在推理过程中,标准的 LLM 模型使用它们预训练的模式来识别输入,并基于概率生成最有可能的输出。这个过程利用算力来分析预训练时学到的知识。较低版本的 LLM 模型不会根据输入的复杂性进行调整,无论查询是简单的,比如“英国的首都是什么?”还是复杂的,比如“解释气候变化的经济影响”,都将使用相同的计算量。这种静态的方式在处理简单任务时效果良好,但在处理需要多步推理和细致回答的查询时存在困难。
标准的 LLM 模型没有“停下来思考”的能力,不会为解决复杂问题而分配额外的计算,而是纯粹基于训练期间识别到的模式来回答问题。测试时间计算(test-time compute)是为解决这个限制而设计的概念。这个机制允许模型在处理复杂问题时使用额外的计算能力,使模型能够根据任务的复杂性动态调整使用的计算能力。这种动态性使模型能够进行迭代过程,并在面对复杂的多步问题时分配更多资源。
测试时间计算是指在模型经过训练后生成响应或执行任务时所使用的计算能力。是模型在实际使用时(而不是训练时)所需的处理能力和时间。OpenAI 的 o1 系列,会在推理过程中动态增加推理时间。这意味着模型可以花更多时间思考复杂的问题,以提高准确性,但计算资源的使用也会增加。
OpenAI o1
如 《Learning to reason with LLMs》中提到,通过大规模强化学习算法结合高效的数据训练过程,教会模型如何通过思维链条进行有效思考。OpenAI 发现,随着强化学习训练时间计算(train-time compute)和思考时间(测试时间计算 test-time compute)的增长,o1 的性能持续提高。
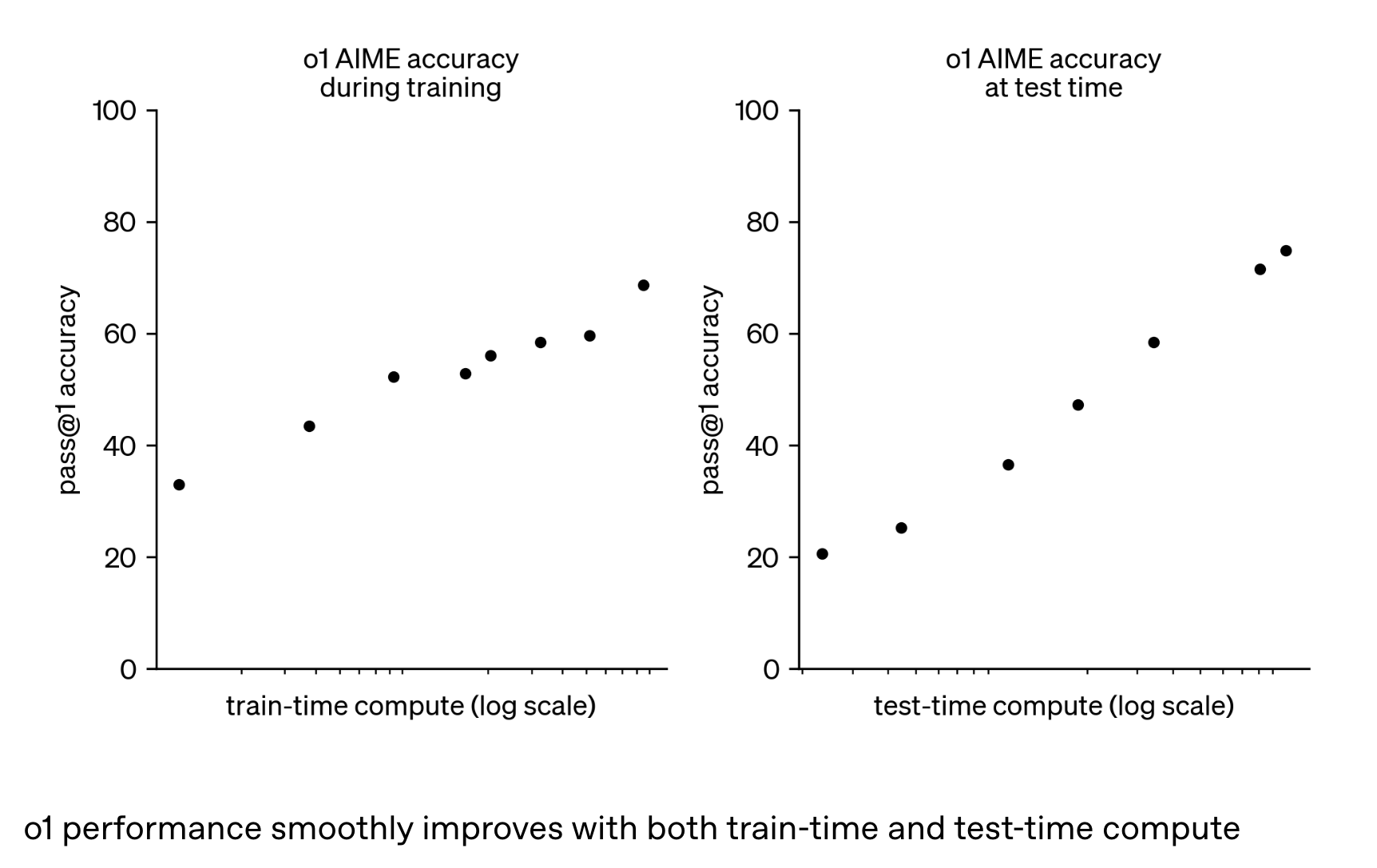
类似于人类在回答困难问题之前可能会思考很长时间,o1 在尝试解决问题时也使用了思维链。通过强化学习,o1 学会了优化自己的思考链条并改进所使用的策略。
DeepSeek
o1 模型是一个闭源的模型,而 DeepSeek 的 DeepSeek-R1 展示了基于 RL 来扩展测试时间计算的方法。DeepSeek 在以下三个关键领域进行了探索:
- DeepSeek-R1-Zero:仅使用 RL 进行训练的模型,没有使用任何预先标注的数据,使用奖励模型引导模型进行思考。
- DeepSeek-R1:应用 RL 之前,先使用小部分 CoT 数据进行微调
- Distillation:将 DeepSeek-R1 的推理技能蒸馏到较小的模型中
具体可以阅读论文 《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》