幻觉检测是确定 LLM 的输出是否得到了输入的支持的任务。通常有两种方法来进行幻觉检测:
- 构建一个专用的模型/函数
- 使用 LLM 作为评判器
第一种比第二种更便宜,延迟更低,因为专用模型通常比 LLM 小得多。
Vectara’s HHEM
Vectara 的 HHEM 是专门用于捕捉幻觉的判别模型。给定一对文本,HHEM 会生成一个介于 0 和 1 之间的分数。分数越高,LLM 的输出与其输入在事实上的一致性就越高。
FACTS Grounding
为了准确评估 LLM 的事实性和基准,FACTS Grounding 数据集包含 1,719 个示例,每个示例都经过精心设计,需要基于提供的上下文文档提供长篇回答。每个示例包括一个文档,一个系统指令,要求 LLM 仅参考提供的文档和一个用户请求,示例如下:
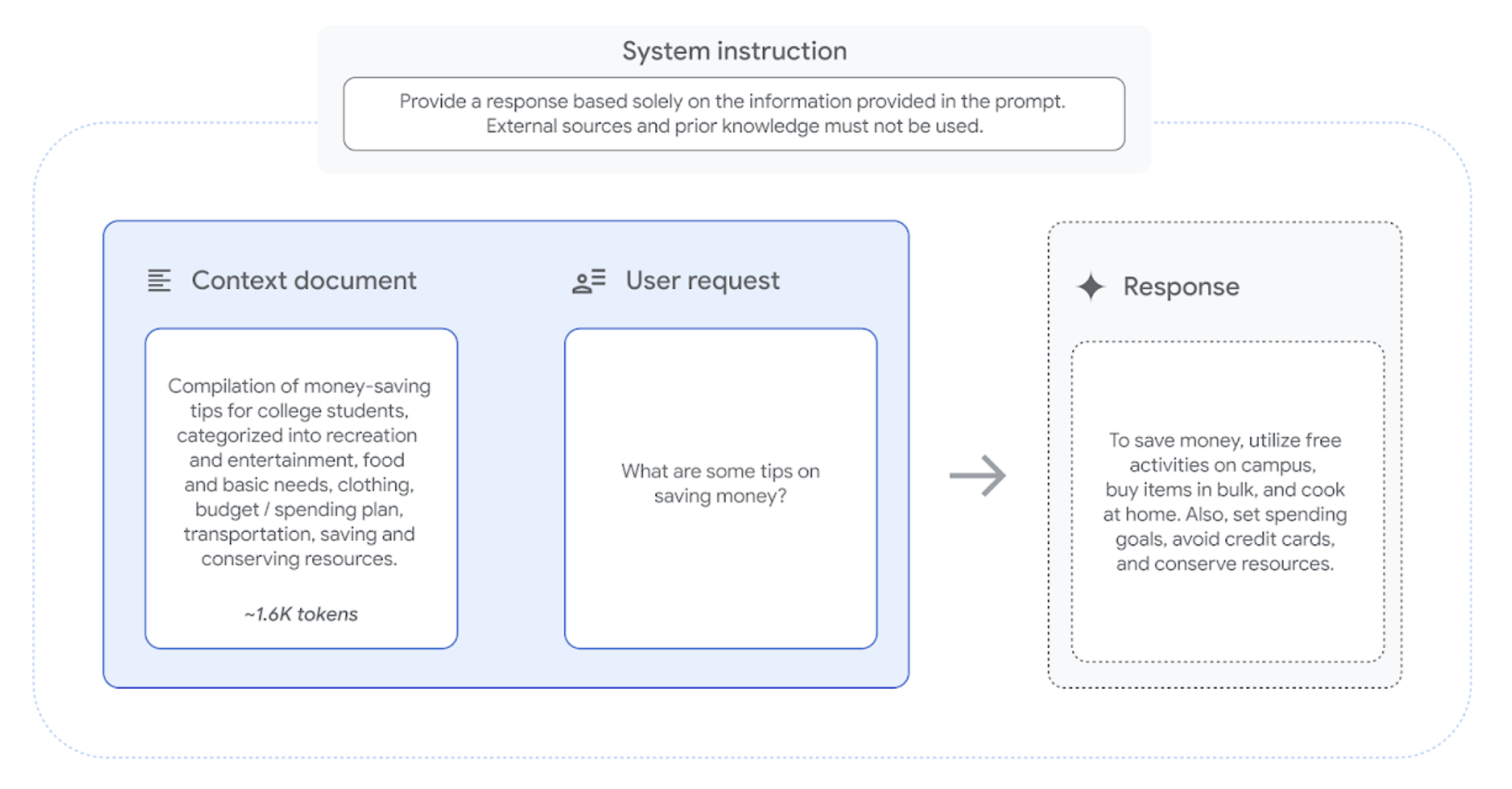
为了确保输入的多样性,FACTS Grounding 的示例包括长度各异的文档,最多达到 32,000 个token(大约 20,000 个单词),涵盖金融、技术、零售、医学和法律等领域。用户请求也同样广泛,包括摘要、问答生成和重写任务等。我们没有包含可能需要创造力、数学或复杂推理的示例,这些能力可能需要模型除了基准测试之外还要应用更高级的推理能力。
为了在给定的示例上成功,LLM 必须综合文档中的复杂信息,并生成一个长篇回答,既是对用户请求的全面回答,又完全归因于该文档。FACTS Grounding 使用三个前沿的 LLM 评判器(即 Gemini 1.5 Pro、GPT-4o 和 Claude 3.5 Sonnet)自动评估模型的回答。我们选择了不同评判器的组合,以减轻评判器对其自身模型系列产生更高分数的潜在偏见。自动评判器模型经过全面评估,与保留的测试集进行比对,以找到表现最佳的评判提示模板,并验证与人工评分者的一致性。
每个 FACTS Grounding 示例经过两个阶段的评判。首先,回答被评估是否合格,如果回答没有充分回应用户的请求,将被取消资格。其次,回答被评判是否在提供的文档中完全基于信息,并且没有幻觉,以确保事实准确性。
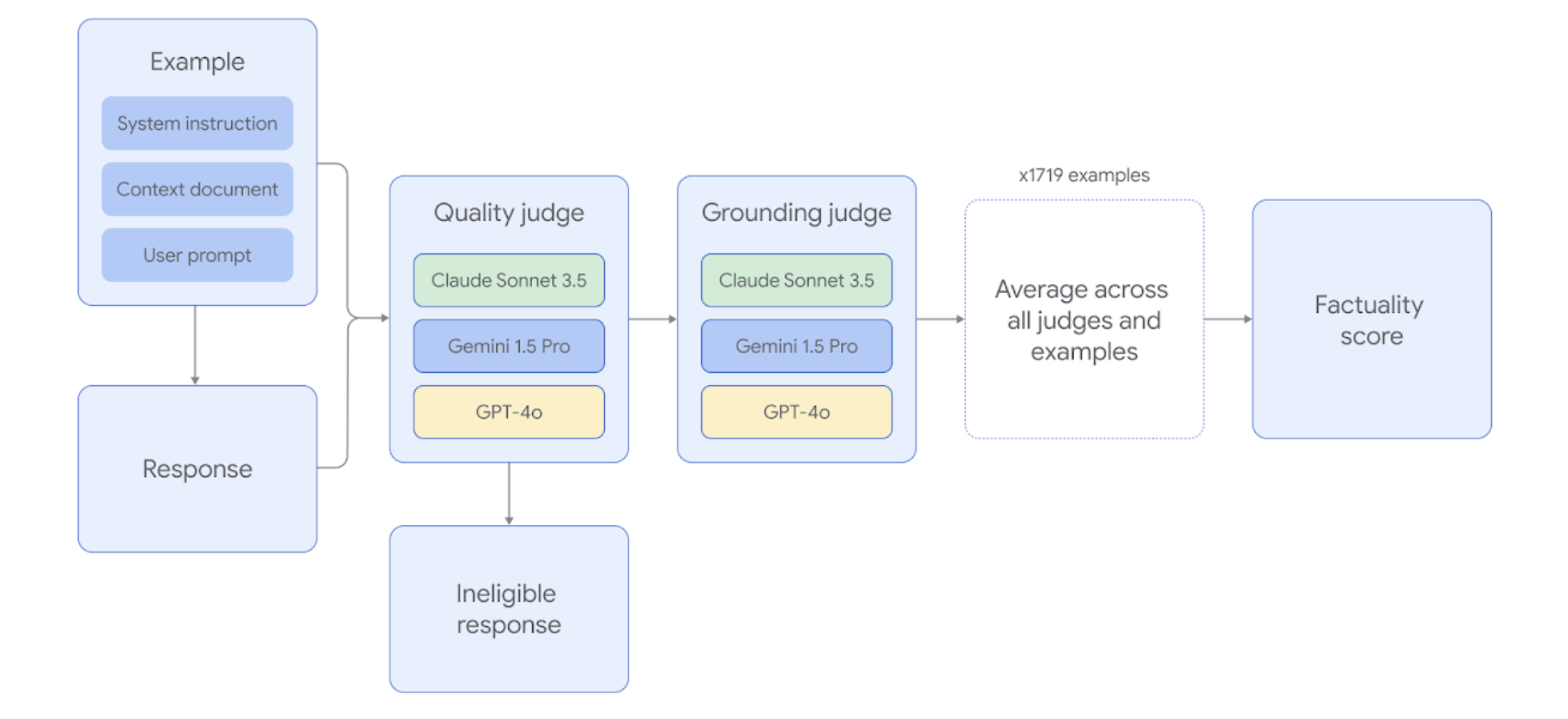
通过多个 AI 评判模型分别评估给定 LLM 回答的合格性和基准准确性,然后将结果汇总,以确定 LLM 是否成功处理了示例。整体基准测试任务的最终得分是所有评判模型在所有示例上得分的平均值。
参考阅读
- DeepSeek-R1 hallucinates more than DeepSeek-V3
- HHEM v2: A New and Improved Factual Consistency Scoring Model
- Understanding Factual Errors in Summarization: Errors, Summarizers, Datasets, Error Detectors
- RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
- The FACTS Grounding Leaderboard: Benchmarking LLMs’ Ability to Ground Responses to Long-Form Input