本文是《ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT》 的笔记。
ColBERT 引入了延迟交互(late interaction)架构,该架构使用 BERT 独立编码查询和文档,然后采用低成本但强大的交互步骤来建模它们的细粒度相似性。通过延迟但保留这种细粒度交互,ColBERT 可以充分利用深度 LM 的表达能力,同时获得离线预计算文档表示的能力,从而显著加快查询处理速度。
除此之外,ColBERT 的剪枝友好交互机制还支持利用向量相似性索引直接从大型文档集合进行端到端检索。我们使用两个最新的段落搜索数据集对 ColBERT 进行了广泛评估。结果表明,ColBERT 的有效性与现有的基于 BERT 的模型相当,同时执行速度快两个数量级,每个查询所需的 FLOPs 少四个数量级。
INTRODUCTION
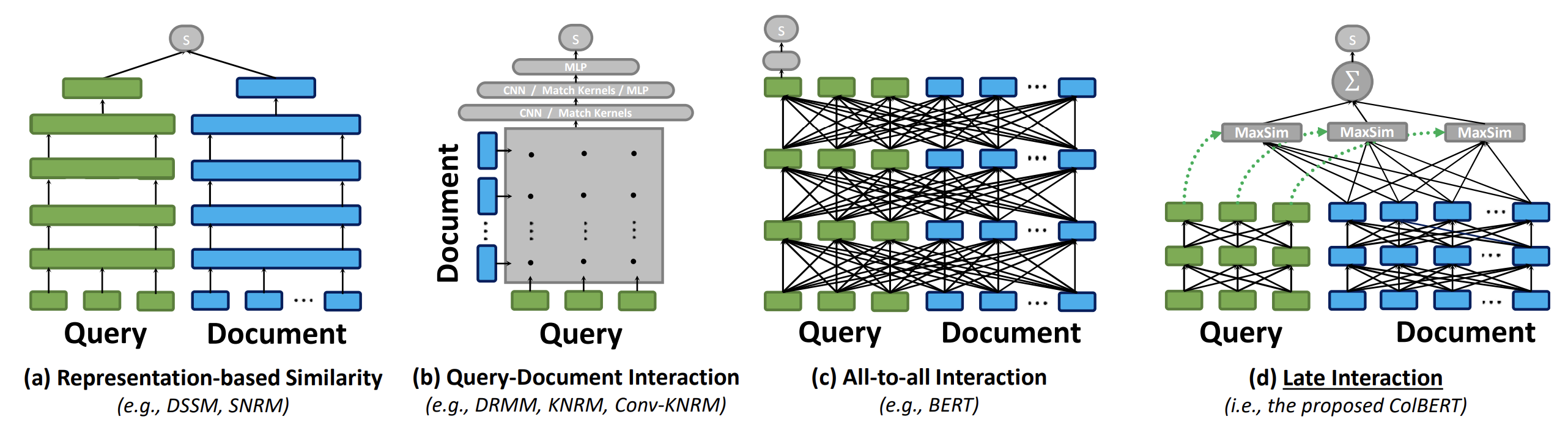
上图将我们提出的延迟交互方法与现有的神经匹配范式进行了对比。图(a)展示了以表示为中心(representation-focused)的排序器,其独立计算查询 $q$ 的嵌入和文档 $d$ 的嵌入,并将相关性估计为两个向量之间的相似性分数。图(b)可视化了典型的以交互为中心(interaction-focused)的排序器,其建模 $q$ 和 $d$ 之间的词级和短语级关系,并使用深度神经网络进行匹配。图(c)展示了一个更强大的基于交互的范式,它同时建模 $q$ 和 $d$ 内部以及跨 $q$ 和 $d$ 的词间交互(BERT 的 transformer 架构)。
虽然基于交互的模型在 IR 任务中往往更优,但以表示为中心的模型——通过隔离 $q$ 和 $d$ 之间的计算——使得离线预计算文档表示成为可能,从而大大减少了每个查询的计算负载。我们观察到,基于交互模型的细粒度匹配和基于表示模型的预计算文档表示可以通过延迟查询-文档交互来结合(图(d))。每个查询嵌入通过 MaxSim 操作符与所有文档嵌入进行交互,计算最大相似性(例如,余弦相似性),输出的标量在查询词项上求和。这种范式允许 ColBERT 利用基于深度 LM 的表示,同时将文档编码的成本转移到离线,并将查询编码的成本分摊到所有排序文档上。此外,它使 ColBERT 能够利用向量相似性搜索索引直接从大型文档集合中检索 top-k 结果,相对于仅对基于词项的检索输出进行重新排序的模型,显著提高了召回率。
COLBERT
Architecture
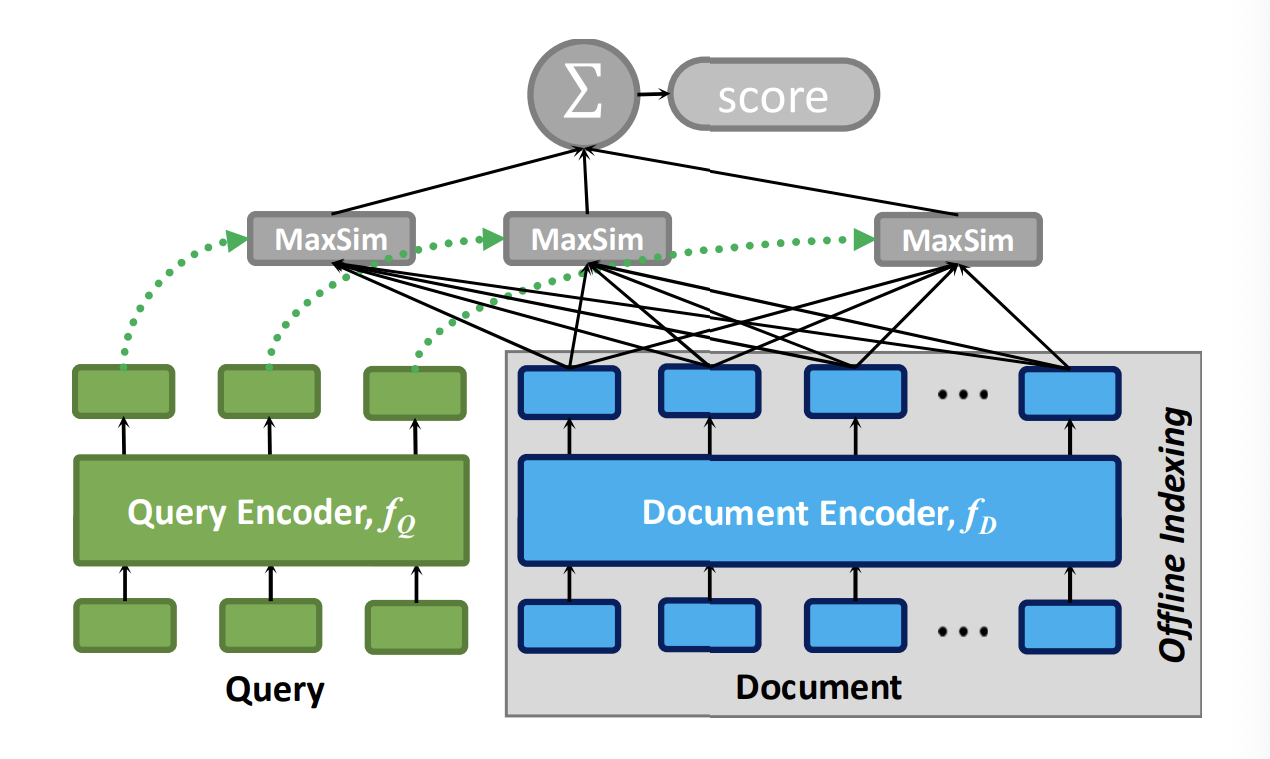
上图描绘了 ColBERT 的总体架构,包括:(a) 查询编码器 $f_Q$,(b) 文档编码器 $f_D$,和 (c) 延迟交互机制。给定查询 $q$ 和文档 $d$,$f_Q$ 将 $q$ 编码为固定大小的嵌入集合 $E_q$,而 $f_D$ 将 $d$ 编码为另一个集合 $E_d$。$E_q$ 和 $E_d$ 中的每个嵌入都基于 $q$ 或 $d$ 中的其他词项进行上下文化。
使用 $E_q$ 和 $E_d$,ColBERT 通过延迟交互计算 $q$ 和 $d$ 之间的相关性分数,我们将其定义为最大相似性(MaxSim)操作符的求和。具体而言,我们找到 $E_q$ 中每个向量 $v$ 与 $E_d$ 中向量的最大余弦相似性,并通过求和的方式来组合输出。
虽然通过其他选择(如深度卷积和注意力层,即以交互为中心的模型)可以实现更复杂的匹配,但最大相似性计算的求和具有两个独特特征。首先,它是一种特别低成本的交互机制。其次,更重要的是,它适用于 top-k 检索的高效剪枝。
Query & Document Encoders
在延迟交互之前,ColBERT 使用基于 BERT 的编码器将每个查询或文档编码为嵌入集合。我们在查询和文档编码器之间共享单个 BERT 模型,但通过在查询前添加特殊 token [Q]和在文档前添加另一个token [D] 来区分对应于查询和文档的输入序列。
Query Encoder
给定文本查询 $q$,我们将其 tokenize 为基于 BERT 的 WordPiece tokens $q_1q_2…q_l$。我们在查询前添加 token [Q]。我们将此 token 放置在 BERT 的序列开始 token [CLS]之后。如果查询的 token 数量少于预定义数量 $N_q$,我们用 BERT 的特殊 [mask] tokens 填充到长度 $N_q$(否则,我们将其截断为前 $N_q$ 个 tokens)。然后,这个填充的输入 token 序列被传递到 BERT transformer 架构中,计算每个 token 的上下文表示。
我们将使用 masked tokens 进行填充称为查询增强,这一步允许 BERT 在对应于这些 mask 的位置产生基于查询的嵌入。查询增强旨在作为一个软的、可微分的机制,用于学习用新词项扩展查询或基于词项对匹配查询的重要性重新权衡现有词项。这对 ColBERT 的有效性至关重要。
给定 BERT 对每个 token 的表示,我们的编码器将上下文化的输出表示传给一个没有激活函数的线性层。该层用于控制 ColBERT 嵌入的维度 $m$。我们通常将 $m$ 固定为比 BERT 的固定隐藏维度小得多。
虽然 ColBERT 的嵌入维度对编码查询的效率影响有限,但对控制文档的空间占用至关重要。此外,它可能对查询执行时间产生重大影响,特别是将文档表示从系统内存传输到 GPU 所需的时间。
最后,输出嵌入被归一化,使得每个嵌入的 L2 范数等于 1。使任意两个嵌入的点积等价于它们的余弦相似性,落在 [−1, 1] 范围内。
Document Encoder
我们的文档编码器具有非常相似的架构。我们首先将文档 $d$ 分割为 tokens $d_1d_2…d_m$,在其前面添加 BERT 的开始 token [CLS],然后添加我们的特殊 token [D] 来表示文档序列。
与查询不同,我们不向文档添加 [mask] tokens。在将此输入序列通过 BERT 和后续线性层后,文档编码器过滤掉对应于标点符号的嵌入,这些标点符号通过预定义列表确定。这种过滤旨在减少每个文档的嵌入数量。
总结来说,给定 $q = q_0q_1…q_l$ 和 $d = d_0d_1…d_n$,我们按以下方式计算嵌入集合 $E_q$ 和 $E_d$,其中 # 表示 [mask] tokens:
\[E_q := \text{Normalize}( \text{CNN}( \text{BERT}("[Q]q_0q_1...q_l \#\#...\#") ) ) ) \tag{1}\] \[E_d := \text{Filter}( \text{Normalize}( \text{CNN}( \text{BERT}("[D]d_0d_1...d_n") ) ) ) ) \tag{2}\]延迟交互
给定查询 $q$ 和文档 $d$ 的表示,文档 $d$ 对查询 $q$ 的相关性分数,记为 $S_{q,d}$,通过它们上下文化嵌入集合之间的延迟交互来测算。如前所述,通过最大相似性计算的求和来进行的,即余弦相似性(由于嵌入归一化而实现为点积)或平方 L2 距离:
\[S_{q,d} := \sum_{i \in [|E_q|]} \max_{j \in [|E_d|]} E_{q_i} \cdot E^\top_{d_j}\]ColBERT 是端到端可微分的。我们微调 BERT 编码器,并使用 Adam 优化器从头训练额外参数(即线性层和 [Q] 和 [D] token 的嵌入)。注意,我们的交互机制没有可训练参数。给定三元组 $\langle q, d^+, d^- \rangle$,其中包含查询 $q$、正文档 $d^+$ 和负文档 $d^-$,ColBERT 用于单独为每个文档生成分数,并通过在 $d^+$ 和 $d^-$ 的计算分数上使用成对 softmax 交叉熵损失进行优化。
Top-k Re-ranking with ColBERT
ColBERT 可以用于重排序另一个检索模型的输出(通常是基于词项的模型),或直接从文档集合进行端到端检索。在本节中,我们讨论如何使用 ColBERT 对给定查询 $q$ 的小集合 k(例如,k = 1000)个文档进行排序。由于 k 较小,我们基于批处理计算来穷举地计算每个文档的分数。
相对于现有的神经排序器,这种计算成本非常低廉。其成本主要由收集和传输预计算嵌入的成本主导。通过典型的 BERT 排序器对 k 个文档进行排序需要向 BERT 输入 k 个不同的输入,每个输入的长度为 $l = |q| + |d_i|$(对于查询 $q$ 和文档 $d_i$),其中注意力机制的计算复杂度和序列长度呈二次关系(quadratic cost)。相比之下,ColBERT 只向 BERT 输入一个更短的序列,长度为 $l = |q|$。
End-to-end Top-k Retrieval with ColBERT
本节关注的是需要排序的文档数量过大而无法对每个可能的候选文档进行穷举评估的情况,特别是当我们只对得分最高的文档感兴趣时。具体而言,我们专注于从包含 $N$ 个文档的大型文档集合中直接检索 top-k 结果,其中 $k ≪ N$。
为此,我们利用延迟交互核心的 MaxSim 操作的剪枝友好特性。我们使用了一个现成的大规模向量相似性搜索库,即 Facebook 的 faiss。在离线索引结束时,我们维护从每个嵌入到其源文档的映射,然后将所有文档嵌入索引到 faiss 中。
随后,在处理查询时,我们使用两阶段程序从整个集合中检索 top-k 文档。两个阶段都依赖于 ColBERT 的评分:第一阶段是近似阶段,旨在过滤;第二阶段是精化阶段。
第一阶段
并发地向 faiss 索引发出 $N_q$ 个向量相似性查询(对应于 $E_q$ 中的每个嵌入)。这检索出该向量在所有文档嵌入上的top-$k’$ 个匹配(例如,$k’ = k/2$)。我们将每个匹配映射到其源文档,产生 $N_q × k’$ 个文档ID。这些 $K ≤ N_q × k’$ 个文档可能包含一个或多个与查询嵌入高度相似的嵌入。
第二阶段
我们通过仅对那 $K$ 个文档按照 Top-k Re-ranking 中描述的常规方式进行穷举重排序来优化这个集合。
在我们的基于 faiss 的实现中,我们使用 IVFPQ(“inverted file with product quantization)索引。该索引基于k-means 聚类将嵌入空间划分为 $P$ 个单元(例如,$P = 1000$),然后根据选定的向量相似性度量将每个文档嵌入分配到其最近的单元。
在处理查询时,当搜索单个查询嵌入的 top-$k’$ 个匹配时,只搜索最近的 $p$ 个分区(例如,$p = 10$)。为了提高内存效率,每个嵌入被划分为 $s$ 个子向量(例如,$s = 16$),每个子向量用一个字节表示。此外,索引在这个压缩域中进行相似性计算,带来更低廉的计算,从而更快的搜索。