本文是《Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs》的笔记。
LLMs 在其预训练权重中包含了大量的事实信息,这可以通过它们在不同领域回答各种问题的能力得到证明。然而,这种知识本质上是有限的,严重依赖于训练数据的特征。因此,使用外部数据集来整合新信息或改进 LLMs 对先前已见信息的能力是一个重大挑战。在这项研究中,我们比较了两种常见的方法:无监督微调和 RAG。我们在不同主题的各种知识密集型任务上评估了这两种方法。我们的研究结果显示,虽然无监督微调提供了一些改进,但 RAG 在现有知识和全新知识方面始终表现优于它。此外,我们发现 LLMs 在无监督微调中难以学习新的事实信息,并且在训练过程中让它们接触到同一事实的多种变体可能有助于缓解这个问题。
Introduction
在这项工作中,我们专注于评估模型的知识以及其记忆、理解和检索事实数据的能力。我们的目标是理解知识注入的概念。以文本语料库的形式给定知识库的情况下,教授预训练模型这些知识的最佳方式是什么?
一种向预训练模型添加知识的方法是通过微调。通过微调,我们继续模型的训练过程,并使用特定任务的数据对其进行调整。通过让模型接触特定的知识库,我们期望模型的权重相应地进行调整。这个过程旨在优化模型以适用于特定的应用领域,提高其在专业领域中的性能和上下文相关性。
另一种增强模型知识库的方式是通过使用上下文学习(In Context Learning,ICL)。ICL 的主要思想是通过修改模型的输入查询而不直接改变模型的权重,从而提高预训练 LLMs 在新任务上的性能。ICL 的一种形式是 RAG,RAG 使用信息检索技术使 LLMs 能够从知识源中获取相关信息并将其融入生成的文本中。
Background
为了评估知识注入,我们首先必须了解对于 LLMs 来说知识意味着什么。知识和语言模型定义知识是一项复杂的哲学任务,然而我们可以在语言模型的背景下探讨事实性知识的含义。如果一个模型知道一个事实,它可以准确而一致地回答与之相关的问题。此外,它可以可靠地区分与该事实相关的真假陈述。然后,我们可以将这个定义扩展到整个知识库。
让 $\mathcal{Q} = \{q_n\}^N_{n=1}$ 为一组 $N$ 个多项选择的事实性问题,其中每个问题有 $L$ 个可能的答案,且只有一个正确答案。让 $\mathcal{A} = \{(a_n^1, \ldots, a_N^L)\}^N_{n=1}$ 为相应的可能答案集合,$\mathcal{C} = \{c_n\}^N_{n=1}$ 为正确答案集合。
设 $\mathcal{M}$ 为一个语言模型。我们用 $\mathcal{M}(q_n) \in \{a^1_n , \ldots, a^L_n\}$ 表示模型对第 $n$ 个问题的预测答案。
我们定义模型 $\mathcal{M}$ 相对于问题集 $\mathcal{Q}$ 的知识得分 $\mathcal{L}$ 作为标准准确率得分:
\[\mathcal{L}_{\mathcal{M}, \mathcal{Q}}:={\frac{\#\{q_{n}|\;{\mathcal{M}}(q_{n})=c_{n}\}}{N}}.\tag{1}\]我们定义如果满足以下条件,则模型 $\mathcal{M}$ 具备问题集 $\mathcal{Q}$ 的任何知识:
\[\mathcal{L}_{\mathcal{M}, \mathcal{Q}} > \frac{1}{L}.\tag{2}\]简单来说,模型能够始终给出正确答案,并且在性能上超过了简单的随机猜测 baseline,自然而然地,如果一个模型的知识得分比另一个模型更高,那么我们可以断言前者在与问题集 $\mathcal{Q}$ 相关的知识方面比后者更有知识。
考虑到现代大型语言模型的训练数据集的规模,涵盖了通过网络文本获取的大量信息。因此,注入知识的目标不一定是教给模型全新的事实,而是通过引入对特定领域的偏好来“刷新”其记忆。
导致事实错误的原因有很多。在 Wang 等人的研究中,提出了五个主要的模型层面原因的分类:
- Domain knowledge deficit 领域知识不足:语言模型可能在未接触过的特定领域缺乏全面的专业知识。例如,一个仅在威廉·莎士比亚的作品中进行训练的模型在被问及马克·吐温的作品时表现不佳。
- Outdated Information 过时信息:LLM 的训练数据集决定了其截止日期。因此,任何在最后一次训练更新之后发生的事件、发现或变化,如果没有访问外部来源,将不在模型的知识范围内。
- Immemorization:有时模型在训练过程中接触到知识,但无法保留。这对于在训练数据集中很少出现的罕见事实尤其如此。
- Forgetting:语言模型在预训练阶段之后通常会进行额外的训练(微调)。在某些情况下,这可能导致一种称为灾难性遗忘(catastrophic forgetting)的现象,即模型在微调过程之前失去了一些先前具有的知识。
- 推理失败 Reasoning Failure:在某些情况下,语言模型可能具有与事实相关的知识,但未能正确利用它。这在复杂的多步推理任务或在同一事实上提出不同问题时尤为明显,导致不一致的结果。
我们观察到这些问题大多数发生在预训练阶段,而灾难性遗忘是一个显著的例外,许多 LLM 在任何后续训练过程中都会出现这种类型的事实错误。
Injecting Knowledge to Language Models
通常的预训练对于许多知识密集型任务来说是不足够的。为了解决这个问题,需要进行额外的后处理步骤来增强预训练模型的知识。这一步骤通常被称为知识注入。在本节中,我们将研究两种广泛使用的知识注入框架:微调(fine-tuning,FT)和检索增强生成(retrieval augmented generation,RAG)。
Problem formulation
在方程(1)和(2)中,我们通过问题的视角提出了语言模型中知识的表述方式。给定一组事实性问题,存在一个包含与这些问题相关信息的文本语料库。知识注入的核心假设是,如果完全访问这个语料库,它可以作为辅助知识库,并提高模型在这组问题上的性能。数学上,假设 $\mathcal{M}$ 是一个预训练模型,$\mathcal{Q}$ 是一组事实性问题,与之前相同。现在,假设我们有一个相关的辅助知识库 $\mathcal{B}_\mathcal{Q}$。我们的目标是发现一个变换,表示为 $\mathcal{F}$,当应用 $\mathcal{F}$ 时,可以增强关于 $\mathcal{Q}$ 的知识:
\[\mathcal{M}^{\prime}:=\mathcal{F}(\mathcal{M},\mathcal{B}_{\mathcal{Q}})\quad s.t.\quad \mathcal{L}_{\mathcal{M}^{\prime}, \mathcal{Q}}> \mathcal{L}_{\mathcal{M}, \mathcal{Q}}.\tag{3}\]在这项工作中,我们的目标是比较 $\mathcal{F}$ 的两个选择:微调和 RAG,以确定哪个选项在这个问题上表现更好。
Fine-Tuning
微调是在特定的、通常是更狭窄的数据集或任务上对预训练模型进行调整,以增强其在该特定领域中的性能。在这里,区分不同类型的微调非常重要。微调技术通常被分类为有监督、无监督和强化学习(RL)方法。
Supervised Fine-Tuning
有监督微调(SFT)需要一组带有标签的输入-输出对。其中最常见的 SFT 方法之一是指令微调(instruction tuning),它已成为提高模型性能的最强大方法之一。在指导微调中,输入是一个自然语言任务描述,输出是所期望行为的示例。许多当前最先进的 LLM 在预训练阶段之后经历了指导微调。指令微调已被证明在提高模型整体质量方面非常有效,特别是在零样本和推理能力上表现突出。然而尽管具有这些优势,许多研究表明,指导微调并不一定会教会模型新的知识。因此,单独的指导微调并不是解决知识注入问题的可行解决方案。
Reinforcemnt Learning
微调的另一种形式依赖于强化学习或受强化学习启发的优化策略,以在预训练阶段之后更好地调整模型。一些著名的例子包括从人类反馈中进行强化学习(RLHF)、直接偏好优化(DPO)和近端策略优化(PPO)。这些技术已被证明非常有用,特别是与指导微调结合使用时。然而,类似于指令微调,这些方法侧重于响应的整体质量和预期行为,而不一定关注其知识的广度。
Unsupervised Fine-Tuning
我们讨论的最后一种微调策略是无监督微调,意味着模型没有可用的标签进行学习。一种常见的无监督微调技术通常被称为持续预训练(continual pre-training)或非结构化微调(unstructured FT)。在这种方法中,微调过程被视为预训练阶段的直接延续。我们从原始 LLM 的保存检查点开始,以 causal autoregressive 的方式进行训练,即预测下一个 token。与实际预训练相比,一个主要的区别是学习率。通常在继续对模型进行预训练时,需要更低的学习率,以避免灾难性遗忘。
众所周知,LLM 在预训练阶段存储了大量的知识。因此,继续这个过程以注入知识到模型中是有意义的。因此,我们在本工作中使用无监督微调方法,并评估其在增强模型学习新信息能力方面的效果。
Retrieval Augmented Generation
检索增强生成(Retrieval Augmented Generation,RAG)是一种通过使用外部知识源来扩展 LLM 在知识密集型任务中的能力的技术。虽然最初的表述涉及每个任务的额外训练,但后来已经证明,预训练的嵌入模型可以在不需要额外训练的情况下实现性能改进。这个想法是,在给定一个辅助知识库和一个输入查询的情况下,我们使用 RAG 架构来查找与输入查询相似的知识库中的文档。然后将这些文档添加到输入查询中,从而为模型提供有关查询主题的更多上下文信息。
Knowledge Base Creation
Task Selection and Rationale
MMLU Benchmark
为了正确评估 LLM 在知识密集型任务上的能力,我们从 Massively Multilingual Language Understanding Evaluation(MMLU)基准测试中选择了四个不同的任务,涉及解剖学、天文学、大学生物学、大学化学和史前史(prehistory)等主题。选择这些任务是基于它们对事实知识的重视程度以及对推理的最小依赖。作为一种启发式方法,我们选择了问题简短且不涉及上下文的任务。在实践中,我们选择了四个 STEM 学科以及一个人文学科,以确保评估不仅局限于特定领域。需要注意的是,史前史涉及了所有非现代历史的问题。这种方法旨在使我们能够测试 LLM 在不依赖其推理过程的情况下理解和处理信息的能力。
Current Events Task
为了进一步独立评估 LLM 学习新知识的能力,我们创建了一个任务,其中包括关于当前事件的多项选择题。该任务包括了在各个模型的训练数据截止日期之后发生的事件的多项选择题。具体而言,我们关注的是美国在 2023 年 8 月至 11 月期间的“当前事件”。这种方法使我们能够基本上确保模型没有接触过这些事实,从而可以直接测试知识注入的能力。
Data Collection and Preprocessing
为了有效评估 LLM 在这些知识密集型任务上的表现,我们通过从维基百科抓取每个主题的相关文章,收集了一个全面的辅助数据集。通过识别每个主题的相关中心页面,使用维基百科 API 获取所有与任务相关的文章。
随后,我们使用“ wikiextractor” 工具(Attardi,2015)进行了严格的数据清理过程,将原始的子段转换为干净的块。将数据分割成小的、干净的块(例如去除 HTML、URL 等)旨在增强对 LLM 在各种知识领域的理解的评估,并帮助 LLM 进行微调过程。
Current Events Task Creation
在从维基百科收集到相关的块之后,我们借助 GPT-4 创建了一个新的多项选择题数据集。首先,我们删除了任何小的块。对于语料库中剩下的每个块,我们通过 GPT-4 创建四个高度具体、高质量的多项选择题,其中只有一个正确答案。这里的问题需要能够在不知道问题所指的上下文的情况下回答,并且具有最小的歧义。接下来,我们要求 GPT-4 从这四个中选择两个最具体的选择题,然后进行手动评估和验证。这总共产生了 910 个新问题。
Paraphrases Generation
在创建数据集之后,我们利用 GPT-4 生成了数据集的增强版本。我们指示 GPT-4 提供输入数据的改写版本,务必完全保留信息但采用不同的措辞表达。为了确保多样性,每个改写迭代都使用了不同的种子。
我们为每个任务随机选择 240 个块,每个块创建了两个改写版本,这些被预留出来用做超参数调整的验证集。对于“当前事件”数据集,我们为每个块创建了十个改写版本用于微调。
Experiments and Results
Experimental Framework
我们使用了流行的 LMEvaluation-Harness 存储库来评估 LLM 在选定的知识密集型任务上的性能。LM-Evaluation-Harness 是一个强大的基准测试工具,目前被视为模型评估的行业标准,并是 HuggingFace 排行榜的基础。利用这个平台可以确保标准化的评估框架,并允许在模型、方法和数据集之间进行一致的比较。更重要的是,通过使用行业标准进行评估,我们可以避免由于提示工程和格式问题而产生的任何差异,并复制每个模型报告的基准结果。
Model Selection
我们选择了三个模型进行推理评估:Llama2-7B、Mistral-7B 和 Orca2-7B。选择这些模型是为了代表最受欢迎的开源基础模型和在各种基准能力上进行指导调整的模型。此外,我们选择了 bge-large-en 作为 RAG 组件的嵌入模型,并使用 FAISS 作为其向量存储。根据 HuggingFace MTEB 排行榜,这个嵌入模型目前是开源嵌入模型的最先进技术。
Configuration Variations
我们的评估包括多个配置,并对它们进行了网格搜索,以进行更全面的基准测试。首先,我们比较了基准模型和经过微调的模型以及它们在 RAG 组件下的性能。其次,我们探索了在 RAG 中添加到上下文中的文本块的最佳数量。具体而言,我们使用不同的 K 值 $K \in \{0, …, 5\}$ 来分析对模型性能的影响。最后,我们探索了 5-shot 性能与 0-shot 性能之间的差异。
Training Setup
我们使用无监督训练过程来训练所有模型。对于每个数据集,我们通过连接或分割原始块来将辅助知识库分成大小为 256 的块。我们还添加了两个特殊的标记 $<BOS>$ 和 $<EOS>$ 用于标记原始块的开头和结尾,以保留文档的结构。
模型的训练使用了学习率在 $1 × 10^{-6}$ 和 $5 × 10^{-5}$ 之间,这些学习率是通过超参数搜索找到的。所有模型在 4 个 NVIDIA A-100 GPU 上进行训练,最多进行 5 个 epoch,batch size 为 64。
Evaluation method
所有评估都是通过将每个多项选择选项附加到问题上,然后传递给模型,以获取每个选项的对数概率分数来进行的。最高分数被解释为模型的选择,用于准确性计算。
MMLU Results
对于每个任务和模型,我们比较了四种方法:仅使用基础模型、RAG、FT 以及将 FT 和 RAG 结合(使用经过微调的模型作为生成器)。此外,我们使用 0-shot 和 5-shot 的情况下测试了 MMLU 任务。
测试结果表明,在所有情况下,RAG 相对于基础模型表现出显著的改进。此外,使用 RAG 并将基础模型作为生成器的方法始终优于仅进行微调。在某些情况下,使用经过微调的模型而不是基础模型结合 RAG 进一步改善了结果。这种不一致展示了微调固有的不稳定性。
此外,我们发现在大多数情况下,5-shot 方法在一定程度上提高了结果。
Current Events Results
当前事件任务的评估结果如下图所示:

由于问题与辅助数据集之间存在一对一的对应关系,RAG 特别有效。微调与 RAG 相比不具有竞争力。不过使用多个改写版本进行微调相对于基准模型也有显著的改进。我们注意到将 RAG 与微调相结合的性能不如单独使用 RAG。
Fine-Tuning vs. RAG
在 MMLU 和当前事件任务的结果中,RAG 相对于微调具有明显的优势。虽然微调在大多数情况下改善了与基准模型相比的结果,但与 RAG 方法相比并不具有竞争力。
这种行为可能有几个因素的影响。首先,RAG 不仅向模型添加知识,还将与问题相关的上下文融入其中,而这是微调所缺乏的特征。此外,微调可能会对模型的其他能力产生影响,因为它可能会导致灾难性遗忘的程度。最后有理由相信,无监督微调的模型可能会通过监督或基于强化学习的微调获得进一步的对齐改进,这一点可以从 Orca2 相较于基础 Llama2 的显著性能提升中得到证明
The Importance of Repetition
与其他任务不同,模型在预训练过程中已经接触到与主题相关的方面,而当前事件任务涉及新信息。在这种情况下,标准的常规微调不仅没有改善 Llama2 的性能,而且还显著降低了性能。为了改善微调结果,我们尝试了使用改写来增强数据。
Data Augmentation
数据增强是一种提高语言模型性能的成熟方法。以下是我们使用 GPT-4 生成改写的 prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
Your task is to paraphrase a text paragraph. The paragraph is given below.
Make sure to keep the same meaning but change the wording. Do not change any factual information.
Try to keep roughly the same length of the original text.
Give {NUM_PARAPHRASES} different paraphrases for each text.
These paraphrases should be as different from each other as possible.
Return a JSON formatted string with one key, called ’paraphrases’, and a list of paraphrases.
Input paragraph:
Below are some examples. First, an example taken from the following Wikipedia page: ”51st International Emmy Awards”.
Paraphrase I
The fifty-first edition of the International Emmy Awards Competition accepted submissions across all categories
from December 7, 2022, until the closing date of February 16, 2023.
Paraphrase II
The International Emmy Awards Competition, now in its 51st year, accepted submissions across all categories
starting from December 7, 2022, until the deadline on February 16, 2023.
Paraphrase III
The fifty-first edition of the International Emmy Awards Competition accepted submissions across all categories
from December 7, 2022, until the closing date of February 16, 2023.
The next example was taken from the following Wikipedia page: ”2023 Indianapolis mayoral election”.
Paraphrase I
The mayoral election in Indianapolis took place on November 7, 2023, with preliminary elections
occurring on May 2. The sitting mayor, Democrat Joe Hogsett, successfully ran for a third term. Both Hogsett and
his Republican opponent, Jefferson Shreve, moved on to the main election.
Paraphrase II
On November 7, 2023, citizens of Indianapolis cast their votes to elect their Mayor, following
primary elections on May 2. Joe Hogsett, the Democrat already in office, won his bid for a third term. Hogsett
and the Republican candidate, Jefferson Shreve, were the two contenders in the final electoral round.
Paraphrase III
The mayoral election in Indianapolis took place on the 7th of November, 2023, following primary elections that
occurred on the 2nd of May. Joe Hogsett, the incumbent Democrat, successfully ran for a third term. Both Hogsett
and his Republican challenger, Jefferson Shreve, made it through to the final round of the election.
这种方法显著改善了我们的结果,如下图所示:
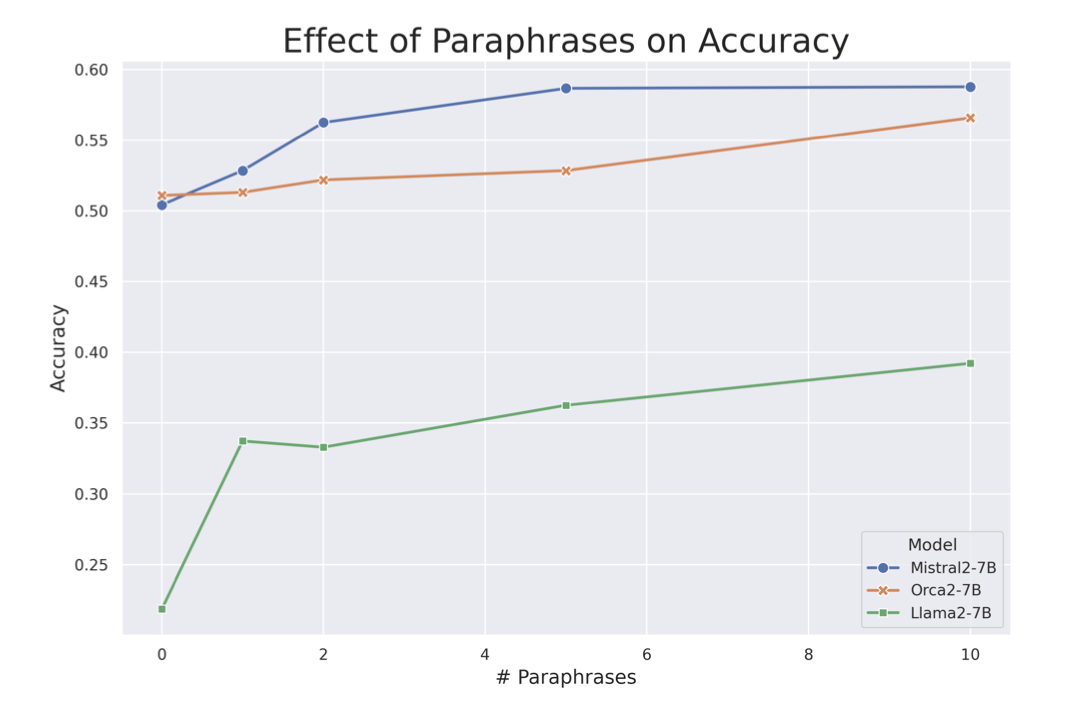
测试的所有模型,准确率都是所使用的改写数量的单调递增函数。这个观察结果强烈表明,改写增强带来的信息重复对模型从有限数据中理解和泛化新知识的能力有积极影响。
在下图中,我们可以看到一个有趣的现象,这个现象在我们的实验中一直存在:
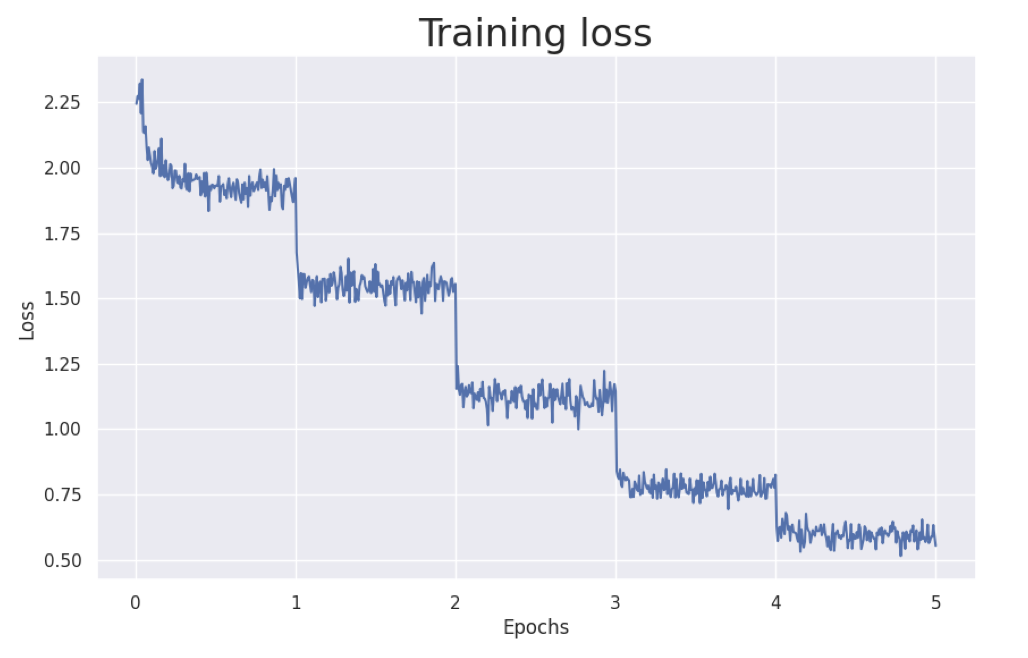
在每个 epoch 之后,也就是完成对整个数据集的一次迭代后,训练损失显著下降。这与我们对 LLM 在训练过程中记忆数据并过度拟合的已知情况一致。我们的假设如下:
为了向预训练的 LLM 教授新知识,这些知识必须以多种方式进行重复。
这对于 LLM 的预训练是众所周知的(Kandpal 等,2023),我们发现这也适用于微调。这个假设的理由是,仅仅记忆句子并不意味着对其内容的了解,这已经在(Berglund等,2023)中得到证明。通过以多种形式提供信息(例如我们使用的数据增强过程),数据中的各种关系更有可能自然出现。我们相信这可能会在一般情况下提升 $\mathcal{L}_{\mathcal{M}, \mathcal{Q}}$,并改善 Berglund 等人提到的 Reversal Curse。