本文是《Foundations-of-LLMs》 第五章【模型编辑】的笔记。
预训练大语言模型中,可能存在偏见、毒性、知识错误等问题。为了纠正这些问题,可以用清洗过的数据重新进行预训练,但成本过高。也可对大语言模型“继续教育”——利用高效微调技术向大语言模型注入新知识,但因为新知识相关样本有限,容易诱发过拟合和灾难性遗忘。为此,仅对模型中的特定知识点进行修正的模型编辑技术应运而生。
模型编辑简介
偏见是指模型生成的内容中包含刻板印象和社会偏见等不公正的观点,毒性是指模型生成的内容中包含有害成分,而知识错误则是指模型提供的信息与事实不符。
与重新预训练和微调方法不同的是,模型编辑期望能更加快速、精准地实现对于模型特定知识点的修正。
模型编辑领域尚缺乏统一标准,不同研究对相关概念的定义各不相同。本书将不同工作中提到的基于知识的模型编辑(KME, Knowledge Model Editing)和知识编辑(KE, Knowledge Editing)等概念统一为模型编辑(ME, Model Editing)。此外,有些研究用“编辑”(edit) 或“事实”(fact)来表示具体的编辑对象,本书将这些概念统一为“知识点”。
模型编辑的目标可被归纳为:修正大语言模型使其输出期望结果,同时不影响其他无关输出。本书将模型编辑定义如下:
将编辑前模型定义为 $M$,编辑后模型定义为 $M^*$。每一次编辑都修改模型的一个知识点 $k$,知识点 $k$ 由问题 $x_k$ 及其对应的答案 $y_k$ 组成。那么,模型编辑的目标可以表示为以下函数:
\[M^*(x) = \begin{cases} y_k, & \text{若 } x = x_k \text{ 或 } x \text{ 与 } x_k \text{ 相关,} \\ M(x), & \text{若 } x \text{ 与 } x_k \text{ 无关。} \end{cases}\]上述定义中有关“相关”和“无关”的判断,涉及到模型编辑的范围问题,如何精确控制模型编辑的范围是一个关键挑战。
本书根据已有工作,将模型编辑的性质归纳为五个方面,分别为准确性(Accuracy)、泛化性(Generality)、可迁移性(Portability)、局部性(Locality)和高效性(Efficiency) 。
- 准确性:准确性衡量对某个知识点k 的直接修改是否有效。
- 泛化性:泛化性用来衡量编辑后模型能否适应目标问题 $x_k$ 的其他表达形式。研究者通常会构造一个泛化性数据集 $D_G = \{(x_i, y_k)\}_{i=1}^{|DG|}$,其中 $x_i$ 是与 $x_k$ 具有语义相似性的问题,它们的答案都为 $y_k$。
- 可迁移性:可迁移性是指编辑后模型将特定知识点 $k$ 迁移到其它相关问题上的能力。通过构造可迁移性数据集(与 $x_k$ 相关但答案不是 $y_k$),评估模型对与 $k$ 间接相关的问题的适应能力。
- 局部性:局部性要求编辑后的模型不影响其他不相关问题的输出。通过构造局部性数据集(与 $x_k$ 无关的问题)来量化编辑后模型的局部性。
- 高效性:高效性主要考虑模型编辑的时间成本和资源消耗。
模型编辑经典方法
本文参考已有工作,将现有编辑方法分为外部拓展法和内部修改法。
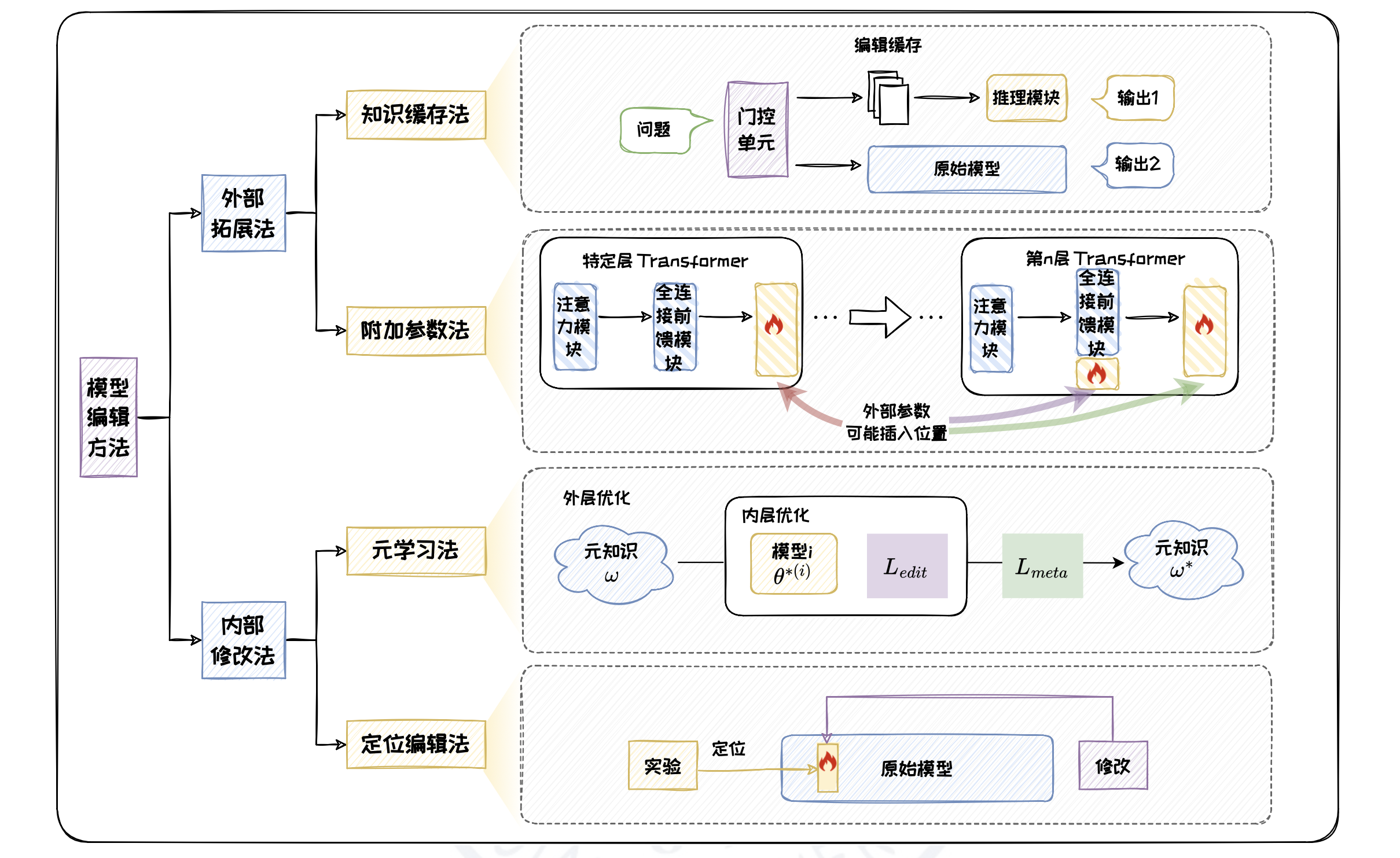
外部拓展法
外部拓展法的核心思想是将新知识存储在附加的外部参数或外部知识库中,将其和原始模型一起作为编辑后模型。该方法不会改变原始模型参数,可降低对模型内部预训练知识的干扰。根据外部组件是否直接整合进模型本身的推理过程,外部拓展法又可划分为知识缓存法和附加参数法。
知识缓存法
知识缓存法中包括三个主要组件,分别为门控单元、编辑缓存和推理模块。编辑缓存充当一个知识存储库,用于保存需要修改的知识,这些知识由用户通过不同的形式指定。门控单元用于判断输入问题与编辑缓存中的知识的相关程度,可通过分类或噪声对比估计等任务进行训练。推理模块获取原始输入问题和编辑缓存中的知识作为输入,通过监督训练的方式学习预测用户期望的结果。
编辑缓存中知识点的存储形式可以分为事实知识、自然语言补丁和正则表达式三种。事实知识以问题-答案对 $(x_k, y_k)$ 存储编辑实例,这种存储形式适用于答案明确的事实性问题,SERAC 是一种代表性方法。自然语言补丁 Language Patch 按照“如果⋯⋯那么⋯⋯”的句式描述编辑知识,类似于 Prompt。这种存储形式适用于修正模型对自然语言中非字面含义语句的理解。正则表达式是一种基于文本匹配和替换的技术,它使用特定的模式来识别和修改文本中的特定部分,适用于精确的文本语义替换。由于编写复杂、泛化性低,因此在模型编辑中并不常用。
知识缓存法直接通过编辑缓存中的信息进行检索,不依赖目标标签的梯度信息,因此可以简化模型编辑过程,使其更加高效直接。然而,这种从外界获取知识的方式相当于在让大语言模型进行求助,而并非将新的知识真正内化为自己的一部分。附加参数法对这种局限进行了改良。
附加参数法
与知识缓存法相比,附加参数法可以将外部参数整合进模型结构,从而有效利用和扩展模型的功能。这类方法的思想与参数高效微调中的参数附加方法类似,都是将外部参数插入到模型中的特定位置,冻结原始模型,只训练新引入的参数以修正模型输出。
CALINET 和 T-Patcher 通过修改模型最后一层 Transformer 的全连接前馈模块来实现。CALINET 首先通过一种对比知识评估方法找出原始模型的知识错误,然后在模型最后一个全连接前馈模块添加一个新的参数矩阵,并通过最小化校准数据上的损失来训练新参数,以纠正模型的错误。T-Patcher 与此类似,同样是在原始模型的最后一个全连接前馈模块引入有限数量的可训练神经元,每个神经元对应一个知识点。
GRACE 则将外部参数以适配器的形式插入模型的特定 Transformer 层中,插入位置随模型变化而变化。其中,适配器是一个用于缓存错误知识(Keys)和对应的修正值(Values)的键值存储体,被称作“codebook”。在 codebook 中,每个错误知识都有一个对应的修正值,以及一个用于匹配相似输入的延迟半径,且随着时间的推移,codebook 会被持续更新。延迟半径用于判断当前输入是否与 codebook 中的任何错误相似,如果是,则应用相应的修正值进行编辑。
内部修改法
内部修改法旨在通过更新原始模型的内部参数来为模型注入新知识。内部修改法又可以分为元学习法和定位编辑法。元学习法通过“学习如何学习”来获取元知识,再基于元知识实现模型编辑;定位编辑法则专注于对模型局部参数的修改,首先识别与目标知识最相关的模型参数,然后仅更新这些特定参数,通过“先定位后编辑”的策略节省更新模型所需成本。
元学习法
元学习指的是模型“学习如何学习”(Learning to Learn)的过程。基于元学习的模型编辑方法,旨在让模型“学习如何编辑”(Learning to Edit),核心思想是使模型从一系列编辑任务中提取通用的知识,并将其应用于未见过的编辑任务,这部分知识被称为元知识 ω。元知识是模型在进行编辑前可以利用的知识,包括优化器参数、超网络等多种形式。元知识的训练过程被称为元训练,其目标是获得一个较好的元知识 ω,使得后续的每次编辑只需少量样本即可快速收敛。
定位编辑法
与元学习法相比,定位编辑法修改的是原始模型的局部参数。其先定位到需要修改的参数的位置,然后对该处的参数进行修改。实现定位前需要了解大语言模型中知识的存储机制。论文 《Transformer Feed-Forward Layers Are Key-Value Memories》 中提出,Transformer 中的全连接前馈模块可以看作存储知识的键值存储体。基于上述结论,KN 提出了知识神经元的概念。其将全连接前馈模块的每个中间激活值定义为一个知识神经元,并认为知识神经元的激活与相应知识点的表达密切相关。为了评估每个神经元对于特定知识预测的贡献,KN 将有关该知识点的掩码文本输入给预训练模型,获取隐藏状态后,将其输入到模型每一层的 FFN 中,通过归因方法,积累每个神经元在预测正确答案时的梯度变化,从而确定哪些神经元在知识表达过程中起关键作用。在确定了知识神经元对于知识预测的贡献后,可以通过直接在模型中修改特定知识神经元对应的键向量,来诱导模型输出的编辑后的知识,从而达到模型编辑的效果。
ROME 设计了一种因果跟踪实验,进一步探索中间层全连接前馈模块与知识的关系,优化了知识存储机制的结论。在编辑方法上,与定位和编辑全连接前馈模块中的单个神经元的 KN 不同,ROME 提出更新整个全连接前馈模块来进行编辑。ROME 是近年来备受瞩目的模型编辑方法,为未来的模型编辑和优化工作提供了重要的参考和指导。