本文是《RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation》 的笔记。
检索增强生成(Retrieval-Augmented Generation,RAG)通过整合大型语言模型(LLMs)和外部知识数据库,在各种自然语言处理任务中展示了显著的改进。然而,RAG 引入了长序列生成,导致计算和内存成本较高。我们提出了 RAGCache,这是一个专为 RAG 定制的新型多级动态缓存系统。我们的分析评估了当前 RAG 系统,确定了性能瓶颈(即由于知识注入导致的长序列)和优化机会(即缓存知识的中间状态)。基于这些见解,我们设计了 RAGCache,它将检索到的知识的中间状态组织成一个知识树,并将其缓存在 GPU 和主机内存层次结构中。RAGCache 提出了一种替换策略,其理解 LLM 推理特性和 RAG 检索模式,并动态地重叠(overlap)检索和推理步骤,以最小化端到端时延。我们实现了 RAGCache,并在 vLLM 和 Faiss 上进行了评估。实验结果显示,与集成 Faiss 的 vLLM 相比,RAGCache 将首个标记的时间(TTFT)缩短了最多 4 倍,并将吞吐量提高了最多 2.1 倍。
Introduction
最近专注于 LLM 推理系统的优化的研究,在共享 LLM 推理的中间状态方面取得了显著进展,以减少重新计算的成本。vLLM 将中间状态管理在非连续的内存块中,以允许对单个请求的多次生成迭代进行细粒度的内存分配和状态共享。SGLang 识别了 LLM 应用中不同请求之间可重用的中间状态,例如多轮对话和思维树。然而,这些工作仅针对 LLM 推理进行优化,而没有考虑 RAG 的特性。它们将中间状态缓存在 GPU 内存中,考虑到增强请求中的长序列,GPU 内存的容量有限,导致性能不佳。
我们对 RAG 进行了系统特性分析,通过使用代表性的 LLMs 在各种数据集和检索设置下测量当前 RAG 系统的性能。我们的分析突出了由于文档注入而导致的增强序列处理中的显著性能限制。此外,我们发现了两个潜在的系统优化机会来缓解这一限制。首先,多个请求中相同文档的重复出现使得可以共享 LLM 推理的中间状态。其次,少部分文档占据了大部分的检索请求。这使得我们可以缓存这些经常访问的文档的中间状态,以减轻计算负担。
我们提出了 RAGCache,这是一个专为 RAG 定制的新型多级动态缓存系统。RAGCache 是第一个能够缓存检索到的文档(即外部知识)的中间状态,并在多个请求之间共享这些状态的系统。RAGCache 的核心是一个知识树,它将检索到的文档的中间状态适应于 GPU 和主机内存层次结构。频繁访问的文档被缓存在快速的 GPU 内存中,而较少访问的文档则被缓存在较慢的主机内存中。在为 RAG 设计缓存系统时主要存在两个挑战:
首先,RAG 系统对于检索到的文档的引用顺序非常敏感。例如,假设有两个文档 $D_1$ 和 $D_2$,以及两个请求 $Q_1$ 和 $Q_2$。假设 $Q_1$ 和 $Q_2$ 的相关文档分别为 $[D_1, D_2]$ 和 $[D_2, D_1]$,其中 $[D_1, D_2]$ 表示 $D_1$ 比 $D_2$ 更相关。由于 LLMs 的注意机制中新 token 的键值张量是基于前面的 token 计算的,因此 $[D_1, D_2]$ 的中间状态(即键值张量)与 $[D_2, D_1]$ 的中间状态是不同的。不幸的是,我们也不能交换 $D_1$ 和 $D_2$ 的顺序。正如最近的研究所显示的,LLMs 的生成质量会受到引用顺序的影响。我们使用知识树来组织在 GPU 和主机内存层次结构中检索到的文档的中间状态,并设计了一种基于前缀感知的贪婪双大小频率(prefix-aware Greedy-Dual-Size-Frequency,PGDSF)替换策略,全面考虑文档的顺序、大小、频率和新旧程度,以最小化缺失率。当请求率较高时,我们还提出了一种缓存感知的请求调度方法,进一步提高命中率。
其次,在 RAG 中,向量检索(在 CPU 上处理)和 LLM 推理(在 GPU 上处理)是两个独立的步骤。在当前的 RAG 系统中,这两个步骤是按顺序执行的,导致在检索过程中 GPU 资源处于空闲状态,并且端到端的时延较长。为了在保持系统负载可控的同时最小化端到端时延,我们提出了一种动态的推测流水线策略(dynamic speculative pipelining strategy),以动态地重叠这两个步骤的计算过程。这样可以充分利用系统资源,减少空闲时间。
Background
在 RAG 的工作流程中,检索步骤主要在 CPU 上执行,而生成步骤则在 GPU 上执行。从系统的角度来看,RAG 的端到端性能受到检索和生成步骤的影响。检索时间主要取决于向量数据库的规模,而生成时间则由模型大小和序列长度决定。我们接下来的特性分析将确定 RAG 的性能瓶颈,并突出潜在的优化领域。
RAG System Characterization
Performance Bottleneck
LLM 推理可以分为两个不同的阶段:预填充(prefill)和解码(decoding)。预填充阶段涉及计算输入 token 的键值张量,而解码阶段则根据先前生成的键值张量以自回归方式生成输出 token。预填充阶段特别耗时,因为它需要计算整个输入序列的键值张量。
正如在第 2 节中讨论的,RAG 包括两个步骤:检索和生成。最近的研究表明,对于十亿级向量数据库,检索步骤每个请求执行时间在毫秒级别,并且具有较高的准确性。与此同时,生成步骤在 GPU 上执行,受到序列长度和模型大小的严重影响。为了确定性能瓶颈,我们在 LLaMA2-7B 上评估了具有固定输出长度和不同输入长度的推理时间,LLaMA2-7B 是 LLaMA2 系列中最小的模型。更大的模型将具有更长的推理时间。后端系统是配备一块 NVIDIA A10G GPU 的 vLLM。结果显示推理时间主要由预填充阶段占据,随着序列长度的增加而迅速增加,在序列长度大于 4000 个 token 时达到一秒。
在 LLM 生成步骤中,序列长度是原始请求的 token 数加上检索到的文档的 token 数。推理时间在大多数情况下明显高于检索时间。但当用户需要极高准确性的相关知识时,检索步骤可能需要与生成步骤相当的时间。
Optimizations Opportunities
Caching knowledge
生成步骤的性能瓶颈主要来自于在注意力块中处理长序列的键值张量。对于 RAG 来说,一个简单但有效的优化方法是缓存先前检索到的文档的键值张量。例如,假设请求 $Q_1$ 和 $Q_2$ 都引用同一个文档 $D_1$。如果 $Q_1$ 先到达,就会计算 $D_1$ 的键值张量,并且我们可以将其缓存起来。当 $Q_2$ 到达时,我们可以复用缓存的键值张量,以减少 $Q_2$ 的预填充时延。使用缓存的平均预填充时延计算如下:
\[\text{Prefill Latency = Miss Rate × Full Prefill Latency + (1 − Miss Rate) × Cache Hit Latency}\]Full prefill computation
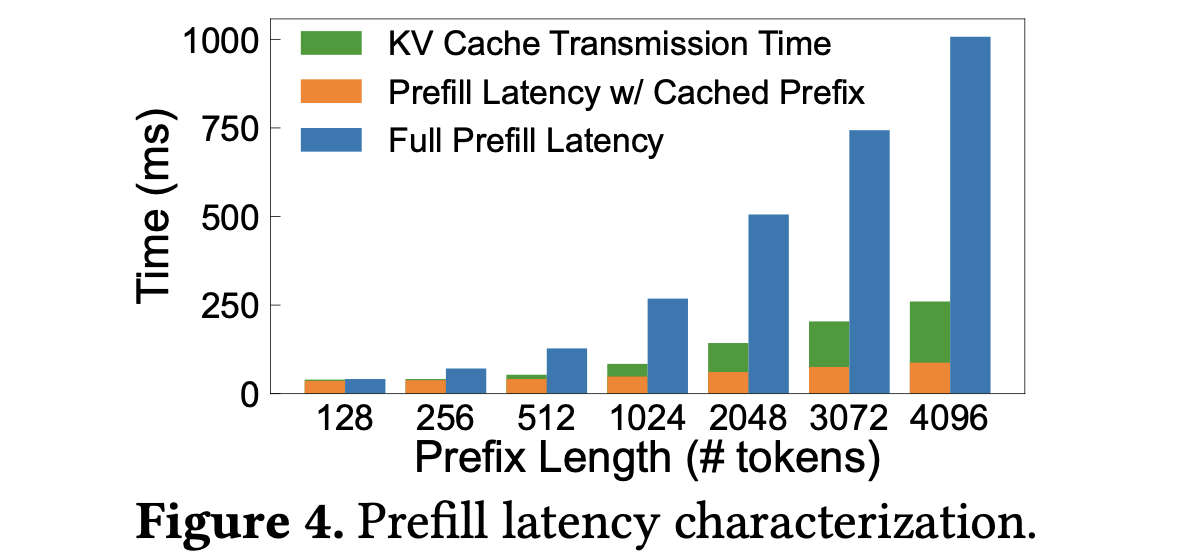
为了量化完整计算,我们比较了缓存与不缓存中间状态(即前缀的键值缓存)下 LLM 预填充阶段的时延。原始请求长度设置为 32 个 token,前缀长度的 token 则位于 128 到 4096 区间。下图显示了使用缓存时预填充时延显著降低。在缓存前缀的情况下,只需计算请求 token 的键值张量。而在完整预填充计算的情况下,需要计算整个序列的键值张量。完整预填充时延比缓存前缀场景下的时延低多达 11.5 倍。这些结果强调了通过缓存访问文档的中间状态可以实现的显著性能改进。
Cache hit
缓存命中包括两个组成部分:请求 token 的预填充计算和加载检索到的文档的键值缓存。与未命中的惩罚相比,前者可以忽略不计。至于后者,需要利用主机内存来扩展有限的 GPU 内存,以容纳更多检索到的文档的键值缓存。然而,这引入了潜在的开销:在 GPU 和主机内存之间传输键值缓存。图 4 将给定前缀长度的 KV 缓存传输时间添加到使用缓存前缀的预填充时间中。可以看出,即使考虑了传输开销,缓存命中时延仍然明显更好(最多降低 3.9 倍),突出了缓存检索文档的中间状态的优势。
Miss rate
最后一个考虑因素是 RAG 系统的检索模式。缓存性能受未命中率的主导,而未命中率直接受检索模式的影响。例如,当每个请求检索一个唯一的文档时,会出现 100% 的缓存未命中率。在这种情况下,缓存检索到的文档的中间状态是没有意义的。我们分析了 RAG 中四个代表性的问答数据集(MMLU、Google Natural Questions、HotpotQA 和 TriviaQA)中的文档检索模式。我们使用 OpenAI 的 text-embedding-3-small 模型将维基百科上的文档转换为向量进行检索。ANN 索引是 FlatL2,即在整个数据集上进行精确的欧氏距离搜索。我们观察到检索模式是倾斜的,少部分文档占据了大部分的检索请求。例如,在 MMLU 数据集中,前 3% 的文档被 60% 的请求引用,这比均匀分布少了 20 倍。
RAGCache Overview
我们提出了 RAGCache,这是一个专为 RAG 定制的新型多级动态缓存系统。RAGCache 通过在多个请求之间缓存检索到的文档的键值张量,以最小化冗余计算。RAGCache 的核心是一个知识树,采用了基于前缀的贪心双大小频率(PGDSF)替换策略,确保缓存最关键的键值张量。RAGCache 还实现了一个全局 RAG 控制器,用于协调外部知识数据库和 LLM 推理引擎之间的交互。该控制器通过缓存感知的重排序和动态推测流水线等系统优化来增强性能。
Architecture overview
在下图中,我们对 RAGCache 进行了简要概述。当一个请求到达时,RAG 控制器首先从外部知识数据库中检索相关文档。然后,这些文档被发送到缓存检索器以定位匹配的键值张量。如果缓存中不存在键值张量,RAGCache 会指示 LLM 推理引擎生成新的 token。相反,如果张量可用,带有键值张量的请求将被转发到 LLM 推理引擎,该引擎使用前缀缓存内核进行 token 生成。在生成第一个 token 后,键值张量被传送回 RAG 控制器,该控制器缓存访问文档的张量并刷新缓存的状态。最后,生成的答案作为响应传递给用户。
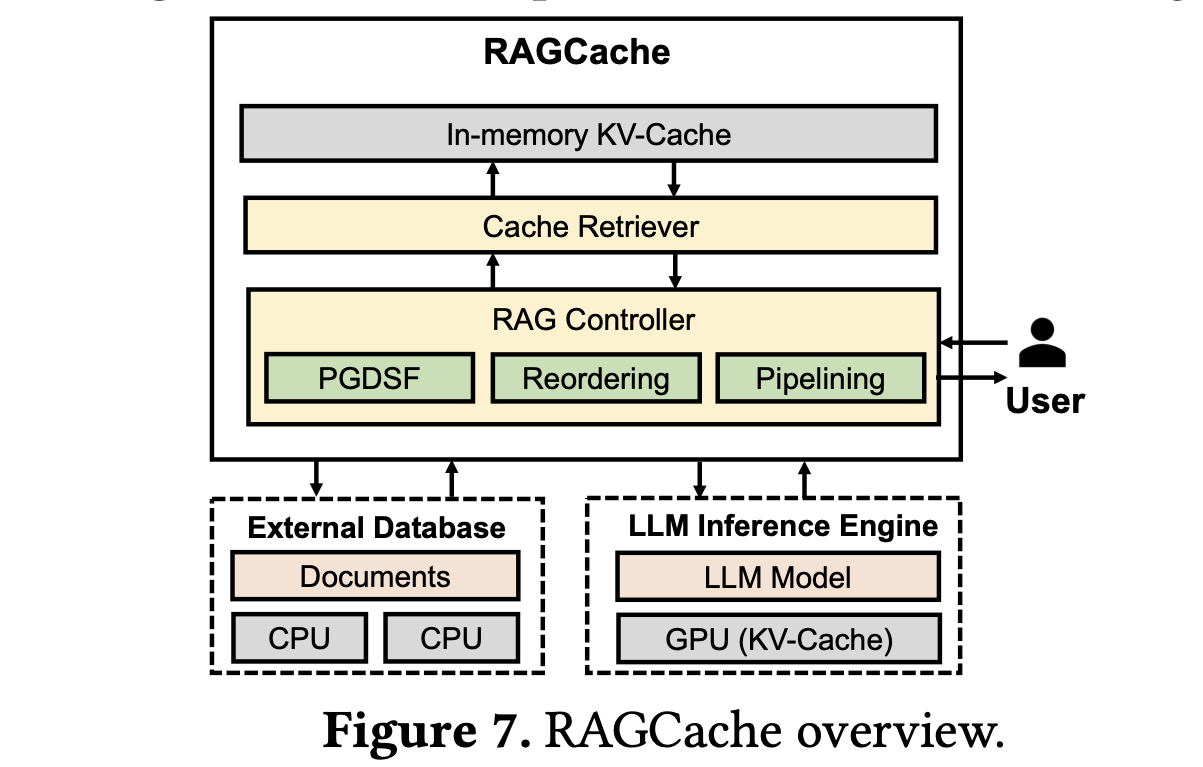
Cache retriever
缓存检索器能够高效地定位存储在内存缓存中的文档的键值张量,利用知识树来组织这些张量。这个树结构是基于文档 ID 的前缀树,与 LLM 对文档顺序的位置敏感性相一致。树中的每条路径代表一个请求引用的特定文档序列,每个节点保存一个被引用文档的键值张量。不同的路径可能共享相同的节点,这表示在不同请求之间共享的文档。这种结构使得检索器能够快速访问按指定顺序排列的文档的键值张量。
RAG controller
RAG 控制器负责协调一些专为 RAG 定制优化的系统之间的交互。采用了基于前缀的贪心双大小频率(PGDSF)策略来最小化缓存未命中率。PGDSF 根据键值张量的频率、大小、最后访问时间和前缀感知的重新计算成本计算优先级。缓存的淘汰由优先级确定,以确保保留最有价值的张量。缓存感知的重排序调度请求以提高缓存命中率并防止抖动,同时还确保请求公平性以减轻饥饿问题。动态推测流水线设计旨在重叠知识检索和 LLM 推理,以最小化延迟,利用检索结果的中间生成来提前启动 LLM 推理。
RAGCache Design
Cache Structure and Replacement Policy
与传统的缓存系统缓存单个对象不同,RAGCache 缓存检索到的文档(对引用顺序敏感)的键值张量。为了在保持文档顺序的同时快速检索,RAGCache 使用知识树来组织文档的键值张量,如下图所示。
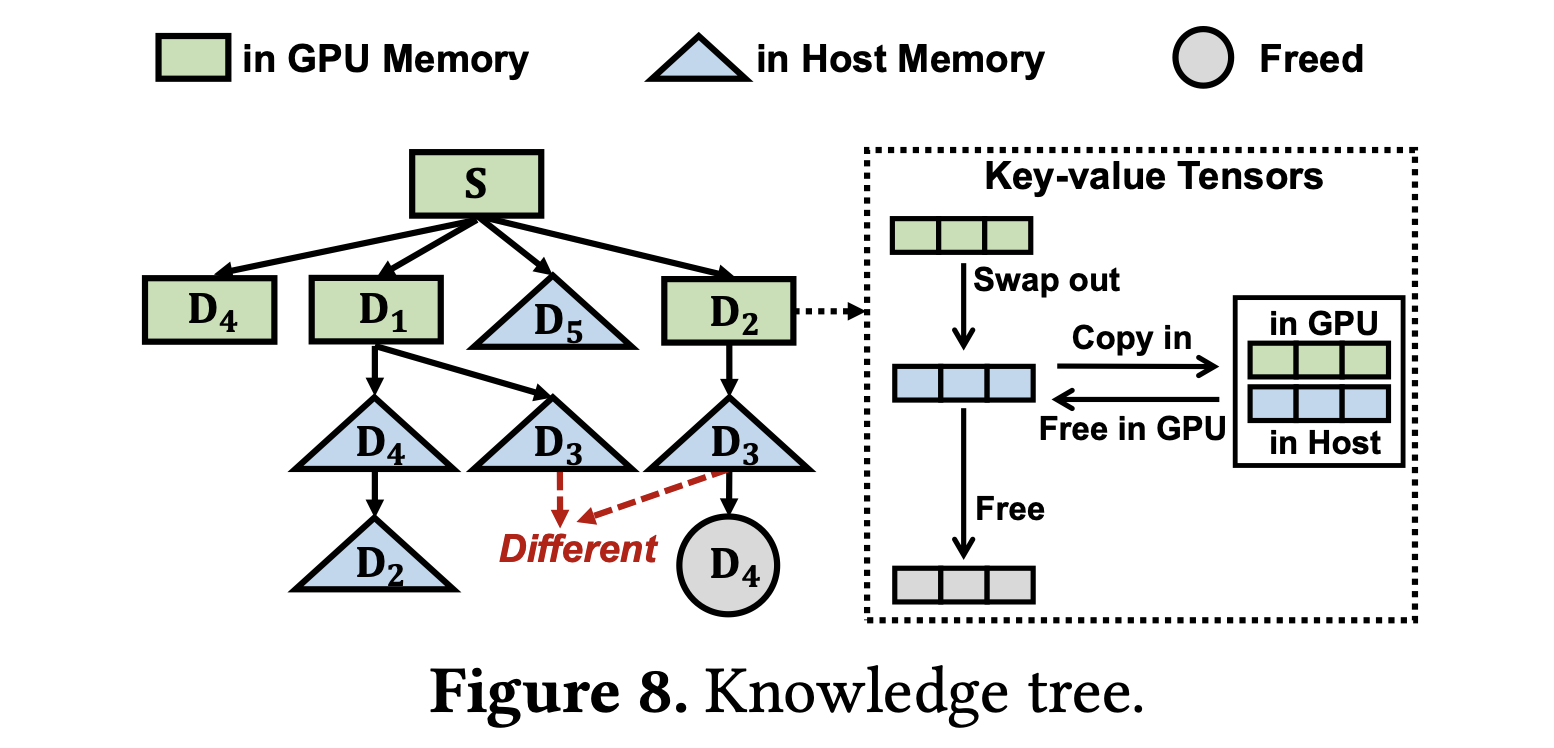
该树将每个文档分配给一个节点,该节点引用文档键值张量的内存地址。与 vLLM 类似,RAGCache 将键值张量存储在非连续的内存块中以进行 KV 缓存重用。根节点 $S$ 表示共享的 System Prompt。从根节点到特定节点的路径表示一系列文档。
这种设计天然地允许 RAGCache 通过树中的重叠路径同时为多个请求提供服务。RAGCache 通过前缀匹配路径来检索张量。在前缀匹配过程中,如果后续文档在子节点中未找到,遍历将立即终止,并返回已识别的文档序列。这种方法确保了效率,时间复杂度为 $O(h)$,其中 $h$ 表示树的高度。
Prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy
使用知识树,RAGCache 需要在层次化缓存中决定每个节点的放置位置。经常访问的节点理想情况下存储在 GPU 内存中,以实现更快的访问速度,而不经常访问的节点则分配给较慢的主机内存或直接释放。为了优化节点的放置,RAGCache 采用了基于经典 GDSF 策略的前缀感知贪心双大小频率(PGDSF)替换策略。与传统的 LRU 等缓存策略不同,PGDSF 根据节点的访问频率、大小和访问成本来评估每个节点。该方法通过保留最有益的节点来利用有限的存储容量,其优先级定义如下:
\[\text{Priority} = \text{Clock} + \frac{\text{Frequency} \times \text{Cost}}{\text{Size}} \tag{1}\]优先级较低的节点首先被淘汰。时钟(Clock)跟踪节点的访问时间。在 RAG 控制器中,我们分别为 GPU 和主机内存维护两个独立的逻辑时钟,以适应缓存层次结构。每个时钟从零开始,并在每次淘汰时更新。当检索到一个文档时,其节点的时钟被设置,并且其优先级被调整。具有较旧时钟的节点,表示较早的使用,其优先级较低。设 $E$ 为一次淘汰操作中被淘汰的节点集合。时钟相应地进行更新:
\[\text{Clock} = \max_{n \in E}\text{Priority}(n) \tag{2}\]频率(Frequency)表示在一个时间窗口内文档的总检索次数。在系统启动或缓存清除时,该计数被重置为零。优先级与频率成正比,因此更频繁访问的文档具有更高的优先级。Size 反映了文档在标记化后的 token 数量,直接影响其键值张量所需的内存。Cost 定义为计算文档的键值张量所需的时间,它随着 GPU 的计算能力、文档大小和前面文档的顺序而变化。
PGDSF 在 RAG 系统中通过两个方面实现了前缀感知:成本估计(cost estimation)和节点放置(node placement)。与 GDSF 不同,RAG 的成本涉及复杂的 LLM 生成动态。例如,下图显示了由相同请求 $[S, D_1, D_2, Q]$ 引起的不同成本。为了估计 $D_2$ 的成本,直接使用 $[S, D_1]$ 缓存或仅 $S$ 缓存的成本是不精确的。
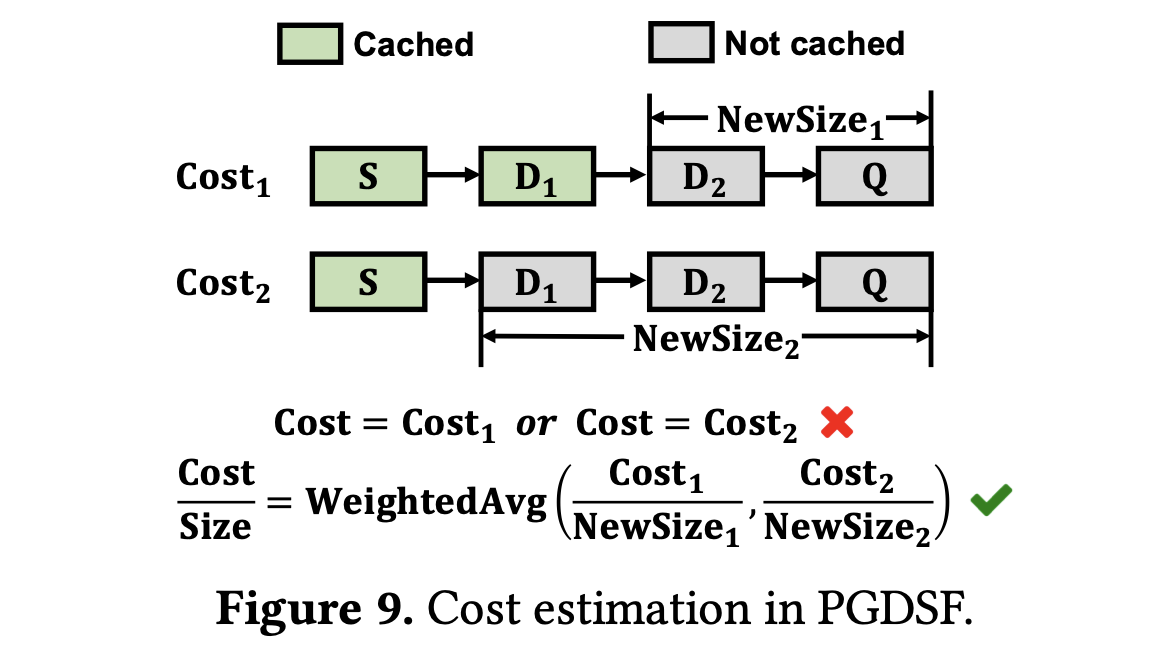
PGDSF 通过替换公式 1 中 Cost/Size 为如下公式来解决这个问题:
\[\frac{\text{Cost}}{\text{Size}} = \frac{1}{m} \sum_{i=1}^{m} \frac{\text{Cost}_i}{\text{NewSize}_i} \tag{3}\]其中 $m$ 是访问该文档但未缓存的请求数量。$Cost_i/NewSize_i$ 表示第 $i$ 个请求每个非缓存 token 的计算时间。这种估计天然地考虑了文档的大小,通过将成本分摊到所有非缓存 token 上。至于 $Cost_i$,RAGCache 在离线状态下使用不同的缓存和非缓存 token 长度对 LLM 预填充时间进行建模,并使用双线性插值来估计给定请求的成本。文档检索触发知识树中节点频率、成本估计和时钟的更新,或为之前未缓存的文档初始化一个新节点。
PGDSF 协调节点在知识树中的放置,该知识树被划分为 GPU、主机和空闲段,如上图 8 所示。GPU 内存中的节点作为主机内存中节点的父节点,建立了一个层次结构。为了提高效率,RAGCache 动态地管理这些段之间的节点淘汰。具体而言,当 GPU 内存已满时,RAGCache 将叶节点中优先级最低的节点与主机内存进行交换。对于主机内存超额分配,RAGCache 采用类似的过程。这种淘汰策略维护了树的层次划分,这对于与 LLM 生成中的内存层次结构和前缀敏感性保持一致非常重要。一个节点依赖于其父节点进行键值张量的计算,强调了优先考虑父节点放置以实现快速检索的需求。

算法 1 概述了在知识树的 GPU 内存中更新和淘汰节点的操作。$T(\alpha, \beta)$ 表示一个有 $\alpha$ 个已缓存 token 和 $\beta$ 个非缓存 token 的请求的估算计算时间。当请求检索到一个文档时,如果文档未缓存,RAGCache 使用双线性插值更新成本(第 6 - 9 行)。如果 GPU 内存已满,EVICT_IN_GPU 从 GPU 内存中淘汰节点以容纳新的请求,并根据公式 2 更新时钟。如果一个父节点在淘汰后变成叶节点,它将被添加到候选集合 $S$ 中。
Swap out only once
GPU 通过 PCIe 总线连接到主机内存,而 PCIe 总线的带宽通常远低于 GPU HBM。为了最小化 GPU 和主机内存之间的数据传输,RAGCache 采用了一种仅进行一次交换(swap-out-only-once)的策略,如图 8 所示。节点的键值张量仅在第一次淘汰时被交换到主机内存。主机内存保留键值张量,直到节点从整个缓存中被淘汰。对于 GPU 内存中的后续淘汰,RAGCache 直接释放节点,无需进行数据复制。考虑到主机内存的容量比 GPU 内存大一到两个数量级,将键值张量在主机内存中保留一份副本是可以接受的。
Cache-aware Reordering
缓存命中率对于 RAGCache 的缓存效率至关重要,但用户请求的不可预测到达模式导致了大量的缓存抖动。指向相同文档的请求可能不会同时发出,从而影响缓存效率。例如,假设请求 $\{Q_i, i\%2 == 0\}$ 和 $\{Q_i, i\%2 == 1\}$ 分别针对文档 $D_1$ 和 $D_2$。缓存容量为一个文档。序列 $\{Q_1, Q_2, Q_3…\}$ 导致 $D_1$ 和 $D_2$ 的键值缓存频繁交换,导致缓存命中率为零。相反,将请求重新排列为 $\{Q_1, Q_3, Q_5, Q_2, Q_4, Q_6, Q_7,…\}$ 可以优化缓存利用率,将命中率提高到 66%。这说明了通过战略性地排序请求可以缓解缓存波动并提高缓存效率。
介绍缓存感知的重新排序算法之前,先考虑两个场景。假设重新计算的成本与重新计算的长度成正比。第一个场景(图 10a)考虑了具有相同重新计算需求但缓存上下文长度不同的请求,在缓存限制为 4 的情况下。初始顺序为 $\{Q_1, Q_2\}$,系统必须清除 $Q_2$ 的缓存空间以容纳 $Q_1$ 的计算,然后重新分配内存以处理 $Q_1$。它有效地利用了 $Q_1$ 的缓存,同时丢弃了 $Q_2$ 的。这导致总计算成本为 $2 + 1 + 2 = 5$。相反,顺序为 $Q_2$, $Q_1$ 则利用了 $Q_2$ 的缓存,但丢弃了 $Q_1$ 的,这使得计算成本增加到 $2 + 2 + 2 = 6$。因此,缓存感知的重新排序建议优先处理具有较大缓存上下文的请求,以提高缓存效率。
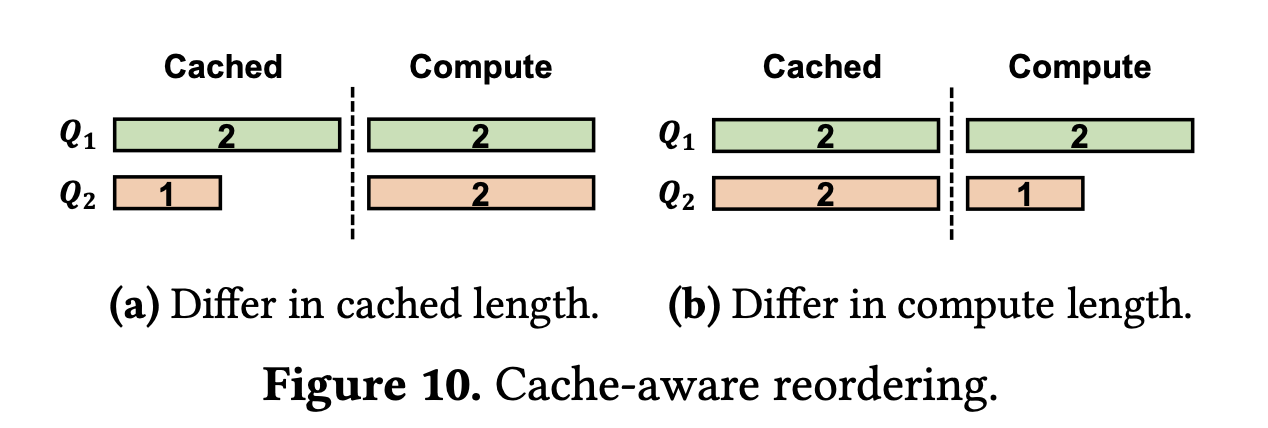
在第二种情况下,我们研究具有相同缓存上下文长度但具有不同重新计算需求的请求,假设缓存容量为 5。对于序列 $\{Q_1,Q_2\}$,系统必须清除 $Q_2$ 的缓存以为 $Q_1$ 的计算分配空间,因为只有一个可用的内存插槽。这需要完全重新计算 $Q_2$,导致计算成本为 $2 + 2 + 1 = 5$。相比之下,序列 $\{Q_2, Q_1\}$ 允许直接计算 $Q_2$,因为缓存可用性充足。这将总计算量减少为 $2 + 1 = 3$ 。因此,优先考虑具有较短重新计算段的请求,因为这种方法最大程度地减少了对缓存效率的不利影响。
根据这些见解,我们引入了一种缓存感知的重新排序算法,旨在提高缓存效率。RAGCache 使用优先队列来管理传入的请求,根据它们对缓存性能的影响来确定优先级。具体来说,请求的处理是基于一个优先级指标来选择的,该指标定义为:
\[\text{OrderPriority}=\frac{\text{Cached Length}}{\text{Computation Length}}\]这个公式优先处理那些相对于其计算需求而言缓存部分较大的请求,因为这些请求更有可能提高缓存效率。通过采用这种缓存感知的重新排序,RAGCache 提高了缓存命中率,减少了总计算时间,从而优化了资源使用和系统性能。为了避免请求饥饿,RAGCache 为每个请求设置了一个窗口,以确保所有请求都能在不超过窗口大小的时间内得到处理。
Dynamic Speculative Pipelining
如果向量数据库规模扩大或检索需要更高的准确性,检索步骤可能会导致显著的延迟。为了减轻检索延迟的影响,RAGCache 采用动态推测流水线(dynamic speculative pipelining)技术,以重叠知识检索和 LLM 推理。该技术背后的关键见解是,向量搜索可能在检索步骤的早期就产生最终结果,LLM 可以利用这些结果提前进行推测性生成。
具体来说,向量搜索维护一个由与请求相似度排名的前 k 个候选文档组成的队列。在检索过程中,队列中的前 k 个文档会不断更新,即一些相似度更高的文档会被插入到队列中。然而,最终的前 k 个文档可能会在检索步骤的早期就出现。基于这一观察,RAGCache 引入了一种推测性流水线策略,将请求的检索过程分为几个阶段。在每个阶段,RAGCache 会通知向量数据库将候选文档发送到 LLM 引擎进行推测性生成。然后,LLM 引擎开始新的推测性生成,如果接收到的文档与之前的不同,则终止之前的生成。如果没有差异,LLM 引擎则继续处理之前的生成。当最终的前 k 个文档生成时,RAGCache 将最终结果发送到 LLM 引擎。此时,如果最新的推测性生成结果与最终的前 k 个文档匹配,LLM 引擎会将结果返回给用户。否则,LLM 引擎会重新生成。
Implementation
我们使用大约 5000 行 C++ 和 Python 代码实现了 RAGCache 的系统原型。我们的实现基于 vLLM v0.3.0。我们扩展了其 Pytorch 和 Triton 中的预填充(prefill)内核,以支持不同注意力机制的前缀缓存,例如多头注意力和分组查询注意力。
Pipelined vector search.
我们在 Faiss 之上实现了动态推测性流水线,并将其适配于两种类型的索引:IVF 和 HNSW。为了支持流水线化的向量搜索,我们修改了这两种索引的搜索过程。具体来说,我们将 IVF 搜索分为多个阶段,每个阶段在某些簇中搜索向量并返回当前的前 k 个向量。对于 HNSW,我们测量了指定搜索配置的平均搜索时间,并将整个时间分割为较小的时间片。在每个时间片的搜索之后,它返回当前的前 k 个向量。
Fault tolerance
我们在 RAGCache 中实现了两种容错机制,以处理 GPU 故障和请求处理故障。GPU 内存作为 RAGCache 的一级缓存,存储知识树层次结构中上层节点的键值缓存。鉴于 LLM 推理的前缀敏感性,GPU 故障会使下层节点失效,从而影响整个树。我们在主机内存中复制了一部分访问频率最高的上层节点(例如系统提示)以便快速恢复。我们还采用了超时机制来重试失败的请求。如果请求在完成第一次迭代之前失败,它将被重新计算。否则,请求可以通过重用存储的键值缓存继续计算。