本文是 《Knowledge Acquisition through Continued Pretraining is Difficult: A Case Study on r/AskHistorians》 的笔记。
像 ChatGPT 这样强大的 LLM 可以掌握各种任务,但在特定领域的限制显著,特别是在要求其复述事实(recite fact)时。这对于越来越多采用基于 LLM 的工具的知识工作者来说尤为重要。虽然有各种技术可以帮助将知识输入 LLM,例如指令调整和对齐,但大多数都有缺点。我们使用从 r/AskHistorians 中精选的知识密集型数据集来研究突出的训练技术对 LLM 的知识准确性的影响。我们评估了从 1.3B 到 7B 参数的不同模型大小以及其他因素(如 LoRA 适配器、量化、过拟合和包含 Reddit 数据在预训练中)。此外,我们还测量了语言指标和人类以及基于 LLM 的偏好。我们的结果表明,预训练和模型大小对知识准确性的影响要比持续预训练大得多,除非出现对测试知识的过拟合情况。在我们的 Reddit 数据集上进行微调会引入较简单但稍微更具有毒性的语言。我们的研究探讨了将领域特定数据集注入 LLM 中的挑战,并对从业者产生影响,例如当需要使用公司特定数据集对 LLM 进行微调时。
Introduction
有多种方法可以尝试将知识输入 LLM,但每种方法都有其缺点:无监督预训练使 LLM 能够学习大量的知识,但缺乏长尾细节(参考阅读 1);监督微调(SFT,或指令微调)可用于在学习新任务时向模型介绍新知识,但特定领域的事实似乎无法“保留”(参考阅读 1),而没有原始训练数据的微调可能导致灾难性遗忘(参考阅读 2 和 3);使用诸如人类反馈强化学习(RLHF)或直接偏好优化(DPO)等技术进行对齐可以极大地提高生成文本的质量并引入安全机制,但由于高度细致的模型调整需要非常小的学习率,因此训练成本很高。检索增强生成(RAG)似乎是一个有前途的解决方案,避免了微调,但需要更复杂的架构设置和更多的提示和 token 来操作,导致更高的使用成本,而结果质量高度依赖于其数据库中存储的信息。
我们使用来自 r/AskHistorians 的大型数据集进行这一研究,r/AskHistorians 是 Reddit 上一个严格管理的在线社区,其中包含关于各种历史主题的问题和长篇回答,通常讨论非常具体的历史事实。由于 Reddit 用户可以对帖子和评论进行赞或踩,该数据集提供了内在的人类反馈,可以用于将 LLM 与 DPO 进行对齐。鉴于社交媒体数据集在数据质量和毒性等问题上经常面临挑战,我们特别策展一个高质量的数据集。此外,我们评估了不同模型大小(从 7B 到 1.3B 参数)、使用 LoRA 适配器和量化以及对知识数据集的过拟合的影响。我们提出了一种通过手动创建知识填充数据集来衡量模型知识准确性的方法。此外,我们进行了人类和 LLM 的评估,并考虑了更传统的自然语言处理指标,如文本复杂度、阅读时间和毒性。本研究的主要目的是展示在尝试将特定知识注入 LLM 并评估其成功时可以采取的方法。我们的代码在 Github 上公开可用。
Background
Training
根据 Touvron 等人(参考阅读 4)的概述,训练 LLM 作为聊天机器人或问答系统的完整流程通常包括以下步骤:
- 在一个大型数据集上进行无监督预训练(可能包含数万亿个 token),以帮助 LLM 识别常见的语言模式
- 在一组问题(或提示)和最佳答案上进行 SFT,以教导 LLM 特定的任务和回答方式
- 使用偏好数据集进行对齐(即,两个答案中一个被评为优于另一个),例如使用 RLHF,以微调 LLM 的回答质量,使其更好地适应人类偏好中微妙的差异
Knowledge Injection
如上所述,有各种技术可以修改 LLM 并注入知识,每种技术都有其优缺点。Kandpal 等人(2023)认为无监督预训练和 SFT 分别擅长使 LLM 学习广泛的世界知识和特定任务,但在注入特定事实和长尾知识存在困难。其他研究表明,针对特定数据进行微调可能会导致先前学习的任务遗忘,而持续学习(continual learning)的概念主张采用旨在防止这种情况发生的方法。DPO 等对齐技术是一种代价高昂的方法,通过非常小的学习率对 LLM 进行细致的对齐。此外,最近的研究表明,使用 LoRA 适配器进行训练可以减少学习和遗忘效应。检索增强生成(RAG)通常被提出作为注入知识的更好选择。然而,RAG 需要更复杂的架构设置,包括一个适当的数据库和一个与主 LLM 连接的检索模型,通过提示将相关的文本摘录提供给后者,从而增加了输入 token 的数量。这增加了使用成本,并引入了各种风险,例如插入新信息的困难,或者检索到不合适的信息片段。
Evaluation
以可扩展和可靠的方式评估 LLM 生成的文本,特别是长篇文本,仍然是一个持续存在的挑战。在评估对话调优或问答模型的生成质量时,人类的判断仍然是黄金标准。在评估 LLM 时的一个关键思想是将经过微调的 LLM 的输出与被认为是最先进或有效的基准 LLM 进行比较,例如 Touvron 等人(2023)将他们的结果与 GPT-4 和人类标注者进行比较。LLM 作为评判者的方法旨在通过调用高质量的 LLM(如 GPT-4)来自动进行评估,尽管与人类偏好存在相当的相关性,但这些方法受到各种偏见的影响,例如评判 LLM 更喜欢较长的回答或与其训练内容相似的回答。除了评估文本质量外,通常还使用各种描述性指标来衡量文本的简单属性,例如毒性、文本复杂性和阅读时间。
Methodology
我们的技术设置的概述如下图所示:
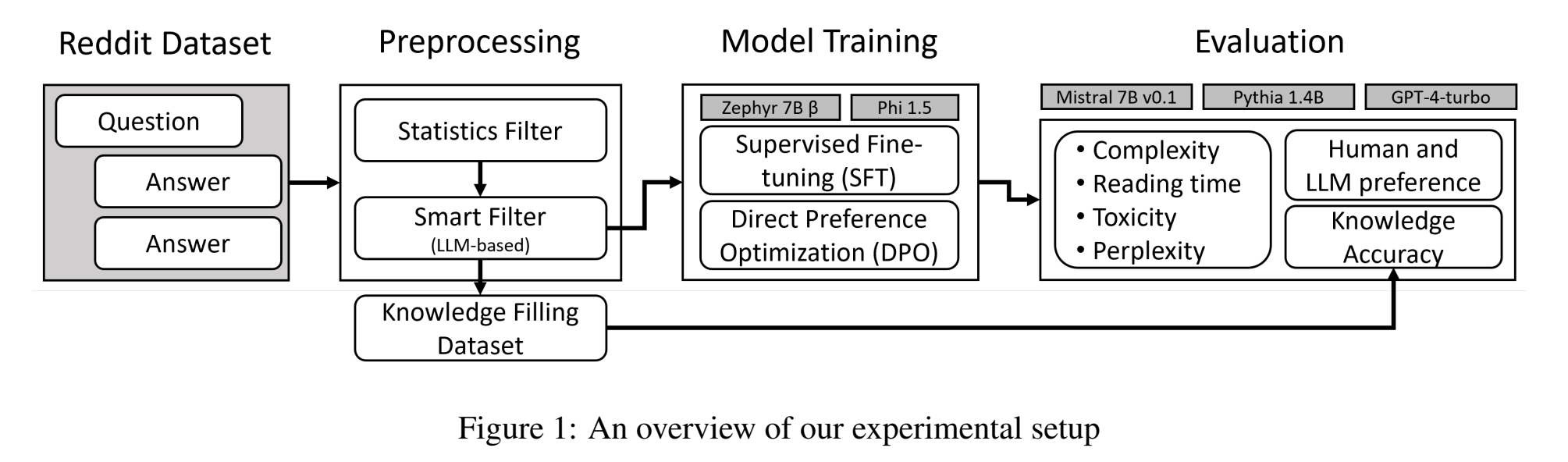
我们从原始的 r/AskHistorians 数据中处理和筛选出一个偏好数据集,使用 SFT(phi-1.5 和 zephyr-7B-beta)和 DPO(zephyr-7B-beta)对模型进行训练,并使用不同的方法进行评估,包括将 GPT-4-turbo 作为 LLM 评判者,以及将 Mistral-7B-v0.1 和 pythia-1.4B 作为基准进行比较。
Dataset
我们从 Pushshift API 中获取我们的数据集,该 API 在 2023 年中旬之前是免费可访问的,但由于对训练机器学习模型的需求增加,Reddit API 的条款发生了变化。因此,我们的数据集涵盖了从 2011 年 8 月创建 subreddit 到 2022 年底的时间段,包含大约 116,452 个问题和 384,491 个答案。为了进一步提高数据质量,我们排除了以下类型的帖子:(1)不包含问题的帖子(例如推荐或每月阅读列表),(2)长度小于 55 个字符的帖子,(3)点赞数低于 4(以便关注热门帖子),或(4)答案少于两个 top-level 的评论(我们需要构建一个偏好数据集)。
最后我们使用基准模型 zephyr-7B-beta 作为智能过滤器,为每个问题分配一个质量评级。为此,我们采用了一种 few-shot 设置,根据 subreddit 的社区准则解释了好问题的标准。我们通过对 100 个随机抽样的问题进行人工评估,确定智能过滤器与人类判断的一致率为 70%,我们认为这已经足够。最终得到了一个包含 34,631 个标记为“好”的问题和 100,429 个答案的数据集。
The r/AskHistorians Knowledge Filling Task
准确评估 LLM 在长篇回答中的事实准确性是具有挑战性的,目前还没有现有的框架可供我们用于此目的。我们创建了一个由填空程序(Taylor,1953)启发的知识填充数据集。我们重新表述数据集中的事实,提出关于特定事实的问题,并制定一个“answer start” 的 prompt,只在其末尾缺少关键事实。然后,LLM 只需使用非常有限数量的 token 来生成缺失的事实。

我们从训练数据集中随机选择 100 个样本,以确保我们的模型在 SFT 和 DPO 期间已经看到了这些数据,因为我们的目标是衡量进一步训练是否有助于注入知识。生成的问题-答案提示相对较短,平均长度为 100 个字符,而平均预期的回答长度为 9.9 个字符,这样可以进行廉价的评估。
在这里需要注意的是,这个过程对于将知识准确性的评估与语言风格分开是至关重要的。目前许多流行的评估框架,如 MTBench 和 G-Eval 会不可避免地评估语言风格。同样,困惑度指标主要衡量文本与语言风格的接近程度,而不是事实准确性。
Model Training
在我们的实验中,我们按顺序在 zephyr-7B-beta 上进行了 SFT 和 DPO,并在 phi-1.5 上进行了 SFT(该模型使用了不同的训练过程和自定义代码,因此我们不对其进行 DPO)。
为了评估知识填充数据集,我们还使用了 mistralai/Mistral-7B-v0.1 和 EleutherAI/pythia-1.4B 作为基准模型。
在与 RLHF 和 PPO 的初步实验之后(这两种方法高度依赖于奖励模型的质量),我们选择了 DPO,因为它的实现简单且更加稳健。
LoRA 微调是一种广泛使用的方法,我们使用它来高效地微调 zephyr-7B-beta 模型。然而由于微调过程中的权重更新是低秩的,这可能会抑制知识的吸收。为了缓解这个问题,我们使用 LoRA 对 zephyr-7B-beta 进行微调,但对 phi-1.5 使用 full-weight SFT。我们对 zephyr-7B-beta 和 Mistral-7B-v0.1 模型应用了 bfloat16 进行量化。
我们在 SFT 和 DPO 中使用 HuggingFace transformers Trainer,在 Nvidia A6000 48GB 或 RTX 3090 Ti 24GB GPU 上进行实验,同时确保两个系统具有相同的超参数。我们总共运行了 3 个 epoch 的监督微调和 18 个 epoch 的 DPO,并根据评估数据集上最高奖励准确率选择最佳的检查点。
为了防止 zephyr-7B-beta 忘记其生成能力,我们在 SFT 和 DPO 期间包括了模型原始微调的数据,遵循持续学习过程(参考阅读 5)。我们从 UltraChat 中随机选择样本进行 SFT,从 UltraFeedback 中选择样本进行 DPO,以便大约百分之二的训练数据来自各自的原始数据集。
Evaluation
我们的主要评估任务是使用我们手动创建的数据集进行 r/AskHistorians 知识填充任务。该任务旨在通过微调来评估知识的吸收,而不受适应新领域语言风格的干扰。我们确定答案是否正确的标准是,如果生成的答案中包含了真实答案的子字符串,则认为是正确的,并报告整个数据集的准确率。由于在某些情况下,可能有多个版本可以编写一个回答(例如,“World War II”和“WW2”),我们会进行人工验证所有结果。
除此之外,我们还衡量模型的风格适应性以及总体质量。为此,我们利用一组 NLP 指标:
- 使用我们的 r/AskHistorians 语料库训练的模型的困惑度,作为模型复制社区语言风格的指标
- 使用 textstat 包测量的文本复杂度和阅读时间,用于比较语言复杂性
- 使用在 ToxiGen 数据集上训练的 HateBERT 分类器测量的毒性
- 用人和 LLM 评估器来两种模型(baseline zephyr-7B-beta 和微调后的 zephyr-7B-beta)的偏好
Results
Knowledge Accuracy
我们的结果显示,尽管我们在 LLM 上进行的持续预训练成功地将 r/AskHistorians 的写作风格灌输到了模型中,但我们无法测量到模型知识准确性的显著提升。相反,SFT 和 DPO 不仅未能在我们的 r/AskHistorians 知识填充任务中取得任何显著改进,而且每一步微调都会略微降低知识准确性值:
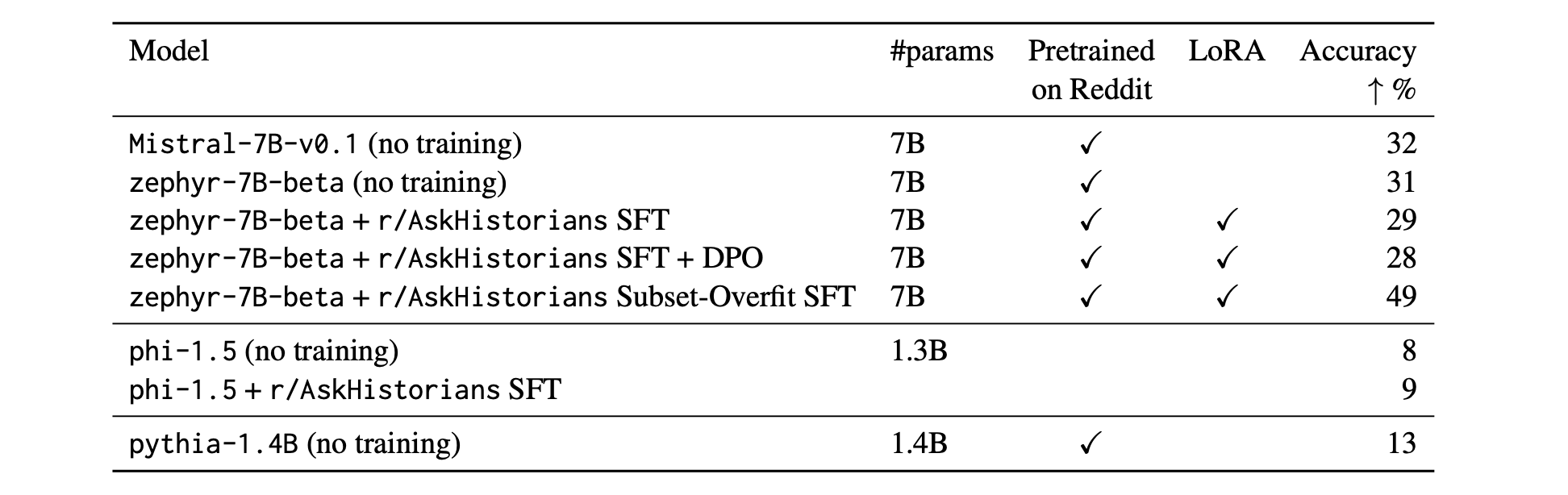
这似乎与直觉相悖,因为评估问题是从训练数据集中包含的事实派生出来的,因此在训练过程中我们的微调模型变体已经看到了这些事实。这表明仅仅在微调过程中包含事实并不能提高模型的知识准确性。
在另一个实验中,我们通过有意地过拟合我们的模型来测试通过微调实现知识吸收的上限:我们用筛选后的 r/AskHistorians 数据集中用于生成知识填充测试集的子集上对 zephyr-7B-beta 进行了 10 个 epoch 的 SFT 训练,这意味着我们没有在我们评估的确切问题-答案对上进行训练,但包含了所有的相关信息。这个实验在上述表格中被列为 r/AskHistorians Subset-Overfit SFT,得到了更高的知识准确性,达到了 49%。虽然这表明知识最终可以通过微调吸收,但经过 10 个 epoch 后的准确性仍远远低于理想的 90-100%。
我们使用 zephyr-7B-beta 的负面结果可能是由于 LoRA 的低秩特性阻碍了知识的捕捉。因此,我们进行了一项额外的实验,使用 phi-1.5 作为我们的基础模型进行 full-weight SFT。由于 phi-1.5 没有在任何 Reddit 数据上进行预训练,该模型的知识准确性得分较低,为 8%。相比之下,作为在 Reddit 上预训练的类似规模的模型,pythia-1.4B 的知识准确性得分为 13%,这表明这种预训练具有积极的效果。然而,对我们筛选后的 r/AskHistorians 数据集进行 full-weight SFT 仍然没有显著提高知识准确性,最终得分为 9%(而基准模型为 8%)。我们得出结论,微调无法将知识注入到 LLM 中(与预训练的有限成功相比),而 LoRA 似乎不是这种失败的根本原因。
Stylistic Adaptation and General Quality
对 LLM 生成的长篇文本的评估通常考虑将写作风格和总体质量作为评估标准之一,因为衡量特定方面(如知识准确性)是具有挑战性的。因此为了进行更全面的评估,我们还分析与这些方面相关的指标。
NLP metrics

以上表格显示,微调模型的训练困惑度在训练数据集上有所改善,这表明尽管知识吸收失败了,但模型学习到了数据集的语言风格。
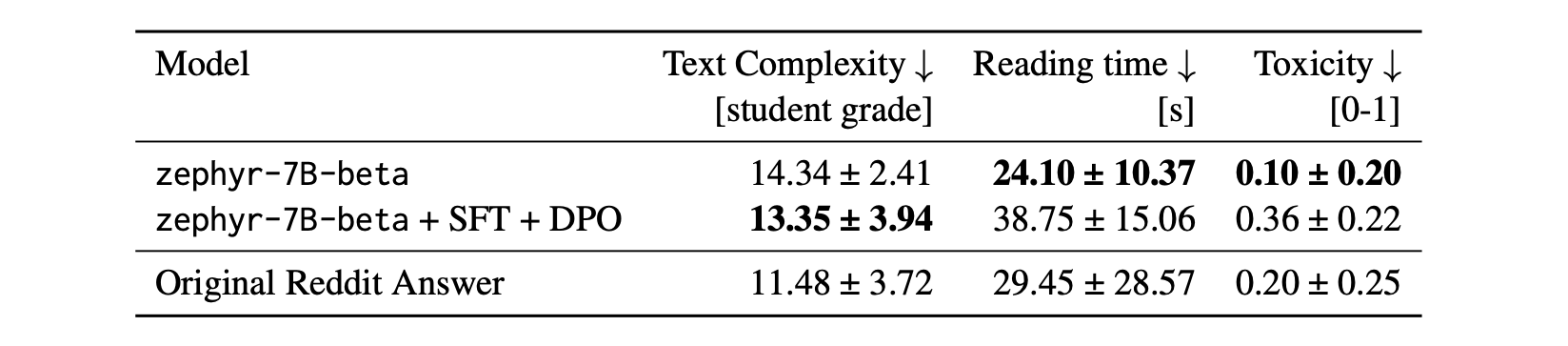
以上表格中列出的其他指标表明,在微调后,zephyr-7B-beta 生成的文本阅读时间更长(即阅读时间更高),毒性得分更高,但同时文本复杂度得分较低(由于句子和词汇更简单)。值得注意的是,模型训练使阅读时间和毒性的变化程度比原始 Reddit 答案中更强,这表明在微调过程中,模型可能会“超调(overshooting)”,可能是由于 r/AskHistorians 数据集与模型的原始训练数据具有不同的特性。
Pairwise comparison
使用人类和 LLM 评判者进行的成对比较评估,结果显示微调后的 zephyr-7B-beta 被评为比基准模型更差。此外,我们使用 GPT-4 来判断原始人类编写的答案和基准模型 zephyr-7B-beta 之间的优劣:在 54 个案例中,原始答案更受青睐,而在 46 个案例中,Zephyr 获胜。这与微调模型的结果形成对比,并显示出微调过程或 zephyr-7B-beta 无法充分捕捉到微调模型中原始 Reddit 答案的总体质量。
根据我们对随机样本进行的手动定性分析,我们认为这种现象与原始的 Reddit 数据缺乏结构和一致的风格有关,不同的作者有不同的写作偏好,这使得模型更难学习到一个连贯的风格。这是与经过精心设计的数据集(如 UltraFeedback)的主要区别。我们观察到,微调模型通常会生成主观的回答,以”我认为…“或”如果我正确理解你的问题…“等表述开始,而原始的 Zephyr 模型直接回答问题,并以列举的方式提供其论点。