本文是《Large Language Models Struggle to Learn Long-Tail Knowledge》的笔记。
在这篇论文中,我们研究了 LLM 所记忆的知识和预训练数据集之间的关系。特别是,我们展示了 LLM 回答基于事实的问题的能力与在预训练期间看到的与该问题相关的文档数量之间的关联。我们通过实体链接(entity linking)预训练数据集并计算包含与给定 QA 对相同实体的文档数量来确定这些相关文档。我们的结果表明,在众多问答数据集(例如 TriviaQA)、预训练语料库(例如 ROOTS)和模型规模(例如 1760 亿参数)中,准确性与相关文档数量之间存在强烈的相关性和因果关系。此外,尽管较大的模型在学习长尾知识方面表现更好,但我们预估现今的模型必须在规模上扩大多个数量级,才能在支持较少的预训练数据中达到具有竞争力的问答性能。最后,我们展示了检索增强可以减少对相关预训练信息的依赖,这是一种捕捉长尾知识的有前景的方法。
Introduction
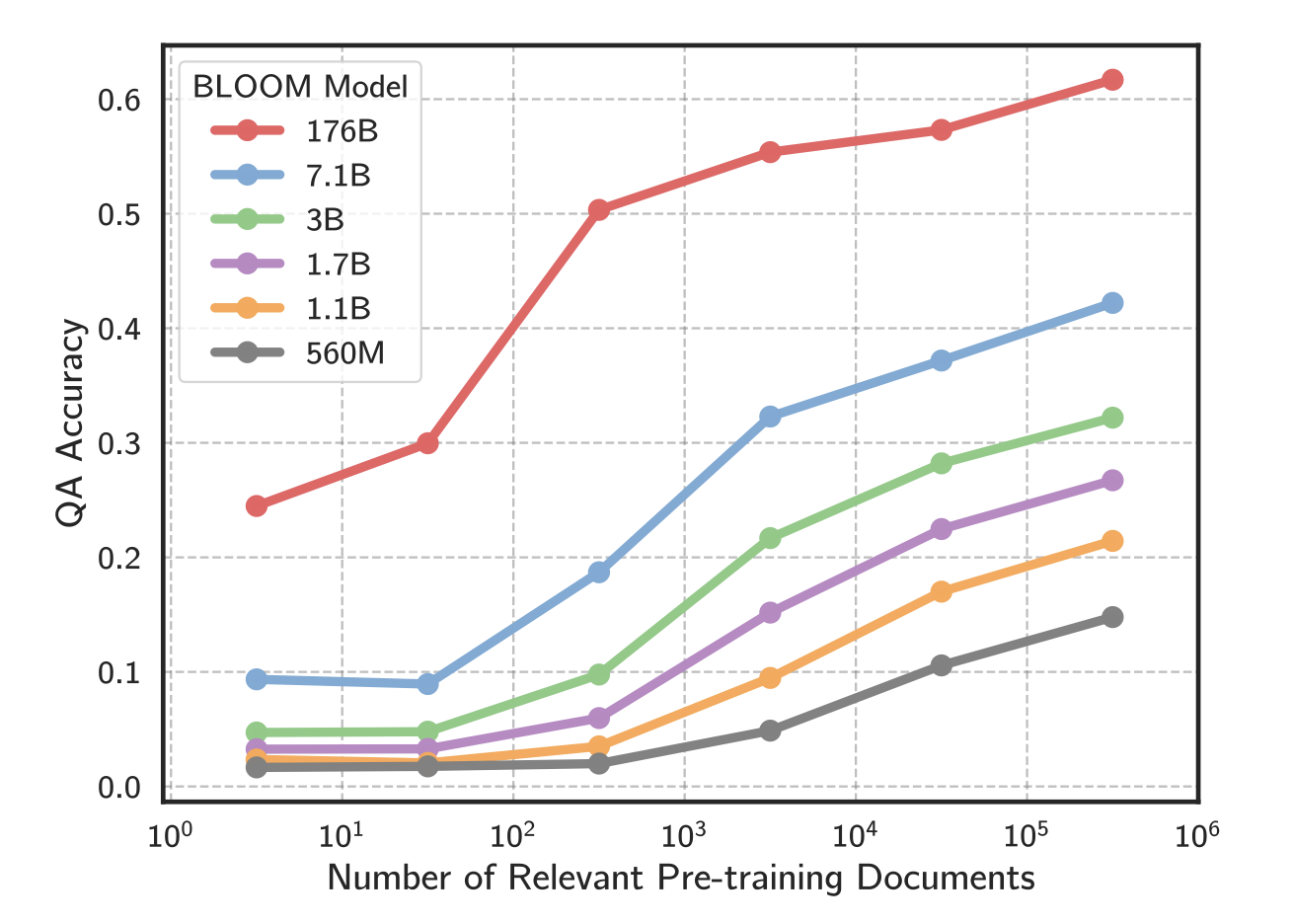
我们观察到在众多问答数据集、预训练数据集和模型规模(见下图),语言模型回答问题的能力与与该问题相关的预训练文档数量之间存在强烈的相关性。例如,当相关的预训练文档数量从 $10^1$ 增加到 $10^4$ 时,BLOOM-176B 的准确率从 25% 跃升至 55% 以上。
我们还进行了一个反事实再训练实验,其中我们在使用和不使用某些文档的情况下训练了一个拥有 48 亿参数的语言模型。当删除了与问题相关的文档时,模型的准确性显著下降,这验证了我们的实体链接流程。
最后,我们分析了更好地捕捉在预训练数据中罕见出现的知识的方法:模型扩展和检索增强。对于模型扩展,我们发现参数数量与问答准确率之间存在强烈的对数线性关系。这表明虽然扩大语言模型可以改善知识学习,但为了在长尾问题上实现有竞争力的问答准确率,模型需要进行巨大的扩展(例如,达到一千万亿个参数)。检索增强系统则更具有前景,当检索器成功找到相关文档时,它减少了语言模型对大量相关预训练文本的需求。然而,检索系统本身仍然对相关文档数量有一定的依赖性。
我们的工作是首次对 LLM 知识如何受到预训练数据影响的研究。
Identifying Relevant Pre-training Data
Background and Research Question
许多 NLP 任务都是知识密集型的,需要从知识源(如维基百科或网络)中回忆和整合事实。使用 LLM 在知识密集型任务上的结果有了显著改进,因为这些模型已被证明能够利用它们从预训练语料库中学到的大量知识。然而,LLM 实际上捕捉到了什么样的知识仍然不清楚,例如,它们是否只是学习了在预训练数据中频繁出现的“简单”事实?
我们使用封闭式问答(closed-book QA)在 LLM 少样本设置下进行研究。模型在没有任何相关背景文本的情况下,通过上下文训练示例(问答对)和一个测试问题进行提示。我们工作的目标是研究语言模型回答问题的能力与该问题相关信息在预训练数据中出现次数之间的关系。
Our Approach
关键挑战是在数百 GB 大小的预训练数据集中高效地识别与特定问答对相关的所有文档。为了解决这个问题,我们首先识别出问题及其一组真实答案别名(aliases)中包含的重要实体(salient entities)。接着,我们通过寻找这些重要的问题实体和答案实体同时出现的情况,来识别相关的预训练文档。
例如考虑问题“诗人但丁在哪个城市出生?”以及有效答案“佛罗伦萨”、“佛罗伦萨市”和“意大利”。我们提取重要的问题和答案实体,“但丁·阿利吉耶里”和“佛罗伦萨”,并计算同时包含这两个实体的文档数量。
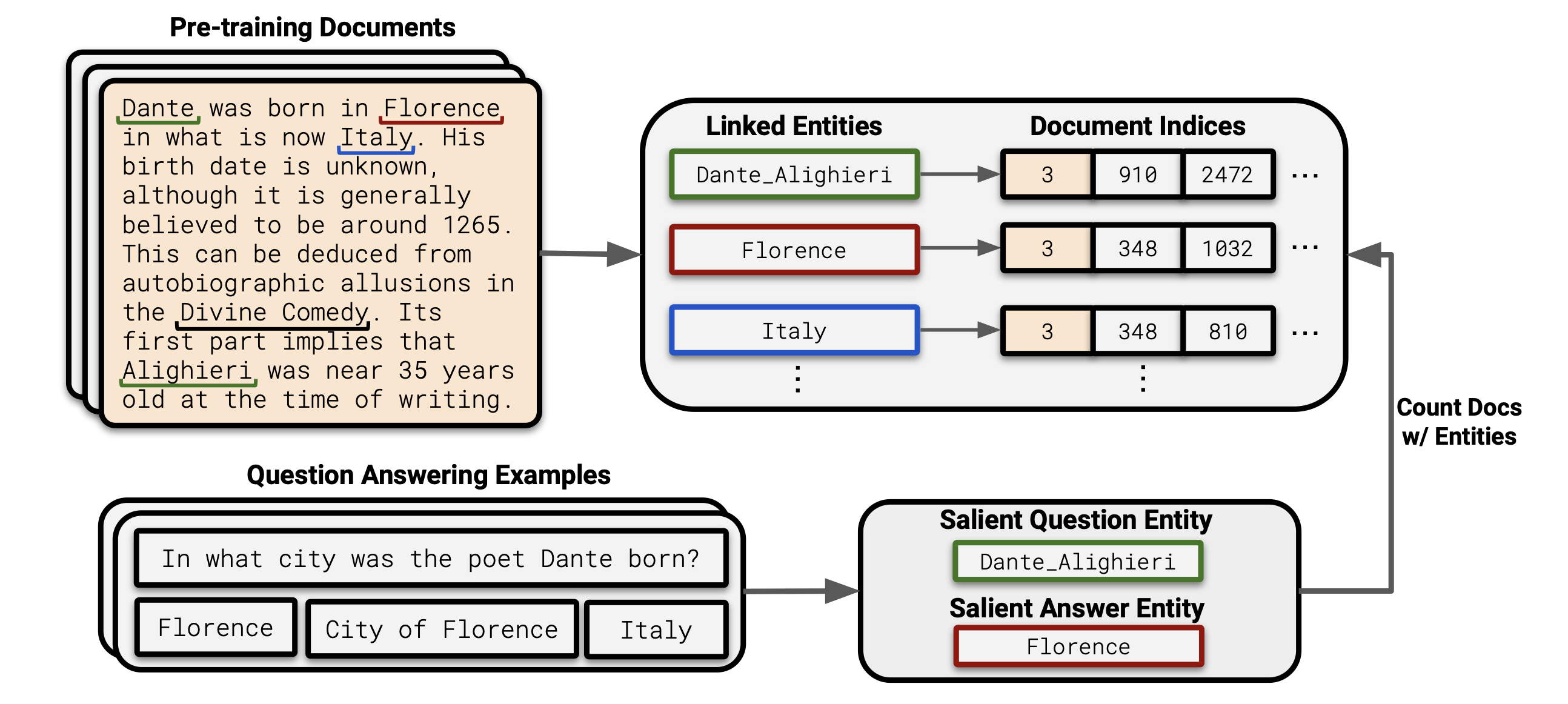
我们的方法受到 Elsahar等人(2018)的启发,他们表明当主语-宾语关系三元组中的主语和宾语在文本中共现时,通常可以推断出这个关系三元组也存在(换句话说,如果你在文本中看到某个主语和宾语同时出现,那么很可能它们之间的关系也在文本中隐含存在)。此外,我们通过训练一个没有某些相关文档的 LM,并展示了这会降低相关问题的准确率,进一步验证我们的流程。基于这些发现,我们将包含重要问题和答案实体的文档称为相关文档。
为了应用上述方法,我们必须对大规模的预训练语料库和下游的问答数据集进行实体链接。我们通过构建一个并行化的实体链接流程,然后针对下游的问答数据集进行定制来实现这一目标。
Entity Linking Pre-training Data
我们使用大规模分布式运行 DBpedia Spotlight 实体链接器来进行规模化的实体链接,该链接器使用传统的实体链接方法将实体链接到 DBpedia 或 Wikidata 的 ID 上。我们对以下预训练数据集进行实体链接,选择这些数据集是基于它们在我们考虑的 LLM 中的使用情况:
- The Pile:一个 825GB 的数据集,包含 22 个不同的主要英语来源的混合数据。
- ROOTS(En):ROOTS 语料库的 490GB 英文子集。
- C4:一个 305GB 的英文语料库,通过对 CommonCrawl 进行过滤收集而来。
- OpenWebText:一个 39GB 的英文语料库,包含 Reddit 网站上链接的网页文本。
- 维基百科:来自 Lee 等人的 2018 年 12 月维基百科文章的文本转储,这是评估开放领域问答系统的标准语料库。
对于这些预训练数据集中的每个文档,我们记录了链接的实体,并使用一种数据结构来快速计算单个实体的出现次数和实体的共现次数。
Finding Entity Pairs in QA Data
接下来,我们对两个标准的开放领域问答数据集进行实体链接:Natural Questions 和 TriviaQA。为了扩大样本大小,我们使用了训练数据和验证数据,仅保留了一小部分用于 few-shot learning prompts。
我们首先对每个样本运行 DBPedia 实体链接器。由于一个样本可能有多个注释答案,我们将问题和所有有效答案连接在一起,以便更准确地进行实体链接。我们使用在一组真实答案中出现频率最高的实体作为重要答案实体。然后,我们遍历问题中找到的所有实体,选择在预训练数据中与重要答案实体共同出现次数最多的实体。如果问题、答案或两者中都没有找到实体,我们将丢弃该样本。如果相关文档的数量为零,我们也会丢弃该样本,因为这很可能是由于实体链接错误导致的。
我们的流程并不完美,因为实体链接器有时会错误地识别实体,以及并非所有包含显著问题和答案实体的文档都是相关的。然而,当应用于大规模的预训练数据集时,这个流程是高效的,并且具有足够的准确率和召回率,可以观察到与问答性能相关的相关性和因果关系。
LM Accuracy Depends on Relevant Document Count
在这一部分,我们衡量了 LLM 回答问题的能力与预训练语料库中相关文档数量之间的关系。我们使用了跨越三个数量级的流行 Transformer decode-only LMs:GPT-Neo、BLOOM 和 GPT-3。我们使用简单的提示,由以下形式的模板组成:
1
2
3
4
5
6
7
8
Q: [上下文问题1]
A: [上下文答案1]
.
.
.
Q: [上下文问题n]
A: [上下文答案n]
Q: [测试问题]
我们通过贪婪解码生成答案,直到模型生成换行符,并使用标准的完全匹配(Exatch Match, EM)指标对答案进行评估,与真实答案集进行比较。
Correlational Analysis
所有测试的模型中,问题回答准确率与相关文档数量之间存在着很强的相关性。模型大小也是知识学习的一个重要因素:随着模型参数数量的增加,问答性能显著提高。例如,在 TriviaQA 问题中,BLOOM-176B 的准确率比 BLOOM-560M 高出 4 倍以上,而且相关文档数量超过 $10^5$。
我们使用 Natural Questions 数据集重复了这个实验,发现所有模型系列同样呈现类似的趋势。
Causal Analysis via Re-training
我们通过从训练数据中删除某些文档并重新训练 LM 来建立因果关系。我们首先在 C4 上按照 Wang 等人(2022)的设置训练一个 baseline 48 亿参数的 LM。然后,我们测量从训练集中删除某些文档的效果。对于每个相关文档数量的对数分组(例如,$10^0$ 到 $10^1$ 个相关文档,$10^1$ 到 $10^2$ 个相关文档…),我们从 Trivia QA 中随机选择 100 个问题,并删除 C4 中这些问题的所有相关文档,这大约删除了 C4 的 30%。最后,我们在这个修改后的预训练数据集上训练一个“反事实” LM,并将其性能与 baseline 模型进行比较。对于 baseline 模型和反事实模型,我们只训练一个 epoch。由于反事实模型的训练步骤减少了 30%,总体上性能稍差一些。为了解决这个问题,我们只研究那些相关文档被删除的问题的性能。
实验结果表明,对于原始 C4 数据集中相关文档较少的问题,基线模型和反事实模型的性能都较差,即它们的性能差异很小。然而,对于相关文档较多的问题,反事实模型的性能显著较差。这表明相关文档数量与问答性能之间存在因果关系。
Methods to Improve Rare Fact Learning
到目前为止,我们已经展示了 LLMs 对相关文档数量具有很强的依赖性。在这里,我们研究了减轻这种依赖性的方法:增加数据规模、增加模型规模和添加辅助检索模块。
Can We Scale Up Datasets?
一个简单的方法来提高对于关于不常见知识的问题的准确性是收集更多的数据。然而我们的结果表明,通过适度扩大数据集规模(例如,5倍)通常只会带来小幅的准确性提升,因此这种方法不会显著改善准确性。另一个想法是增加预训练数据的多样性。然而,我们认为这也只会带来很小的好处,因为许多数据源之间存在意外的相关性。
Can We Scale Up Models?
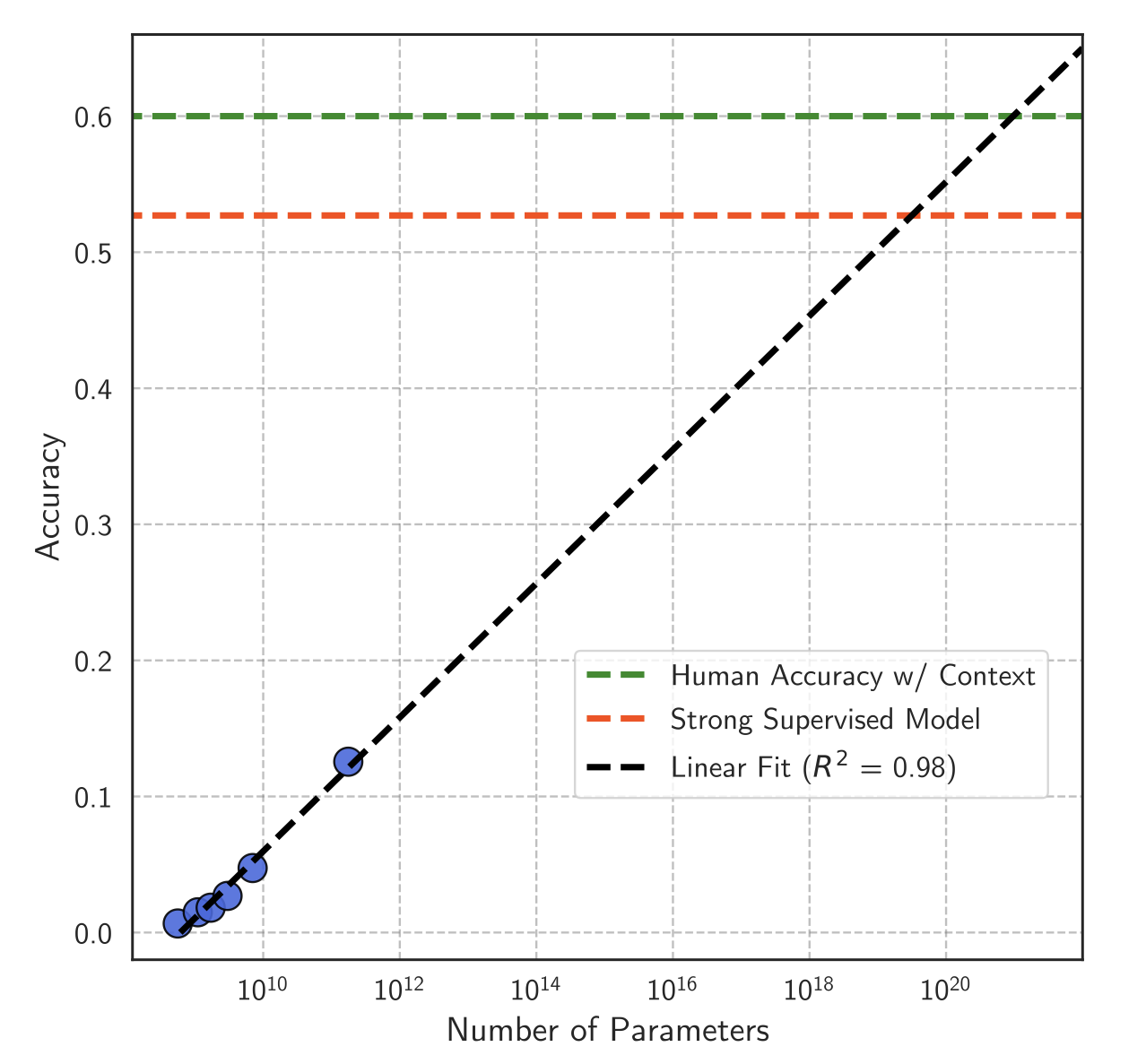
使用更大的模型通常会产生更好的问答性能。然而,我们的结果表明,为了在长尾问题上实现高准确性,人们需要使用极其庞大的 LMs。在下图中,我们绘制了罕见事实学习的 scaling 趋势线,其中我们展示了 BLOOM 模型在自然问题中罕见实例(<100个相关文档)上的准确性与模型大小的对数函数的关系。
Modifying the Training Objective
另一个选项是直接修改训练目标以鼓励记忆。一个简单的方法是增加训练的 epoch。我们研究的所有 LMs 都进行了有限的 epoch 训练,因为通常认为最好使用足够大的预训练数据集,以便在计算预算耗尽时 LM 完成一次训练时期。然而,在问答的背景下,增加 epoch 并减少数据量可能更可取,以确保模型尽可能多地记忆。另外,可以考虑修改训练损失以鼓励模型专注于显著的事实,或设计一个课程表以最小化遗忘。
Can We Use Retrieval Augmentation?
对于知识密集型任务,一个自然的替代方案是将 LMs 与检索模块结合起来,即使用检索增强模型,该模型返回相关的文本上下文。总体而言,检索增强模型在所有相关文档数量范围内表现优于 closed-book 模型,特别是在罕见的示例上。这些结果表明,检索增强为改善预训练数据集中相关文档较少的问题的性能提供了一个有希望的途径。