本文是 《LIMA: Less Is More for Alignment》 的笔记。
大型语言模型的训练分为两个阶段:(1)从原始文本进行无监督预训练,学习通用表示;(2)进行大规模指令微调和强化学习,以更好地适应最终任务和用户偏好。通过训练 LIMA,一个具有 65B 参数的 LLaMa 语言模型,我们衡量了这两个阶段的相对重要性。LIMA 仅使用 1,000 个精心策划的提示和回复进行标准的监督损失微调,没有进行任何强化学习或人类偏好建模。令人惊讶的是,LIMA 展现出了非常强大的性能,仅从训练数据中的少数示例中学会了遵循特定的回复格式,包括从规划旅行行程到推测另类历史的复杂查询。此外,该模型在未出现在训练数据中的未知任务上表现出良好的泛化能力。在一项受控的人类研究中,LIMA 的回复在 43% 的情况下要么与 GPT-4 相当,要么被严格优先选择;与 Bard 相比,这一统计数据高达 58%,与经过人类反馈训练的 DaVinci003 相比高达 65%。综合这些结果强烈暗示,几乎所有大型语言模型的知识都是在预训练阶段学习的,只需要有限的指导调整数据就足以教会模型产生高质量的输出。
Introduction
语言模型经过预训练以在惊人的规模上预测下一个 token,使其能够学习通用表示以转移到几乎任何语言理解或生成任务中。为了实现这种转移,已经提出了各种用于对齐(aligning)语言模型的方法,主要集中在大规模的几百万示例数据集上进行指令微调,以及最近从人类反馈中进行强化学习(RLHF),这些反馈是通过与人类注释者进行数百万次交互收集而来的。现有的对齐方法需要大量的计算资源和专门的数据才能达到 ChatGPT 级别的性能。然而,我们证明,只需在 1,000 个精心策划的训练示例上进行微调,就可以实现非常强大的性能,前提是有一个强大的预训练语言模型。
我们假设对齐可以是一个简单的过程,模型在这个过程中学习与用户进行交互的风格或格式,以展示在预训练阶段已经获得的知识和能力。为了测试这个假设,我们策划了 1,000 个示例,这些示例近似于真实用户的提示和高质量回复。我们从社区论坛(如 Stack Exchange 和 wikiHow)中选择了 750 个顶级问题和答案,以确保质量和多样性。此外,我们还手动编写了 250 个提示和回复的示例,同时优化任务的多样性,并强调以 AI 助手的精神为基础的统一回复风格。最后,我们训练了 LIMA,这是一个预训练的 65B 参数 LLaMa模型,在这组 1,000 个示例中进行了微调。
我们将 LIMA 与最先进的语言模型和产品在 300 个具有挑战性的测试提示上进行了比较。在一项人类偏好研究中,我们发现 LIMA 在性能上超过了经过 RLHF 训练的 OpenAI 的 DaVinci003,以及在 52,000 个示例上训练的 65B 参数的 Alpaca 的复制版本。虽然人们通常更喜欢 GPT-4、Claude 和 Bard 的回复,但这并不总是如此;LIMA 在 43%、46% 和 58% 的情况下分别产生了相等或更好的回复。对 LIMA 回复进行绝对评估显示,88% 的回复满足提示要求,50% 的回复被认为是优秀的。
消融实验揭示了在增加数据数量而不增加提示多样性时,收益显著减少,而在优化数据质量时则获得了重大收益。此外,尽管没有对话示例,我们发现 LIMA 能够进行连贯的多轮对话,并且通过仅向训练集添加 30 个手工制作的对话链,这种能力还可以得到显著改善。总的来说,这些显著的发现展示了预训练的强大能力以及其相对于大规模指令微调和强化学习方法的重要性。
Alignment Data
我们提出了表面对齐假设(Superficial Alignment Hypothesis):模型的知识和能力几乎完全是在预训练期间学习的,而对齐则教会模型在与用户交互时应该使用哪种格式的子分布。如果这个假设是正确的,并且对齐主要是关于学习风格,那么表面对齐假设的一个推论是,可以用相当小的示例集对预训练的语言模型进行足够的调整。为此,我们收集了一个包含 1,000 个提示和回复的数据集,其中输出(回复)在风格上是对齐的,但输入(提示)是多样的。具体而言,我们寻求以有帮助的 AI 助手风格的输出。我们从各种来源策划这些示例,主要分为社区问答论坛和手动编写的示例。我们还收集了一个包含 300 个提示的测试集和一个包含 50 个提示的开发集。
Community Questions & Answers
我们从三个社区问答网站收集数据:Stack Exchange、wikiHow 和 Pushshift Reddit 数据集。总的来说,Stack Exchange 和 wikiHow 的回答与一个有帮助的 AI 代理的行为非常一致,而 Reddit 上得到高赞的回答往往是幽默或恶搞的,需要更多手动的方法来策划符合适当风格的回复。
Manually Authored Examples
为了进一步使我们的数据多样化,我们收集了提示。我们指定了两组作者,编写答案时,我们尽量设置一个适合有帮助的 AI 助手的统一语调。具体而言,许多提示将以对问题的承认为开头,然后是答案本身。初步实验表明,这种一致的格式通常可以提高模型的性能;我们假设这有助于模型形成一条思路链,类似于“让我们逐步思考”的提示。
我们还包括了 13 个带有一定程度的恶意或恶意性的训练提示。我们仔细编写了部分或完全拒绝命令的回答,并解释了助手不会遵守的原因。测试集中还有 30 个类似问题的提示。
除了我们手动编写的示例之外,我们还从《超自然指令》中抽样了 50 个训练示例。具体而言,我们选择了 50 个自然语言生成任务,如摘要、改写和风格转换,并从每个任务中随机选择一个示例。我们对其中一些示例进行了轻微编辑,以符合我们手动编写的 200 个示例的风格。虽然潜在用户提示的分布与《超自然指令》中任务的分布可能不同,但我们的直觉是,这个小样本可以为训练示例的整体混合增加多样性,并可能增加模型的鲁棒性。
手动创建多样化的提示并以统一的风格编写丰富的回答是费时费力的。一些最近的研究通过蒸馏和其他自动手段避免了手动劳动[Honovich等,2022,Wang等,2022a,Taori等,2023,Chiang等,2023,Sun等,2023]。
Training LIMA
我们使用以下协议对 LIMA 进行训练。从 LLaMa 65B 开始,我们在我们的 1,000 个示例的对齐训练集上进行微调。为了区分每个发言者(用户和助手),我们在每个话语的末尾引入了一个特殊的转换结束标记(EOT);该标记的作用与停止生成的 EOS 相同,但避免了与预训练模型可能赋予预先存在的 EOS 标记的任何其他含义混淆。
我们遵循标准的微调超参数:使用 AdamW 进行 15 个时期的微调,其中 $\beta_1 = 0.9$,$\beta_2 = 0.95$,权重衰减为 $0.1$。没有预热步骤,我们将初始学习率设置为 $1e^{-5}$,并在训练结束时线性衰减到 $1e^{-6}$。批量大小设置为 32 个示例(较小的模型为 64 个示例),超过 2048 个 token 的文本将被修剪。
与常规的做法相比,我们使用了残差丢弃(residual dropout);我们遵循 Ouyang 等人的方法,在残差连接上应用丢弃,从底层 $p_d = 0.0$ 开始,在最后一层线性提高到 $p_d= 0.3$(较小的模型为 $p_d= 0.2$)。我们发现困惑度与生成质量没有相关性,因此通过 50 个示例的开发集来手动选择第 5 个和第 10 个 epoch 之间的检查点。
Human Evaluation
Results
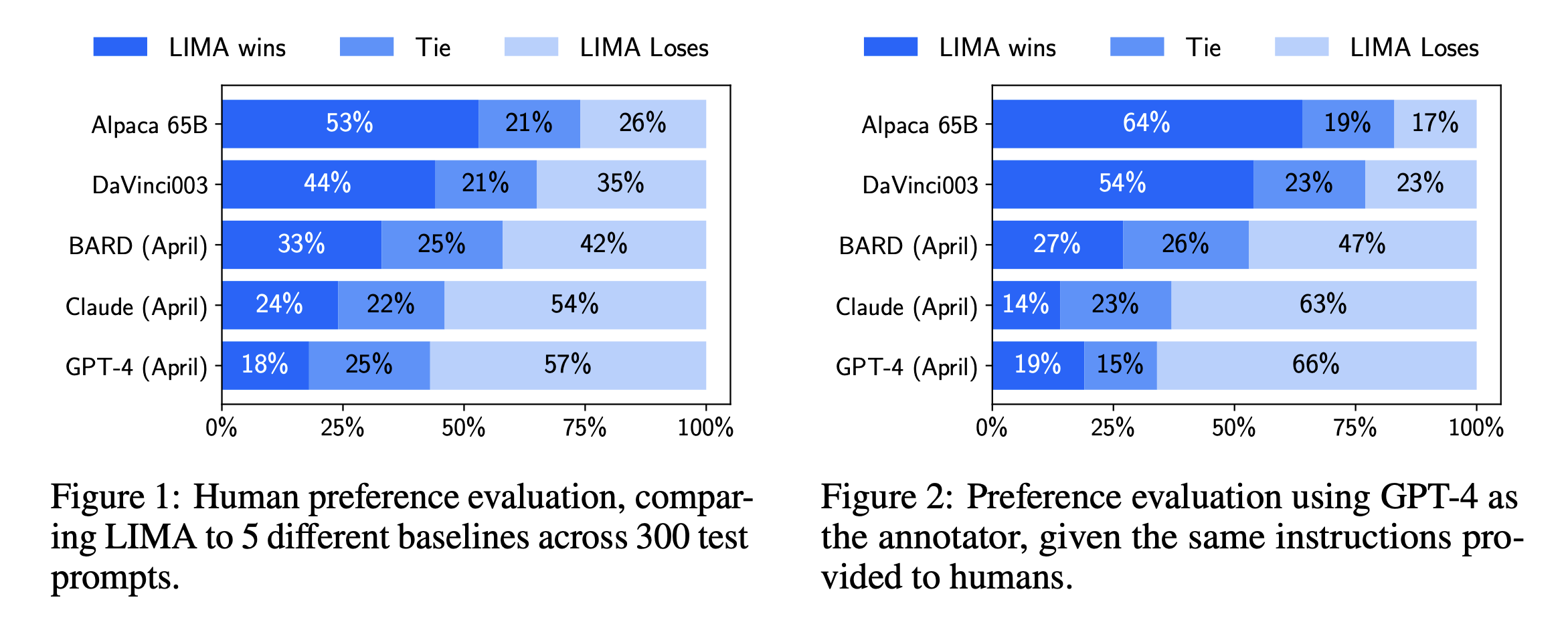
图 1 显示了我们人类偏好研究的结果,而图 2 显示了 GPT-4 偏好的结果。我们主要关注人类研究的结果,因为 GPT-4 在很大程度上展现出相同的趋势。我们的第一个观察是,尽管 Alpaca 65B 的训练数据是 LIMA 的 52 倍,但它倾向于产生比 LIMA 更不可取的输出。对于 DaVinci003 也是如此,尽管程度较轻;这个结果引人注目的是,DaVinci003 是使用 RLHF 训练的,这是一种被认为是更优越的对齐方法。Bard 显示了与 DaVinci003 相反的趋势,42% 的时间内产生比LIMA更好的回答,这也意味着 58% 的时间内 LIMA 的回答至少和 Bard 一样好。最后,我们发现虽然 Claude 和 GPT-4 通常表现比LIMA更好,但在一些情况下,LIMA 确实能够产生更好的回答。或许具有讽刺意味的是,即使是 GPT-4 自己也有 19% 的时间更喜欢 LIMA 的输出。
Why is Less More? Ablations on Data Diversity, Quality, and Quantity
我们通过消融实验来研究训练数据的多样性、质量和数量对模型的影响。我们观察到,在对齐的目的下,增加输入多样性和输出质量会产生可衡量的积极影响,而仅增加数量可能不会有同样的效果。
实验设置:我们在各种数据集上对 7B 参数的 LLaMa 模型进行微调,控制相同的超参数。然后,我们对每个测试集提示采样 5 个回答,并通过询问 ChatGPT(GPT-3.5 Turbo)对回答的帮助程度进行评分。
多样性:我们比较了在质量过滤后的 Stack Exchange 数据(具有异质提示和优秀响应)和 wikiHow 数据(具有同质提示和优秀响应)上进行训练的效果。虽然我们将 Stack Exchange 与 wikiHow 进行比较作为多样性的 proxy,但我们承认从两个不同来源采样数据时可能存在其他混杂因素。我们从每个来源采样 2,000 个训练示例。结果显示,更具多样性的 Stack Exchange 数据显著提高了性能。
质量:为了测试回答质量的影响,我们从 Stack Exchange 中采样了 2,000 个示例,没有进行任何质量或风格过滤,并将在这个数据集上训练的模型与在我们的过滤数据集上训练的模型进行比较。结果显示,在经过过滤和未经过滤的数据源上训练的模型之间存在显著的0.5 分差异。
数量:在许多机器学习场景中,增加示例数量是提高性能的一种众所周知的策略。为了测试其对我们的设置的影响,我们从 Stack Exchange 中采样指数增加的训练集。令人惊讶的是,结果显示,将训练集翻倍并没有改善回答质量。这个结果与本节中的其他发现一起,表明对齐的规模定律(scaling laws of alignment)不仅仅取决于数量,而是取决于多样性的函数,同时保持高质量的回答。
Multi-Turn Dialogue
可以只在 1,000 个单轮交互上进行微调的模型参与多轮对话吗?我们在 10 个实时对话中测试了 LIMA,并将每个回答标记为失败(Fail)、通过(Pass)或优秀(Excellent)。对于一个 zero-shot 聊天机器人来说,LIMA 的回答出奇地连贯,引用了对话中之前的信息。然而,很明显模型正在超出训练分布的范围;在 10 次对话中,有 6 次 LIMA 在 3 次交互内未能遵循提示。
为了提高 LIMA 进行对话的能力,我们收集了 30 个多轮对话链。其中,10 个对话是由作者编写的,而其余 20 个对话是基于 Stack Exchange 的评论链,我们对其进行编辑以适应助手的风格。我们使用合并的 1,030 个示例对预训练的 LLaMa 模型进行微调,得到 LIMA 的新版本,并使用与 zero-shot 模型相同的提示进行了 10 个实时对话。结果显示,添加对话显著提高了生成质量,优秀回答的比例从 45.2% 提高到 76.1%。此外,失败率从 42 个回合中的 15 次失败降低到 46 个回合中的 1 次失败。我们进一步比较了整个对话的质量,并发现在 10 个对话中,微调模型在 7 个对话中明显更好,并与 zero-shot 模型在 3 个对话中持平。这种能力的飞跃仅仅依靠 30 个示例,以及 zero-shot 模型能够进行对话的事实,进一步证实了这样的能力是在预训练期间学习的,并可以通过有限的监督来调用。
Discussion
我们展示了在 1,000 个精心策划的示例上对强大的预训练语言模型进行微调,可以在各种提示下产生出色且有竞争力的结果。然而,这种方法存在一些限制。首先,构建这样的示例需要相当大的心智努力,而且很难扩展。其次,LIMA 不像产品级模型那样稳健;虽然 LIMA 通常生成良好的回答,但在解码过程中遇到不利样本或对抗性提示往往会导致较弱的回答。尽管如此,本研究提供的证据表明,用简单的方法解决复杂的对齐问题具有潜力。