equation}\]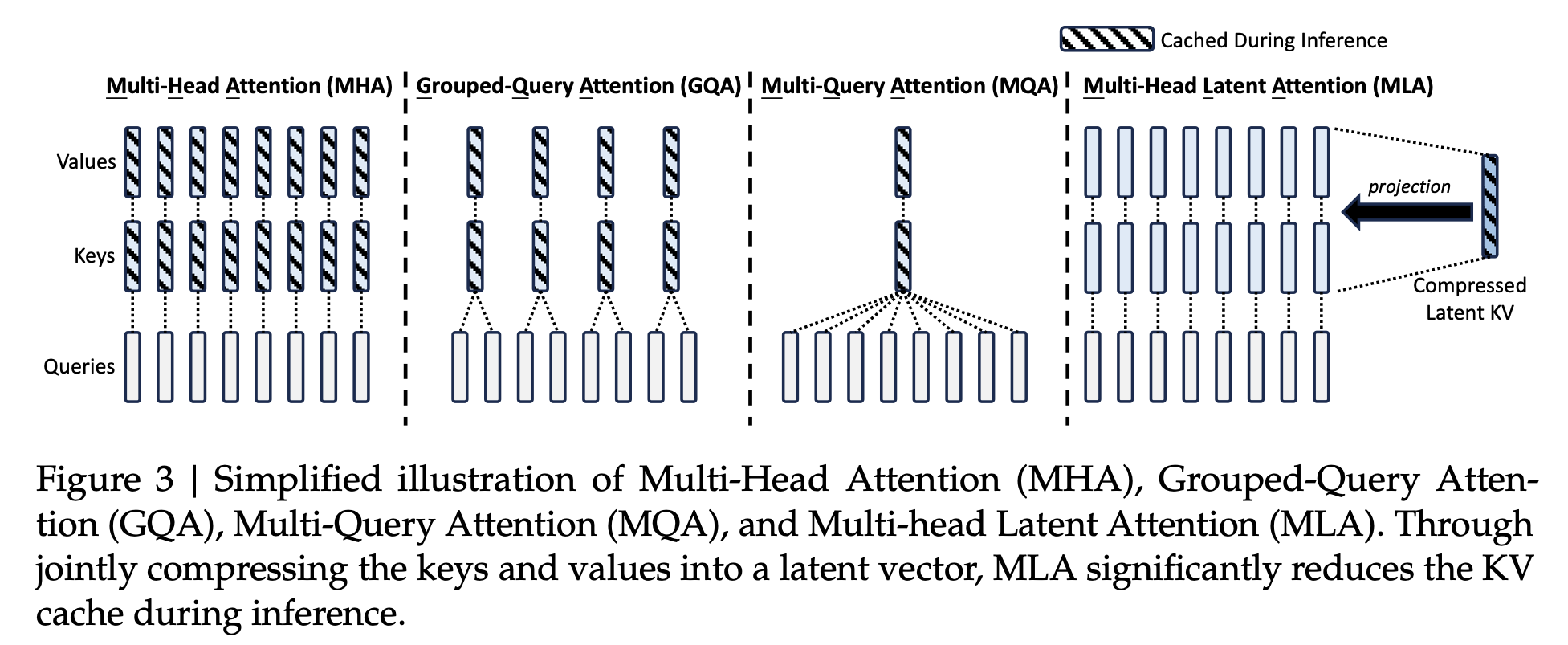
为了在训练期间减少激活内存,我们还对查询进行低秩压缩,即使它不能减少 KV 缓存:
\[{\mathbf{c}}_{\mathrm{t}}^{Q}=W^{D Q}{\bf h}_{t},\\ {\mathbf{q}}_{\mathrm{t}}^{C}=W^{U Q}{\mathbf{c}}_{\mathrm{t}}^{Q},\]其中 ${\mathbf{c}}_{\mathrm{t}}^{Q} \in \mathbb{R}^{d_c^\prime}$是查询的压缩潜在向量;$d_c’$(≪ $d_h n_h$)表示查询压缩维度;${W}^{D Q} \in \mathbb{R}^{d_c’ \times d}, {W}^{U Q} \in \mathbb{R}^{d_h n_h \times d_c’}$ 分别是查询的下投影矩阵和上投影矩阵。
解耦旋转位置嵌入
我们打算在 DeepSeek-V2 中使用旋转位置嵌入(RoPE)。然而 RoPE 与低秩 KV 压缩不兼容。具体来说,RoPE 对键和查询都是位置敏感的。如果我们对键 ${\mathbf{k}}_{\mathrm{t}}^{C}$ 应用 RoPE,那么公式 $10$ 中 $W^{UK}$ 将与一个位置敏感的 RoPE 矩阵耦合。
这样,在推理过程中就无法将 $W^{UK}$ 吸收到 $W^Q$ 中,因为与当前生成的 token 相关的一个 RoPE 矩阵将位于 $W^Q$ 和 $W^{UK}$ 之间,而矩阵乘法不满足交换律。因此,在推理过程中,我们必须重新计算所有前缀 token 的键,这将显著阻碍推理的效率。
作为解决方案,我们提出了解耦 RoPE 策略,该策略使用额外的多头查询 $\mathbf{q}^R_{t,i} \in \mathbb{R}^{d^R_h}$ 和共享键 $\mathbf{k}^R_t \in \mathbb{R}^{d^R_h}$ 来携带 RoPE,其中 $d^R_h$ 表示解耦查询和键每个头的维度。配备解耦 RoPE 策略,MLA 执行以下计算:
\[\begin{align*} [\mathbf{q}^R_{t,1}; \mathbf{q}^R_{t,2};...; \mathbf{q}^R_{t,n_h}] = \mathbf{q}^R_t = RoPE(W^{QR}\mathbf{c}_t^Q), \\ \mathbf{k}^R_t = RoPE(W^{KR}\mathbf{h}_t), \\ \mathbf{q}_{t,i} = [\mathbf{q}^C_{t,i}; \mathbf{q}^R_{t,i}], \\ \mathbf{k}_{t,i} = [\mathbf{k}^C_{t,i}; \mathbf{k}^R_{t}], \\ \mathbf{o}_{t,i} = \sum_{j=1}^{t} \text{Softmax}_j(\frac{\mathbf{q}^{\top}_{t,i}\mathbf{k}_{j,i}}{\sqrt{d_h+d_h^R}})\mathbf{v}^C_{j,i}, \\ \mathbf{u}_t = W^O[\mathbf{o}_{t,1}; \mathbf{o}_{t,2};...; \mathbf{o}_{t,n_h}] \end{align*}\]其中 $W^{QR} \in \mathbb{R}^{d^R_h n_h \times d_c’}, W^{KR} \in \mathbb{R}^{d^R_h \times d}$ 分别是用来生成解耦查询和键的矩阵。$RoPE(·)$ 表示应用 RoPE 矩阵的操作;$[·; ·]$ 表示 concatenation 操作。在推理过程中,解耦的键也需要被缓存。因此,DeepSeek-V2 需要一个包含 $d_c + d^R_h l$ 个元素的 kv cache。
DeepSeekMoE: 以经济成本训练强大模型
基础架构
DeepSeekMoE 有两个关键思想:将专家细分为更细的粒度,以提高专家的专业化程度和更准确的知识获取,并隔离一些共享的专家,以减少路由专家之间的知识冗余。在激活的专家参数和总专家参数数量相同的情况下,DeepSeekMoE 可以大幅超越例如 GShard 等传统的 MoE 架构。
设 $\mathbf{u}_{t}$ 为第 $t$ 个 token 的 FFN 输入,我们按如下方式计算 FFN 输出 $\mathbf{h}’_t$:
\[\begin{align*} \mathbf{h}_{t}^{\prime}&=\mathbf{u}_{t}+\sum_{i=1}^{N_{s}}\mathrm{FFN}_{i}^{(s)}\left(\mathbf{u}_{t}\right)+\sum_{i=1}^{N_{r}}g_{i,t}\,\mathrm{FFN}_{i}^{(r)}\left(\mathbf{u}_{t}\right), \\ g_{i,t}&=\begin{cases}s_{i,t},&s_{i,t}\in\mathrm{Topk}(\{s_{j,t}|1\leqslant j\leqslant N_{r}\},K_{r}),\\ 0,&\text{otherwise},\end{cases} \\ s_{i,t}&=\mathrm{Softmax}_{i}\left(\mathbf{u}_{t}^{T}\mathbf{e}_{i}\right) \end{align*}\]其中 $N_{s}$ 和 $N_{r}$ 分别表示共享专家和路由专家的数量。$\text{FFN}_i^{(s)}(·)$ 和 $\text{FFN}_i^{(r)}(·)$ 分别表示第 $i$ 个共享专家和第 $i$ 个路由专家。$K_r$ 表示激活的路由专家数量。
$g_{i,t}$ 是第 $i$ 个专家的门值,$s_{i,t}$ 表示 token 到专家的关联度;$e_i$ 表示该层中第 $i$ 个路由专家的质心(centroid);$\text{Topk}(·, K)$ 表示在计算给定第 $t$ 个标记和所有路由专家之间的关联度得分时,选择其中最高的 K 个分数构成的集合。
设备限制的路由
我们设计了一种设备限制的路由机制来限制与 MoE 相关的通信成本。当使用专家并行性时,路由的专家将分布在多个设备上。对于每个 token,其与 MoE 相关的通信频率与其目标专家所覆盖的设备数量成正比。由于 DeepSeekMoE 中的细粒度专家分割,激活的专家数量可能很大,因此如果应用专家并行性,与 MoE 相关的通信成本将更高。
对于DeepSeek-V2,在对路由的专家进行简单的 top-K 选择之外,我们还确保每个标记的目标专家最多分布在 M 个设备上。具体而言,对于每个标记,我们首先选择具有最高关联度得分的专家的 M 个设备。然后,在这 M 个设备上对专家进行 top-K 选择。在实践中,我们发现当 $M ⩾ 3$ 时,设备限制的路由可以实现与无限制的 top-K 路由大致相当的性能。
辅助损失用于负载均衡
在自动学习路由策略时,我们考虑了负载均衡。首先,不平衡的负载会增加路由崩溃的风险,阻碍一些专家得到充分训练和利用。其次,当采用专家并行性时,不平衡的负载会降低计算效率。在DeepSeek-V2 的训练过程中,我们设计了三种辅助损失,分别用于控制专家级负载均衡、设备级负载均衡和通信均衡。
Token 丢弃策略
为了进一步减少由不平衡负载引起的计算浪费,我们在训练过程中引入了一种基于设备级别的 token 丢弃策略。该策略首先计算每个设备的平均计算预算,即每个设备的容量因子等于 1.0。然后,受到 Riquelme 等人的启发,我们在每个设备上丢弃具有最低关联度得分的标记,直到达到计算预算。此外,我们确保大约 10% 的训练序列中的 token 永远不会被丢弃。通过这种方式,我们可以根据效率要求灵活决定在推理过程中是否丢弃标记,并始终确保训练和推理之间的一致性。
讨论
SFT 数据量
关于是否需要大量 SFT 语料的讨论一直存在激烈争议。先前的研究认为少于 10K 的 SFT 数据实例就足以产生令人满意的结果。然而,在我们的实验中,如果使用少于 10K 的实例,我们在 IFEval 基准测试上观察到显著的性能下降。可能的解释是,语言模型需要一定量的数据来发展特定技能。尽管随着模型规模的增加,所需的数据量可能会减少,但不能完全消除。我们的观察强调了为语言模型提供足够数据以获得所需能力的重要性。此外,SFT 数据的质量也至关重要,特别是对于涉及写作或开放性问题的任务。
强化学习的一致性税(Alignment Tax of Reinforcement Learning)
对齐过程可能对一些标准基准测试的性能产生负面影响。为了减轻对齐成本,在强化学习阶段,我们在数据处理和改进训练策略方面做出了重大努力,最终在标准和开放式基准测试之间实现了可接受的权衡。探索如何在不损害模型整体性能的情况下将其与人类偏好对齐,为未来的研究提供了有价值的方向。