本文是《Foundations-of-LLMs》 第二章【大语言模型架构】的笔记。
大数据 + 大模型 → 新智能
Kaplan-McCandlish 扩展法则
2020 年,OpenAI 团队的 Jared Kaplan 和Sam McCandlish 等人首次探究了神经网络的性能与数据规模 $D$ 以及模型规模 $N$ 之间的函数关系。他们在不同规 模的数据集(从 2200 万到 230 亿个 Token)和不同规模的模型下(从 768 到 15 亿个参数)进行实验,并根据实验结果拟合出了两个基本公式:
\[\begin{aligned} L(D) &= \left(\frac{D}{D_c} \right)^{\alpha_D}, \alpha_D \sim -0.095, D_c \sim 5.4 \times 10^{13} \\ L(N) &= \left(\frac{N}{N_c} \right)^{\alpha_N}, \alpha_N \sim -0.076, D_c \sim 8.8 \times 10^{13} \end{aligned}\]$L(N)$ 表示在数据规模固定时,不同模型规模下的交叉熵损失函数,反映了模型规模对拟合数据能力的影响。相应地,$L(D)$ 表示在模型规模固定时,不同数据规模下的交叉熵损失函数,揭示了数据量对模型学习的影响。$L$ 的值衡量了模型拟合数据分布的准确性,值越小表明模型对数据分布的拟合越精确。
实验结果和相关公式表明,模型的性能与模型以及数据规模这两个因素均高度正相关。然而,在模型规模相同的情况下,模型的具体架构对其性能的影响相对较小。因此,扩大模型规模和丰富数据集成为了提升大型模型性能的两个关键策略。
此外,OpenAI 在进一步研究计算预算的最优分配时发现,总计算量 $C$ 与数据量 $D$ 和模型规模 $N$ 的乘积近似成正比,即 $C \approx 6ND$。在这一条件下,如果计算预算增加,为了达到最优模型性能,数据集的规模D 以及模型规模 $N$ 都应同步增加。但是模型规模的增长速度应该略快于数据规模的增长速度。具体而言,两者的最优配置比例应当为 $N_{opt} \propto C^{0.73}, D_{opt} \propto C^{0.27}$。这意味着,如果总计算预算增加了 10 倍,模型规模应扩大约 5.37 倍,而数据规模应扩大约 1.86 倍,以实现模型的最佳性能。
Chinchilla 扩展法则
谷歌旗下 DeepMind 团队对“模型规模的增长速度应该略高于数据规模的增长速度”这一观点提出了不同的看法。在 2022 年,他们对更大范围的模型规模(从 7000 万到1600 亿个参数)以及数据规模(从 50 亿到 5000 亿个 Token)进行了深入的实验研究,并据此提出了 Chinchilla 扩展法则:
\[L(N, D) = E + \frac{A}{N^{\alpha}} + \frac{B}{D^{\beta}}\]其中 $E=1.69, A=406.4, B=410.7, \alpha=0.34, \beta=0.28$。
DeepMind 同样探索了计算预算的最优分配问题,最终得出数据集规模 $D$ 与模型规模 $N$ 的最优配置为 $N_{opt} \propto C^{0.46}, D_{opt} \propto C^{0.54}$。这一结果表明,数据集量 $D$ 与 模型规模 $N$ 几乎同等重要,如果总计算预算增加了 10 倍,那么模型规模以及数据规模都应当扩大约 3.16 倍。谷歌后续在 2023 年5 月发布的 PaLM 2 的技术报告中也再次证实了这一观点,进一步强调了数据规模在提升模型性能中的重要性。
此外,Chinchilla 扩展法则进一步提出,理想的数据集大小应当是模型规模的 20 倍。例如,对于一个 7B(70 亿参数)的模型,最理想的训练数据集大小应为 140B(1400 亿)个 Token。但先前很多模型的预训练数据量并不够,例如 OpenAI 的 GPT-3 模型的最大版本有 1750 亿参数,却只用了 3000 亿 Token 进行训练。因此,DeepMind 推出了数据规模 20 倍于模型规模的 Chinchilla 模型(700亿参数,1.4 万亿 Token),最终在性能上取得了显著突破。
DeepMind 提出的 Chinchilla 扩展法则是对OpenAI 先前研究的补充和优化,强调了数据规模在提升模型性能中的重要性,指出模型规模和数据规模应该以相同 的比例增加,开创了大语言模型发展的一个新方向:不再单纯追求模型规模的增加,而是优化模型规模与数据规模的比例。
大语言模型架构概览
在语言模型的发展历程中,Transformer 框架的问世代表着一个划时代的转折点。Self-Attention 机制极大地提升了模型对序列数据的处理能力,在捕捉长距离依赖关系方面表现尤为出色。此外,Transformer 框架对并行计算的支持极大地加速了模型的训练过程。当前,绝大多数大语言模型均以 Transformer 框架为核心,并进一步演化出了三种经典架构,分别是 Encoder-only 架构,Decoder-only 架构以及 Encoder-Decoder 架构。
Encoder-only 架构
Encoder-only 架构仅选取了 Transformer 中的编码器(Encoder)部分,用于接收输入文本并生成与上下文相关的特征。具体来说,Encoder-only 架构包含三个部分,分别是输入编码,特征编码以及任务处理。其中输入编码部分包含分词、向量化以及添加位置编码三个过程。而特征编码部分则是由多个相同的编码模块(Encoder Block)堆叠而成,其中每个编码模块包含自注意力模块(Self-Attention)和全连接前馈模块。任务处理模块是针对任务需求专门设计的模块,由用户针对任务需求自行设计。
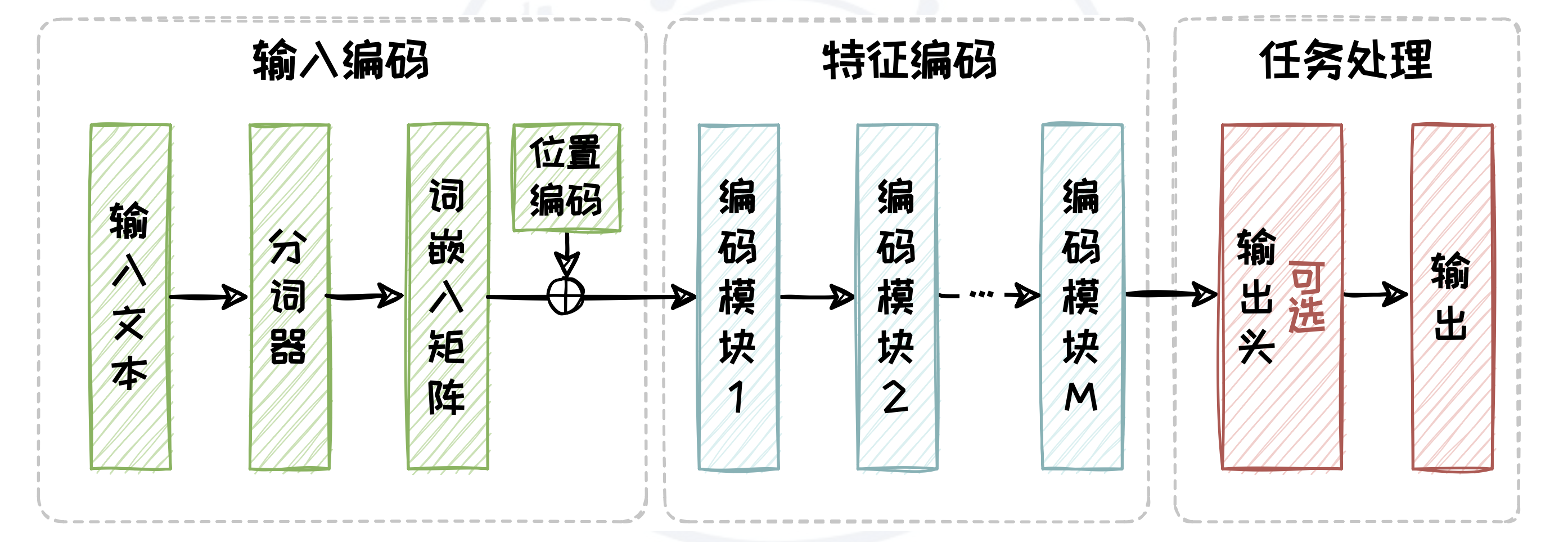
Encoder-only 架构模型的预训练阶段和推理阶段在输入编码和特征编码部分是一致的,而任务处理部分则需根据任务的不同特性来进行定制化的设计。
在输入编码部分,原始输入文本会被分词器(Tokenizer)拆解为 Token 序列,随后通过词表和词嵌入(Embedding)矩阵映射为向量序列,确保文本信息得以数字化表达。为了保留文本中单词的顺序信息,每个向量序列会被赋予位置编码(Positional Encoding)。在特征编码部分,先前得到的向量序列会依次通过一系列编码模块,这些模块通过自注意力机制和前馈网络进一步提取和深化文本特征。
任务处理部分在预训练阶段和下游任务适配阶段一般有所差别。在预训练阶段,模型通常使用全连接层作为输出头,用于完成掩码预测等任务。而在下游任务适配阶段,输出头会根据具体任务需求进行定制。例如分类等判别任务只需要添加一个分类器。但对于生成任务,则需要添加一个全连接层,逐个预测后续的 Token。但以这种形式来完成生成任务存在着诸多的限制,例如在每次生成新的 Token 时,都需要重新计算整个输入序列的表示,这增加了计算成本,也可能导致生成的文本缺乏连贯性。
Encoder-Decoder 架构
为了弥补 Encoder-only 架构在文本生成任务上的短板,Encoder-Decoder 架构在其基础上引入了一个解码器(Decoder),并采用交叉注意力机制来实现编码器与解码器之间的有效交互。
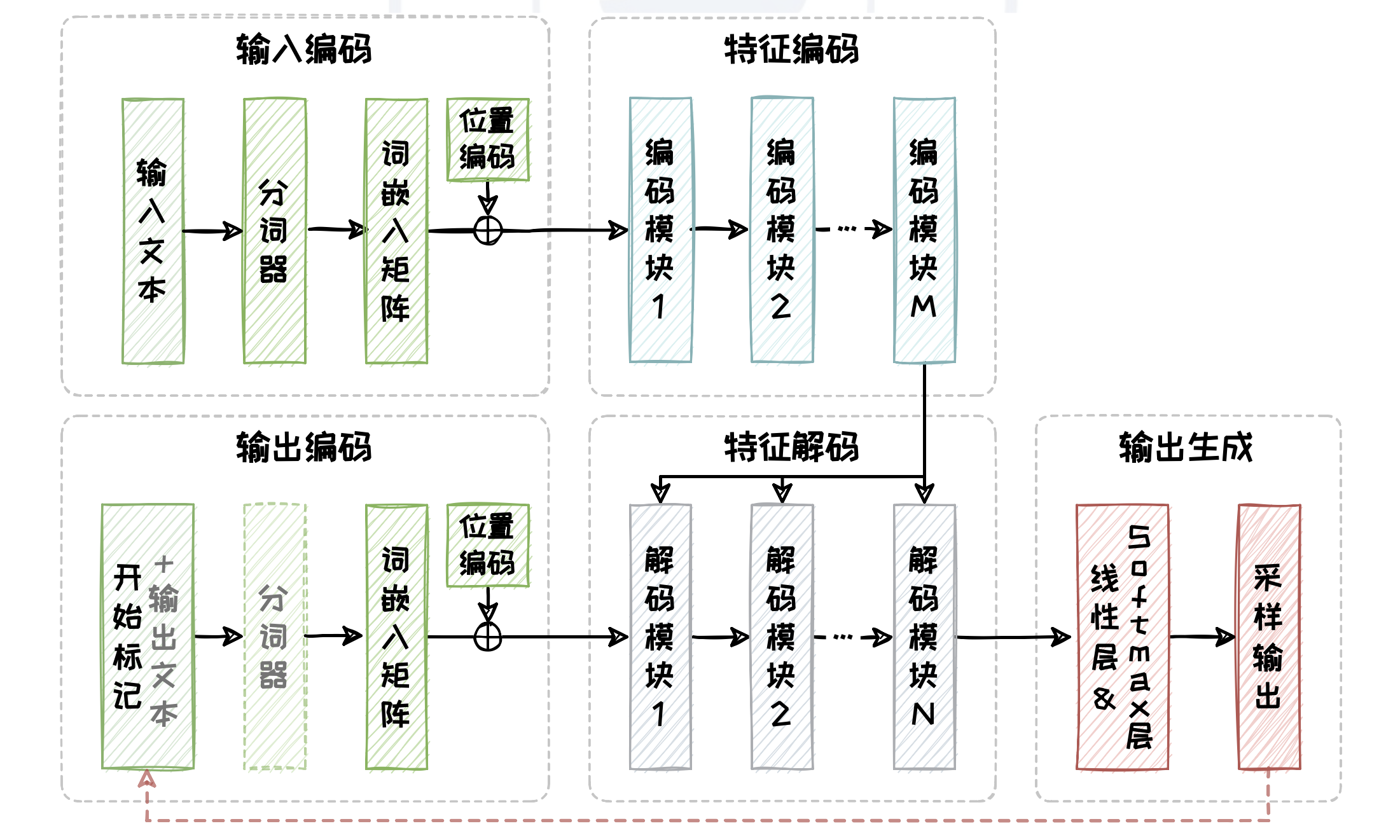
图:Encoder-Decoder 架构。分词器和输出文本只在训练阶段存在,而实现“自回归”的红色虚线只在推理阶段存在。
解码器包含了输出编码、特征解码以及输出生成三个部分。其中输出编码与编码器中的输入编码结构相同,包含分词、向量化以及添加位置编码三个过程。此外,特征解码部分与特征编码部分在网络结构上也高度相似,包括掩码自注意力(Masked Self-Attention)模块,交叉注意力模块和全连接前馈模块。交叉注意力模块负责处理从编码模块向解码模块传递相关信息。输出生成部分则由一个线性层以及一个Softmax 层组成,负责将特征解码后的向量转换为词表上的概率分布,并从这个分布中采样得到最合适的 Token 作为输出。
Decoder-only 架构
Decoder-only 架构模型仅使用解码器来构建语言模型,采用“自回归”机制生成文本。
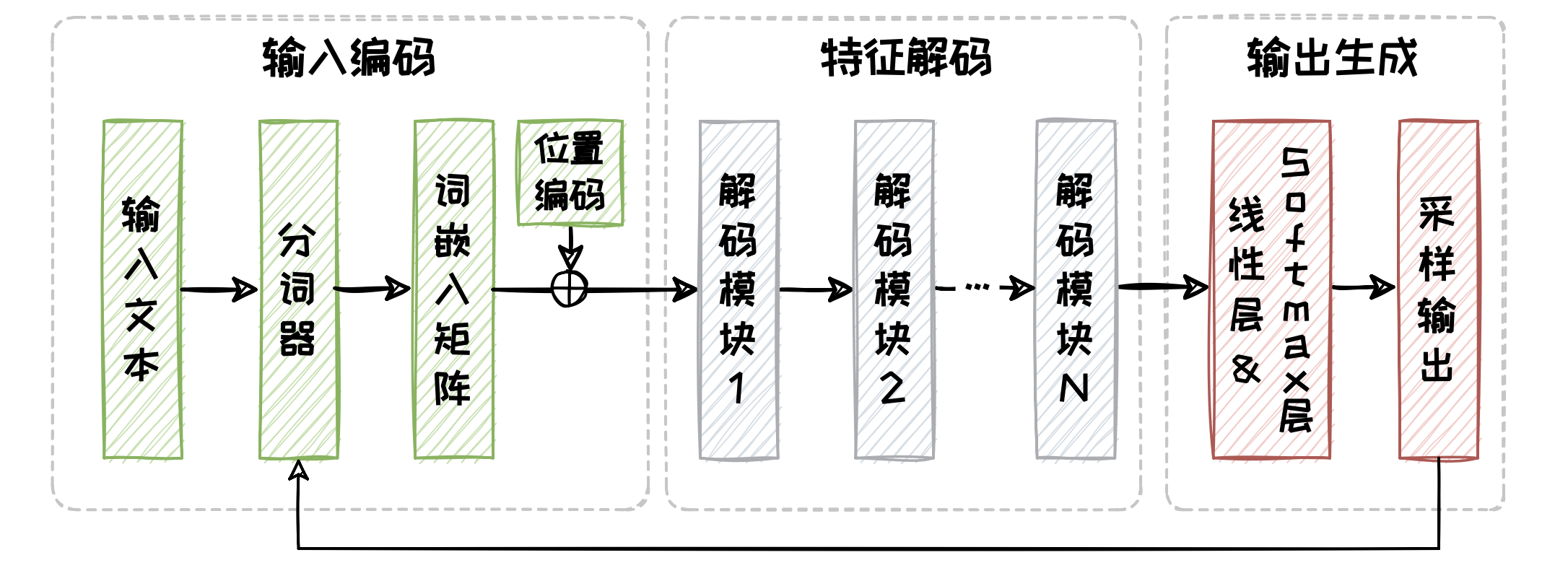
Decoder-only 架构同样包含了三个部分,分别是输入编码、特征解码以及输出生成。Decoder-only 架构的核心特点在于省略了每个编码模块中的交叉注意力子模块。
基于 Encoder-only 架构的大语言模型
Encoder-only 架构的核心在于双向编码模型(Bidirectional Encoder Model)。在处理输入序列时,双向编码模型能充分捕捉每个 Token 的上下文信息。得益于其上下文感知能力和动态表示的优势,双向编码器显著提升了自然语言处理任务的性能。不同于先前常用的 Word2Vec 和 GloVe 此类的静态编码方式,双向编码器为每个词生成动态的上下文嵌入(Contextual Embedding),使模型能够更加精准地理解词与词之间的依赖性和语义信息,有效处理词语的多义性问题。
BERT 语言模型
BERT 模型有 BERT-Base 和 BERT-Large 两个版本。其中 BERT-Base 由 12 个编码模块堆叠而成,隐藏层维度为 768,自注意力头的数量为 12,总参数数量为 1.1 亿;BERT-Large 由 24 个编码模块堆叠而成,隐藏层维度为 1024,自注意力头的数量为 16,总参数数量约为 3.4 亿。
BERT 使用小说数据集 BookCorpus(包含约 8 亿个 Token)和英语维基百科数据集(包含约 25 亿个 Token)进行预训练,总计约 33 亿个 Token,总数据量达到了 15GB 左右。在预训练任务上,BERT 开创性地提出了掩码语言建模(Masked Language Model, MLM)和下文预测(Next Sentence Prediction, NSP)两种任务来学 习生成上下文嵌入。
由于 BERT 的输出是输入中所有 Token 的向量表示,总长度不固定,无法直接应用于各类下游任务。为了解决这一问题,BERT 设计了 [CLS] 标签来提取整个输入序列的聚合表示。[CLS] 标签是专门为分类和汇总任务设计的特殊标记。其全称是 “Classification Token”,即分类标记。通过注意力机制,[CLS] 标签汇总整个输入序列的信息,生成一个固定长度的向量表示,从而实现对所有 Token 序列信息的概括,便于处理各种下游任务。
BERT 衍生语言模型
RoBERTa 语言模型
RoBERTa (Robustly Optimized BERT Pretraining Approach)由 Facebook AI 研究院于 2019 年 7 月提出,旨在解决 BERT 在训练程度上不充分这一问题。RoBERTa 在 BERT 的基础上采用了更大的数据集(包括更多的英文书籍、维基百科和其他网页数据)、更长的训练时间(包括更大的批次大小和更多的训练步数)以及更细致的超参数调整(包括学习率、训练步数等的设置)来优化预训练的过程,
RoBERTa 同样有两个版本,分别是 RoBERTa-Base 和 RoBERTa-Large。其中 RoBERTa-Base 与BERT-Base 对标,由 12 个编码模块堆叠而成,其中隐藏层维度为 768,自注意力头的数量为 12,总参数数量约为 1.2 亿;RoBERTa-Large 则与 BERT-Large 对标,由 24 个编码模块堆叠而成,其中隐藏层维度为 1024,自注意力头的数量为 16,总参数数量约为 3.5 亿。
RoBERTa 在 BERT 原有的基础上,添加了新闻数据集 CC-News(包含约 76GB 的新闻文章)、网页开放数据集 OpenWebText(包含约 38GB 的网页文本内容)以及故事数据集 Stories(包含约 31GB 的故事文本),总数据量达到约 160GB。
RoBERTa 移除了 BERT 中的下文预测任务,并将 BERT 原生的静态掩码语言建模任务更改为动态掩码语言建模。RoBERTa 将训练数据复制成10 个副本,分别进行掩码。在同样训练 40 个 epoch 的前提下,BERT 在其静态掩码后的文本上训练了40 次,而 RoBERTa 将 10 个不同掩码后的副本分别训练了 4 次,从而增加模型训练的多样性,有助于模型学习到更丰富的上下文信息。
ALBERT 语言模型
ALBERT (A Lite BERT)是由 Google Research 团队于 2019 年 9 月提出的轻量级 BERT 模型,旨在通过参数共享和嵌入分解技术来减少模型的参数量和内存占用,从而提高训练和推理效率。ALBERT 在设计过程通过参数因子分解技术和跨层参数共享技术显著减少了参数的数量。
在 BERT 中,Embedding 层的输出向量维度 $E$ 与隐藏层的向量维度 $H$ 是一致的,这意味着 Embedding 层的输出直接用作后续编码模块的输入。BERT-Base 模型对应的词表大小 $V$ 为 3,0000 左右,并且其隐藏层的向量维度 $H$ 设置为 768。因此,BERT 的 Embedding 层需要的参数数量是 $V \times H$,大约为 2,304 万。
ALBERT 将 Embedding 层的矩阵先进行分解,将词表对应的独热编码向量通过一个低维的投影层下投影至维度 $E$,再将其上投影回隐藏状态的维度 $H$。具体来说,ALBERT 选择了一个较小的 Embedding 层维度,例如 128,并将参数数量拆解为 $V \times E + E \times H$。按照这个设计,ALBERT 的 Embedding 层大约需要 394 万个参数,大约是 BERT 参数数量的六分之一。对于具有更大隐藏层向量维度 $H$ 的 Large 版本,ALBERT 节省参数空间的优势更加明显,能够将参数量压缩至 BERT 的八分之一左右。
ELECTRA 语言模型
LECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)是由 Google Brain 和斯坦福大学的研究人员于 2020 年 3 月提出的另一种 BERT 变体,旨在解决大规模预训练语言模型中的效率和可扩展性问题。通过使用生成器-判别器架构,ELECTRA 能够更高效地利用预训练数据,提高了模型在下游任务中的表现。
ELECTRA 在 BERT 原有的掩码语言建模基础上结合了生成对抗网络(Generative Adversarial Network, GAN)的思想,采用了一种生成器-判别器结构。具体来说,ELECTRA 模型包含一个生成器和一个判别器,其中生成器(Generator)是一个能进行掩码预测的模型(例如 BERT 模型),负责将掩码后的文本恢复原状。而判别器(Discriminator)则使用替换词检测(Replaced Token Detection, RTD)预训练任务,负责检测生成器输出的内容中的每个 Token 是否是原文中的内容。
基于 Encoder-Decoder 架构的大语言模型
Encoder-Decoder 架构在 Encoder-only 架构的基础上引入 Decoder 组件,以完成机器翻译等序列到序列(Sequence to Sequence, Seq2Seq)任务。
Encoder-Decoder 架构主要包含编码器和解码器两部分。模型的输入序列在通过编码器部分后会被转变为固定大小的上下文向量,这个向量包含了输入序列的丰富语义信息。交叉注意力通过将解码器的查询(query)与编码器的键(key)和值(value)相结合,实现了两个模块间的有效信息交流。
T5 语言模型
Google Research 团队在 2019 年 10 月提出了一种基于 Encoder-Decoder 架构的大型预训练语言模型 T5 (Text-to-Text Transfer Transformer)。T5 模型的核心思想是将多种 NLP 任务统一到一个文本转文本的生成式框架中。在此统一框架下,T5 通过不同的输入前缀来指示模型执行不同任务,然后生成相应的任务输出。这种方法可以视为早期的提示(Prompt)技术的运用,通过构造合理的输入前缀,T5 模型能够引导自身针对特定任务进行优化,而无需对模型架构进行根本性的改变。这种灵活性和任务泛化能力显著提高 了模型的实用性,使其能够轻松地适应各类新的 NLP 任务。
与 BERT 模型中采用的单个 Token 预测不同,T5 模型需要对整个被遮挡的连续文本片段进行预测。这些片段可能包括连续的短语或子句,它们在自然语言中构成了具有完整意义的语义单元。这一设计要求模型不仅等理解局部词汇的表面形式,还要可以捕捉更深层次的句子结构和上下文之间的复杂依赖关系。
基于预训练阶段学到的大量知识以及新提出的文本转文本的统一生成式框架,T5 模型可以在完全 Zero-Shot 的情况下,利用 Prompt 工程技术直接适配到多种下游任务。同时,T5 模型也可以通过微调来适配到特定的任务。
基于 Decoder-only 架构的大语言模型
在开放式(Open-Ended)生成任务中,通常输入序列较为简单,甚至没有具体明确的输入,因此维持一个完整的编码器来处理这些输入并不是必要的。对于这种任务,Encoder-Decoder 架构可能显得过于复杂且缺乏灵活性。
Decoder-only 架构通过自回归方法逐字生成文本,不仅保持了长文本的连贯性和内在一致性,而且在缺乏明确输入或者复杂输入的情况下,能够更自然、流畅地生成文本。此 外,Decoder-only 架构由于去除了编码器部分,使得模型更加轻量化,从而加快了训练和推理的速度。
GPT 系列语言模型
GPT (Generative Pre-trained Transformer)的演进历程可以划分为五个阶段,从表中可以明显看出,GPT 系列模型参数规模与预训练语料规模呈现出激增的趋势。
| 模型 | 发布时间 | 参数量(亿) | 语料规模 |
|---|---|---|---|
| GPT-1 | 2018.06 | 1.17 | 约 5GB |
| GPT-2 | 2019.02 | 1.24 / 3.55 / 7.74 / 15 | 40GB |
| GPT-3 | 2020.05 | 1.25 / 3.5 / 7.62 / 13 / 27 / 67 / 130 / 1750 | 1TB |
| ChatGPT | 2022.11 | 未知 | 未知 |
| GPT-4 | 2023.03 | 未知 | 未知 |
| GPT-4o | 2024.05 | 未知 | 未知 |
InstructGPT 等模型
InstructGPT(ChatGPT 的前身)通过引入了人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF),显著提升了模型对用户指令的响应能力。
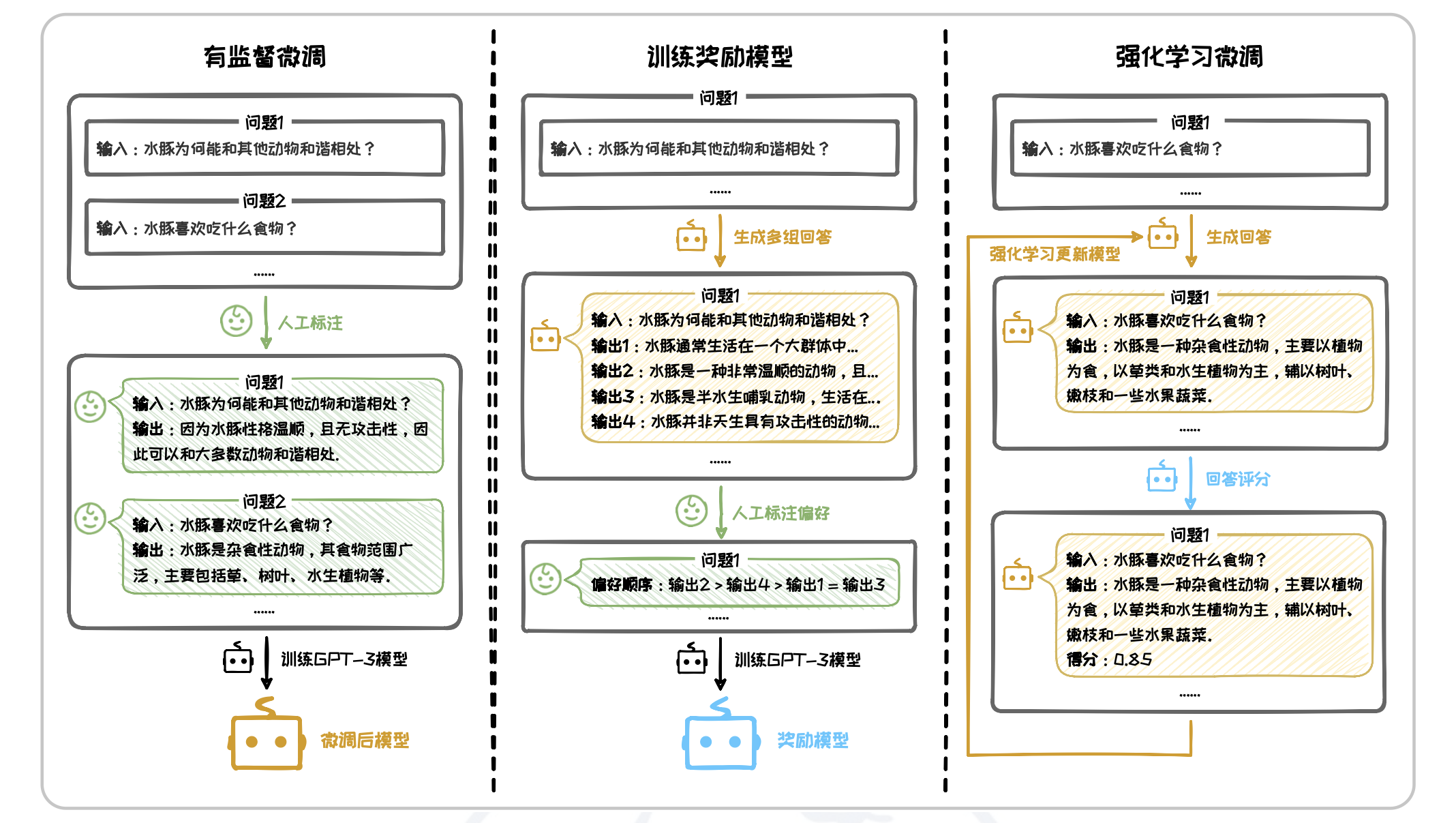
在人类反馈强化学习中,人类评估者首先提供关于模型输出质量的反馈,然后使用这些反馈来微调模型。具体过程如下图,整体可以分为以下三个步骤:
- 有监督微调:收集大量“问题-人类回答”对作为训练样本,对大语言模型进行微调。
- 训练奖励模型:针对每个输入,让模型生成多个候选输出,并由人工对其进行质量评估和排名,构成偏好数据集。用此偏好数据集训练一个奖励模型,使其可以对输出是否符合人类偏好进行打分。
- 强化学习微调:基于上一步中得到的奖励模型,使用强化学习方法优化第一步中的语言模型,即在语言模型生成输出后,奖励模型对其进行评分,强化学习算法根据这些评分调整模型参数,以提升高质量输出的概率。
RLHF 的缺点是计算成本十分高昂,主要是由于:1)奖励模型的训练过程复杂且耗时。2)不仅需要单独训练语言模型和奖励模型,还需要协调这两个模型进行多模型联合训练。为了克服 RLHF 在计算效率上的缺陷,斯坦福大学在 2023 年在其基础上,提 出了一种新的算法直接偏好优化(Direct Preference Optimization, DPO)。DPO 算法直接利用人类偏好数据来训练模型。首先收集包含多个响应的人类偏好数据,并从中标记出最优和次优响应。然后微调模型以提高模型选择最优响应的概率,同时降低选择次优响应的概率。这种方法显著简化了人类反馈对齐的流程,提高了训练效率和模型稳定性。
LLAMA 系列语言模型
LLaMA (Large Language Model Meta AI)是由 Meta AI 开发的一系列大语言模型。
LLaMA1 模型
在模型架构方面,LLaMA1 采用了与 GPT 系列同样的网络架构。但是,其在 Transformer 原始词嵌入模块、注意力模块和全连接前馈模块上进行了优化。在词嵌入模块上,为了提高词嵌入质量,LLaMA1 参考了 GPTNeo 的做法,使用旋转位置编码(Rotary Positional Embeddings, RoPE)替代了原有的绝对位置编码,从而增强位置编码的表达能力,增强了模型对序列顺序的理解。在注意力模块上,LLaMA1 参考了PaLM 的做法,将 Transformer 中的 RELU 激活函数改为 SwiGLU 激活函数。并且,LLaMA1 在进行自注意力操作之前对查询(query)以及键(key)添加旋转位置编码。在全连接前馈模块上,LLaMA1 借鉴了 GPT-3 中的 Pre-Norm 层正则化策略,将正则化应用于自注意力和前馈网络的输入。
LLaMA2 模型
预训练阶段之后,LLaMA2 采纳了人类反馈强化学习的方法,进一步提升了模型的性能。首先,其使用了大规模且公开的指令微调数据集 对模型进行有监督的微调。然后,LLaMA2 还训练了RLHF 奖励模型,并基于近似策略优化(Proximal Policy Optimization, PPO)以及拒绝采样(Rejection Sampling)进行强化学习。
LLaMA2-34B 和 LLaMA2-70B 还额外增加了分组查询注意力(Grouped Query Attention, GQA),以提升计算效率。
LLaMA3 模型
在模型架构上,LLaMA3 与前一代 LLaMA2 几乎完全相同,只是在分词(tokenizer)阶段,将字典长度扩大了三倍,极大提升了推理效率。这一改进减少了中文字符等语言元素被拆分为多个 Token 的情况,有效降低了总体 Token 数量,从而提高了模型处理语言的连贯性和准确性。另一方面,扩大的字典有助于减少对具有完整意义的语义单元进行分割,使模型在处理文本时可以更准确的捕捉词义和上下文,提高生成文本的流畅性和连贯性。