本文是 《RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture》 的笔记。
搭建 LLM 应用时,开发人员通常有两种常见的方式来整合专有的领域特定数据:检索增强生成(RAG)和微调。RAG 通过外部数据增强提示信息,而微调则将额外的知识融入到模型本身中。然而,这两种方法的优缺点尚未被很好地理解。在本文中,我们提出了一个微调和 RAG 的流程,并展示了这两者在多个流行的 LLM(包括 Llama2-13B、GPT-3.5 和 GPT-4)上的权衡。
我们的流程包括多个阶段,包括从 PDF 中提取信息、生成问题和答案、将其用于微调,并利用 GPT-4 评估结果。我们提出了 RAG 和微调流程中不同阶段性能的评估指标。我们对农业数据集进行了深入研究。我们的结果显示,我们的数据集生成流程在捕捉地理特定知识方面是有效的,并且 RAG 和微调带来了定量和定性上的好处。当对模型进行微调时,我们看到准确率提高了超过 6 个百分点,而 RAG 进一步提高了 5 个百分点。在一个特定的实验中,我们还展示了经过微调的模型如何利用来自不同地理区域的信息来回答特定问题,将答案的相似度从 47% 提高到 72%。总体而言,这些结果表明,使用 LLM 构建的系统可以适应并整合特定行业关键维度上的知识,为 LLM 在其他工业领域的进一步应用铺平了道路。
1. Introduction
在本文中,我们引入了一个新的关注点:为需要特定背景和自适应响应的行业(如农业行业)创建 AI copilots。我们提出了一个全面的 LLM 流程,用于生成高质量的行业特定问题和答案。这种方法涉及一个系统化的过程,包括识别和收集涵盖广泛农业主题的相关文档。然后对这些文档进行清理和结构化,以便使用基础 GPT 模型生成有意义的问答对,随后对生成的问答对的质量进行评估和过滤。我们的目标是为特定行业创建有价值的知识资源,并以农业为案例研究,最终为这一关键领域的发展做出贡献。
在我们的农业研究中,我们的目标是生成地理特定的答案。为此,我们从一个农业数据集开始,该数据集被输入到三个主要组成部分中:问答生成、RAG 和微调。问答生成根据农业数据集中的信息创建问题和答案对,而 RAG 则将其作为知识源。生成的数据经过精炼并用于微调多个模型,其质量使用一组度量标准进行评估。
这篇论文主要贡献如下:
-
LLM 的全面评估:我们对大型语言模型进行了广泛的评估,包括 LlaMa2-13B、GPT-4 和 Vicuna,用于回答与农业相关的问题。我们使用了来自主要农业生产国家的基准数据集进行评估。我们的评估包括完整的微调和 RAG 流程,每个流程都有自己的一套度量标准。这些评估的结果为我们在农业背景下这些模型的性能提供了重要的基准理解。此外,我们还评估了空间转移(spatial shift)对现有 LLM 编码的知识的影响,以及空间范围微调所提供的改进。在我们的分析中,GPT-4 始终优于其他模型,但需要考虑与其微调和推理相关的成本。
-
检索技术和微调的影响:我们研究了检索技术和微调对 LLM 性能的影响。研究表明,RAG 和微调都是改善 LLM 性能的有效技术。RAG 在数据与上下文相关的情况下(例如解释农场数据)表现出很高的效果,并且比基础模型提供更简洁的回答。另一方面,我们发现微调有助于教授模型新技能(农业领域)以及提供更精确和简洁的回答。然而,由于在新数据上进行广泛的微调工作所需的高成本是一个重要的考虑因素。
-
LLM 在不同行业潜在应用的影响:这项研究在建立 RAG 和微调技术在 LLM 中的应用流程方面迈出了开创性的一步。我们展示了这些策略如何从问答生成过程开始,促使模型变得更加高效。从这项研究中获得的见解可以应用于其他领域,潜在地为各种应用的更高效的 AI 模型的开发提供指导。
2. Methodology
本文提出的方法论围绕着一个旨在生成并评估问题-答案对以构建特定领域的 AI copilots 的流程。所提出的流程如图 1 所示。
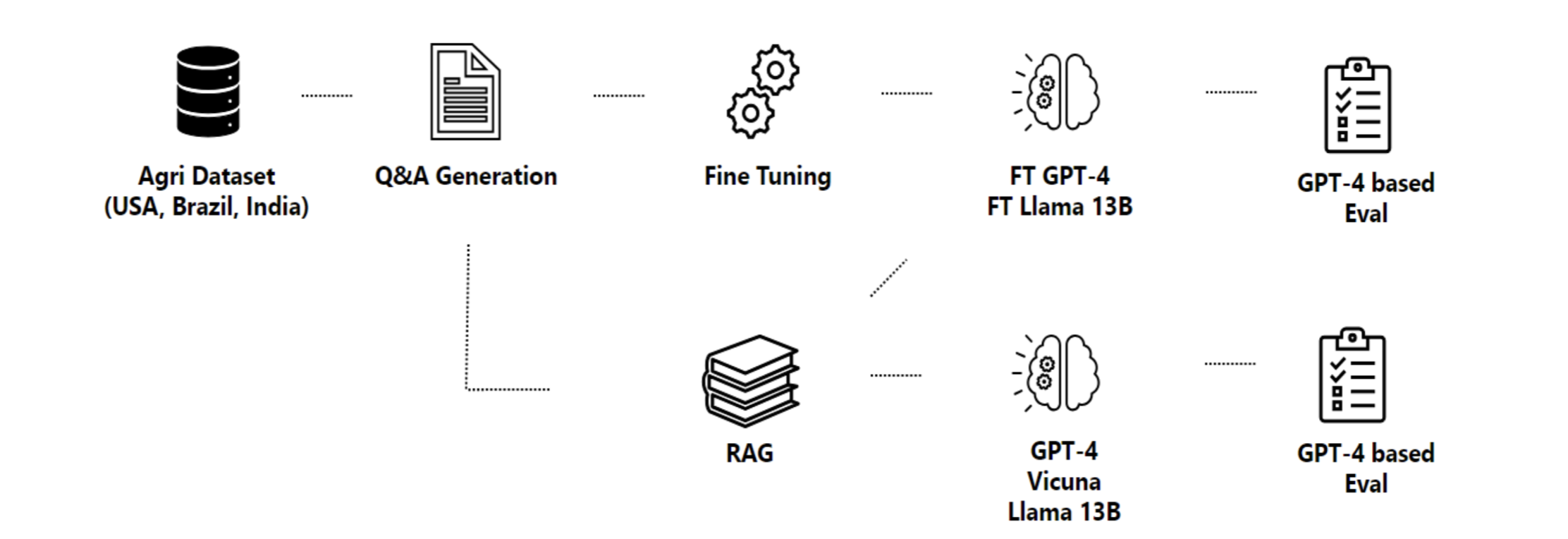
流程:首先收集领域特定的数据集,并提取文档的内容和结构。然后将这些信息输入到问答生成步骤中。合成的问题-答案对被用于对语言模型进行微调。使用基于 GPT-4 的不同指标对模型进行有和无 RAG 的评估。
2.1 Data Acquisition
流程的初始重点是收集一个多样化且经过精心整理的数据集,使得可以生成问题和答案,为优化模型以产生更精确和相关的回答奠定基础。确定了权威数据源之后,我们使用网络爬虫工具来收集所需的数据。我们采用了包括 Scrapy 和 BeautifulSoup 等网络爬虫框架,通过解析网站,获取所有可用的文档并下载相关文件。
2.2 PDF Information Extraction
在我们的研究中,从收集的文档中提取信息和文本结构对于后续步骤的质量至关重要。然而,这是一项具有挑战性的任务,因为 PDF 的主要目的是在不同系统上准确显示文档,而不是为了方便信息提取。此外,由于文档来自不同的来源,我们观察到它们的布局和格式复杂且缺乏标准化,通常呈现出表格、图片、侧边栏和页脚的混合形式。
基于这一点,流程中这一步的主要目标是解决处理来自各种格式化 PDF 文档。我们通过利用强大的文本提取工具和采用先进的自然语言处理机器学习算法来实现。不仅恢复每个文件的内容,还包括其结构。通过获取文档的组织结构,我们可以轻松地对信息进行分组,对表格中的数值数据进行推理,并为问题和答案生成步骤提供更一致的文本片段。
有多种在线工具可以从 PDF 中提取信息(PDF2Text/PyPDF)。然而,其中许多工具缺乏以结构化方式检索内容的能力。例如,pdf2text 是一个开源的 Python 库,提供了遍历 PDF 页面并恢复文本信息的方法。该库能够恢复文本信息,但在提取的数据中丢失了表示章节或子章节开头的标记,这妨碍了我们对文档结构进行推理的能力。表格和图表的标题在转换过程中也丢失了。
考虑到这一点,我们采用了 GROBID(GeneRation Of BIbliographic Data),这是一个专门用于从科学文献中提取和处理数据的机器学习库,支持 PDF 格式。其目标是将非结构化的 PDF 数据转换为以 TEI(Text Encoding Initiative)格式呈现的结构化数据,以高效地处理大量文件。使用经过大量科学文章训练的 GROBID,可以识别各种文档元素并提取相关的文献数据。
从 GROBID 生成的 TEI 文件中,我们提取了 TEI 文件的部分章节:包括文档元数据(标题、作者、摘要)、章节、表格、图表引用、参考文献和内容本身。这一阶段强调了文本的结构与其内容同样重要。最终将 TEI 文件转换为更易管理的 JSON 文件,既保留了内容,也保留了原始 PDF 的结构。这种方法确保对科学文献的内容和上下文有全面的理解。
2.3 Question Generation
这一部分的重点是从提取的文本生成问题时,管理自然语言固有的复杂性和多样性。我们的目标是生成与上下文相关且高质量的问题,准确反映提取的文本内容。为此,我们采用了 Guidance 框架,其主要优势在于对输入和输出的结构组成的卓越控制,从而增强了语言模型生成回答的整体效果。这种控制使模型的输出不仅更加精确,而且表现出更强的连贯性和上下文相关性。该框架将生成、提示和逻辑控制融合为一个统一的过程,与语言模型文本处理的内在机制密切相似。此外,Guidance 通过上下文特定的提示来引导语言模型,提高了生成文本的语义相关性。
首先,我们通过显式添加文本中的支持标签来增强可用文档的内容和结构。我们设计了提示,以提取文档每个部分中提到的位置和农业主题列表,如 Listing 3 所示,并要求 LLM 模型根据从 JSON 文件中提取的数据来回答这些问题。我们的目标是利用额外的信息,包括位置和提到的主题,来为生成过程提供基础,增强问题的相关性,并引导模型涵盖广泛的主题和挑战。
1
2
3
4
5
6
7
8
9
10
Answer the following questions with a single Yes or No:
1. The text mentions a specific location (City/State/Country), yes or no?
2. The text mentions a specific crop, yes or no?:
3. The text mentions a specific cattle, yes or no?:
4. The text mentions a specific disease, yes or no?:
Answer the following questions with a python list, or return an empty python list:
1. If the text mentioned a location or locations, list them:
2. If the text mentioned a crop or crops, list them:
3. If the text mentioned a cattle or cattles, list them:
4. If the text mentioned a disease or diseases, list them:
Listing 3:在问题生成过程中,用于从文档中识别支持上下文(即提及的位置和农学主题列表)的提示。
结合支持上下文信息和章节内容,我们提示 LLM 基于这些内容生成一组问题。Listing 4 中提供了一个问题生成提示的示例。该提示包括一个系统前言,引导 LLM 根据文档内容制定与行业主题相关的评估问题。而 user 部分则提供了预期问题类型的少量示例,以及用于生成的问题内容和支持的上下文。通过这种设置,LLM 为文档的每个章节生成 5 到 15 个问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{ {#system~ } }
You are an expert in agriculture and you are formulating questions from documents to assess
the knowledge of a student about agriculture-related topics.
You have access to the following document metadata encoded as JSON: { { context } }
{ {~/system} }
{ {#user~} }
An example of expected output follows:
Examples:
{ examples }
The document is from { { source } } and has title: { { title } }
Add location (state, country) and crop information to each question, if possible.
Please formulate as many questions as possible to assess knowledge of the text below.
{ {section} }
{ {~/user} }
{ {#assistant~} }
{ {gen ’answer’ max_tokens=2000} }
{ {~/assistant} }
Listing 4: 在提示模型时,我们将 { {context} } 标签替换为在上一步中检索到的支持信息,并分别将 { {source} }、{ {title} }、{ {section} } 标签替换为文档来源、标题和章节内容。
2.4 Answer Generation
我们采用了 RAG,首先从我们的数据集中检索与给定问题最相关的文档或段落。检索系统采用了诸如 BM25、Dense Retrieval 和其他先进的检索机制等技术。检索到的文档作为后续生成阶段的知识源。LLM 将问题和检索到的信息作为输入,并生成一个符合上下文的恰当答案。生成过程受到检索文档提供的上下文的引导,确保生成的问答对准确、相关且信息丰富。具体而言,生成过程包括以下三个步骤:
- 生成嵌入 & 构建索引:我们使用 sentence transformers(Reimers 和 Gurevych,2019)从我们的数据集中提取的文本块计算嵌入。然后,我们使用 Facebook AI Similarity Search(FAISS)创建嵌入数据库。
- 检索:给定一个输入问题,我们计算其嵌入并从 FAISS 数据库中检索相关的文本块。我们使用 FAISS 检索工具 similarity_search_with_score 来执行相似性搜索,返回与问题相关的文本片段。
- 答案生成:问题和检索到的文本块作为输入,使用 LLM 模型合成答案。我们将从 FAISS 数据库中检索到的信息作为上下文提供给 GPT-4,并在自定义提示中生成领域特定的答案。答案与相关的问题一起构成 JSON 格式的问答对。
2.5 Fine-tuning
在开发先进的 AI 语言模型时,涉及到创建数据集和训练具有不同容量的模型。我们使用 Llama2-13b-chat 结合 RAG 生成了一个包含问题和相应答案的数据集。我们训练了几个不同大小的基础模型,包括 Open-Llama-3b、Llama2-7b 和 Llama2-13b。这些模型旨在根据问题 prompt 预测答案,同时屏蔽 prompt token 以确保模型不会预测它们。
为了优化这些模型的性能,我们采用了使用 8 个 H100 GPU 和 PyTorch 的完全分片数据并行(FSDP)的微调过程。FSDP 允许对参数、优化器状态和梯度进行分片,有效地减少了训练期间的内存需求。每个模型中的每个 transformer 模块都作为 FSDP 模块运行,并带有激活检查点。训练过程涉及每个 GPU 的微批量为 4 个样本,累积梯度超过 4 个微批量,从而实现每步 128 个样本的有效批量大小。训练进行了 4 个 epoch,采用自动混合精度(automatic mixed precision,AMP)与 BFloat16,基础学习率为 2e-5,cosine learning rate scheduler 与线性预热(占总步数的 4%)。整个训练过程中使用了带 flash-attention monkeypatching 的 FastChat 训练脚本。
最后,我们也用这个设置对 GPT-4 进行了微调。由于其规模更大且更昂贵,我们的目标是评估模型是否会从额外的知识中受益,相比于基础训练。由于其复杂性和可用数据的数量,我们在微调过程中使用了 Low Rank Adaptation(LoRA)。这种技术提供了一种有效的方法来调整参数较多的模型,相比传统的重新训练,需要更少的内存和计算资源。通过调整架构中注意力模块的一组减少的参数,它可以嵌入来自新数据的领域特定知识,同时不丢失基础训练中获得的知识。在我们的研究中,优化进行了 4 个 epoch,批次大小为 256 个样本,基本学习率为 1e-4,并随着训练的进行而衰减。微调在七个节点上进行,每个节点配备八个 A100 GPU,总运行时间为 1.5 天。
4. Metrics
我们建立了一套全面的指标,用于指导问答生成过程的质量评估,特别是针对微调和RAG方法。机器学习中的一个基本原则是,模型的质量受到其训练数据质量的强烈影响。在这个背景下,为了训练或微调一个能够有效生成高质量问答对的模型,我们首先需要一个强大的数据集。我们的框架的输入是问答及其相关上下文,输出是问答的质量以及最终微调模型的量化评估。
在开发我们的指标时,必须考虑几个关键因素。首先,问题质量中固有的主观性是一个重要的挑战,必须设计能够在这种主观性中客观评估质量的指标。其次,这些指标必须考虑到问题的相关性和有用性与其上下文的依赖关系。在一个上下文中提供有价值见解的问题在另一个上下文中可能被认为是不相关的,这凸显了对上下文感知指标的需求。第三,我们需要评估生成的问题的多样性和新颖性。一个强大的问题生成系统应该能够产生涵盖给定内容各个方面的各种问题。然而,量化多样性和新颖性可能具有挑战性,因为它涉及评估问题的独特性以及与内容和其他生成的问题的相似性。语法正确性和流畅性也是问题质量的重要因素。虽然自动化工具可以评估语法正确性,但评估流畅性通常需要人类判断,这使得创建一个完全自动化的指标变得困难。最后,一个好的问题应该能够基于提供的内容得到回答。评估一个问题是否可以根据可用信息准确回答需要对内容有深入的理解,并能够识别与问题相关的信息。
我们开发了一套专注于评估问题质量的指标。鉴于问题在推动有意义的对话和生成有用答案方面起着关键作用,确保问题的质量与答案一样重要。对问答的定量评估不仅有助于改进生成过程,还能确保输出的相关性和准确性,最终提高我们模型的整体效力。
4.1 Question Evaluation
我们开发的用于评估问题的指标如下:
-
相关性:我们使用 LLMs(即 GPT-4)来对指定上下文的问题进行评分,评分范围为 1 到 5,其中 5 表示农民可能会提出这个问题,1 表示不会。该指标确保生成的内容与目标受众相关且准确。
-
全局相关性:我们使用 LLMs(即 GPT-4)来对不指定上下文的问题进行评分,评分范围为 1 到 5,其中 5 表示农民可能会提出这个问题,1 表示不会。该指标确保生成的内容与目标受众相关且准确。
-
覆盖范围:为了判断生成的答案是否可以直接从提供的上下文中提取,并且模型是否没有产生幻觉的答案,我们使用 LLMs 来对每个问答进行评分,评分范围为 1 到 5。提示是:“Your task is to rate from 1 to 5 if the answer can be extracted from the context and the question”。较高的分数表示答案更可靠地从上下文中提取,确保模型的输出基于可用信息。
-
重叠度:为了评估生成的问题与源文本/部分之间的语义相似性,我们使用 Kullback-Leibler(KL)散度作为度量标准。KL 散度是一种不对称的度量,用于量化两个概率分布之间的差异。通过利用文本中单词的平滑计数(smoothed counts of words),该方法可以更细致地比较它们的语义内容。较低的 KL 散度值表示问题与文本之间更高的语义重叠度,这符合生成有效问答的预期。
-
多样性:我们使用 Word Mover’s Distance(WMD) 作为度量标准。WMD 是一种用于衡量两个文档或文本样本之间语义相似性的强大指标。它基于最优传输的概念,旨在找到以单词的语义含义为基础,将一个文档的内容“移动”到另一个文档的最有效方式。WMD 利用词嵌入,如 Word2Vec 或 GloVe,将单词表示为捕捉其语义含义的高维向量。这些嵌入使得可以在连续的语义空间中计算单词之间的距离,从而可以更细致地比较两个文本样本的含义。较小的 WMD 值表示问题和文本之间更高的含义重叠度,这符合生成有效问答的预期。然后,我们计算所有生成问题之间的相似性矩阵。通过计算该矩阵的非对角线元素的平均值,我们可以得到一个多样性的度量。较小的平均值表示问题之间更大的相似性,因此多样性较低。
-
细节:我们通过计算生成的问题和答案中的 token(单词)数量来评估细节水平。该指标提供了问答系统生成内容的深度和具体性的见解。通过使用这些指标,我们可以有效评估和完善问答生成过程,确保生成的内容信息丰富、相关、多样,并基于源材料。
-
流畅性:最后,我们使用流畅性指标来评估流畅性和连贯性,利用 LLM(如 GPT-4)。通过准备一个提示,指示 AI 对给定的问题进行 1 到 5 的评分并提供解释,模型可以为每个问题生成有见地的评分。在将生成的问题附加到提示中,提交给 GPT-4,并解析响应以提取流畅性评分和解释后,可以将结果存储以供进一步分析。这种方法有效利用了 GPT-4 的语言理解能力,评估生成问题的质量,有助于改进问题生成模型并选择特定应用的最佳问题。
4.2 Answer Evaluation
在评估由 LLM 生成的答案时,由于其倾向于生成冗长、信息丰富且对话式的答案,这是一项具有挑战性的任务。传统的指标不适合评估这种类型的答案。最近的研究表明,LLM 本身作为评判者,与人类的高度一致,可以直接使用或与其他技术结合使用,以评估带或者不带上下文的问题答案。在开放式场景中,将微调 LLM 为评判者也具有潜力。在这项工作中,我们使用了 AzureML 模型评估,并使用以下指标将生成的答案与真实答案进行比较:
- 一致性:在给定上下文的情况下比较真实答案和预测答案的一致性。该指标提供 1 到 5 的评分,其中 5 表示答案具有完美的一致性。
- 相关性:相关性衡量基于上下文,答案在多大程度上解决了问题。该指标的评分范围为 1 到 5,其中 5 表示答案具有完美的相关性。
- Groundedness:该指标定义答案是否在逻辑上遵循上下文中包含的信息。
4.3 Model Evaluation
评估微调 LLM 是一项重大挑战,因为人工评估成本高昂,非专家很难判断技术答案的正确性。为了评估不同的微调模型,我们使用了 GPT-4 作为评估者。使用 GPT-4 从农业文档中生成大约 270 个问答对,作为基准数据集。针对这些问题,每个 FT 和 RAG 模型生成答案。为了确保 GPT-4 作为评估者的一致性,我们在每次评估中提示 GPT-4 五次,以测量响应的差异。LLM 通过多种不同的指标进行评估:
- 使用指南进行评估:对于每个问答基准对,提示 GPT-4 生成一个评估指南,列出正确答案应包含的内容。然后,提示 GPT-4 根据答案是否满足评估指南中的标准,对其进行 0 到 1 的评分。
- 简洁性:我们创建了一张评分表,描述简洁和冗长答案可能包含的内容。我们将评分表、基准答案和 LLM 答案提示给 GPT-4,并要求在 1 到 5 的范围内进行评分。
- 正确性:我们创建了一张评分表,描述完整、部分正确或不正确答案应包含的内容。我们将评分表、基准答案和 LLM 答案提示给 GPT-4,并要求对其评分。
5. Experiments
实验部分的主要目标是对各种模型在农业数据背景下生成问答对的性能进行全面评估和分析,并将这些用于 RAG 或微调。实验分为几个独立的子实验,每个子实验专注于问答生成和评估、RAG 和微调的特定方面。这些实验设计为独立但互补的,提供了对模型性能的多方面理解。
实验探讨了以下领域:
- 问答质量:该实验评估了三种 LLMs,即 GPT-3、GPT-3.5 和 GPT-4,在不同上下文设置下生成问答的质量。质量评估基于多个指标,包括相关性、覆盖率、重叠度和多样性。
- 上下文研究:该实验研究了不同上下文设置对模型生成问答对性能的影响。它在三种上下文设置下评估生成的问答对:无上下文、上下文和外部上下文。
- 模型到指标计算:该实验比较了 GPT-3.5 和 GPT-4 在用于计算评估问答质量指标时的表现。
- 一起生成 vs 分别生成:该实验探讨了分别生成问题和答案的好处,而不是将它们一起生成,重点关注 token 使用的效率。
- 检索消融研究:该实验评估了 RAG 的检索能力,这是一种通过在回答问题时提供额外上下文来增强 LLM 内在知识的方法。
- 微调:该实验评估了微调模型与基础指令调优模型的性能。其目的是了解微调在帮助模型学习新知识方面的潜力。
5.1 Q&A Quality
在接下来的实验中,我们使用了三种 LLM ,即 GPT-3、GPT-3.5 和 GPT-4,来评估生成问答的质量。这些问答对是在不同的上下文下生成的:无上下文、上下文和外部上下文。我们使用了多种指标(在第 4.1 节中定义)来评估它们的质量。对于某些指标,如重叠度和多样性,我们采用了 Kullback-Leibler(KL)散度和 Word Mover’s Distance(WMD),以衡量源文本与生成问题之间的语义相似性。此实验设置的主要目的是理解不同的问答生成技术如何影响生成问答对的质量。我们旨在辨别各种指标如何感知和评估这些问答对的质量,这对改进问答生成过程至关重要,因为它确保生成的内容是信息丰富的、相关的、多样的和流畅的。
5.1.1 Context Study
我们要求 GPT-3、GPT-3.5 和 GPT-4 模型在三种不同的上下文设置下生成问答:无上下文、上下文和外部上下文。无上下文设置在提示中没有提供具体信息。上下文设置在提示中包括文档来源的位置或州。在外部上下文设置中,通过第 2.3 节中描述的过程获取的额外上下文被包含在提示中。表 12 中提供了一个示例。
| Context | Question |
|---|---|
| No context | What are some decision support tools that can help producers in the Pacific Northwest understand the impacts of climate change and variability on their operations? |
| Context | As a dryland farmer in the Inland Pacific Northwest, USA, how can decision support tools help in adapting to climate change and its impacts on agricultural operations? |
| External context | What decision support tools are available to agricultural decision-makers in the Inland Pacific Northwest to help them understand how climate change and variability may affect their operations? |
表 12: 没有上下文、有上下文和外部上下文生成的问题示例。
这些模型在生成问答时的性能通过表 13 中呈现的各种指标进行评估的。
在没有上下文的设置中,GPT-4 在三个模型中具有最高的覆盖率和提示大小,这表明它可以涵盖更多的文本部分,但它生成的问题更冗长。然而,三个模型在多样性、重叠度、相关性和流畅性方面的数值相似。当包括上下文时,与 GPT-3 相比,GPT-3.5 的覆盖范围略有增加,而 GPT-4 保持了最高的覆盖范围。无上下文配置中,GPT-4 的 Prompt Size 是最大的,表明其能够生成更详细的问题和答案。
在外部上下文设置中,观察到类似的趋势。GPT-4 具有最高的覆盖范围和提示大小,而所有模型在多样性和重叠度方面表现相似。相关性和流畅性在 GPT-4 中略高。
总的来说,无论在哪种上下文设置下,GPT-4 在覆盖范围和提示大小方面通常表现出优越性。三个模型在多样性和重叠度方面表现相似,而 GPT-4 在相关性和流畅性方面稍有优势。
| GPT version | Context | Coverage ↑ | Prompt Size | Diversity ↓ | Overlap ↑ | Relevance ↑ | Fluency ↑ |
|---|---|---|---|---|---|---|---|
| 3 | No context | 3.67 | 12.05 | 1.16 | 1.04 | 4.74 | 4.78 |
| 3.5 | No context | 3.90 | 12.50 | 1.14 | 1.02 | 4.70 | 4.70 |
| 4 | No context | 3.97 | 14 | 1.13 | 0.98 | 4.80 | 4.80 |
| 3 | Context | 3.18 | 18.33 | 0.92 | 1.02 | 4.74 | 4.72 |
| 3.5 | Context | 3.78 | 16.99 | 1.06 | 0.98 | 4.73 | 4.73 |
| 4 | Context | 3.89 | 18.52 | 0.96 | 0.95 | 4.77 | 4.77 |
| 3 | External context | 3.21 | 17.77 | 0.93 | 1.04 | 4.75 | 4.77 |
| 3.5 | External context | 3.83 | 16.36 | 1.06 | 0.98 | 4.75 | 4.75 |
| 4 | External context | 3.97 | 19.44 | 0.93 | 0.96 | 4.81 | 4.81 |
表 13: 对于不同上下文和模型组合计算的指标进行翻译。对于几乎所有指标,更高的数值是可取的,但对于多样性指标,较小的数值表示问题集更加多样化。
此外,针对每个模型来看,对于 GPT-4 来说,没有上下文的设置似乎在平均覆盖范围、多样性、重叠、相关性和流畅性方面提供了最佳平衡,但生成的问答对较短。有上下文的设置会导致较长的问答对,并在大多数指标上略有下降,除了提示大小。外部上下文的设置生成了最长的问答对,保持了平均覆盖范围,并在相关性和流畅性方面略有增加。
因此,选择其中一个模型取决于任务的具体要求。如果不考虑提示的长度,外部上下文可能是最佳选择。在不同的上下文设置中,GPT-3 表现出不同的性能。没有上下文的设置在平均覆盖范围、多样性、重叠、相关性和流畅性方面提供了最佳平衡,但生成的提示最短。当包含上下文时,大多数指标都有所下降,除了提示的大小会增加。与上下文设置相比,外部上下文设置在覆盖范围和多样性方面略有改善,并保持了重叠、相关性和流畅性的稳定性。然而,它生成的提示略短于上下文设置,但长于没有上下文的设置。总体而言,考虑所有指标时,GPT-3 在没有上下文的设置中表现最佳,但生成的提示较短。
对于 GPT-3.5,无上下文设置在多样性、重叠度、相关性和流畅性方面表现出合理的性能,平均提示大小相对较短。当包括上下文时,平均覆盖范围和多样性增加,而平均提示大小减少。与上下文设置相比,外部上下文设置在平均覆盖范围、相关性和流畅性方面略有增加,平均提示大小进一步减少。虽然上下文设置具有最高的平均覆盖范围和多样性,但外部上下文设置在平均相关性和流畅性方面略有增加。对于 GPT-3.5,选择这些设置将取决于具体要求,如果更高的相关性和流畅性得分更受青睐,外部上下文设置可能是最佳选择。
5.1.2 Model to Metrics Calculation
在这里,我们比较了在使用 GPT-3 计算第 4.1 节中提出的指标时,GPT-3.5 和 GPT-4 的行为。结果显示在表 14 中。在这里,所有的问题和答案都是使用 GPT-3 一起生成的。
| Evaluation | Context | Coverage ↑ | Prompt Size | Diversity ↓ | Overlap ↑ | Relevance ↑ | Fluency ↑ |
|---|---|---|---|---|---|---|---|
| GPT-3.5 | No context | 3.67 | 12.05 | 1.16 | 1.04 | 4.74 | 4.78 |
| GPT-3.5 | Context | 3.18 | 18.33 | 0.92 | 1.02 | 4.74 | 4.72 |
| GPT-3.5 | External context | 3.21 | 17.77 | 0.93 | 1.04 | 4.75 | 4.77 |
| GPT-4 | No context | 4.34 | 13.14 | 0.74 | 0.80 | 4.12 | 4.81 |
| GPT-4 | Context | 4.30 | 15.52 | 0.74 | 0.80 | 4.06 | 4.84 |
| GPT-4 | External context | 4.50 | 15.64 | 0.77 | 0.81 | 4.20 | 4.83 |
表 14:使用 GPT-3.5 和 GPT-4 计算时的指标比较
Coverage 衡量了答案在多大程度上可以从提供的上下文中提取出来,与 GPT-3.5 模型相比,GPT-4 模型在所有上下文中都给出了更高的评分。这表明,与 GPT-3.5 相比,GPT-4 可能认为生成的问答更基于可用的上下文。
在 Diversity 方面,GPT-4 在所有上下文中提供了较低的分数。这可能表明与 GPT-3.5 相比,GPT-4 认为生成的问题之间的语义变化较小。观察 Overlap 指标,即评估生成的问题与源文本之间的语义相似性,GPT-4 在所有上下文中给出了较低的分数。这表明 GPT-4 认为问题与源文本之间的语义重叠较小,意味着生成了更多独特的问题。
在 Relevance 方面,即从农民的角度衡量生成问答的信息量,与 GPT-3.5 相比,GPT-4 在所有上下文中给出了较低的分数。最后,Fluency 指标评估生成文本的流畅性和连贯性,GPT-4 在所有上下文中给出了较高的分数。
在考虑这两个模型 GPT-3.5 和 GPT-4 时,最明显的区别之一是它们的性能速度。相比之下,GPT-3.5 的速度要比 GPT-4 快。例如,在使用 Azure OpenAI 时,gpt-35-turbo 和 gpt-35-turbo-16k 每分钟可以生成 24 万到 30 万个 token,具体取决于地区。另一方面,GPT-4 和 GPT-4-32k 根据地区和模型的不同,每分钟生成的 token 数在 2 万到 8 万之间。考虑到这种权衡,大多数问答对生成的指标是使用 GPT-3.5 计算的,而模型评估指标是使用 GPT-4 计算的。
5.1.3 Combined vs Separated Generation
在另一个实验中,我们探索了将问题和答案分别生成与一起生成的好处。这种方法的主要优势是在 token 使用效率方面。通过分别生成问题和答案,使用的 token 较少,这在工作在语言模型的标记限制内时尤为有益。
此外,将问题和答案分别生成打开了使用不同方法或模型处理问答的可能性。例如,可以利用 RAG 模型或微调模型来回答问题,从而不仅仅依赖于基础语言模型。这种灵活性可以实现更加个性化和潜在有效的问答对生成方法。计算的指标见表 15。问答或问题是使用 GPT-4 生成的,指标是使用 GPT-3.5 计算的。
| Generation Method | Context | Coverage ↑ | Diversity ↓ | Overlap ↑ | Relevance ↑ | Fluency ↑ |
|---|---|---|---|---|---|---|
| Combined generation | No context | 3.97 | 1.13 | 0.98 | 4.80 | 4.80 |
| Combined generation | Context | 3.89 | 0.96 | 0.95 | 4.77 | 4.77 |
| Combined generation | External context | 3.97 | 0.93 | 0.96 | 4.81 | 4.81 |
| Only questions | No context | 4.34 | 0.74 | 0.80 | 4.12 | 4.81 |
| Only questions | Context | 4.30 | 0.74 | 0.80 | 4.06 | 4.84 |
| Only questions | External context | 4.50 | 0.77 | 0.81 | 4.20 | 4.83 |
表 15:针对不同的上下文和生成方法组合生成的指标
在评估覆盖范围时,该指标衡量生成内容对所使用的文本的覆盖程度,Only questions 在所有上下文中的表现均优于 combined generation。这表明当任务仅是从文本中生成问题时,模型能够涵盖更多内容。与 only question 相比,combined generation 通常多样性分数更高(表明内容变化较少,参考 4.1 节多样性指标的说明)。
重叠度指标衡量生成内容与源材料之间的相似性,在所有上下文中,combined generation 的重叠度略高。这表明 combined generation 产生的内容与源材料更一致。但这可能是因为生成的内容更长,因此与所使用的文本更相似。
就相关性而言,combined generation 在所有上下文中优于 only questions。这表明生成问题和答案可以产生更与上下文相关的内容。另一方面,我们改变计算相关性的提示,去除了农民的角度。在这种情况下,两种设置的得分非常相似。最后,对于流畅性,即生成内容的可读性和自然性,两种方法在所有上下文中表现相似,表明两种方法都生成非常流畅的内容。
总结起来,Only questions 在覆盖范围和较低的多样性方面表现更好,而 combined generation 在重叠度和相关性方面得分更高。两种方法在流畅性方面表现相似。因此,选择这两种方法之间将取决于任务的具体要求。如果目标是覆盖更多信息并保持更多的多样性,那么 only questions 将是首选。然而,如果要与源材料保持较高的重叠度,combined generation 将是更好的选择。
5.2 Retrieval Ablation Study
在本节中,我们对 RAG 的检索能力进行了消融研究。
我们使用召回率来衡量 RAG 在多大程度上能检索出用于生成数据集中问题的原始内容。这些问题是基于华盛顿州基准数据集的 573 个文档生成的,对于每个问题,我们存储了用作生成依据的文本段落。按照第 2.4 节中介绍的 RAG 设置,我们的目标是检索出包含在给定问题的原始摘录中的片段。在这个背景下,召回率指的是我们能够在给定问题的情况下检索到原始摘录的次数。我们希望召回率更高,因为只要在回答生成过程中提供了正确的上下文,语言模型就能够过滤掉不相关的信息并突出显示关键部分。
首先,我们研究了检索片段数量(即 top-k)的影响,并在表 16 中呈现了结果。通过考虑更多的片段,RAG 能够更一致地恢复原始摘录。此外,当构建 FAISS 索引时,我们将文档分成多个部分,因此片段可能代表原始文档的不同部分,涵盖了在回答生成过程中可能有用的补充信息。基于这一点,我们在本研究的后续实验中考虑 k = 3 个片段,因为它能够在不显著增加输入提示大小的情况下,超过 80% 的情况下可以恢复原始段落。
| Top-k | Recall |
|---|---|
| 1 | 61.9% |
| 2 | 75.0% |
| 3 | 81.5% |
| 5 | 87.8% |
| 10 | 93.6% |
表 16:在不同数量的检索片段(top-k)下的召回率。
为了确保模型能够处理来自不同地理背景和现象的问题,我们可能需要扩展支持文档的语料库,以涵盖各种主题。随着我们考虑更多的文档,我们预计索引的大小会增加。这可能会增加检索过程中相似片段之间的碰撞次数,阻碍我们恢复输入问题的相关信息的能力,从而降低召回率。为了评估这种行为,我们逐步重建 FAISS 索引,添加除华盛顿州以外的其他州的文档。我们计算了华盛顿州基准数据集上的召回率(top-3)。随着文档数量的增加,由于碰撞变得更加常见,召回率会降低。尽管如此,即使索引增加了六倍(从 573 个文档增加到 3888 个文档),仍然在超过 75% 的情况下能检索到相关上下文。
5.3 Fine-tuning
在本节中,我们评估了微调模型与基础指令微调模型的性能。微调模型在从华盛顿州数据集中提取的问题数据集上进行训练,该数据集是一个包含 573 个文档的大型集合,涉及大约 200 万个 token。问题的答案是使用 Llama2-13B-chat 结合 RAG 生成的。评估数据集由 273 个人工整理的样本组成,每个样本都包含一个问题和一个描述期望答案的评估指南。我们为基础模型和微调模型生成了集成和不集成 RAG 的答案,并使用 4.3 节中讨论的指标来评估答案。
对于基础模型,我们评估了开源模型 Llama2-13B-chat 和 Vicuna-13B-v1.5-16k,这两个模型都相对较小。这两个模型都是 Llama2-13B 的微调版本,使用了不同的方法进行微调。Llama2-13B-chat 是通过 SFT 和强化学习(RLHF)进行指令微调的。Vicuna-13B-v1.5-16k 是通过在 ShareGPT 数据集上做 SFT 进行指令微调的。此外,我们还评估了基础的 GPT-4,作为一个更大、更昂贵和更强大的替代方案。对于微调的模型,我们直接在农业数据上对 Llama2-13B 进行微调,以与在更通用任务进行微调的类似模型进行比较。我们还对 GPT-4 进行微调,以评估微调对非常大的模型是否仍然有帮助。
5.3.1 Evaluation with Guideline
评估结果显示,当与 RAG 集成时,GPT-4 是表现最好的模型,获得了 80% 的得分。Vicuna 和 Llama2-chat 13B 紧随其后,分别得分为 79% 和 75%。值得注意的是,在没有集成 RAG 的情况下,GPT-4 和 Llama2-chat 13B 的结果非常相似。在微调模型方面,GPT-4 表现出色,与 RAG 集成时准确率达到 86%,没有 RAG 时为 81%。这些结果强调了 GPT-4 在所有情景下始终表现出色。
5.3.2 Succinctness
为了全面衡量回答的质量,除了准确性外,我们还评估了回答的简洁性。回答可能过长,影响了回答的质量。在各个模型中,集成 RAG 会带来更加简洁的回答,因为回答通常集中在提供的上下文上。GPT-4 + RAG 倾向于提供最简洁的回答。
5.3.3 Correctness
我们还要求 GPT-4 对答案进行评估,看其是否完全正确。与使用指南进行评估类似,我们发现 GPT-4 和 LLama-2-chat 13B 在性能上优于 Vicuna。集成 RAG 后,我们看到所有模型的完全正确答案的百分比大幅增加。与简洁性一样,我们观察到 RAG 将回答集中在最相关的信息子集上。对于 Vicuna 来说,集成 RAG 带来了最大的改进,完全正确的答案从 28% 增加到 56%。精调的 GPT-4 在有或没有 RAG 的情况下表现优于其他模型,分别为 45% 和 61% 的完全正确回答。
5.4 Knowledge Discovery
我们的研究旨在探索通过精调来帮助 GPT-4 学习新知识的潜力。为了测试这一点,我们从美国 50 个州中选择了至少在三个州中相似的问题。然后计算嵌入的余弦相似度,并确定了 1000 个这样的相似问题。这些问题被从训练集中移除,我们使用微调和集成 RAG 的微调来评估 GPT-4 是否能够基于不同州之间的相似性来学习新知识。
我们研究的结果如表 22 所示。数据显示,GPT-4 只能学习到所呈现给它的新知识的 47%。然而,通过精调的帮助,我们能够显著提高这个百分比。具体而言,经过精调的模型能够学习到新知识的最高达到 72% 和 74%,具体取决于是否使用了 RAG。这个上限代表了模型在所呈现的数据下可能学习到的最大新知识量。
| Model | GPT-4 | Fine-tuned | Fine-tuned+RAG |
|---|---|---|---|
| Similar | 47% | 72% | 74% |
| Somewhat similar | 49% | 27% | 25% |
| Not similar | 4% | 1% | 1% |
表 22:基础模型和经过精调的模型(集成和不集成 RAG)的准确性。
6. Conclusion
本研究旨在建立评估 LLM(如 LLama 2、GPT-3.5 和 GPT-4)在农业领域解决复杂问题能力的基准。通过评估它们在集成 RAG 和/或精调时的性能,该研究为农业领域的 LLM 的优势和局限性提供了有价值的见解。
RAG 在改善大型模型的准确性方面表现出色,特别适用于数据在上下文中具有相关性的情况。创建嵌入向量(数据的向量表示)的初始成本较低,使 RAG 成为一个有吸引力的选择。然而,需要考虑到提示 token 大小可能会增加,输出 token 大小倾向于更冗长且更难控制。
另一方面,精调提供了精确而简洁的输出,适合简洁性要求。它非常有效,并提供了在特定领域学习新技能的机会,然而,由于需要在新数据上进行大量工作来进行精调,初始成本较高。此外,精调需要最小的输入 token 大小,使其成为处理大型数据集的更高效选项。表 23 对这两种方法进行了比较。
| Model | RAG | Fine-tuning |
|---|---|---|
| Cost – input token size | Increased Prompt Size | Minimal |
| Cost – output token size | More verbose, harder to steer | Precise, tuned for brevity |
| Initial cost | Low – creating embeddings | High – fine-tuning |
| Accuracy | Effective | Effective |
| New Knowledge | If data is in context | New skill in domain |
表 23:关于 RAG 与微调的见解。
在这项研究中,我们还展示了如何通过利用结构化文档理解、结合 GPT-4 进行问题生成和 RAG 进行答案生成,为特定行业的数据集生成相关的问题和答案。我们的探索表明,分别生成问题和答案可以有效利用 token,从而打开了在 Q&A 配对的每个组成部分使用不同模型或方法的可能性。我们还提出了一系列度量标准,以正确评估生成的问题与原始文档中包含的信息之间的质量,并展示了用于衡量 RAG 生成答案质量的多个度量标准。 随着我们的研究进展,不断完善对不同 LLM 能力的理解,包括 RAG 和精调,是至关重要的。