本系列文章是对 MIT 6.824 课程的学习笔记。
ZooKeeper
Abstract
ZooKeeper 旨在提供简单高效的内核以供客户端实现更复杂的 coordination primitives。In addition to the wait-free property, ZooKeeper provides a per client guarantee of FIFO execution of requests and linearizability for all requests that change the ZooKeeper state.
Introduction
为了保证状态更新操作(写请求)的 linearizability,ZooKeeper 实现了 Zab,一个基于 leader 的原子广播协议。In ZooKeeper, servers process read operations locally, and we do not use Zab to totally order them.
在客户端缓存数据是提高读性能的重要技术,ZooKeeper 提供了 watch 机制,不直接管理客户端缓存。
Service overview
ZooKeeper 提供给客户端 znode 的抽象,znode 有下列两种类型:
- Regular : 由客户端显式创建和删除
- Ephemeral: 由客户端创建,可以由客户端显式删除,当会话终止时系统也会自动删除
ZooKeeper 实现了 watch 机制,当数据发生改变时通知客户端,而不必通过让客户端轮询服务器的方式。
客户端连接到 ZooKeeper 时会初始化一个 session。Session 有超时机制,当 ZooKeeper 在超时时间内没有收到来自客户端 session的任何信息时,会判定该客户端已经挂掉。
ZooKeeper guarantees
ZooKeeper 具备以下两个基础保证:
-
Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect precedence;
-
FIFO client order: all requests from a given client are executed in the order that they were sent by the client.
Examples of primitives
Simple Locks without Herd Effect
1
2
3
4
5
6
7
8
9
10
Lock
1 n = create(l + “/lock-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for watch event
6 goto 2
Unlock
1 delete(n)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Write Lock
1 n = create(l + “/write-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if n is lowest znode in C, exit
4 p = znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 2
Read Lock
1 n = create(l + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n
5 if exists(p, true) wait for event
6 goto 3
ZooKeeper Implementation
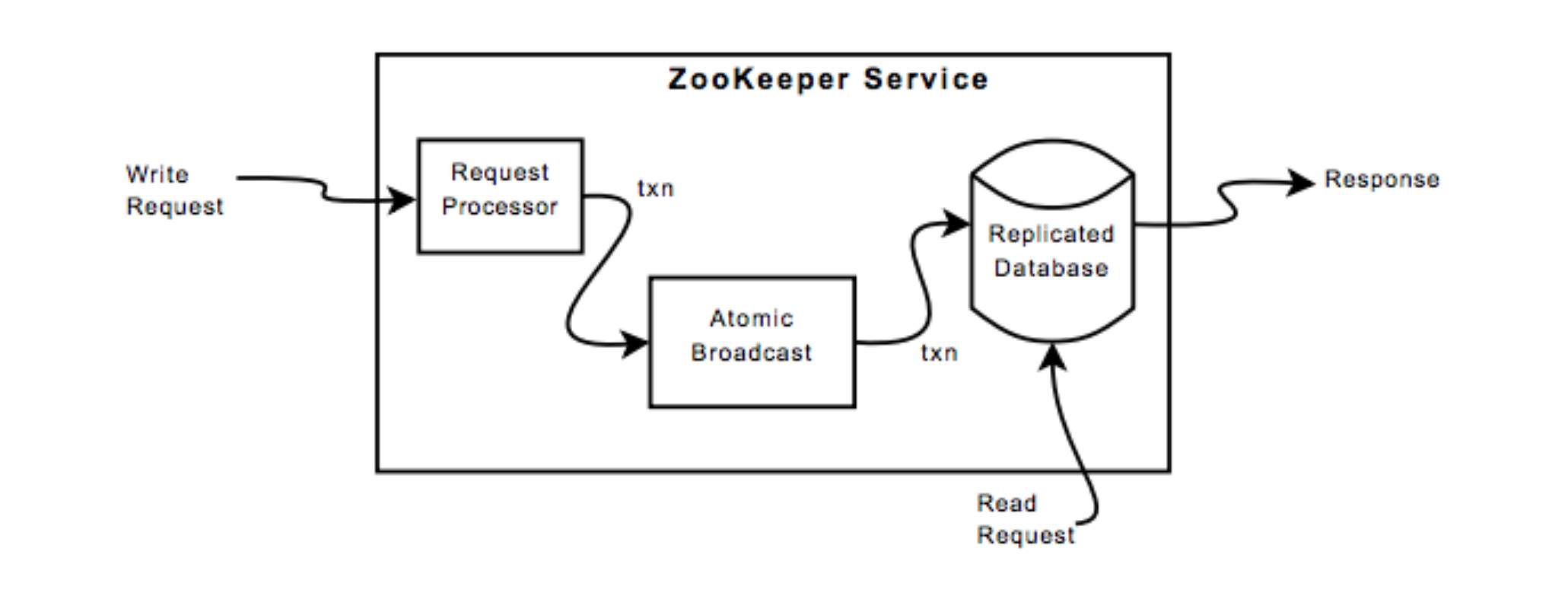
收到请求时,由 request processor 处理。如果是写请求,则使用 zab 协议,最终提交到 ZooKeeper 数据库的修改将会被复制到该系统上所有的服务器。
复制数据库是一个内存数据库,在变更被应到到内存数据库之前,我们强制将更新记录刷到磁盘上以实现 recoverability。
每个 ZooKeeper 服务器都接收处理来自客户端的请求。 读操作由每个服务器的本地数据库来处理,写请求则由 zab 协议处理。
Request Processor
与客户端发送的请求不同,事务是幂等的。When the leader receives a write request, it calculates what the state of the system will be when the write is applied and transforms it into a transaction that captures this new state. The future state must be calculated because there may be outstanding transactions that have not yet been applied to the database. (尽管 transaction 可能执行多次,但通过计算 state 的方式,且保证多次执行的 transaction 也按照原先的顺序,就能保证幂等性)
Atomic Broadcast
所有更新 ZooKeeper 状态的请求都被转发到 leader。 Leader 执行请求并通过 Zab,一个原子广播协议广播该变更。Zab 采用majority quorums 来决定一个建议,因此 ZooKeeper 在 2F + 1 服务器的场景下最多可以容忍 F 台服务器故障。
Because state changes depend on the application of previous state changes, Zab provides stronger order guarantees than regular atomic broadcast. More specifically, Zab guarantees that changes broadcast by a leader are delivered in the order they were sent and all changes from previous leaders are delivered to an established leader before it broadcasts its own changes.
Replicated Database
重放消息以恢复状态非常耗时,因此 ZooKeeper 定期进行快照,恢复时只需要重放快照后的消息。 为了不锁住状态,ZooKeeper 采用模糊快照的方式。对树进行深度优先扫描,原子读取每个 znode 的数据和元数据并写入磁盘。Since the resulting fuzzy snapshot may have applied some subset of the state changes delivered during the generation of the snapshot, the result may not correspond to the state of ZooKeeper at any point in time. However, since state changes are idempotent, we can apply them twice as long as we apply the state changes in order.
Client-Server Interactions
读请求由服务器本地处理。每个读请求都被一个 zxid 标记,表示服务器看到的最后一个事务。本地读取的方式提高了性能,但可能返回旧数据。客户端可以在读操作后调用 sync 来保证返回的是最新的值。In our implementation, we do not need to atomically broadcast sync as we use a leader-based algorithm, and we simply place the sync operation at the end of the queue of requests between the leader and the server executing the call to sync. In order for this to work, the follower must be sure that the leader is still the leader. If there are pending transactions that commit, then the server does not suspect the leader. If the pending queue is empty, the leader needs to issue a null transaction to commit and orders the sync after that transaction.
ZooKeeper 服务器以 FIFO 的顺序来处理客户端的请求。Response 包含了 zxid。Even heartbeat messages during intervals of no activity include the last zxid seen by the server that the client is connected to. If the client connects to a new server, that new server ensures that its view of the ZooKeeper data is at least as recent as the view of the client by checking the last zxid of the client against its last zxid. If the client has a more recent view than the server, the server does not reestablish the session with the client until the server has caught up.
Linearizability versus Serializability
注:摘自 Linearizability versus Serializability
Linearizability: single-operation, single-object, real-time order
Linearizability is a guarantee about single operations on single objects. It provides a real-time guarantee on the behavior of a set of single operations.
In plain English, under linearizability, writes should appear to be instantaneous. Imprecisely, once a write completes, all later reads (where “later” is defined by wall-clock start time) should return the value of that write or the value of a later write. Once a read returns a particular value, all later reads should return that value or the value of a later write.
Linearizability for read and write operations is synonymous with the term “atomic consistency” and is the “C,” or “consistency,” in Gilbert and Lynch’s proof of the CAP Theorem. We say linearizability is composable (or “local”) because, if operations on each object in a system are linearizable, then all operations in the system are linearizable.
Serializability: multi-operation, multi-object, arbitrary total order
Serializability is a guarantee about transactions, or groups of one or more operations over one or more objects. It guarantees that the execution of a set of transactions (usually containing read and write operations) over multiple items is equivalent to some serial execution (total ordering) of the transactions.
Serializability is the traditional “I,” or isolation, in ACID. If users’ transactions each preserve application correctness (“C,” or consistency, in ACID), a serializable execution also preserves correctness. Therefore, serializability is a mechanism for guaranteeing database correctness.
Serializability is not composable. Serializability does not imply any kind of deterministic order—it simply requires that some equivalent serial execution exists.
关于 Serializability 和 Linearizability,可以读读分布式系统一致性的发展历史
Transaction Management in the R* Distributed Database Management System
这篇论文的主题是关于分布式数据库系统的事务管理,着重描述了 R* 提交协议:Presumed Abort(PA)和 Presumed Commit(PC)。PA 和 PC 是著名的 two-phase(2P)提交协议的扩展。
Introduction
R* is an experimental, distributed database management system (DDBMS). In a distributed database system, the actions of a transaction (an atomic unit of consistency and recovery) may occur at more than one site. A commit protocol is needed to guarantee the uniform commitment of distributed transaction executions.
Some of the desirable characteristics in a commit protocol are
- guaranteed transaction atomicity always
- ability to “forget” outcome of commit processing after a short amount of time(不需要一直记录结果)
- minimal overhead in terms of log writes and message traffic
- optimized performance in the no-failure case
- exploitation of completely or partially read-only transactions
- maximizing the ability to perform unilateral aborts
Multilevel hierarchical commit protocols are suggested to be more natural than the conventional two-level (one coordinator and a set of subordinates) protocols. With these goals in mind, we extended the conventional 2P commit protocol to support a tree of processes and defined the Presumed Abort (PA) and the Presumed Commit (PC) protocols to improve the performance of distributed transaction commit.
The Two-Phase Commit Protocol
在 2P 提交协议中,分布式事务执行模型包括了一个 coordinator 进程,它连接了客户端应用程序和其他称为 subordinates 的进程。Subordinates 进程彼此之间不交互,只和 coordinator 交互。每个事务分配一个全局唯一的名字。
2P Under Normal Operation
当 coordinator 接收到来自用户的事务提交请求时,并行的发送 PREPARE 消息给 subordinates,此时进入提交协议的第一阶段。如果该事务可以提交,subordinate 先 force-write 一条 prepare log record,之后发送 YES VOTE 给 coordinator,再等待 coordinator 返回最后的决策(commit 还是 abort),之后 subordinate 进入 prepare 状态,无法单方面终止或提交事务。如果 subordinate 决定终止事务,先 force-write 一条 abort record,之后发送 NO VOTE 给 coordinator。因为 NO VOTE 表示否决,subordinate 不需要等待 coordinator,直接终止该事务,释放锁并“忘记”该事务(不需要记录任何信息了)。
当 coordinator 接收到所有 subordinates 的投票时,进入提交协议的第二阶段。如果所有投票都是 YES,则 coordinator 进入 committing 状态:首先 force-write 一条 commit record,发送 COMMIT 消息给所有 subordinates. 在 force-write 成功执行后,事务即可提交,且通知客户端事务已经成功提交。如果 coordinator 有收到 NO VOTE,则进入 aborting 状态:force-write 一条 abort record,发送 ABORT 消息给处于准备状态的或者没有回 PREPARE 消息的 subordinates。
如果 subordinate 收到 COMMIT 消息,则进入 committing 状态:先 force-write 一条 commit record,发送 ACK 消息给 coordinator,然后提交事务并且“忘记”该事务。如果收到的是 ABORT 消息,进入 aborting 状态:force-write 一条 abort record,发送 ACK 消息给 coordinator,然后终止事务并且“忘记”该事务。当 coordinator 收到所有 subordinates 的 ACK 消息(不包括 NO VOTE 的 subordinates),写一条 end record 然后“忘记”该事务。
The general principle on which the protocols described in this paper are based is that if a subordinate acknowledges the receipt of any particular message, then it should make sure (by forcing a log record with the information in that message before sending the ACK) that it will never ask the coordinator about that piece of information.
log 包含了如下内容:
- the type (prepare, end, etc.) of the record
- the identity of the process that writes the record
- the name of the transaction
- the identity of the coordinator
- the names of the exclusive locks held by the writer in the case of prepare records
- the identities of the subordinates in the case of the commit/abort records written by the coordinator
总结下,提交事务总共需要:
- subordinate 写两条记录:prepare record 和 commit record,且发送两条消息:YES VOTE 和 ACK
- coordinator 发送两条消息:PREPARE 和 COMMIT,以及写两条记录:commit record(force-write)和 end record(非 force-write)
2P and Failures
每个站点都存在一个 recovery 进程,处理来自其他站点的 recovery 进程的信息。当从 crash 中恢复时,recovery 进程读取 stable storage 的 log,并且在 virtual storage 中重建。在 virtual storage 的这部分信息有下列用途:
- 应答其他站点发来的事务查询请求,这些事务的 coordinators 是运行在该挂掉的站点上(answer queries from other sites about transactions that had their coordinators at this site)
- 发送事务的查询信息给其他站点的 subordinates,这些事务的 coordinators 是运行在该挂掉的站点上(send unsolicited information to other sites that had subordinates for transactions that had their coordinators at this site)
在 virtual storage 构建的好处在于可以快速回应其他站点的查询,而不需要从 stable storage 查询日志。
当 recovery 进程发现有事务处于 prepare 状态,则会定期向 coordinator 询问该事务应该如何处理(commit 还是 abort)。如果 recovery 进程发现有事务在执行过程中崩溃,没有留下任何日志,则直接回滚操作,写一条 abort record,然后“忘记”。
如果 recovery 进程发现事务处于 committing/aborting 状态,它将尝试定期发送 COMMIT/ABORT 给所有还没 ACK 过的 subordinates。一旦收到所有 ACK,则写一条 end record 并且“忘记”该事务。
如果 recovery 进程收到一条事务查询,但 virtual storage 中没有该事务的信息,则直接返回 ABORT。
The Presumed Abort Protocol
上一节提到,在找不到关于事务的信息时,recovery 进程将返回 ABORT。这意味着当 coordinator 决定要 abort 事务时,可以直接“忘记”该事务,coordinator 和 subordinates 不再需要 force-write 一条 abort record,subordinates 也不需要 ACK 来自 coordinator 的 ABORT 消息。coordinator 也不在需要记录 end record 了。
只读事务的情况下,leaf 进程直接返回 READ VOTE,释放锁,且“忘记”该事务。 A nonroot, nonleaf sends a READ VOTE only if its own vote and those of its subordinates’ are also READ VOTES. Otherwise, as long as none of the latter is a NO VOTE, it sends a YES VOTE.(存在部分只读事务)
There will not be a second phase of the protocol if the root process is readonly and it gets only READ VOTES. In this case the root process, just like the other processes, writes no log records for the transaction.
总结下,完全只读事务,所有进程都不需要写任何 log record。每个 nonleaf 进程发送一条 PREPARE 消息,每个 nonroot 进程发送一条信息 READ VOTE 消息。
ZooKeeper Note
Zookeeper: a generic “master” service
Design challenges:
- What API?
- How to make master fault tolerant?
- How to get good performance?
Challenges interact: good performance may influence API e.g., asynchronous interface to allow pipelining
Sessions: clients sign into zookeeper
-
Session allows a client to fail-over to another zookeeper service Client know the term and index of last completed operationsend it on each request. Service performs operation only if caught up with what client has seen.
-
Sessions can timeout Client must refresh a session continuously send a heartbeat to the server (like a lease). Zookeeper considers client “dead” if doesn’t hear from a client. Client may keep doing its thing (e.g., network partition) but cannot perform other zookeeper ops in that session
Challenge: Duplicates client requests
-
Scenario Primary receives client request, fails Client resends client request to new primary
-
Lab 3: Table to detect duplicates Limitation: one outstanding op per client(缓存回包,所以需要等上一个请求处理完,才能处理下一个请求,对比是否重复,重复的话返回已经缓存好的回包) Problem problem: cannot pipeline client requests
-
Zookeeper: Some ops are idempotent period Some ops are easy to make idempotent: test-version-and-then-do-op Some ops the client is responsible for detecting dups Consider the lock example. Create a file name that includes its session ID “app/lock/request-sessionID-seqno” zookeeper informs client when switch to new primary client runs getChildren() if new requests is there, all set if not, re-issue create
Problem: read may return stale data if only master performs it
Zookeeper solution: don’t promise non-stale data (by default)
- Reads are allowed to return stale data
- Reads can be executed by any replica
- Read throughput increases as number of servers increases
- Read returns the last zxid it has seen So that new primary can catch up to zxid before serving the read Avoids reading from past
- Only sync-read() guarantees data is not stale
Sync optimization: avoid ZAB layer for sync-read
Must ensure that read observes last committed txn. Leader puts sync in queue between it and replica. If ops ahead of in the queue commit, then leader must be leader, otherwise, issue null transaction.(In same spirit read optimization in Raft paper, see last par section 8 of raft paper)
2P Note
What about concurrent transactions?
1
2
3
4
5
6
7
8
9
10
11
x and y are bank balances
x and y start out as $10
T1 is doing a transfer of $1 from x to y
T1:
add(x, 1) -- server A
add(y, -1) -- server B
T2:
tmp1 = get(x)
tmp2 = get(y)
print tmp1, tmp2
Problem: What if T2 runs between the two add() RPCs? Then T2 will print 11, 10 money will have been created! T2 should print 10,10 or 9,11.
The traditional correctness definition is “serializability”. Results should be as if transactions ran one at a time in some order as if T1, then T2; or T2, then T1. The results for the two differ, either is OK.
“Two-phase locking” is one way to implement serializability. Each database record has a lock. The lock is stored at the server that stores the record. Transaction must wait for and acquire a record’s lock before using it. Thus add() handler implicitly acquires lock when it uses record. x or y transaction holds its locks until after commit or abort.
What are locks really doing?
- When transactions conflict, locks delay one to force serial execution.
- When transactions don’t conflict, locks allow fast parallel execution.
Raft and two-phase commit solve different problems!
-
Use Raft to get high availability by replicating, i.e. to be able to operate when some servers are crashed. The servers all do the same thing
-
Use 2PC when each subordinate does something different and all of them must do their part. 2PC does not help availability since all servers must be up to get anything done. Raft does not ensure that all servers do something since only a majority have to be alive.
What if you want high availability and distributed commit?
- Each “server” should be a Raft-replicated service
- And the Transaction Coordinator(TC) should be Raft-replicated
- Run two-phase commit among the replicated services
Then you can tolerate failures and still make progress.