本文是 《The False Promise of Imitating Proprietary LLMs》 的笔记。
一种廉价改进较弱语言模型的新方法是在较强模型(如 ChatGPT)的输出上进行微调,例如使用较弱的开源模型来廉价模仿专有模型的能力。在本研究中,我们对这种方法进行了批判性分析。我们首先使用不同的基础模型大小(1.5B-13B)、数据源和模仿数据量(0.3M-150M tokens)对一系列语言模型进行微调以模仿 ChatGPT。然后,我们使用众包评估员和经典的自然语言处理基准对这些模型进行评估。最初,我们对模仿模型的输出质量感到惊讶——它们在遵循指令方面表现得更好,众包工作者将它们的输出评为与 ChatGPT 具有竞争力。然而,当进行更有针对性的自动评估时,我们发现在模仿数据中没有得到很好支持的任务上,模仿模型几乎没有弥补基础语言模型与 ChatGPT 之间的差距。我们表明,这些性能差异可能会逃过人工评估员的注意,因为模仿模型擅长模仿 ChatGPT 的风格,但不擅长模仿其事实性。总的来说,我们得出结论,模型模仿是一个虚假的承诺:开源和闭源语言模型之间存在显著的能力差距,当前的方法只能通过大量的模仿数据或使用更强大的基础语言模型来弥合。我们认为,提高开源模型的最有效措施是迎接开发更好基础语言模型这个艰难挑战,而不是走模仿专有系统的捷径。
Introduction
在这项工作中,我们研究了模型模仿(model imitation):一旦专有的 LM 通过 API 提供,就可以收集 API 输出的数据集,并将其用于对开源 LM 进行微调。理论上,这种模仿过程可以提供一种简单的方法来提取任何专有模型的能力。迄今为止,最近的研究已经试图模仿 OpenAI 的最佳系统,例如 Self-Instruct 和Alpaca,初步结果表明这些模型已经接近与专有模型的相当水平。因此,广大技术社区的许多成员普遍认为,闭源模型很快将不再具有优势。
我们的工作目标是通过训练和评估 ChatGP T的模仿模型来批判性地分析模型模仿的有效性。我们首先收集了专注于特定任务或广泛模仿 ChatGPT 的数据集。然后,我们使用不同的模型大小(1.5B-13B)、基础模型(GPT-2 和 LLaMA)和数据量(0.3M-150M tokens)对这些数据集上的LM进行微调。我们使用人工评估和 GPT-4 评估(与 ChatGPT 进行盲目的成对比较)以及在经典的自然语言处理基准测试(MMLU、NQ、HumanEval)上的准确性进行评估。
我们最初对模仿模型相比基础模型的改进程度感到惊讶:它们在遵循指令方面表现得更好,其输出与 ChatGPT 的输出相似。这一点在人工评估和 GPT-4 评估中得到了进一步的支持,我们最好的模仿模型的输出被评为与 ChatGPT 具有竞争力。
然而,当进行更有针对性的自动评估时,我们发现模仿模型在 LLaMA 和 ChatGPT 之间的巨大差距上几乎没有改进。特别是,我们证明了模仿模型在在模仿训练数据中得到很好支持的评估任务上有所改进。另一方面,对于缺乏支持的评估数据集,模型并没有改进(甚至准确性下降)。例如,使用广泛覆盖用户输入的 100k 个 ChatGPT 输出进行训练对于自然问题的准确性没有任何好处,但是仅使用 ChatGPT 对自然问题类似查询的回答进行训练则极大地提高了任务准确性。因此,我们得出结论,仅通过模仿来广泛匹配 ChatGPT 需要(1)集中精力收集大量的模仿数据集,以及(2)比当前可用的模仿数据更加多样化和高质量。
这些发现凸显了在众包工作者评估和自然语言处理基准测试中语言模型性能之间的不一致性。我们发现,模仿模型在众包工作者评估中得到积极评价,因为它们擅长模仿 ChatGPT 的风格——它们输出自信且结构良好的答案。然而,它们的事实性较弱,没有领域专业知识或没有投入足够时间的众包工作者可能会忽略这些错误。
总体而言,我们的主要观点是,模型模仿并非一种免费的午餐:当前的开源语言模型与闭源对应模型之间存在着能力差距,这个差距不能通过廉价地在模仿数据上进行微调来弥合。事实上,我们发现,弥合这种能力差距,例如通过增加基础语言模型的大小,比在额外的模仿数据上进行微调要更有效。这意味着改进开源语言模型的最有效方法是解决开发更好的基础模型的困难挑战(例如通过扩大模型规模、提高预训练数据质量、改进预训练等),而不是采用模仿专有系统的捷径。我们认为如果有足够强大的基础语言模型,在避免注释高质量微调数据方面,模型模仿是有用的。
What is Model Imitation
模型模仿的目标是使用 API 收集数据来训练一个与之相当性能的 LM。
在进行模型模仿时,可以选择进行局部的“任务特定”模仿或更全局的“广泛覆盖”模仿。广泛覆盖的模仿具有挑战性,因为(1)必须收集非常多样化的模仿数据集,以及(2)模仿模型必须捕捉到这种广泛的数据分布。
Building Imitation Datasets
我们考虑了任务特定和广泛覆盖的模型模仿。对于任何形式的模型模仿,都需要策划一组输入来查询目标模型。在实践中,可以有一组输入示例(例如来自维基百科的句子,关于可口可乐的推文),如果这组输入示例足够大,就可以使用它们来查询目标模型并构建一个模仿数据集。在无法创建大量和多样化的输入示例的情况下,也可以通过提示语言模型迭代生成示例来创建合成示例 (Wang et al., 2022a; Honovich et al., 2022)。
任务特定的模仿:对于任务特定的模仿,我们创建了一个针对自然问题的模仿数据集,即关于维基百科实体的事实知识。具体而言,我们首先从验证数据集中策划了一个包含十个问答对的种子集。然后,我们通过提示 ChatGPT 使用五个随机问答对并要求其生成类似但不同的示例,迭代生成了额外的 6,000 个示例。所有这些示例都是单轮的,没有对话历史。我们将这个数据集称为 NQ-synthetic。
广泛覆盖的模仿:对于更宏大的广泛覆盖模仿数据的目标,我们可以在网上收集大量、多样化且通常高质量的示例数据,而无需与公司的 API 进行交互。具体而言,我们从三个来源收集示例:
- ShareGPT:我们使用了大约 90,000 个对话,这些对话是用户在 ShareGPT 网站上共享的。为了保持数据质量,我们在查询级别进行了去重,并使用语言检测器删除了任何非英语对话。这样留下了大约 50,000 个示例,每个示例由多个对话轮组成
- HC3:我们使用 English Human-ChatGPT Comparison 语料库中的 ChatGPT 回答。其中包含了大约 27,000 个 ChatGPT 回答和大约 24,000 个问题
- Discord ChatGPT Bots:我们使用了从 r/ChatGPT 和 Turing AI Discord 服务器收集的 10,000 个输入-输出示例,这是两个公共频道,允许用户与 ChatGPT 机器人进行交互
我们将这个数据集称为 ShareGPT-Mix。我们发现 ShareGPT-Mix 的质量普遍很高。首先,指令的多样性很高:对于数据集中的每个用户查询,与之最相似的其他用户查询的平均 BLEU 分数相似度仅为 8%。这比其他数据集(如 SuperNaturalInstructions)要低得多,后者在类似规模的示例集上的 BLEU 相似度为 61%。除此之外该数据集包含多种类别,包括许多多语言对话和编码任务。
Main Results
我们使用 ShareGPT-Mix 和 NQ-synthetic 数据集训练模仿 LM,并进行人工和自动评估。
Training and Evaluation Setup
我们研究了随着模仿数据量的增加以及基础 LM 的能力变化下,模型模仿的改进情况。我们考虑了参数从 1.5B 到 13B 的 decoder-only 模型:GPT-2 1.5B,LLaMA 7B 和 LLaMA 13B。我们还通过使用不同大小的数据子集进行微调来研究数据规模的影响。
在训练过程中,我们将对话分块为 2048 个标记的块。我们引入了特殊的 token 来界定每个用户查询和模型输出的起始。我们仅使用模型输出上的标准 LM 损失进行微调,使用 AdamW 优化器进行一个 epoch 的训练,梯度按每个权重的大小进行重新缩放。我们使用学习率为 2e-3,线性预热 1000 个步骤从 0 开始,并使用批量大小 32 进行训练。所有模型都在 JAX 中训练,使用 Google Cloud 上托管的 TPU 进行完全共享的数据并行和张量并行,或者在一台带有 8 个 A100 GPU 的 Nvidia DGX 服务器上进行训练。
对于自动评估,我们在 5-shot MMLU、3-shot 自然问题和 0-shot 人工评估上衡量性能。我们报告与每个数据集相关的原始评分指标。对于人工评估,我们使用 Mechanical Turk 进行盲对比输出比较。在我们的用户界面中,我们向每个评估者呈现任务说明以及两个未知模型的输出,其中一个是 ChatGPT,另一个是我们的模仿模型之一。评估者选择他们更喜欢的输出,或者如果两个输出在质量上相等。我们使用大约 70 名众包工人,在 255 个保留的提示上进行评估。我们报告数据集的平均偏好以及均值周围的一个标准差。此外,我们还使用 GPT-4 进行评估。
Qualitative Analysis and Crowdworker Evaluation Show Promise
模仿模型受到众包工人的高度评价。我们最初对我们的 ShareGPT-Mix 模型的质量感到惊讶:尽管基础的 GPT-2 或 LLaMA 模型经常无法遵循指令,但模仿模型产生的输出能够保持在任务上。然而,我们还发现随着模仿数据量的增加,人工评分很快饱和,这暗示了这种方法可能存在一些缺点。
Targeted Automatic Evaluations Expose Failure Modes
广泛覆盖的模仿模型在大多数任务上无法缩小差距。接下来,我们进行了有针对性的自动评估,以确定在模仿之后特定的模型能力是否得到改善。我们发现,在我们测量的每个基准测试中,与基础模型相比,ShareGPT-Mix 模仿模型在准确性方面并没有改善(甚至下降),即使添加了额外的模仿数据。这表明,在我们的广泛覆盖的模仿数据上模仿 ChatGPT 并不能在大多数方面改善模型,例如事实知识、编码和问题解决能力。我们认为这是因为与 LLaMA 相比,ChatGPT 从网络中获取了更多的知识和能力。因此,期望通过少量的模仿数据(例如比预训练数据少 1000 倍的数据)来弥合这一差距是不合理的。我们认为要广泛匹配 ChatGPT,使用像 LLaMA-13B 这样的较弱基础 LM,需要集中努力收集一个非常庞大且多样化的模仿数据集,其规模接近预训练的规模。
另一方面,我们使用 NQ-synthetic 数据训练的模型在本地模仿 ChatGPT 方面取得了很大的成功。特别是,与 LLaMA 基础模型相比,模仿模型的性能显著提高,并且很快接近了 ChatGPT 的准确性。这表明从 ChatGPT 中提取特定行为要比广泛匹配其能力更加可行。一个有趣的现象是,在一些评估中,使用更多的 ShareGPT-Mix 数据对性能产生了负面影响。我们认为,这些性能回退是由于对话风格微调数据与下游基准之间的分布偏移(distribution shift and tension)引起的。一个未解决的问题是,是否可以通过使用正则化或在微调过程中混入预训练数据来缓解这些性能回退。
我们发现,与增加模仿数据规模相比,使用更好的基础 LM(通过增加基础模型的规模)确实可以显著提高准确性。这与我们之前的观点一致:当前的开源 LM 与闭源存在能力差距,无法通过廉价的模仿数据微调来弥合。相反,改进开源 LM 的最佳方式是解决开发更好的基础 LM 的难题,无论是通过模型扩展还是其他手段。
Imitation Models Learn Style, Not Content
最后,我们调查了为什么在众包工人评估中,模仿模型表现得非常强大,而在自然语言处理基准测试中,模仿模型的表现并不比基础 LM 更好。我们发现,模仿模型在人工评估中表现良好,因为它们擅长模仿 ChatGPT 的风格——它们输出流畅、自信且结构良好的答案。特别是,随着我们添加更多的模仿数据,ChatGPT 和我们的模仿模型产生的输出在长度、词语选择、权威语调的使用以及低级结构(例如列表的使用)方面非常相似。
然而,正如我们之前的自动评估所显示的,模仿模型在事实准确性方面较弱。换句话说,模仿模型实际上体现了一些 AI 助手的最糟糕的方面:它们的答案听起来自信,但事实准确性不如 ChatGPT。这在下图中可能最清楚地阐明,模仿模型输出了一个与 ChatGPT 答案风格相似但完全错误的答案:
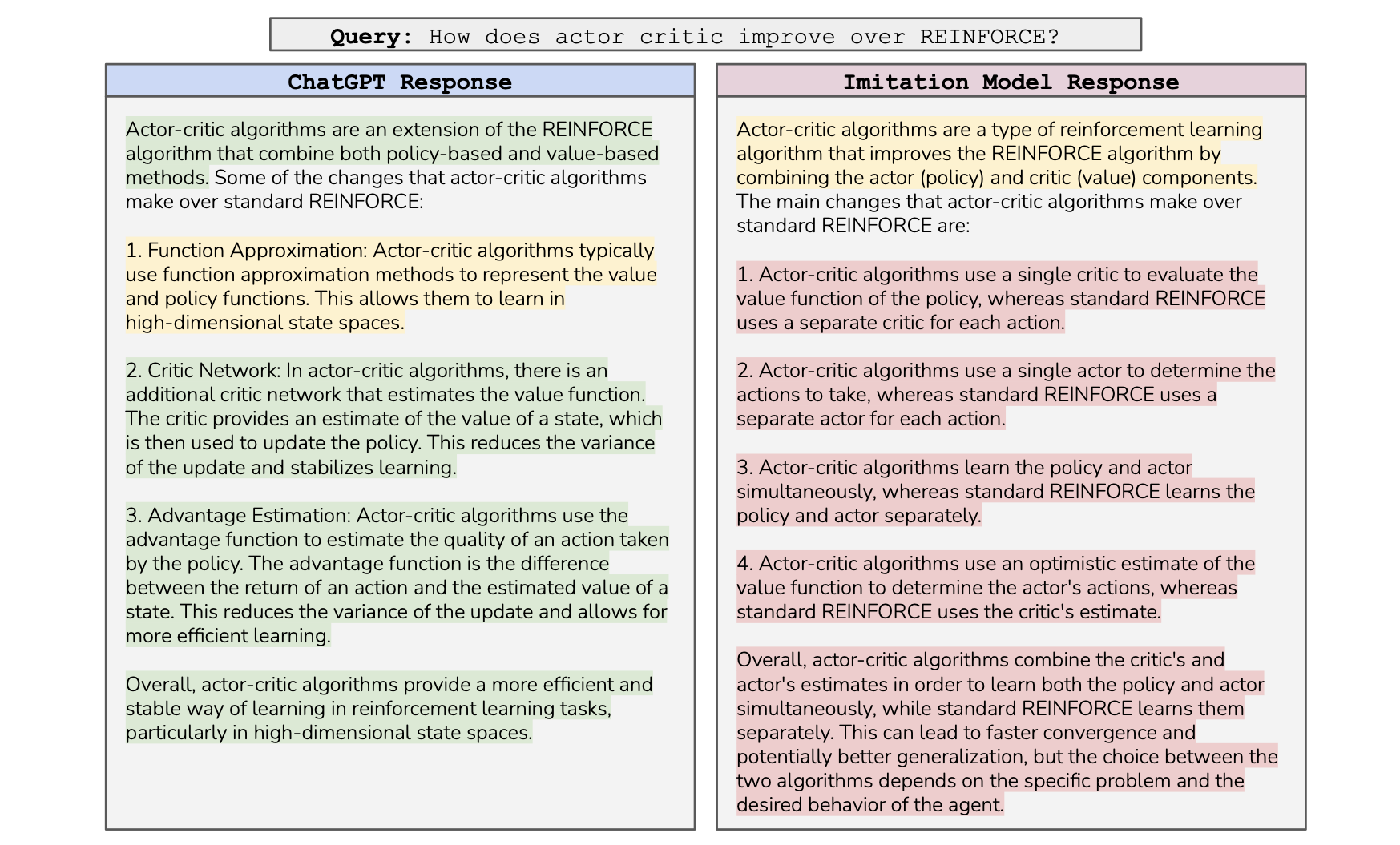
ChatGPT 和我们最佳的模仿模型在风格上产生了类似的答案——它们都以一个概述段落开始,列出了不同之处,并以一个总结结束。然而,尽管模仿模型的答案听起来很有权威性,但它的答案完全不准确,与 ChatGPT 的答案相比。我们用绿色表示正确的句子,黄色表示含糊不清但可能正确的句子,红色表示错误的句子。
人工评估变得越来越困难。不幸的是,没有领域专业知识的众包工人很容易被风格组成部分所欺骗——往往错误选择了听起来自信的答案。为了改进人工评估,因此越来越有必要既吸引领域专家,同时策划一组高难度的提示,以严格测试不同模型的能力。令人惊讶的是,我们的 GPT-4 评估结果也显示出与众包工人评估相同的趋势(尽管对 ChatGPT 的输出有稍微更大的绝对偏好)。虽然这表明 GPT-4 可能是在某些任务上廉价模拟人工评估的可行候选者,但它也意味着 LLM 可能会复制一些类似人类的认知偏差。
模仿模型继承了教师模型的安全性和毒性风格。尽管模仿只在模仿目标模型的“风格”或“个性”方面提供了好处,但仍然有价值。例如,OpenAI 经过精心和有意识地训练 ChatGPT 对最终用户是“无害”的,避免产生有害的输出,并拒绝回应可疑的用户请求。我们发现我们的模仿模型也继承了这些特点。特别是随着我们在更多的模仿数据上进行微调,模仿模型在 RealToxicityPrompts 上的输出变得毒性更少,因为模型学会了以类似于 ChatGPT 的方式避免产生有害输出。因此,我们得出结论,当拥有强大的基础 LM 并希望规避昂贵的微调数据注释时,模型模仿在某些情况下非常有效。
Discussion
研究结果显示,适度的微调对语言模型的知识或能力几乎没有提升。因此,我们同意预训练是语言模型能力的主要来源,而微调则是一种轻量级的方法,用于训练模型提取自身的知识(Schulman,2023)。这就是为什么仅仅通过在少量数据上模仿 ChatGPT 来改进模型的表现是不够的,因为基础知识基本上没有受到影响。此外,这种观点还暗示,在微调过程中,甚至应该避免引入新的知识,否则将训练模型去猜测或产生幻觉式的答案,而不是按照预期执行任务(Schulman,2023;Gao,2021;Goldberg,2023)。