本文是 《Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks》 的笔记。
基于多种来源文本的预训练语言模型构成了当今自然语言处理的基础。鉴于这些广泛覆盖模型的成功,我们研究了是否仍然有必要将预训练模型定制到目标任务的领域。我们在四个领域(生物医学和计算机科学出版物、新闻和评论)和八个分类任务中进行了一项研究,显示在领域内进行第二阶段的预训练(领域自适应预训练)在高资源和低资源环境下都能带来性能提升。此外,即使在领域自适应预训练之后,进一步利用相关任务的无标签数据继续训练(任务自适应预训练)也能提高性能。最后,我们展示了使用简单数据选择策略增强的任务语料库进行适应是一种有效的替代方法,特别是在领域自适应预训练的资源可能不可用时。总体而言,我们一致发现,多阶段自适应预训练在任务性能上提供了显著的提升。
Introduction
当今的预训练语言模型是在大规模、异构的语料库上进行训练的。例如,ROBERTA 是在超过 160GB 的非压缩文本上进行训练的,数据源包括英语百科全书和新闻文章、文学作品和网络内容。这些模型学习到的表示在许多任务上都表现出色,这些任务的数据集大小不一,来源多样。这引发了我们思考一个问题:任务的文本领域——通常用来表示某个特定主题或体裁(如‘科学’或‘悬疑小说’)的语言分布——是否仍然重要?最新的大型预训练模型是否能普遍适用,或者构建针对特定领域的单独预训练模型是否仍然有帮助?
虽然一些研究表明在领域特定的无标签数据上继续预训练的好处,但这些研究每次只考虑一个领域,并使用在比最新语言模型更小且不那么多样化的语料库上预训练的语言模型。此外,目前尚不清楚继续预训练的好处如何随可用标签任务数据的数量或目标领域与原始预训练语料库的接近程度等因素而变化。
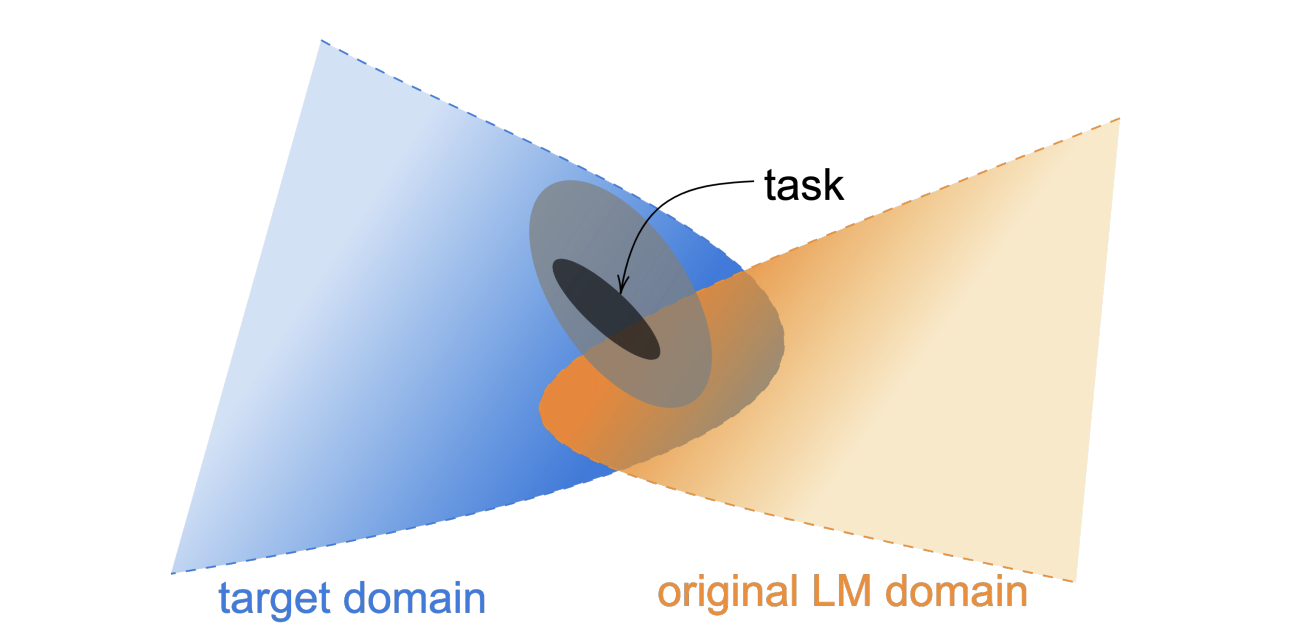
图 1:数据分布的示意图。任务数据由可观察的任务分布组成,通常是从更广泛的分布(浅灰色椭圆)中非随机抽样得到的,而这个更广泛的分布则属于更大的目标领域,不一定是原始语言模型预训练领域中包含的领域之一,尽管可能存在重叠。我们探讨了在任务分布和领域分布的数据上进行持续预训练的好处。
我们针对其中一个表现优异的模型,ROBERTA,来探讨这个问题。我们考虑了四个领域(生物医学和计算机科学出版物、新闻和评论;第3节)和八个分类任务(每个领域两个任务)。对于 ROBERTA 来说,如果目标不属于其原始领域,我们的实验证明在该领域上进行持续预训练(我们称之为领域自适应预训练,domain-adaptive pretraining,DAPT)可以在高资源和低资源环境下持续提高目标领域任务的性能。
我们考虑了围绕体裁和论坛定义的领域,但也可以从用于任务的特定语料库中引出一个领域,例如用于模型监督训练的语料库。这引发了一个问题,即在与任务更直接相关的语料库上进行预训练是否能进一步提高性能。我们在一个较小但与任务相关的语料库(无标签的任务数据集,从任务分布中获取)上研究了领域自适应预训练与任务自适应预训练(task-adaptive pretraining,TAPT)的对比。我们发现,TAPT 可以显著提升 ROBERTA 的性能,无论是否进行领域自适应预训练。
最后,我们展示了任务自适应预训练受益于有人工筛选的来自任务分布的额外无标签数据。受此启发,我们提出了自动选择额外任务相关无标签文本的方法,并展示了在某些低资源情况下如何提高性能。在所有任务中,我们使用自适应预训练技术的结果与当前最先进的技术相媲美。
总的来说,我们的贡献包括:
- 对跨四个领域和八个任务进行领域自适应和任务自适应预训练的彻底分析,覆盖了低资源和高资源的情况
- 对经过适应的语言模型在不同领域和任务之间的可迁移性进行研究
- 突出了在人工筛选的数据集上进行预训练的重要性,并提出了一种简单的数据选择策略实现自动化
Background: Pretraining
自 2018 年以来,大多数 NLP 学习过程包括两个阶段的训练。首先,使用大规模无标签语料库对神经语言模型进行训练,通常具有数百万个参数。预训练模型中学到的词表示随后在下游任务的有监督训练中被复用,并可以选择性地更新(微调)第一阶段的表示和网络。其中一种预训练的 LM 是 ROBERTA,它使用了与其前身 BERT 相同的基于 Transformer 的架构。ROBERTA 使用掩码语言建模目标进行训练(即,交叉熵损失用于预测随机掩码的标记)。ROBERTA 的无标签预训练语料库包含来自不同英语语料库的超过 160GB 的非压缩原始文本。ROBERTA 在各种任务上比其前身表现更好,因此我们选择它作为基准。
尽管 ROBERTA 的预训练语料库来自多个来源,但尚未确定这些来源是否足够多样化以涵盖英语语言的大部分变化。换句话说,我们希望了解 ROBERTA 领域之外的内容。为了实现这一目标,我们进一步探索了将这个大型 LM 进行持续预训练以适应两类无标签数据:(i)领域特定文本的大型语料库,以及(ii)与给定任务相关的无标签数据。
Domain-Adaptive Pretraining
我们进行 DAPT 的方法很简单——我们继续在大规模的领域特定无标签文本语料库上对 ROBERTA 进行预训练。我们关注的四个领域是生物医学论文、计算机科学论文、来自 REALNEWS 的新闻文本和 AMAZON 评论。我们选择这些领域是因为它们在以前的工作中很受欢迎,并且每个领域都有可用于文本分类的数据集。
Analyzing Domain Similarity
在进行 DAPT 之前,我们尝试量化目标领域与 ROBERTA 的预训练领域的相似性。我们考虑包含以下内容的领域词汇表:在每个领域语料库的保留文档中随机采样,取出最常见的 10K 个单词(不包括停用词)。对于除 REVIEWS 以外的每个领域,我们使用 50K 篇保留文档,而在 REVIEWS 领域,由于文档更短,我们使用 150K 篇保留文档。我们还从与 ROBERTA 的预训练语料库类似的来源(即 BOOKCORPUS、STORIES、WIKIPEDIA 和 REALNEWS)中抽样了 50,000 个文档,以构建预训练领域的词汇表,因为原始的预训练语料库并未公开。图 2 显示了这些样本之间的词汇重叠情况。我们观察到 ROBERTA 的预训练领域与 NEWS 和 REVIEWS 具有较强的词汇重叠,而 CS 和 BIOMED 与其他领域的相似性较低。这个简单的分析表明,将 ROBERTA 适应于不同领域时的预期收益程度——领域越不相似,DAPT 的潜力就越大。
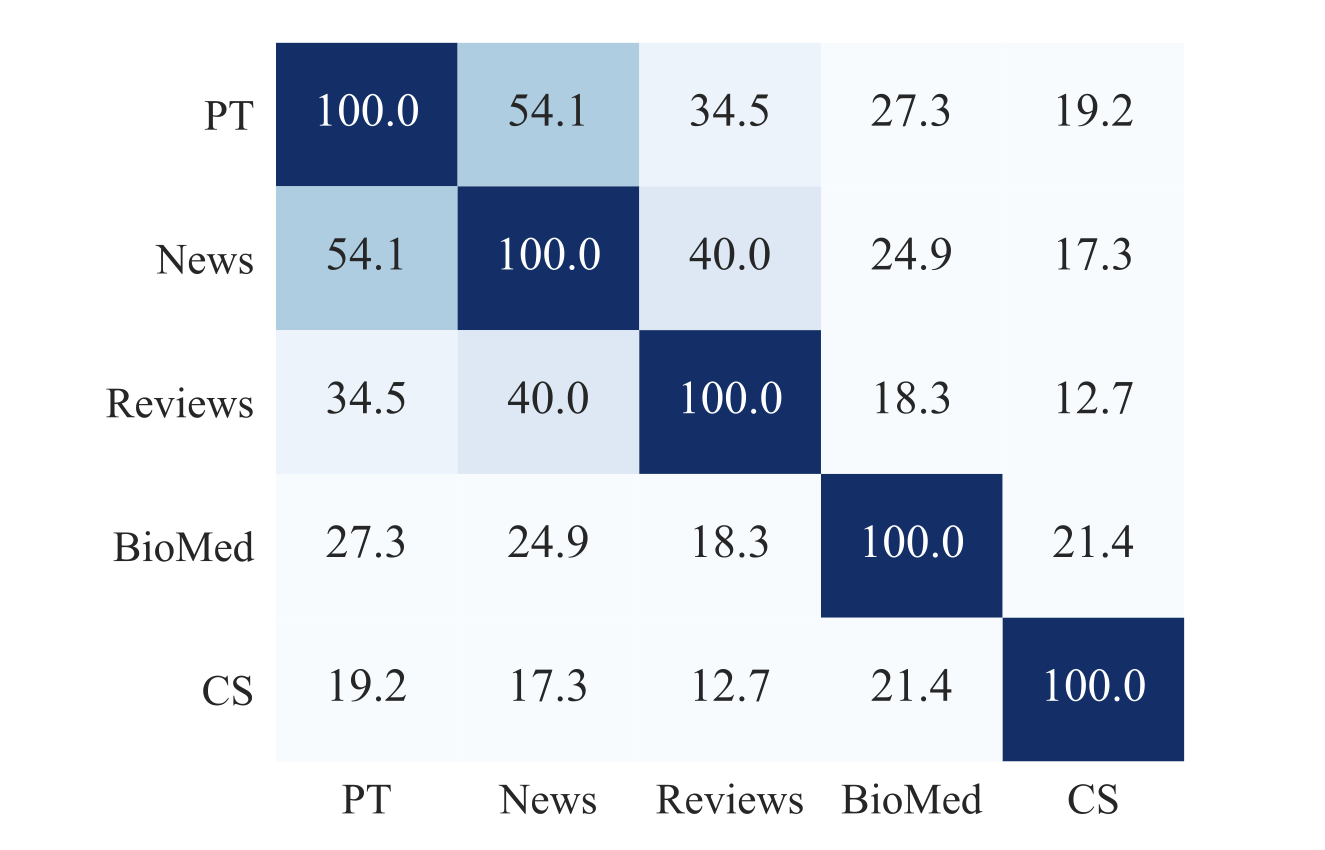
图 2:领域之间的词汇重叠(%)。PT 表示与 ROBERTA 的预训练语料库类似的样本。每个领域的词汇表是通过考虑从每个领域中抽样的文档中前 10,000 个最常见的词(不包括停用词)来创建的。
Experiments
我们的 LM 自适应遵循了 ROBERTA 训练的设置。我们在 v3-8 TPU 上对每个领域的 ROBERTA 进行了 12.5K 步的训练,相当于对每个领域的数据集进行了一次遍历。第二阶段的预训练得到了四个经过领域自适应的 LM。我们在表 1 中展示了 DAPT 前后 ROBERTA 在每个领域上的掩码 LM 损失。我们观察到除了 NEWS 领域外,DAPT 后所有领域的掩码 LM 损失都有所减少。

表1:领域特定的无标签数据集列表。在第5列和第6列中,我们报告了 ROBERTA 在每个领域中从随机抽样的 50,000 个保留文档上进行 DAPT 之前(LROB.)和之后(LDAPT)的掩码 LM 损失(较低的值表示对样本拟合更好)。‡ 表示掩码 LM 损失是在从与 ROBERTA 的预训练语料库类似的来源进行抽样的数据上估计的。
在每个领域下,我们考虑了两个文本分类任务,如表 2 所示。我们的任务涵盖了高资源和低资源(≤ 5K 个标注的训练样本,没有额外的无标签数据)的设置。对于 HYPERPARTISAN 任务,我们使用了 Beltagy 等人的数据划分。对于 RCT 任务,我们将所有句子表示为一个长序列进行同时预测。
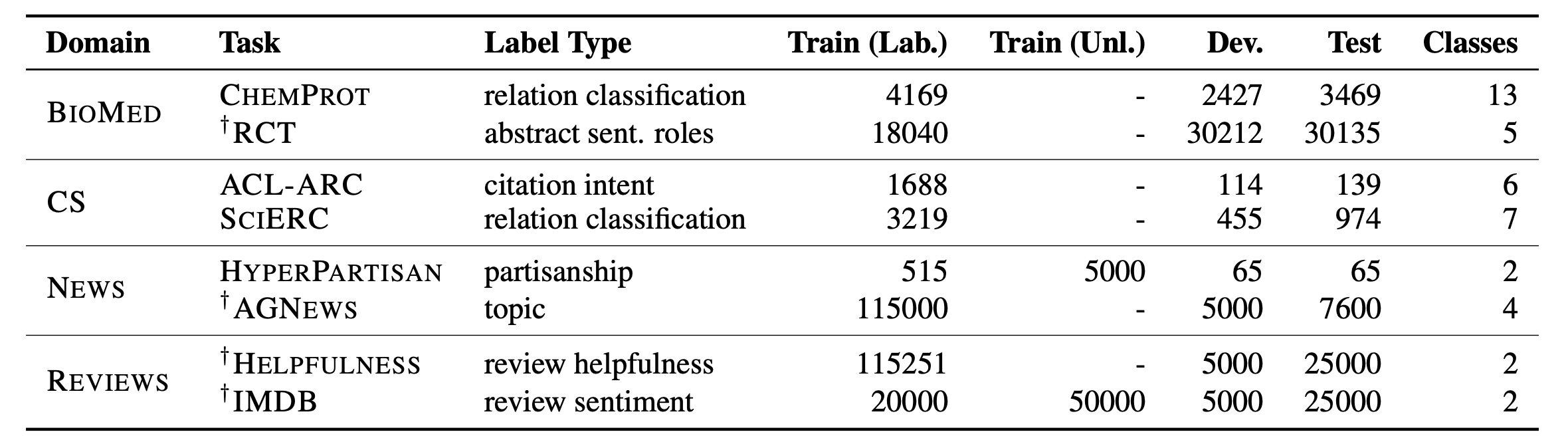
表 2:各个目标任务数据集的规格。† 表示高资源设置。
我们使用现成的 ROBERTA-base 模型,并对其参数进行有监督的微调以进行每个分类任务,来作为我们的基准线。平均而言,ROBERTA 并不明显落后于最先进的模型,并且作为一个良好的基准线,因为它提供了一个单一的语言模型来适应不同的领域。按照标准做法,我们将最后一层的 $\text{[CLS]}$ token representation 传递给任务特定的前馈层进行预测。测试结果显示在表 3 的 DAPT 列下。我们观察到 DAPT 在所有领域中都改善了 ROBERTA 的性能。对于 BIOMED、CS 和 REVIEWS,我们看到相对于 ROBERTA 的一致改进,这表明当目标领域与 ROBERTA 的源领域相距较远时,DAPT 的好处显而易见。这种模式在高资源和低资源设置下都是一致的。尽管 DAPT 并未提高 AGNEWS 的性能,但我们在 HYPERPARTISAN 任务中观察到的好处表明,即使对于与 ROBERTA 的源领域更为接近的任务,DAPT 也可能是有用的。
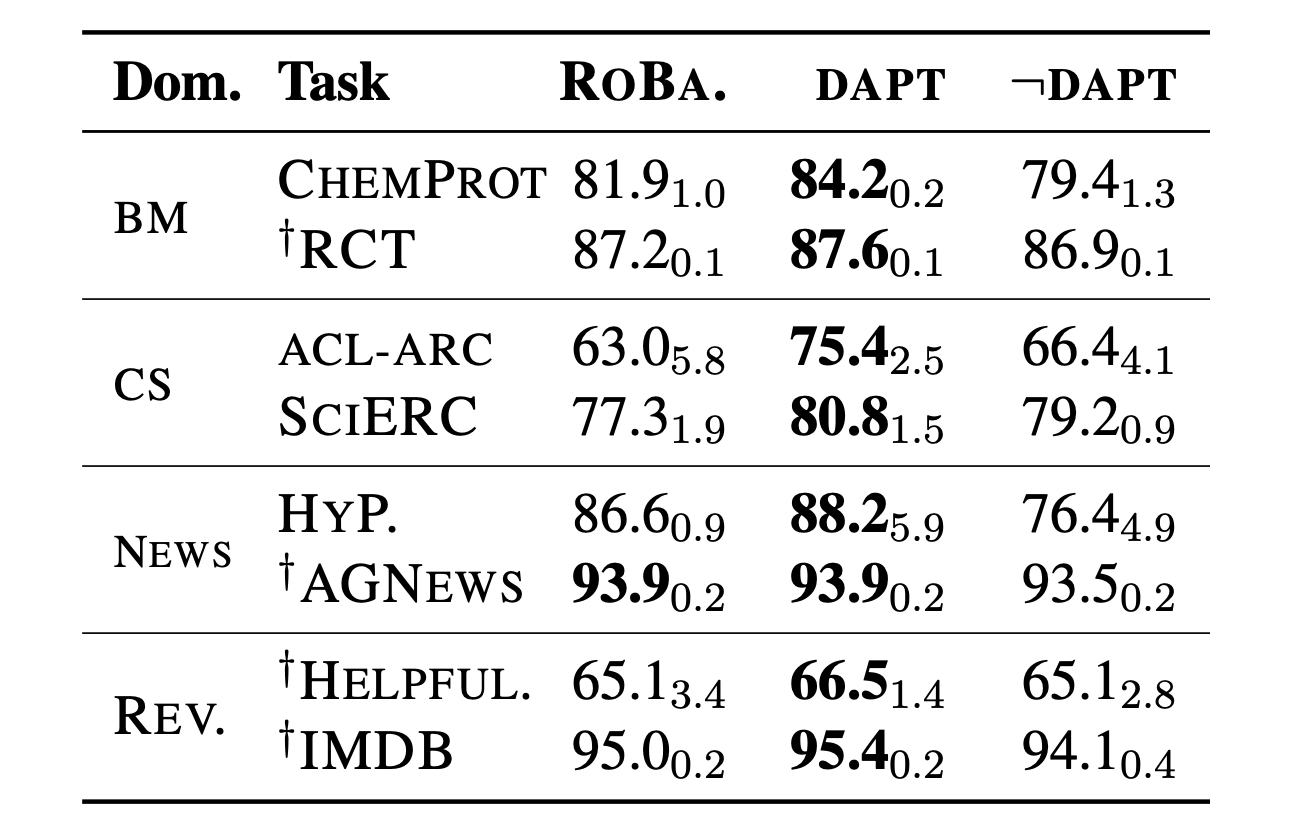
表 3:ROBERTA(ROBA.)和 DAPT 与适应无关领域(¬DAPT)的比较。报告的结果是测试集的 macro-F1 值,除了 CHEMPROT 和 RCT,我们报告的是 micro-F1 值,遵循 Beltagy 等人(2019)的做法。我们报告了五个随机种子的平均值,标准差作为下标。†表示高资源设置。最佳任务性能以粗体显示。
Domain Relevance for DAPT
此外,我们将 DAPT 与以下配置进行比较:对于每个任务,将 LM 适应到与感兴趣领域不同的领域。这样可以控制对 ROBERTA 的改进可能仅仅归因于暴露于更多数据,而与领域无关的情况。在这种设置中,对于 NEWS 任务,我们使用 CS LM;对于 REVIEWS 任务,我们使用 BIOMED LM;对于 CS 任务,我们使用 NEWS LM;对于 BIOMED 任务,我们使用 REVIEWS LM。我们使用图 2 中的词汇重叠统计数据来指导这些选择。
我们的结果显示在表 3 中,最后一列(¬DAPT)对应于这种设置。对于每个任务,DAPT 在性能上明显优于对无关领域的适应,这表明在预训练中使用与领域相关的数据的重要性。此外,我们通常观察到 ¬DAPT 的结果甚至比 ROBERTA 在最终任务上的表现更差。综合这些结果,可以得出结论,在大多数情况下,暴露于更多数据而不考虑领域相关性对最终任务的性能是有害的。然而,有两个任务(SCIERC 和 ACL-ARC)在 ¬DAPT 方面略微改善了 ROBERTA 的性能。这可能表明在某些情况下,继续在任何额外数据上进行预训练是有用的(Baevski 等,2019)。
Task-Adaptive Pretraining
为捕捉特定感兴趣任务而整理的数据集往往只涵盖更广泛领域内可用文本的一个子集。我们假设,在这种情况下,任务数据是更广泛领域的一个狭义定义的子集,在任务数据集本身或与任务相关的数据上进行预训练可能会有帮助。
TAPT 是指在给定任务的无标签训练集上进行预训练;先前的研究已经证明了其有效性(例如 Howard 和 Ruder,2018)。与 DAPT 相比,任务自适应方法在权衡上有所不同:它使用了一个远远较小的预训练语料库,但这个语料库更加与任务相关(在假设训练集很好地代表了任务的各个方面的情况下)。这使得 TAPT 的运行成本比 DAPT 要低得多,并且正如我们在实验中展示的那样,TAPT 的性能通常与 DAPT 相媲美。
Experiments
与 DAPT 类似,TAPT 对 ROBERTA 进行第二阶段的预训练,但仅使用特定任务的训练数据。与我们对 DAPT 进行 12.5K 步的训练不同,我们对 TAPT 进行 100 个 epoch 的训练。我们通过在不同的 epoch 中随机屏蔽不同的单词(使用屏蔽概率 0.15)来人为增加每个数据集的样本。与我们的 DAPT 实验一样,我们将最终层的 $\text{[CLS]}$ 标记表示传递给特定任务的前馈层进行分类。
我们的结果显示在表 5 的 TAPT 列中。TAPT 在所有领域的所有任务中都显著改善了 ROBERTA 的基准性能。即使在新闻领域,它也超过了 ROBERTA 的性能,这表明任务自适应的优势。尤其值得注意的是 TAPT 和 DAPT 之间的相对差异。DAPT 需要更多的资源,但 TAPT 在某些任务中的表现与 DAPT 相当,例如 SCIERC。在 RCT、HYPERPARTISAN、AGNEWS、HELPFULNESS 和 IMDB 任务中,TAPT 的结果甚至超过了 DAPT,突显了这种更经济的自适应技术的功效。
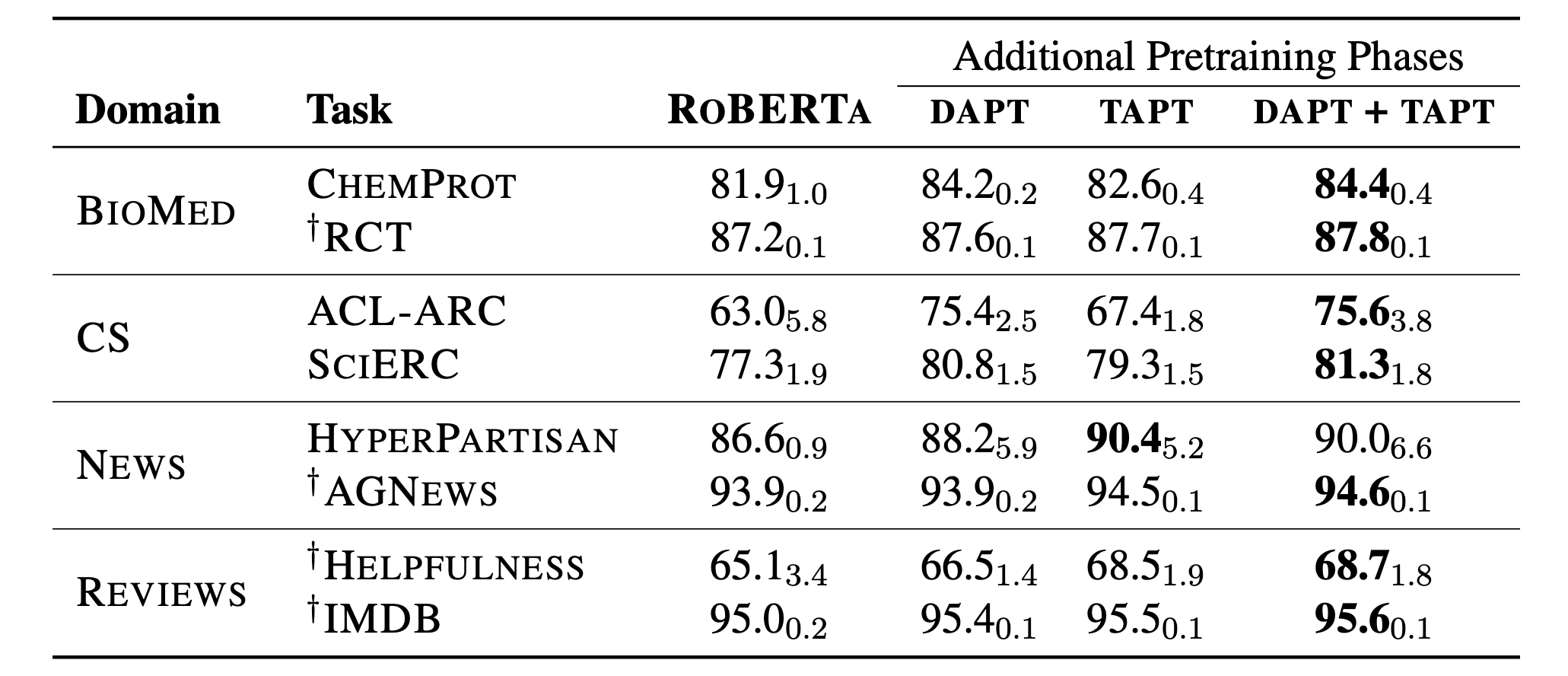
表 5:与基准 ROBERTA(第 1 列)相比,不同阶段的自适应预训练的结果。我们的方法包括 DAPT,TAPT,以及两者的组合。报告的结果遵循与表 3 相同的格式。我们可以进行比较的最先进结果为:CHEMPROT(84.6),RCT(92.9),ACL-ARC(71.0),SCIERC(81.8),HYPERPARTISAN(94.8),AGNEWS(95.5),IMDB(96.2);
我们还研究了同时使用这两种自适应技术的效果。我们从 ROBERTA 开始,先应用 DAPT,然后进行 TAPT。这三个预训练阶段使得这个设置成为我们所有设置中计算上最昂贵的。正如预期的那样,结合领域自适应和任务自适应预训练在所有任务上都取得了最佳性能(表5)。
总体而言,我们的结果表明,先进行 DAPT,然后进行 TAPT 可以同时实现领域和任务意识的最佳效果,从而获得最佳性能。虽然我们推测先进行 TAPT,然后进行 DAPT 可能会导致对任务相关语料库的灾难性遗忘(Yogatama 等,2019),但是结合这两种方法的替代方法可能会产生更好的下游性能。未来的工作可以探索使用更复杂的领域和任务分布课程进行预训练。
我们通过探索适应一个任务是否能够转移到同一领域的其他任务来比较 DAPT 和 TAPT。例如,我们进一步使用 RCT 的无标签数据对语言模型进行预训练,然后使用 CHEMPROT 的标签数据进行微调,并观察其效果。我们将这个设置称为 Transfer-TAPT。我们在所有四个领域的任务中的结果表明,TAPT 优化了单个任务的性能,但对跨任务迁移的影响较大。这些结果表明,在给定领域内,任务的数据分布可能不同。此外,这也可以解释为什么仅适应广泛的领域是不够的,以及为什么在 DAPT 之后进行 TAPT 是有效的。
Augmenting Training Data for Task-Adaptive Pretraining
在上一节中,我们仅使用监督任务的训练数据继续对语言模型进行任务适应的预训练。受 TAPT 成功的启发,我们接下来研究另一种情况,即存在一个来自任务分布的更大无标签数据池(通常由人工整理)。
我们探索了两种情况:首先,对于三个任务(RCT、HYPERPARTISAN 和 IMDB),我们使用人工策划语料库的更大规模的未标注数据池。接下来,对于那些没有额外人工策划数据的任务,我们探索从一个大型无标签领域内语料库中检索相关无标签数据用于 TAPT。
Human Curated-TAPT
数据集的创建通常涉及从已知来源收集大量无标签语料库,然后根据预算对该语料库进行下采样以收集标注。我们探索这种语料库在 TAPT 中的作用。
我们通过将 RCT 数据集的训练数据下采样到 500 个示例(总共有 18 万个可用示例),并将其余的训练数据视为无标签数据,模拟了低资源设置的 RCT-500。HYPERPARTISAN shared task 有两个设置:低资源和高资源。我们使用高资源设置中的 5,000 个文档作为 Curated-TAPT 的无标签数据,并使用原始的低资源训练文档进行任务微调。对于 IMDB,我们使用由任务注释者手动整理的额外无标签数据,这些数据从与标记数据相同的分布中提取。
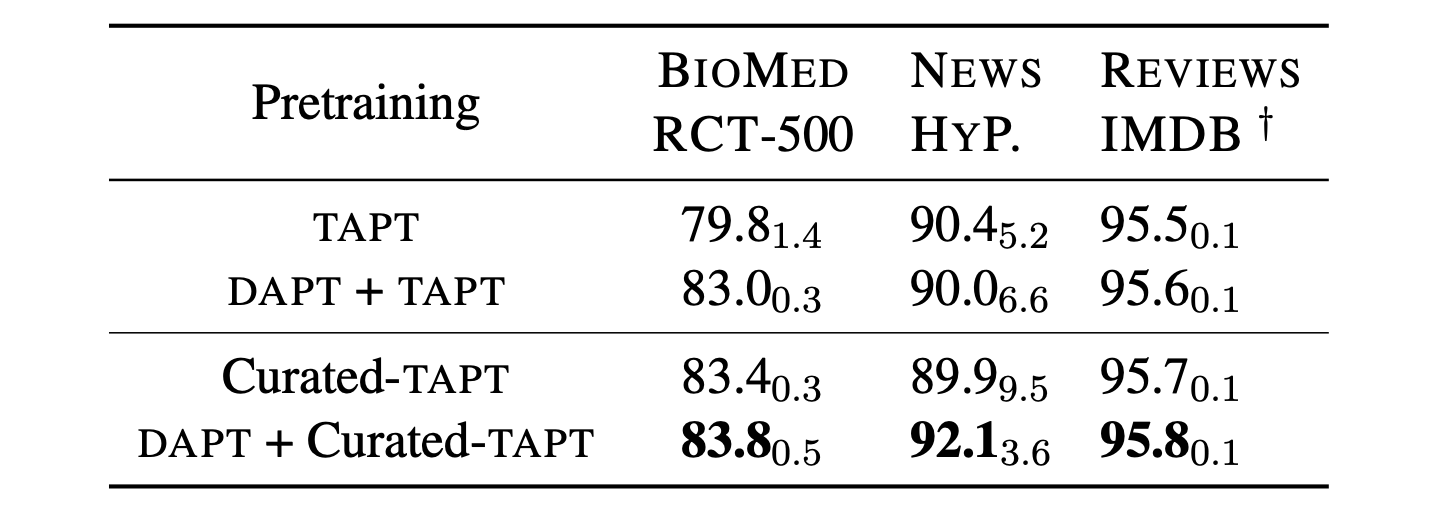
表7:在五个随机种子下,使用 Curated-TAPT 进行的 HYP. 和 IMDB 的测试集 macro-F1 均值,以及 RCT-500 的 micro-F1 均值,标准差以下标表示。†表示高资源设置
我们在表 7 中将 Curated-TAPT 与 TAPT 和 DAPT + TAPT 进行了比较。在所有三个数据集上,Curated-TAPT 进一步改善了我们先前的结果。在适应领域后应用 Curated-TAPT 可以在所有任务上获得最大的性能提升;在 HYPERPARTISAN 任务中,DAPT + Curated-TAPT 的性能在 Curated-TAPT 标准差范围内。Curated-TAPT 在仅使用 0.3% 标注数据的情况下,达到了 DAPT + TAPT 在完全标注的 RCT 语料库上 95% 的性能(表 5)。这些结果表明,从任务分布中筛选大量数据对于最终任务的性能非常有益。我们建议任务设计者释放大量未标记的任务数据,以通过预训练来帮助模型适应。
Automated Data Selection for TAPT
考虑到没有大量未标注数据的低资源情况,无法充分从 TAPT 中获益,同时也缺乏进行 DAPT 所需的计算资源。我们提出了一种简单的无监督方法,从大规模的领域内语料库中检索与任务分布相吻合的未标注文本。我们的方法通过将任务和领域的文本嵌入到共享空间中,然后基于任务数据的查询从领域中选择候选文本。嵌入方法必须足够轻量级,能够在合理的时间内嵌入可能有数百万个句子的文本。
在这些限制条件下,我们使用 VAMPIRE,一个轻量级的词袋语言模型。我们用领域内大规模去重样本(百万级数量的句子)对 VAMPIRE 进行预训练,以获得任务和领域样本的嵌入。然后,在嵌入空间中从领域样本中选择每个任务句子的 k 个候选数据。候选数据的选择方式有两种:(i)最近邻选择(kNN-TAPT),或者(ii)随机选择(RAND-TAPT)。我们继续在这个增强的语料库上,同时使用任务数据(与 TAPT 相同)和选定的候选数据池对 ROBERTA 进行预训练。
实验结果显示,对于所有情况,kNN-TAPT 的性能优于 TAPT。RAND-TAPT 通常比 kNN-TAPT 差。随着 k 的增加,kNN-TAPT 的性能稳步提高,并接近 DAPT 的性能。
Conclusion
我们研究了几种将预训练的语言模型适应到不同领域和任务的变体。我们的实验表明,即使是拥有数亿参数的模型也难以编码单一文本领域的复杂性,更不用说整个语言了。我们展示了将模型预训练于特定任务或小语料库可以带来显著的好处。我们的研究结果表明,除了不断增大语言模型的工作外,辅之以识别和使用与领域和任务相关的语料库来专门化模型可能是有价值的。虽然我们的结果展示了这些方法如何改进了 ROBERTA 这个强大的语言模型,但我们研究的方法足够通用,可以应用于任何预训练的语言模型。