数据并行 Data Parallelism
Data Parallelism 是最常见的并行计算形式,数据集被分割成多个片段,每个片段被分配给一个设备。这相当于沿着批次维度并行化训练过程。每个设备有模型副本的完整拷贝,并在分配的数据集片段上进行训练。在反向传播之后,模型的梯度将进行 all-reduced,以保持不同设备上的模型参数同步。
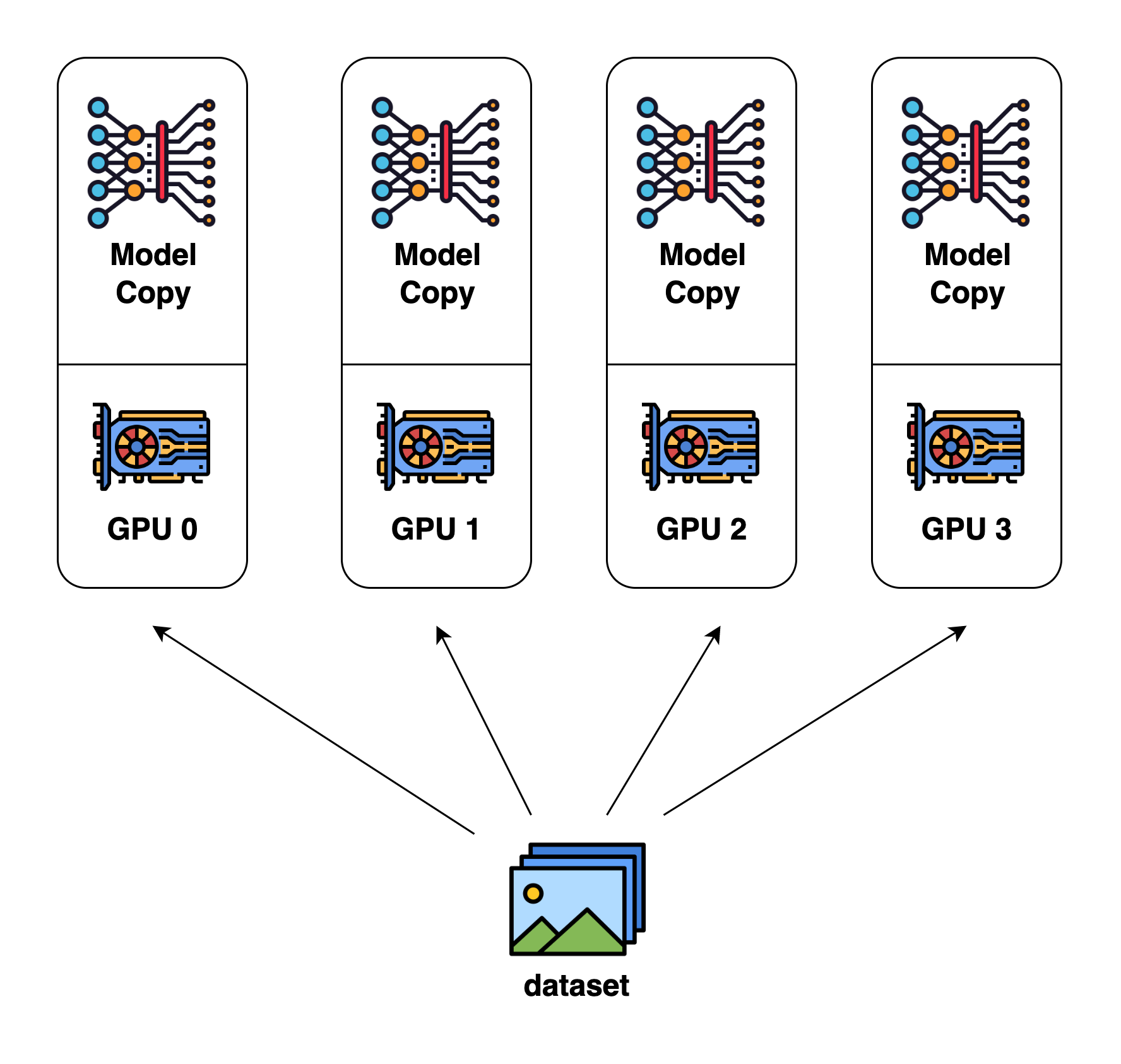
DistributedDataParallel vs DataParallel
Data Parallelism 可以方便地利用 PyTorch 内置的功能来实现。PyTorch 文档建议在多 GPU 训练中优先选择 DistributedDataParallel(DDP)而不是 DataParallel(DP),因为它适用于所有模型。
DDP
- 在开始时,主进程将模型从 GPU 0 复制到其他 GPU 上。
- 然后对于每个批次:
- 每个 GPU 直接使用其小批量数据。
- 在 backward 过程中,一旦本地梯度准备好,它们会在所有进程中进行平均。
DP
对于每个批次:
- GPU 0 读取数据批次,然后将小批量数据发送到每个 GPU。
- 从 GPU 0 复制最新的模型到每个 GPU。
- 执行 forward,并将每个 GPU 的输出发送到 GPU 0 以计算损失。
- 损失从 GPU 0 分发到所有 GPU,并运行 backward。
- 每个 GPU 的梯度发送到 GPU 0 并进行平均。
其关键区别包括:
- DDP 通常比 DP 更快:
- DDP 每个批次只执行一次通信 - 发送梯度,而 DP 每个批次执行五次不同的数据交换。
- DDP 使用torch.distributed 来复制数据,而 DP 通过 Python 线程在进程内复制数据(引入了与 GIL 相关的限制)。
- DP 中 GPU 0 执行的工作量明显多于其他 GPU,导致 GPU 利用率不高。
- DDP 支持跨多台机器进行分布式训练,而 DP 不支持。
- DDP 支持与模型并行一起使用,而 DP 目前不支持。当 DDP 与模型并行结合使用时,每个 DDP 进程都会使用模型并行,而所有进程共同使用数据并行。
具体可见 Getting Started with Distributed Data Parallel。
Model Parallel
模型并行中,模型被分割并分布在一组设备上。通常有以下两种类型:
- Tensor Parallelism(张量并行):在 op 内部(如矩阵乘法)并行化计算
- Pipeline Parallelism(流水线并行):在层之间并行化计算
另一个角度来看,张量并行可以被视为层内并行,而流水线并行可以被视为层间并行。
Tensor Parallel
张量并行训练是将一个张量沿着特定维度分割成 N 个块,每个设备只持有整个张量的 1/N 部分,需要额外的通信来确保结果的正确性。参考下图:
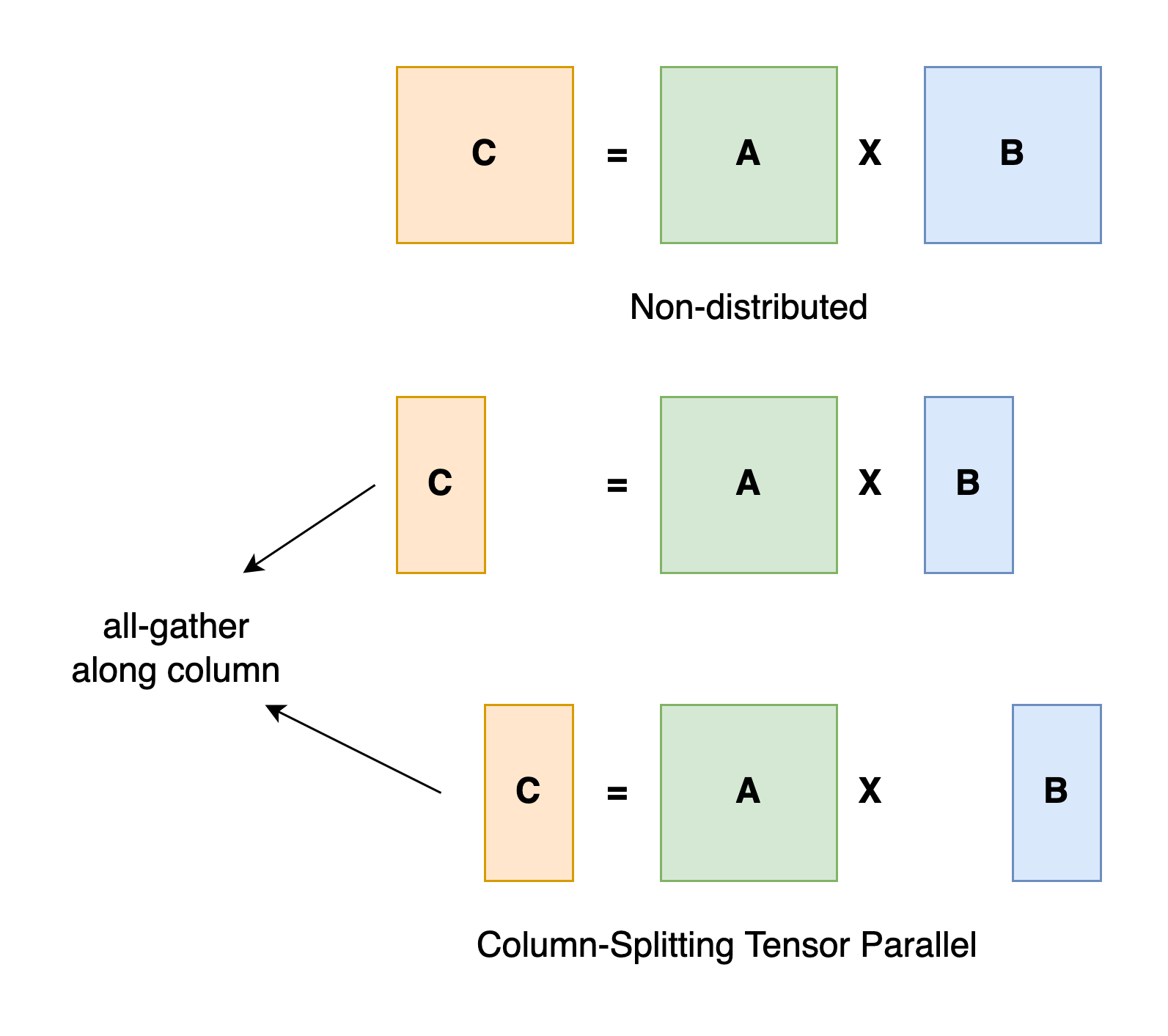
Pipeline Parallel
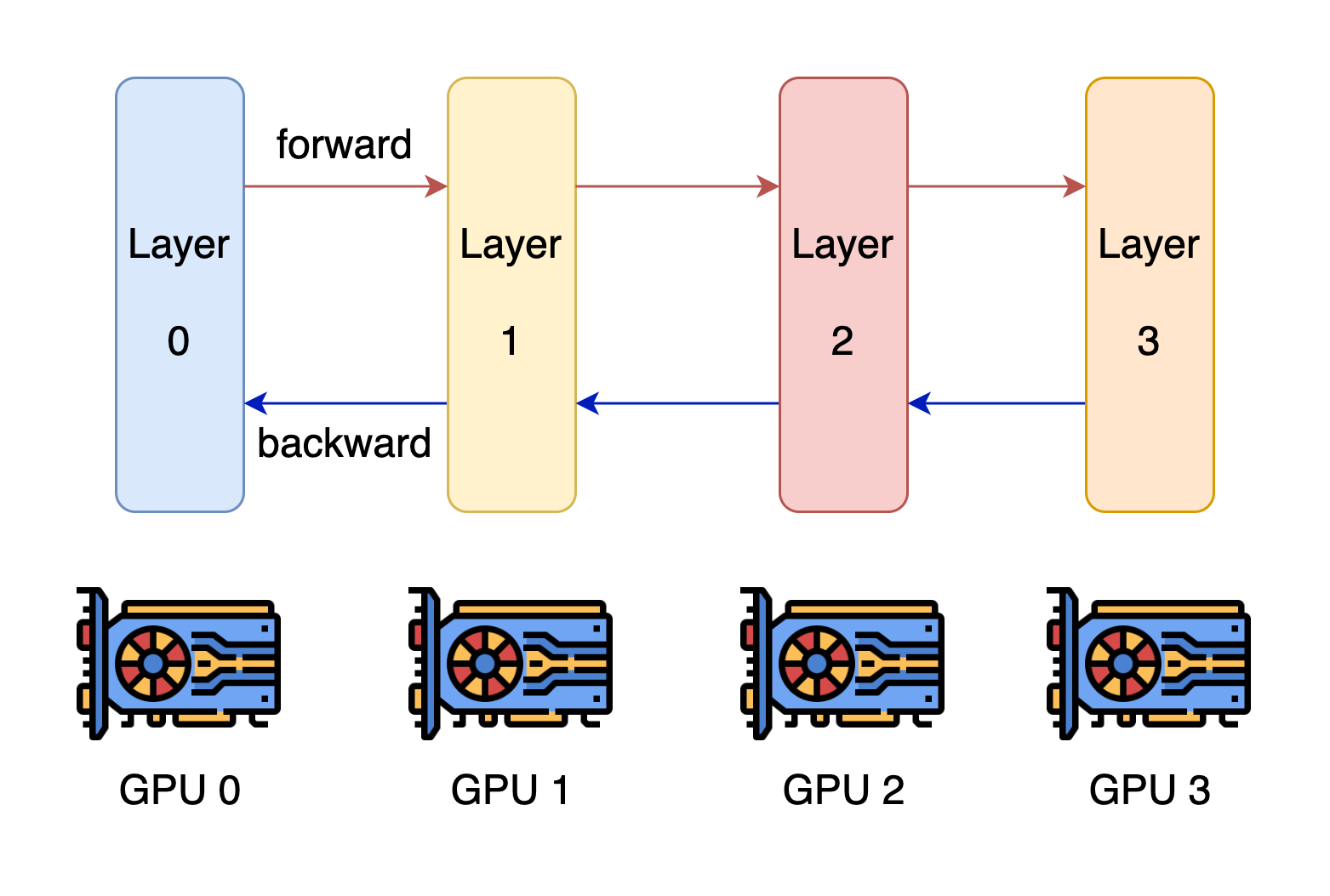
流水线并行的核心思想是将模型按层分割成几个块,每个块分配给一个设备。在前向传播过程中,每个设备将中间激活传递给下一个阶段。在反向传播过程中,每个设备将输入张量的梯度传递回前一个流水线阶段。
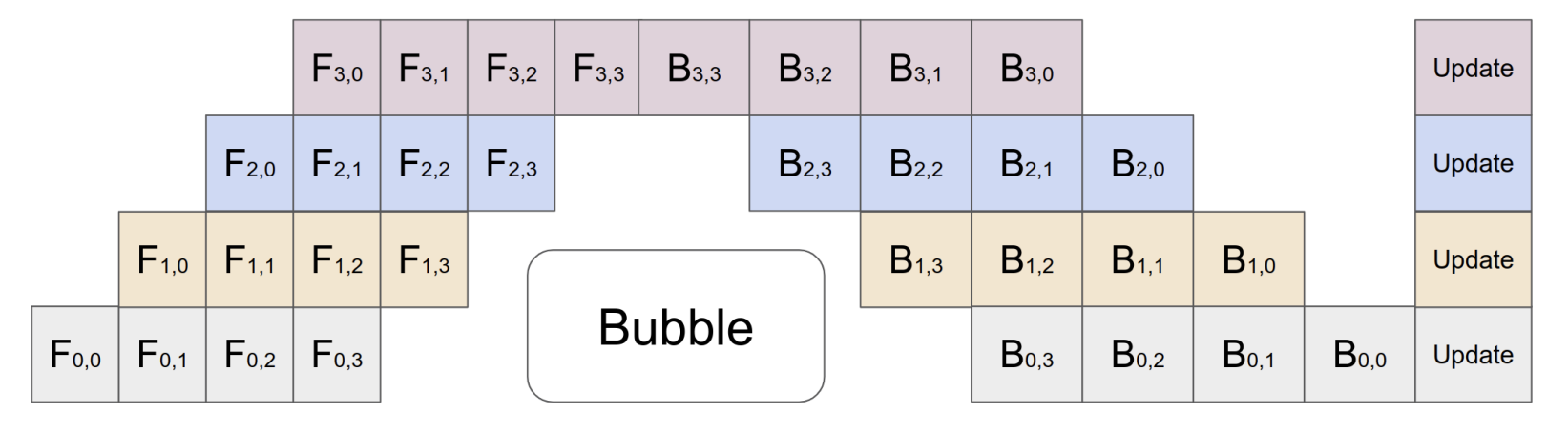
流水线并行训练的一个缺点是会出现一些空闲时间,导致计算资源的浪费。如下图的 bubble:
Sequence Parallelism
序列并行是一种沿着序列维度进行分割的并行策略,可以解决长文本序列的训练问题。成熟的序列并行方法包括 Megatron 的序列并行、DeepSpeed-Ulysses 的序列并行和环形注意力的序列并行。
Megatron SP
Megatron SP 是建立在张量并行的基础上实现的。对于无法利用张量并行的部分,例如 LayerNorm 等非线性操作,样本数据可以沿着序列维度分割成多个部分,每个 GPU 计算一部分数据。然后,对于像注意力和 MLP 这样的线性部分,使用张量并行。
DeepSpeed-Ulysses
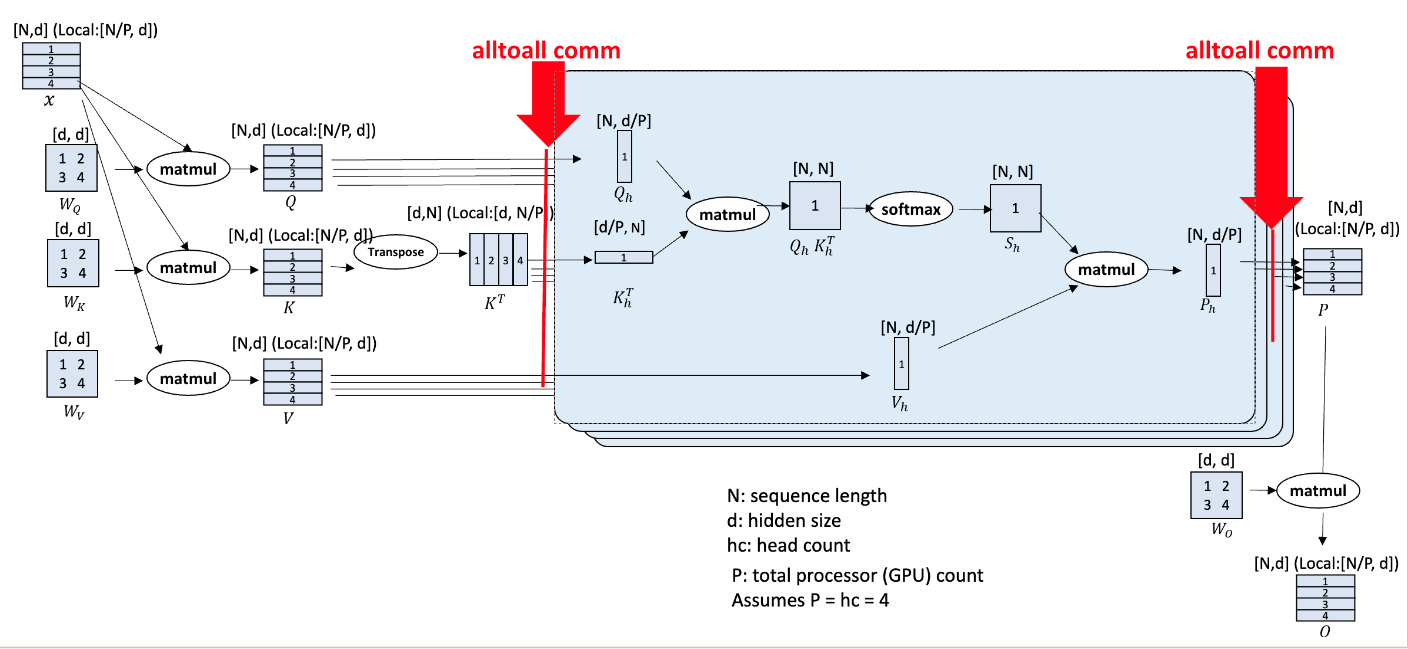
输入序列 N 分区到 P 个可用设备上。每个本地的 N/P 分区被投影到查询(Q)、键(K)和值(V)的嵌入中。接下来,通过 all-to-all 操作,将(QKV)嵌入收集到全局的 QKV 中进行注意力计算。之后,另一个 all-to-all 操作将注意力计算的输出张量转换为序列(N/P)并行,以供 transformer 层块的其余模块中的后续运算符(MLP MatMul、层归一化等)使用。
Ring Attention
Ring Attention 在概念上类似于 Flash Attention。每个 GPU 只计算局部注意力,最后将注意力块进行合并以计算总的注意力。在 Ring Attention 中,输入序列沿着序列维度被分割成多个块,每个块由不同的 GPU 或处理器处理。环形注意力采用了一种称为“环形通信”的策略,其中 kv 子块通过 p2p 在 GPU 之间传递,用于迭代计算,从而实现对超长文本的多 GPU 训练。在这种策略中,每个处理器只与其前任和后继交换信息,形成一个环形网络。这样可以在不进行全局同步的情况下,高效地在处理器之间传输中间结果,减少通信开销。
Data Parallelism + Pipeline Parallelism
下图演示了如何将 DP 与PP 结合使用(引用自 DeepSeed):
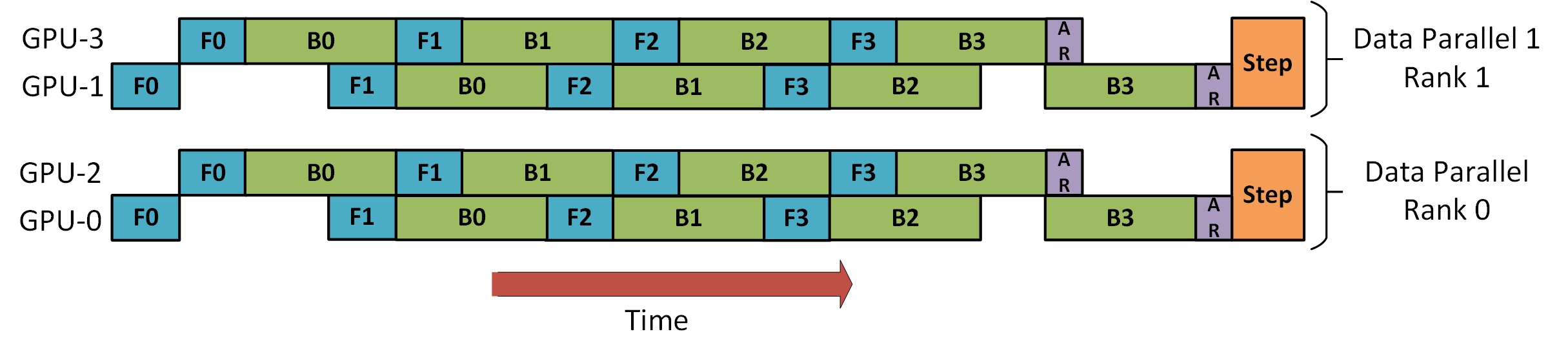
GPU 0 和 2 被组织成一个 pipeline,它们将交替进行前向(F)和后向(B)传递。然后对应的与 GPU 1 和 3 分别进行梯度的 all-reduce。最后更新模型权重。对于 DP 来说,只有 GPU 0 和 1 参与,它们将数据分配给这两个 GPU,就好像只有两个 GPU一样。GPU 0 通过 PP “秘密地”将部分负载转移到GPU 2上。同样,GPU 1通过将GPU 3纳入其帮助中来完成相同的操作。
Data Parallelism + Pipeline Parallelism + Tensor Parallelism
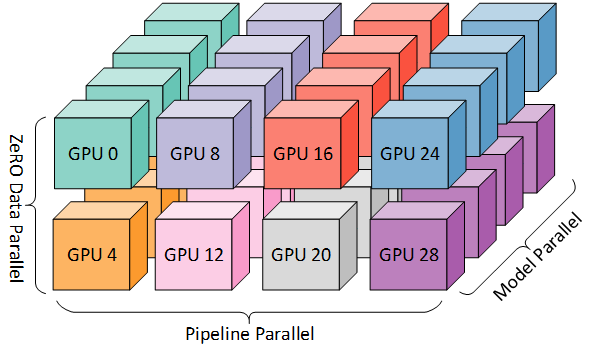
具体可以参考 3D parallelism: Scaling to trillion-parameter models。