前言
这篇文章是《漫谈分布式》系列文章的第二篇,讲解分布式系统中数据复制的方式,讨论了分布式系统的一致性模型,以及在分布式系统中如何确定事件时序,如何解决不同数据复制方式下的一致性问题和写冲突问题。
数据复制
复制即将同一份数据备份在多台不同的节点,节点之间网络互通。为什么需要复制?复制能带给什么好处?
- 数据多地部署,用户可以选择就近接入,减少时延。
- 提高可用性,部分节点挂掉不影响整个系统的运作。
- 提高读操作的性能,多个拥有数据备份的节点都可以处理读请求。
复制有两种实现方式:基于 leader(single-leader 和 multi-leader)复制以及无 leader(leaderless)复制。
基于单 leader 的复制 Leader-Based Replication
基于单 leader 的复制,又或主从复制的实现下,某个节点被选举为 leader,其他节点为 follower。写操作必须经由 leader 处理,leader 先写本地存储,同时转发给 follower,follower 必须采用和 leader 同样的操作顺序更新本地存储。读操作则可以由 leader 或者 follower 处理(follower 可能会返回过期数据)。
因为 leader 到 follower 的数据同步总是需要时间,follower 相比 leader 数据总存在一定的延时。主从复制分为两种方式:同步和异步。若采用同步复制的方式,leader 必须阻塞等到 follower 成功接收更新数据后才会返回成功,但这样某个 follower 节点挂了就会影响到整个系统的可用性,因此通常同步复制的方式只要求其中一台 follower 是同步的,其他为异步复制。如果同步复制的 follower 挂掉了,就重新选出一台 follower 作为同步复制的 follower,这种方式通常也称为半同步复制(Semi-Synchronous)。论文 Semi-Synchronous Replication at Facebook 介绍了半同步复制在 facebook 的实践。
尽管异步复制的方式可能会丢数据,例如 leader 挂了,来不及将最新的数据复制给 follower 的情况下。但在实际中却是应用最广泛的。除了同步异步复制,目前还有其他方向的探索,比如 chain replication,有兴趣的参考附录的论文。
复制日志的形式
主从同步的复制日志有不同的形式,包括了 statement-based、wal、row-based,另外还有基于 trigger 的方式。
基于语句复制 Statement-Based Replication
通过字面可以看出,基于语句复制即把 leader 执行的语句原封不动的转发给 follower 去执行。优点是写入少,只需要记录操作语句,不需要记录所有受影响的行。但这种方式存在如下的问题:
- 调用非确定性函数时,例如 NOW() 或者 RAND(),主从可能会返回不同的结果,进而导致主从的数据不一致。
- 当执行语句涉及自增字段,或涉及到条件判断,需要保证主从执行语句的顺序严格一致。这意味着在执行的时候需要加更多的锁,影响并行事务的执行效率。
If statements use an autoincrementing column, or if they depend on the existing data in the database (e.g. UPDATE … WHERE
), they must be executed in exactly the same order on each replica, or else they may have a different effect. This can be limiting when there are multiple concurrently executing transactions. -- 摘自《Designing Data-Intensive Applications》 - 执行带副作用的语句,例如 trigger、UDF,同样可能产生非确定性的结果。
预写日志 Write-Ahead Log (WAL) Shipping
上一篇文章提到说 LSM 和 B-Tree 在写操作前都会记录 wal,wal 中以追加的形式记录每次对数据库的写操作。PostgreSQL 和 orcale 就采用了这种做法,参考论文 WAL Internals Of PostgreSQL。但 wal 和存储引擎实现息息相关,两者强耦合,如果升级了存储引擎,可能导致前后不兼容。
逻辑日志复制 Logical (Row-Based) Log Replication
相比起 WAL,采用基于行的日志进行复制可以与存储引擎的实现解藕,因此基于行日志也称为逻辑日志,以区分存储引擎中数据的物理存储形式。
逻辑日志记录的是数据的详细变化。以关系型数据库举例,插入操作的逻辑日志记录了新插入记录所有字段的值;删除操作记录的是所删除记录的主键(如果没有主键则需要记下所删除记录所有字段的值);更新操作记录的是主键以及所更新字段的值。
MySQL 的 binlog 从 5.1 版本起支持逻辑日志格式。这里以 Python-Mysql-Replication 给的 demo 为例,展示下 binlog 所记录的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
=== WriteRowsEvent ===
Date: 2012-10-07T15:03:16
Event size: 27
Read bytes: 10
Table: test.test4
Affected columns: 3
Changed rows: 1
Values:
--
* data : Hello
* id : 1
* data2 : World
=== UpdateRowsEvent ===
Date: 2012-10-07T15:03:17
Event size: 45
Read bytes: 11
Table: test.test4
Affected columns: 3
Changed rows: 1
Affected columns: 3
Values:
--
* data : Hello => World
* id : 1 => 1
* data2 : World => Hello
=== DeleteRowsEvent ===
Date: 2012-10-07T15:03:17
Event size: 27
Read bytes: 10
Table: test.test4
Affected columns: 3
Changed rows: 1
Values:
--
* data : World
* id : 1
* data2 : Hello
逻辑日志的格式更容易被外部应用解析,如果你希望实现离线数据分析,或者数据缓存,可以很方便通过解析逻辑日志来实现,这种技术也称为 change data capture (CDC)。
详细关于 statement-based 和 row-based 的对比可以参考 mysql 官方文档 Advantages and Disadvantages of Statement-Based and Row-Based Replication
基于触发器复制 Trigger-Based Replication
还可以采用关系型数据库提供的 triggers 和 stored procedures 来实现主从复制,但会带来更大的性能损耗,也容易引入更多的 bug。不过 trigger-based 的方式提供了更大的灵活性,比如可以只复制数据库中的某张表。
数据延迟引发的一致性问题
主从之间数据的延迟(Replication Lag)可能会带来一致性的问题。下面列举几个一致性模型(关于一致性模型的讨论可参阅附录)说明数据延迟可能引发的问题:
写后读一致性 Read-After-Write Consistency
写后读一致性(Read-After-Write Consistency 或 Read-Your-Writes Consistency)保证一旦数据写入成功,后续的读操作总是能读到写入的数据。但在异步复制模式下,主从数据存在延迟时却会出现读不到最新写数据的情况:
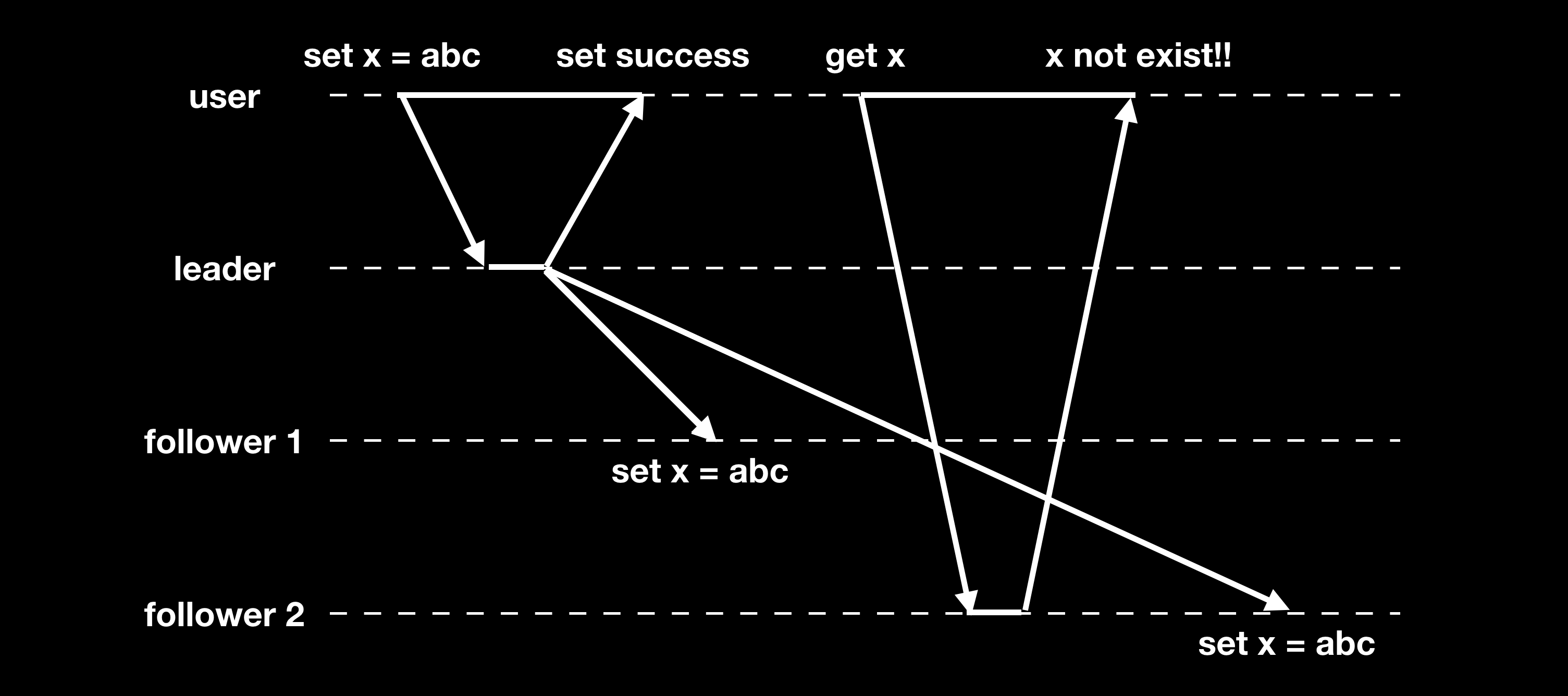
通常解决方法有以下几种:
- 用户修改过的数据始终从 leader 读。
- 记录玩家最后的写操作时间,读请求的时候带上,根据最后的写操作时间将请求路由到足够新的节点上处理。
涉及到多 datacenter 或者用户使用多客户端进行请求的时候,处理起来更加麻烦一些。
单调读一致性 Monotonic Reads Consistency
单调读一致性保证读操作返回的结果不会倒退。同样异步复制下可能会出现读回退的状况:
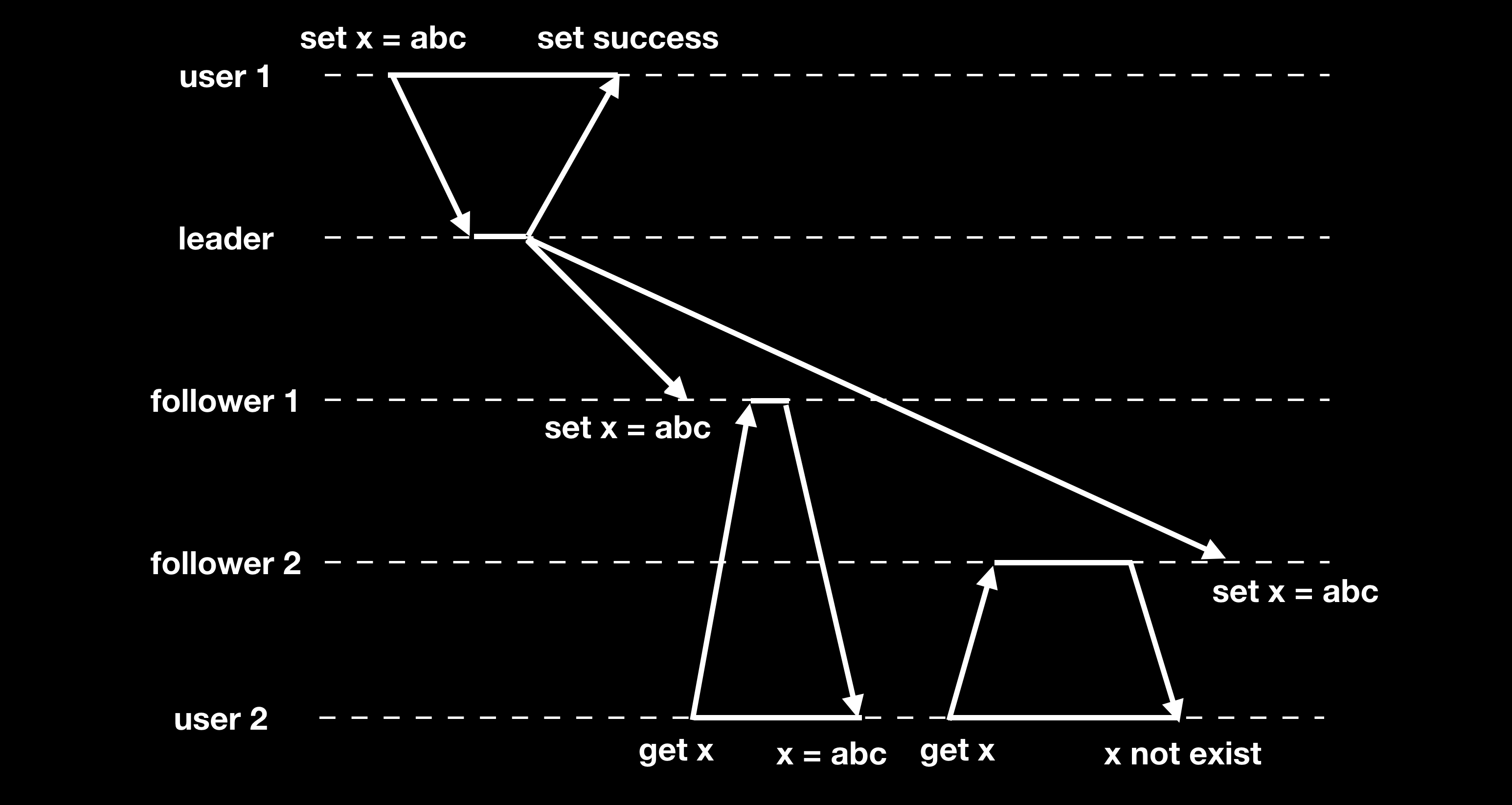
解决方法可以根据用户 id 通过哈希路由到固定的 replica 节点,每次都从该节点读,但在节点扩容的话哈希路由规则可能会失效。
前缀一致性 Consistent Prefix Reads Consistency
前缀一致性提供如下保证:如果写操作以一定的顺序执行,那么读出来的结果必须和写操作的执行顺序相同。如果数据库不同分区独立执行写操作,则会出现不一致的问题:
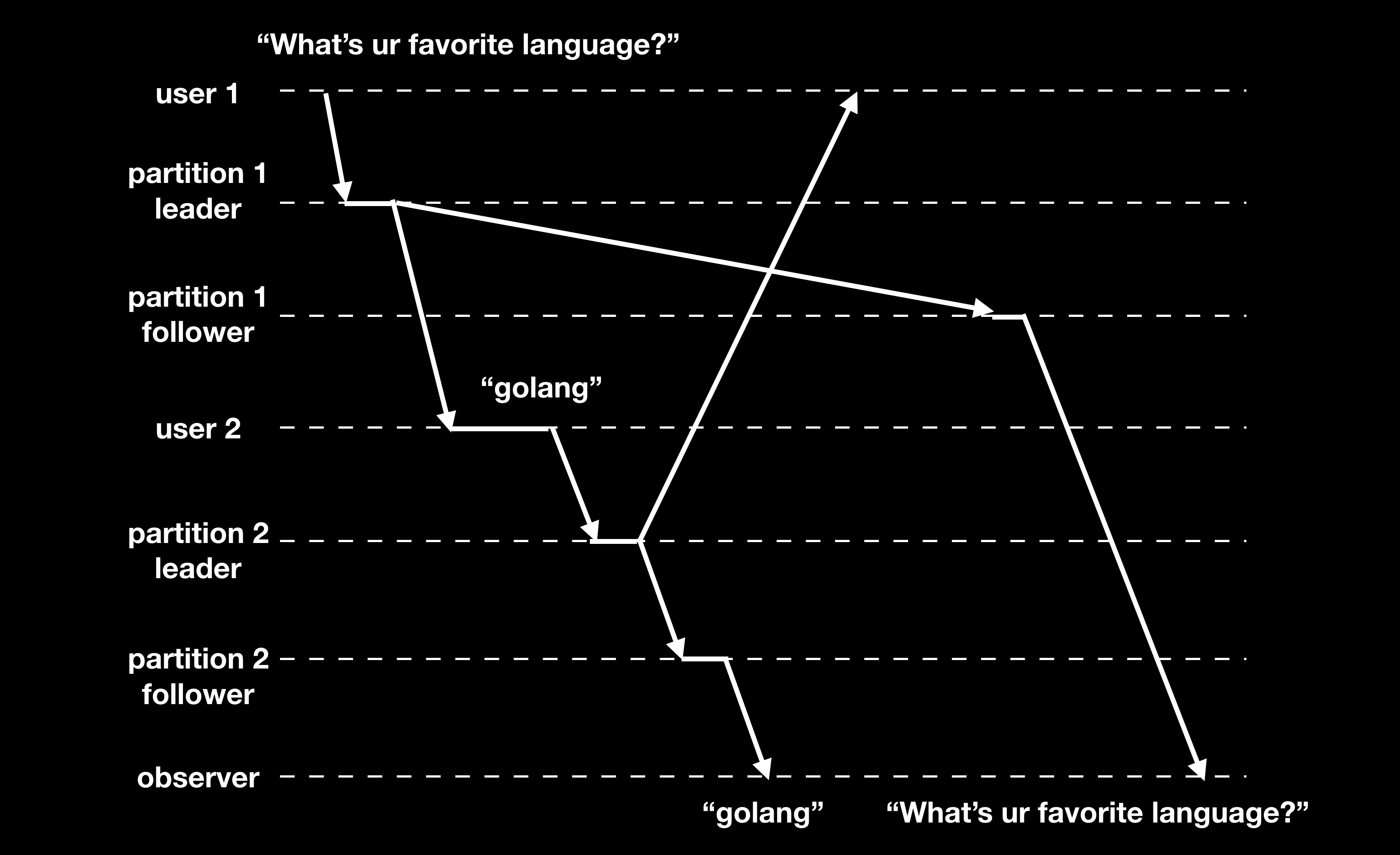
解决这种问题,可以将所有关联的写操作都写入到同一个分区中,或者需要维护写操作的因果关系。
多 leader 复制 Multi-Leader Replication
多 leader 复制模式下,允许多个节点处理写请求。处理写操作的同时转发给其他所有的节点。该模式下 leader 同时扮演其他 leader 的 follower 的角色。
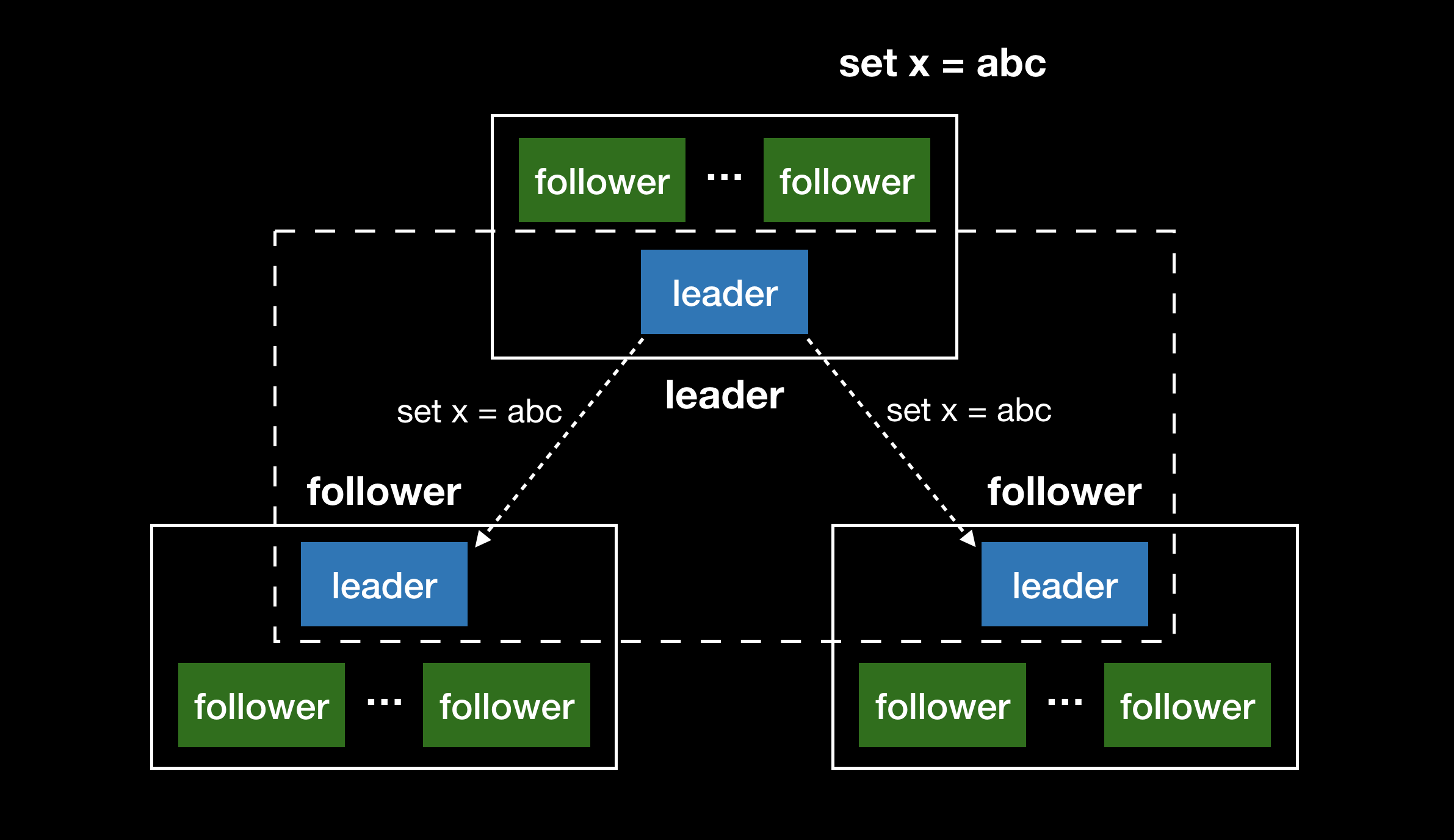
应用场景
多数据中心
多数据中心可以实现就近接入,每个数据中心都有自己的 leader 处理写请求,每个数据中心内为基于单 leader 的复制模式。当某个数据中心数据更新时,该数据中心的 leader 会同步给其他数据中心的 leader,其他 leader 此时就扮演 follower 的角色。
离线客户端模式
例如 Evernote,支持在不同的客户端设备上编辑并且多设备同步。每个设备是一个 datacenter,可以独立处理写操作,允许离线编辑。恢复网络之后,会把本地修改同步给其他设备。
协作编辑
例如 Etherpad、Google Docs 允许用户同时编辑文档。协作编辑的场景下,用户的修改首先写入到本地存储(本地 web 浏览器或本地客户端),然后再被异步同步到其他用户的终端。避免多个终端写冲突可以采用加锁的方式,下面小节会详细讨论写冲突。
写冲突问题
多 leader 会引入一个难以解决的问题:因为允许多个节点处理写操作,存在同一份数据被不同的节点同时修改造成写冲突的风险。State of the Art for MySQL Multi-Master Replication 总结了四类解决方法:
- 悲观锁 Pessimistic Locking:Wait your turn, pal!
- 乐观锁 Optimistic Locking:Early bird gets the worm
- 解决冲突 Conflict Resolution:Your mother cleans up later
- 避免冲突 Conflict Avoidance:Solve the problem by not having it
下面列举一些解决写冲突的具体方式:
采用同步复制
同步复制,直到所有的 replica 都复制成功了才返回给用户写操作成功。但这种方式牺牲了多 leader 最突出的优势:支持多个节点独立地处理写操作。
规避写冲突
最简单的策略是规避写冲突,将相同记录的写操作路由到同一个 leader 进行。但在缩容扩容或者节点挂掉导致路由规则修改的情况下,还是可能会出现写冲突。
收敛冲突至一致状态
还可以采用收敛写冲突的方式,比如:
- 给每个写操作或每个 replica 赋值一个唯一 ID,采用 last write wins(LWW)的方式,但可能会造成数据丢失。Cassandra 就采用了该策略。
- 将冲突的写数据进行排序然后按字符拼接,这种只对字符型值有效,而且简单拼接不一定能得到有意义的结果。
- 保存写冲突的必要信息,由应用层处理,一般分为 on read 和 on write 这两种方式。Dynamo 和 CouchDB 就采用了这种做法。Dynamo 使用了向量时钟(vector clock)来记录各版本的写操作信息,提供给应用侧去合并。
- 自动解决冲突(automatic conflict resolution),例如 operational transformation、conflict-free replicated datatypes 和 mergeable persistent data structures,可参阅附录。
一致性问题
由于节点数据同步存在延迟,多 leader 同样可能存在和单 leader 一样的一致性问题。如下图,由于各节点间消息传递的网络延迟快慢,导致违背了前缀一致性:
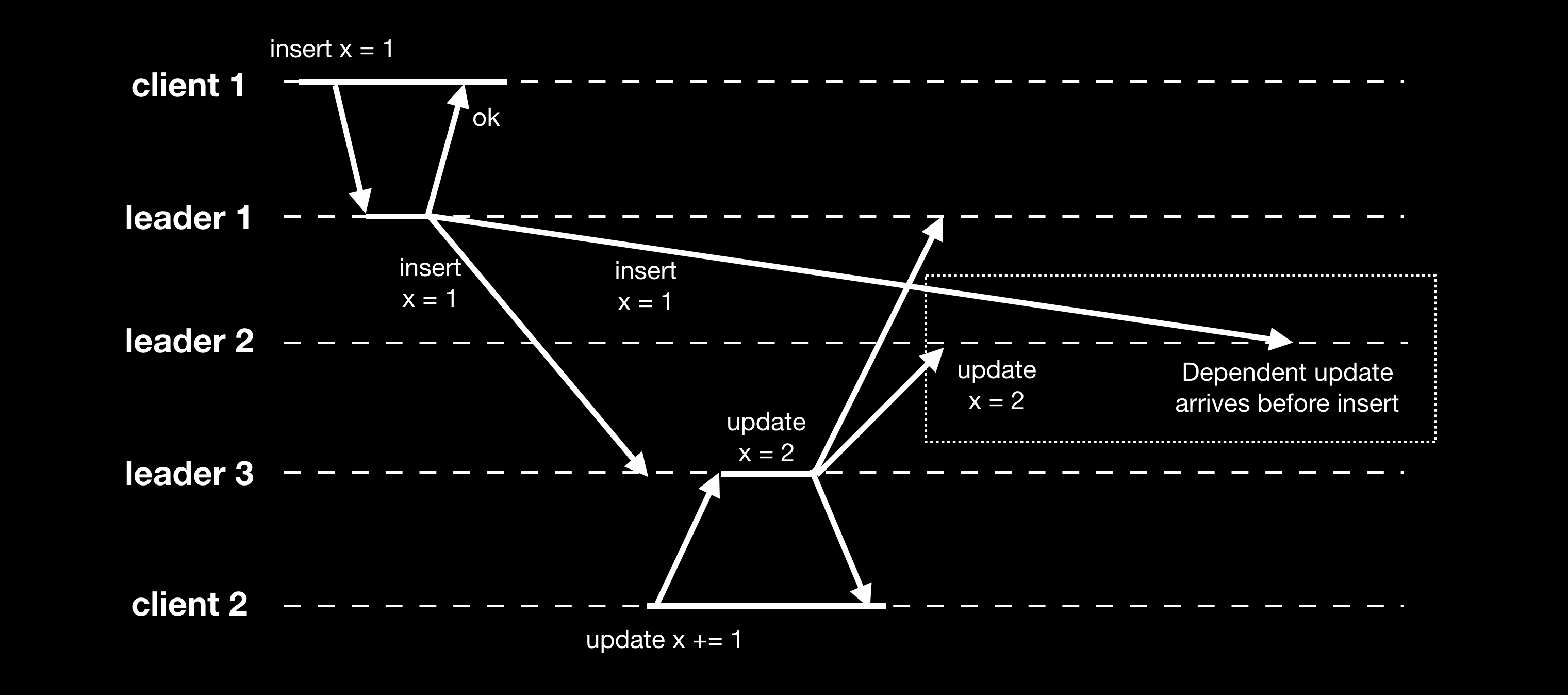
因为不同机器的时间可能存在差异,给写操作附上时间戳也无法解决上述问题。后续小节介绍的版本向量可以用以处理事件的因果关系,但通常多 leader 复制的模式下基本上不检测处理写冲突,也不处理事件的先后时序。
无中心复制 Leaderless Replication
之前讨论的单 leader 和多 leader 模式下,都是由 leader 来决策写操作顺序,follower 以和 leader 相同的操作顺序执行。而无中心复制(leaderless replication)则摒弃了 leader 的概念,每个 replica 都可以接收处理写操作。Dynamo 的出现极大推动了无中心复制的发展,因此无中心复制也称为 dynamo-style。
Quorum 读写
无中心复制模式下读写操作流程如下图,客户端的读写操作是并行地发给多个 replica 的:
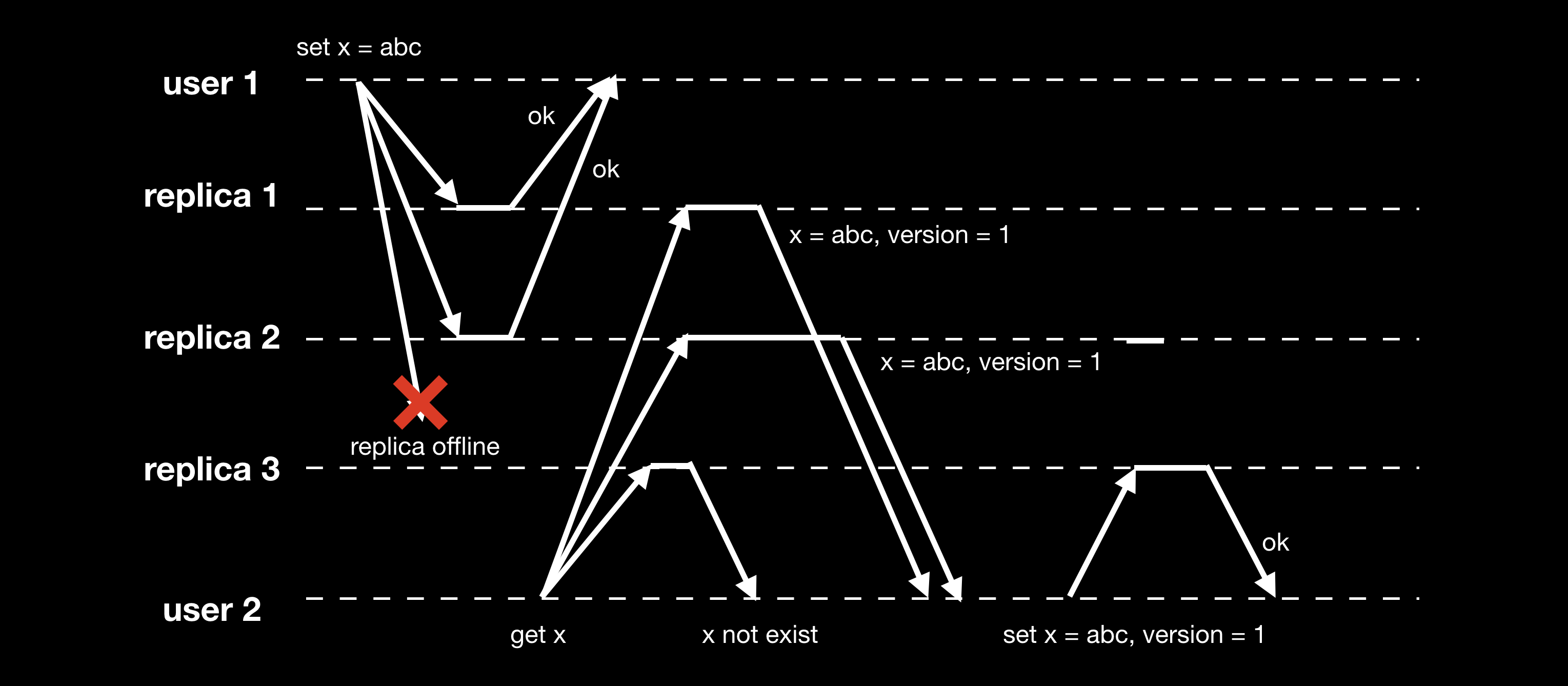
无中心复制采用 quorum 机制进行读写操作:假设有 n 个 replica,写操作需要至少 w 个节点确认才认为是成功,读操作至少需要查询 r 个节点,当 w + r > n 时,能保证读取到最新的数据,这种方式称之为 quorum reads and writes。一般来说,r 和 w 会取超过 n/2 的值,以保证 r + w > n。但实际上 r 和 w 并没有必要一定取超过 n/2 的值,只需要保证 w 和 r 有交集即可,论文 Flexible Paxos: Quorum Intersection Revisited 探讨了其他一些方案。
Quorum 虽然简单但并不是十全十美,例如下图:
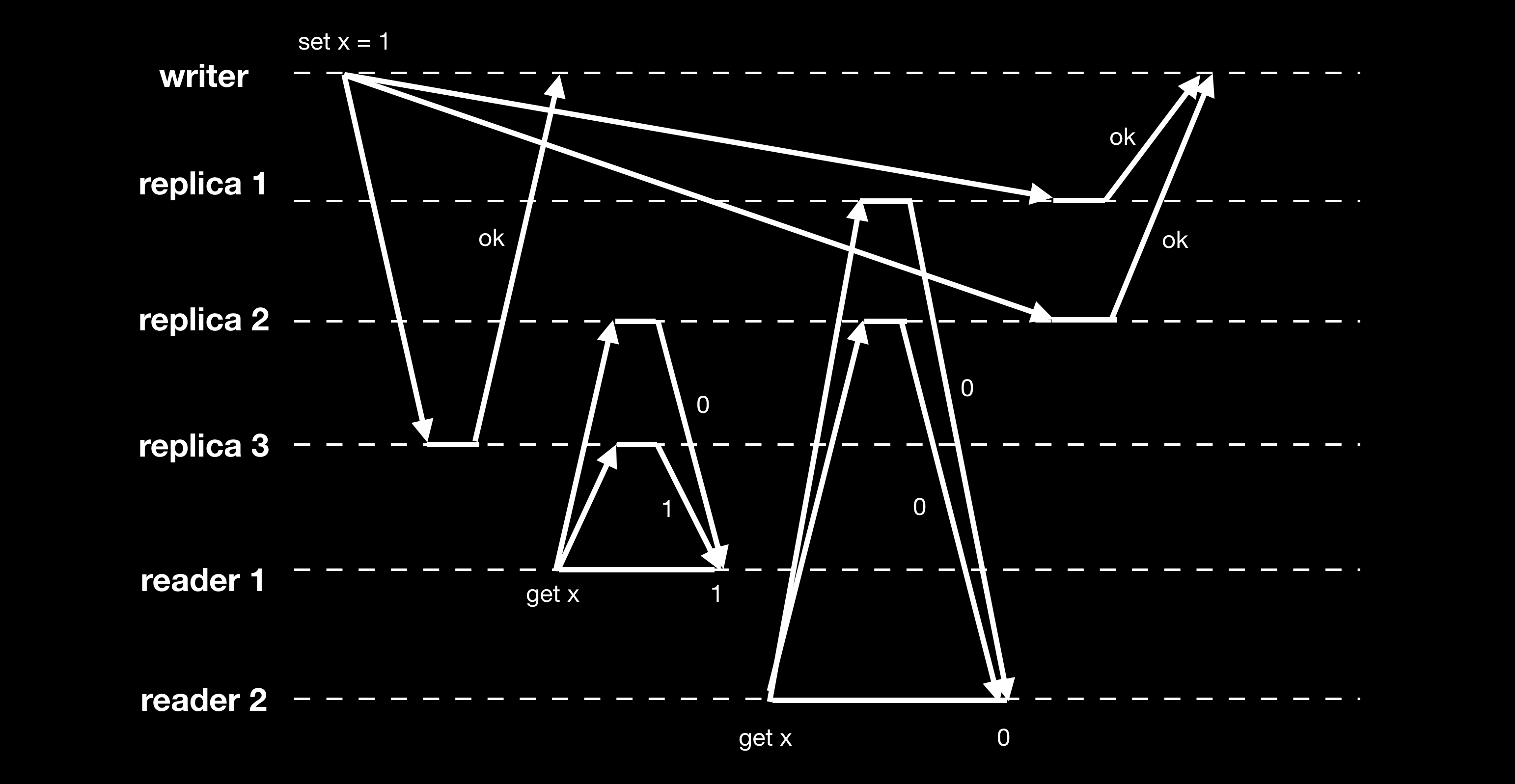
reader2 的读请求在 reader1 之后,但却返回的是旧值,不符合线性一致性(linearizable)。这种情况可以在读操作时强制更新过期数据来保证线性一致性:reader1 读取到 replica2 的数据是过期之后,先同步执行 read repair 更新 replica2 的过期数据后才返回客户端结果,写操作需要在写之前先读取 quorum 个节点的数据。
Dynamo-style 数据库使用的 quorum 机制通常只能保证最终一致性,并不能提供 Read-After-Write Consistency、Monotonic-Read Consistency、Consistent-Prefix Consistency,更强的一致性需要事务或者一致性算法来提供。有关 dynamo-style 一致性的讨论,可以看看 Bringing Consistency to Riak。
为了使 replica 达成最终一致,通常会采用 read repair 和 anti-entropy 的方式:
-
Read repair
读操作 replica 返回过期数据时,会把最新数据写回该 replica。
-
Anti-entropy process
Read repair 只会在读的时候修复数据,而没有被读取的冷数据,则可以通过 anti-entory process 的方法,后台起一个进程检查数据差异,同步数据。但整个过程是无序的,并不会按照写操作的先后顺序。
基于 leader 的模式下,因为 follower 和 leader 都是按相同的顺序执行复制日志,因此可以通过比对复制日志的执行位置来监控主从数据复制延迟。但在无中心复制模式下,各个 replica 的执行顺序并不保证相同,因此没有办法按照基于 leader 模式的方法去监控。关于 无中心复制模式下监控复制延迟的一些探讨,可以看看论文 Quantifying Eventual Consistency with PBS。
Cassandra 和 voldemort 使用了无中心模式来支持多数据中心。Riak 在跨数据中心则采用的是类似多 leader 复制模式,具体请看 Riak Enterprise: Multi-Datacenter Replication
写冲突
无中心复制模式下同样存在写冲突的可能性:
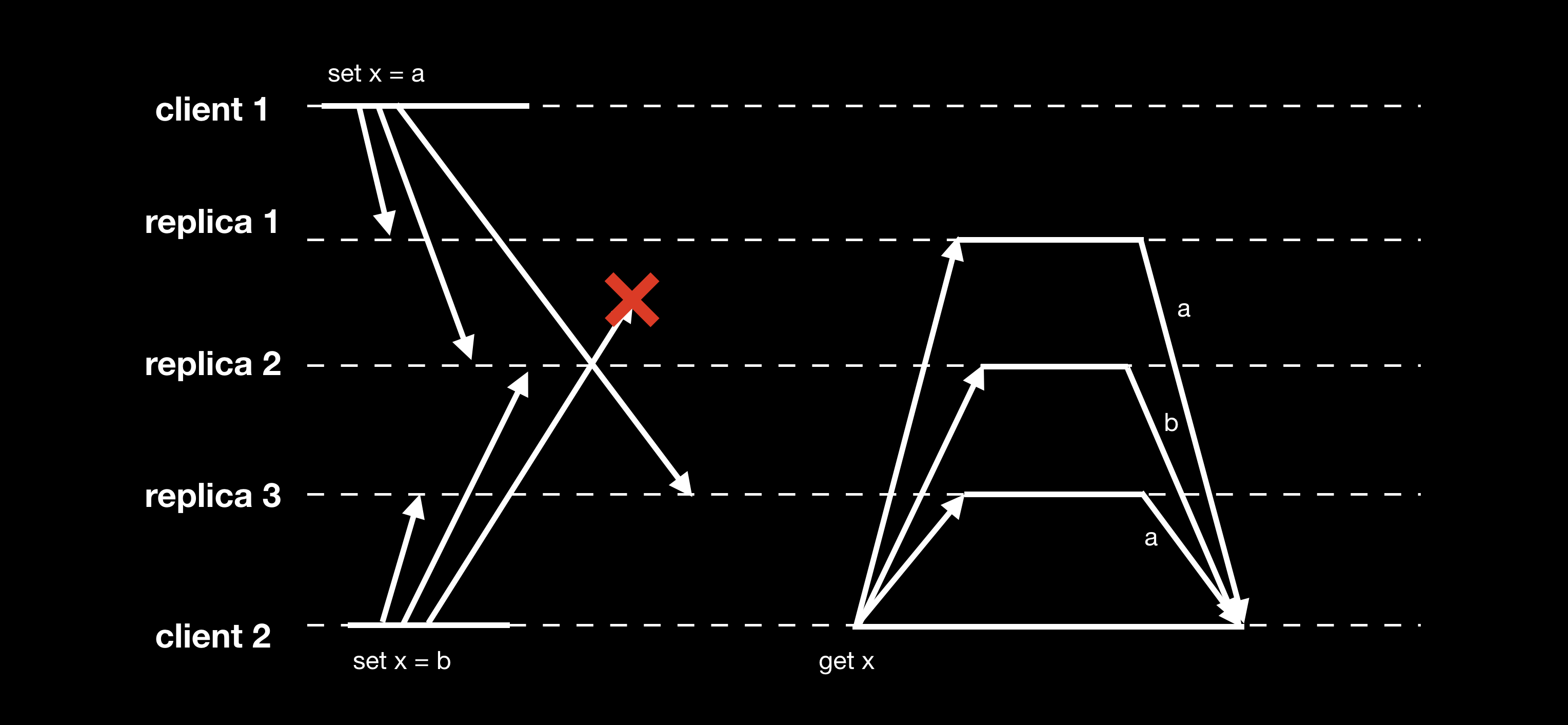
Replica 2 认为最终 x 的值为 b,replica 3 认为最终 x 的值为 a。
Last Write Wins
之前提到可以采用 lww 的方法来最终收敛写冲突,每个 replica 只保存“最近”的值。问题在于,如何定义“最近”?上图的例子可以认为两个写操作是同时的,很难去定义谁先谁后。在这种情况下,虽然我们可以采用 lww 算法,给每个写操作赋予一个 ID,例如时间戳,来给写操作强行排序。但 lww 存在写丢失的问题(给客户端返回成功,实际上同时多个写请求只有一个能成功),而且 lww 并不能真实地反应出写操作的先后顺序。
事件时序
基于 leader 的模式下,由 leader 对写操作进行排序,follower 严格按照与 leader 相同顺序来执行。而在无中心模式下,多个节点如何定义事件先后顺序?如何判断两个操作是否同时发生?每台机器的时间可能存在差异,消息的传递在不同的网络状况下有不同的延迟,因此在分布式系统中以物理时间或者消息接收的顺序来决定事件发生的顺序是不准确的。
Lamport 逻辑时钟
Lamport 在论文 Time, Clocks and the Ordering of Events in a Distributed System 中提出了逻辑时钟的概念来描述分布式系统中事件的时序。
Lamport 通过消息传递定义了 “happened before” 关系,以符号 -> 表示:
- 如果在一个进程中,a 发生于 b 之前,那么 a->b。
- 如果 a 是发送一条消息的事件,而 b 是接收这条消息的事件,那么 a->b。
- 若 a->b 成立,且 b->c 成立,则 a->c 也成立。如果 a、b 不满足 a->b 和 b->a,那么认为 a、b 两个事件是同时发生的。
定义 Ci<a> 为进程 Pi 上事件 a 的逻辑时钟。正确定义的逻辑时钟需要满足:如果 a->b,则 C<a> 需要小于 C<b>。要实现正确的逻辑时钟,需要满足以下条件:
- 如果 a、b 事件属于同一个进程,且 a 发生在 b 之前,那么C<a> 小于 C<b>。
- 如果 a、b 是不同进程中的事件,且 a 是发送消息的事件,而 b 是接收这条消息的事件,那么C<a> 小于 C<b>。
实现 Lamport 时钟的算法如下:
- 每个进程 Pi 维护本地计数器 Ci,初始为 0。
- 每次执行事件,计数器 Ci 自增。
- 进程 Pi 发消息时需要带上自己的计数器 Ci。当进程 Pj 接收到消息时更新本地的计数器 Cj = Max(Ci, Cj) + 1。
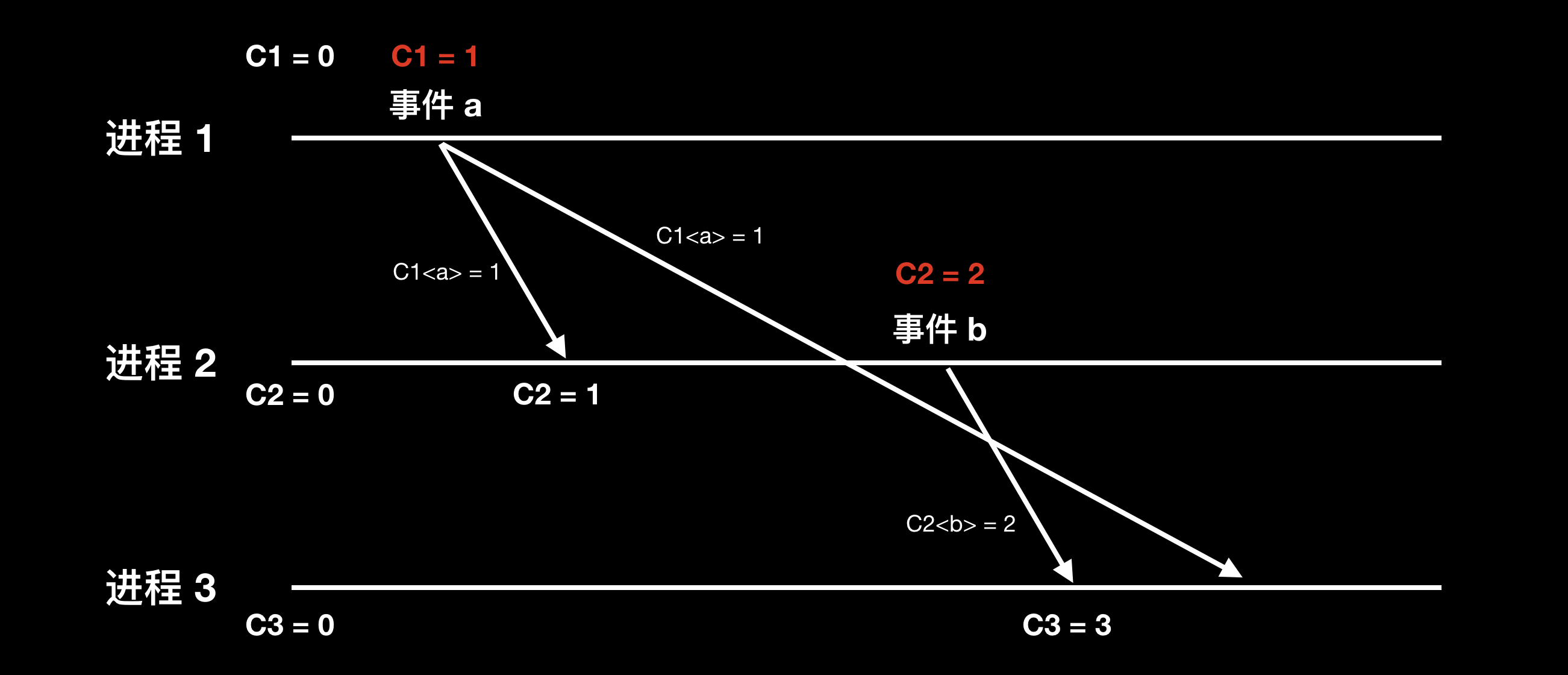
版本向量 Version Vectors
Lamport 逻辑时钟定义了事件的全序关系,但分布式系统中多个节点发生的事件其实是属于偏序关系,即存在不相关的无法比较先后顺序的事件,此时用逻辑时钟进行比较就没有意义。换句话说,当 C<a> 小于 C<b>,无法推导出 a 事件先于 b 事件发生,a 和 b 也有可能同时发生。举下图的例子来说:
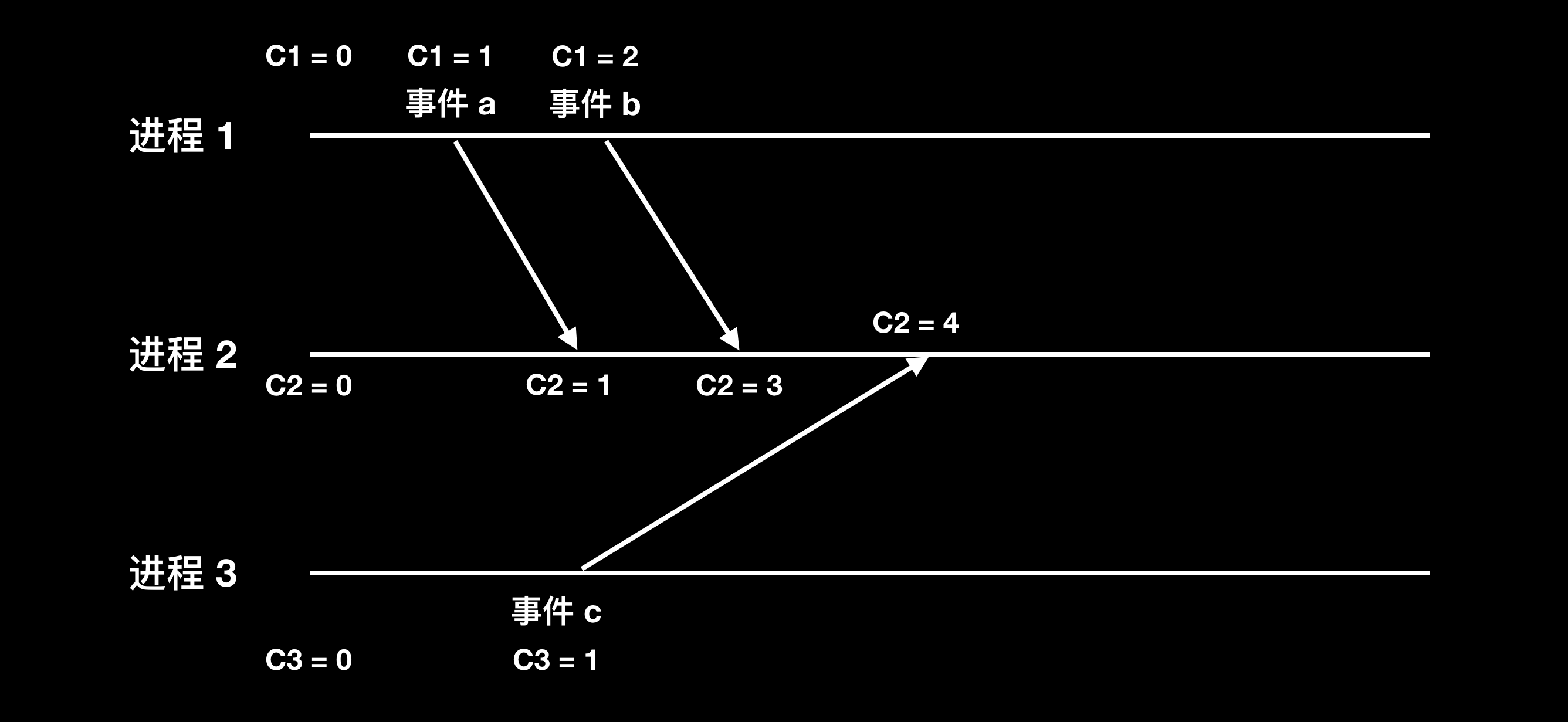
事件 c 和事件 b 是无因果关系、同时发生的,但 C3<c> 小于 C1<b>
如何检测同时发生的事件?先以单一节点的数据库为例,通过在请求和回包带上版本号,可以判断写操作是否是同时发生。如下图所示:
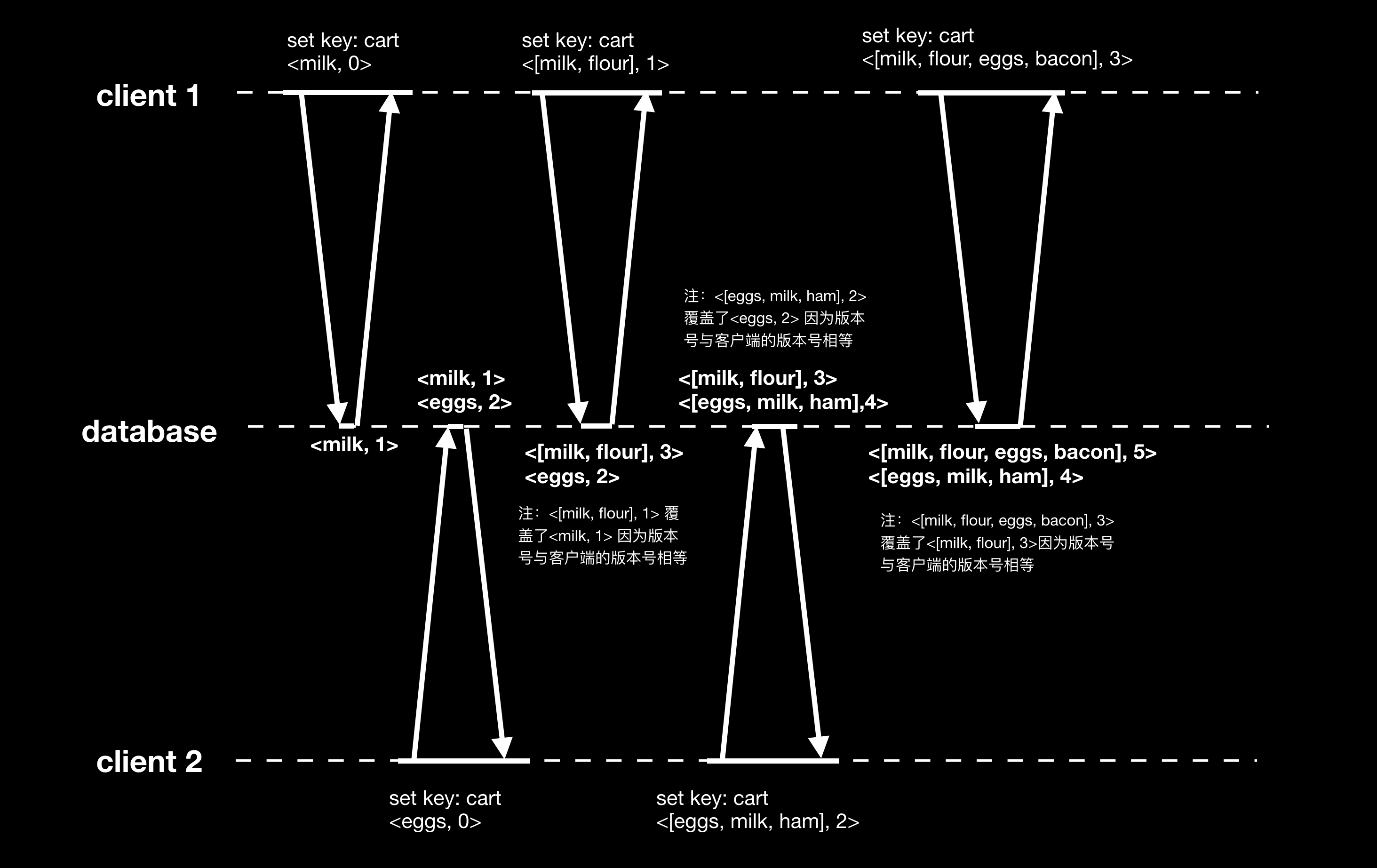
算法的流程如下:
- 服务端每个节点对每个 key 维护一个版本号,每次写操作都会递增版本号,并且写入的值会关联最新的版本号。例如<milk, 1> 表示值 milk 关联的版本号为 1。
- 客户端每次读操作,服务端返回所有的值和关联的版本号。
- 客户端每次写操作都会带上客户端接收过的最新版本号,并且客户端需要对读取到的多个版本号的值进行合并。
- 服务端收到客户端的写操作时,会将小于等于客户端请求版本号的值覆盖,保留高于客户端版本号的值,因为高于客户端版本号写入的值属于同时写(注意这里的同时写并非指真正的“同时发生”,而是说这两个写操作并无因果关系)。
将算法从单节点扩展成多个 replica,则每个 replica 都需要维护所有 replica 的版本号,这个版本号的集合即称之为版本向量 version vector 。每个 replica 在写操作时递增自身的版本号,发送消息时需要带上自己的版本向量,接收消息的 replica 需要对齐自己的版本向量。如下图,中括号表示所有 replica 的版本号向量 [replica 1 版本号,replica 2 版本号,…,replica n 版本号]:
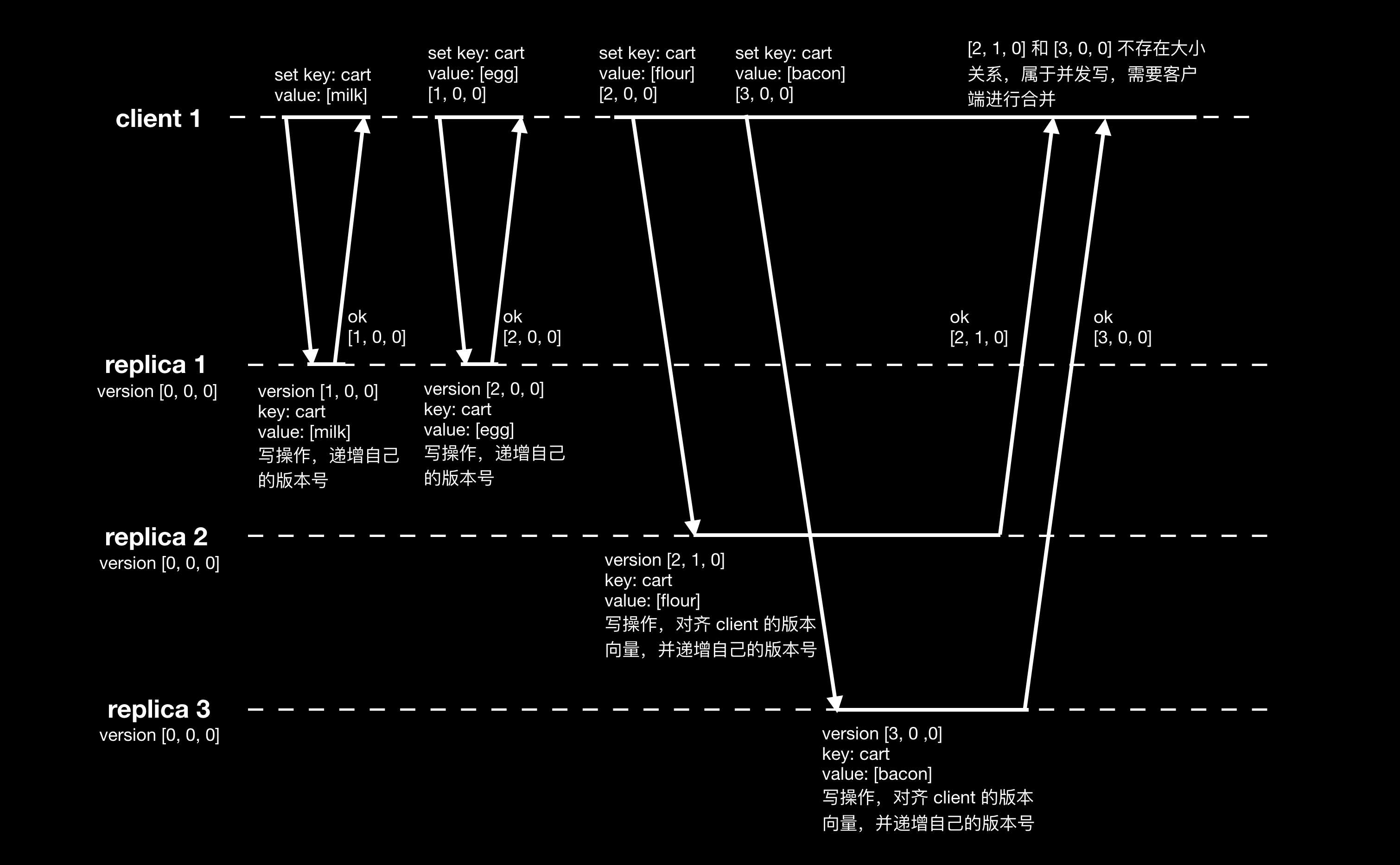
当事件 A 的版本向量在各个维的值都小于等于事件 B 的版本向量,并至少有一个维的值小于 B 的版本向量时,则事件 A 的版本向量小于事件 B 的版本向量,同时可以推导出事件 A 发生在事件 B 之前。如果两个事件的版本向量不存在大小关系,则认为这两个事件是同时发生,不存在先后顺序。上图中客户端最后读取 replica 2 返回值的版本向量为 [2, 1, 0],读取 replia 3 返回值的版本向量为 [3, 0, 0],这两个版本向量不存在大小关系,表示这两个值是同时写入的,需要客户端对这两个值进行合并。
版本向量对逻辑时钟进行了扩展,与逻辑时钟不同,版本向量对事件定义了严格的偏序关系,版本向量的大小准确地反映了事件的时序。Riak 使用了其变种 dotted version vector,具体可以参阅论文 Vector Clocks Revisited Part 2: Dotted Version Vectors 和 A Brief History of Time in Riak
附录
一致性模型
从学术的角度,一致性模型主要有两种分类方式:以数据为中心的一致性模型和以客户为中心的一致性模型。
以数据为中心的一致性是从多节点数据存储的角度出发,分为以下几类:
-
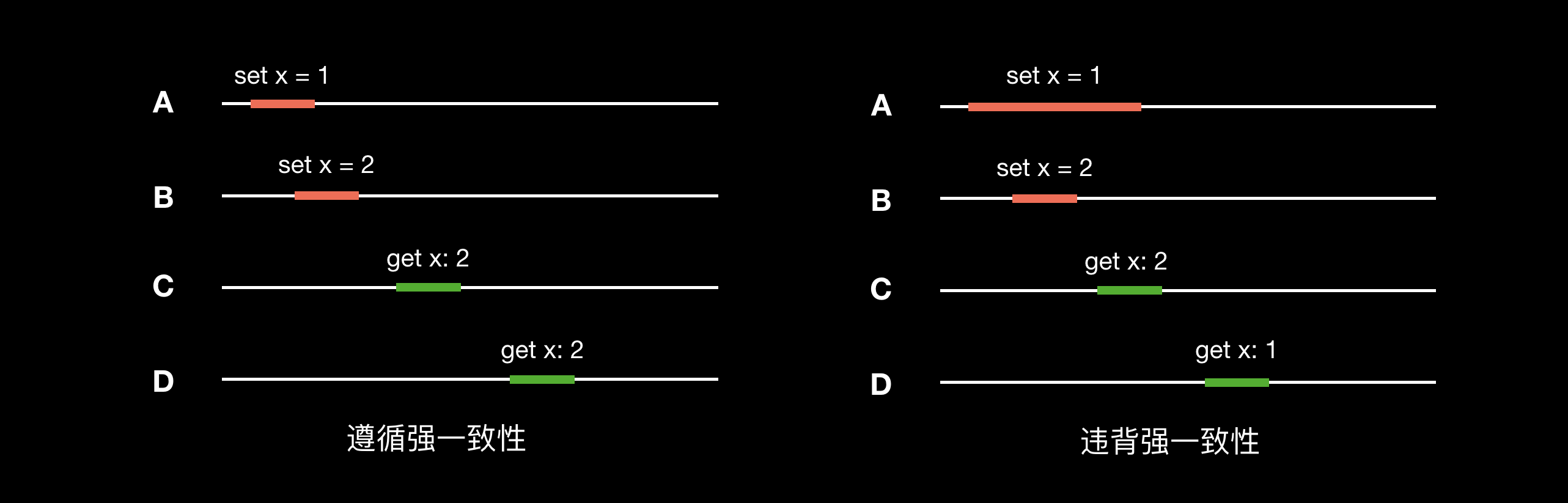
严格一致性(Strict Consistency)
严格一致性要求任何写操作都能即时同步到所有进程,任何读操作都能立刻读取到最新的修改。在分布式环境下目前无法实现。
-
线性一致性(Linearizable Consistency)
线性一致性也称为原子一致性。线性一致性保证所有的读写操作在一个单调递增的物理时间线上串行地向执行,任何读操作总能返回最新的修改。线性一致性也是目前生产环境下可以达到的最高的一致性等级,CAP 中的 C 即表示线性一致性。
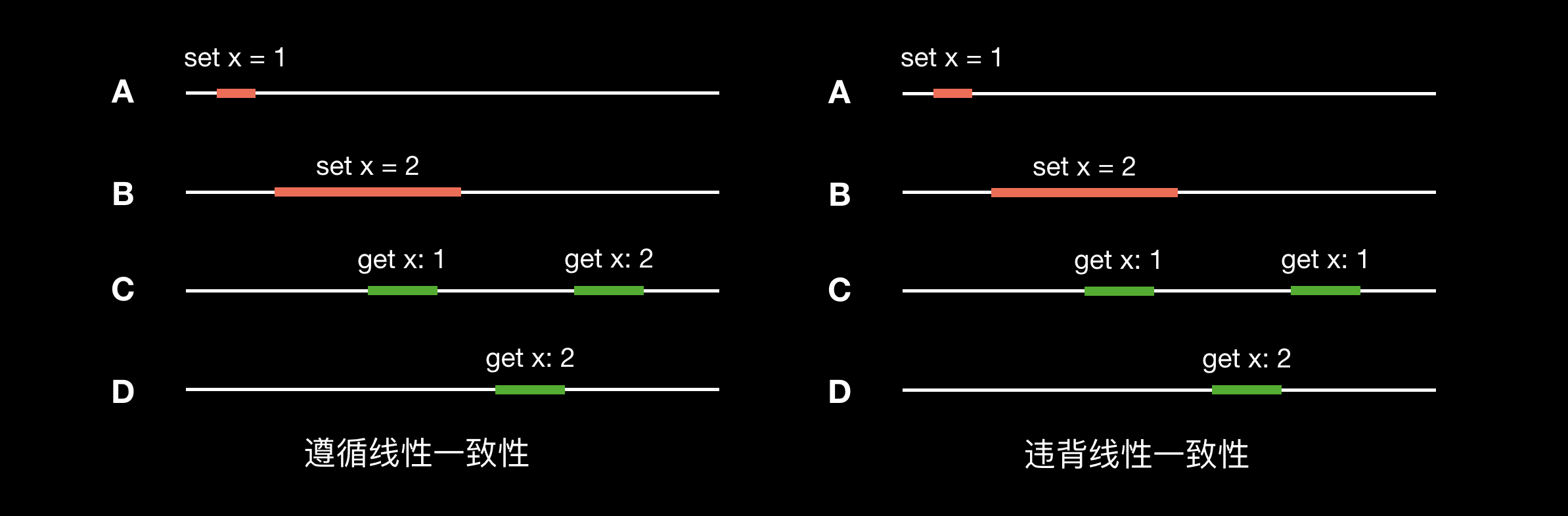
右图中,D 节点已经读取到 x 的最新值 2,C 节点的第二个读请求从物理时间上晚于 D 节点的读请求,因此应该读取的值也是 2 才不违背线性一致性。
-
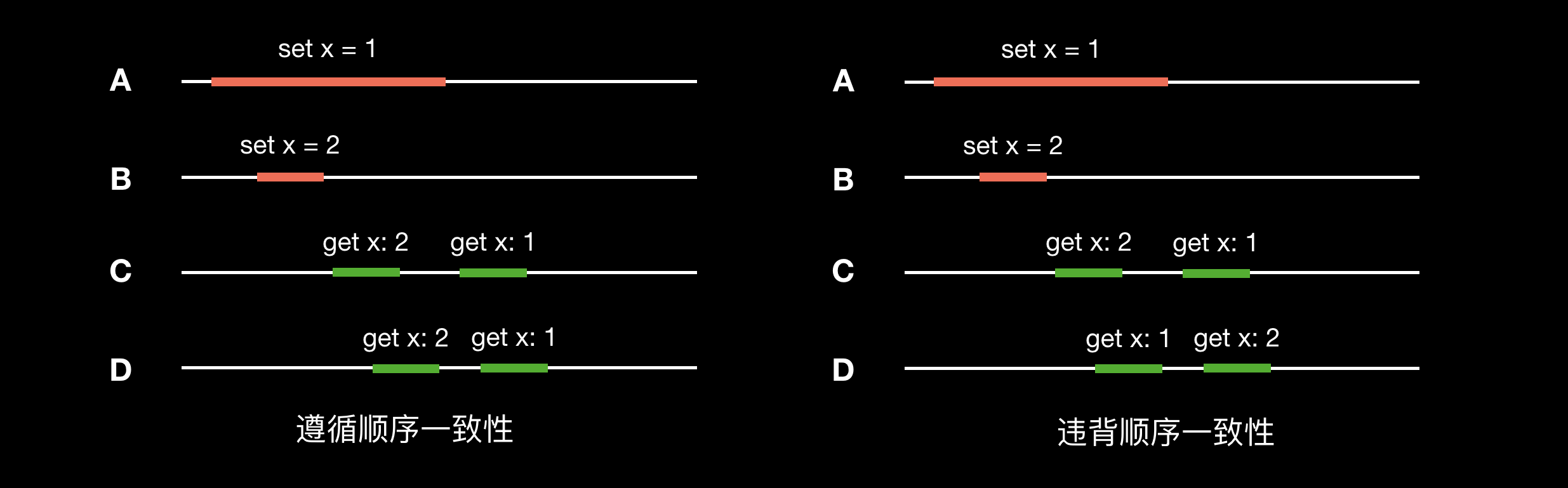
顺序一致性(Sequential Consistency)
顺序一致性是指所有的进程以相同的顺序看到所有写操作。读操作未必能及时读到最新的修改,但所有进程读到不同值的顺序是一致的。
-
因果一致性(Causal Consistency)
因果一致性是弱化的顺序一致性。不同进程可以以不同的顺序看到并发的写操作,但所有进程必须以相同的顺序看到具有潜在因果关系的写操作。因果关系即 Lamport 提出的 “happened-before” 关系(见 “Lamport 逻辑时钟” 小节)。
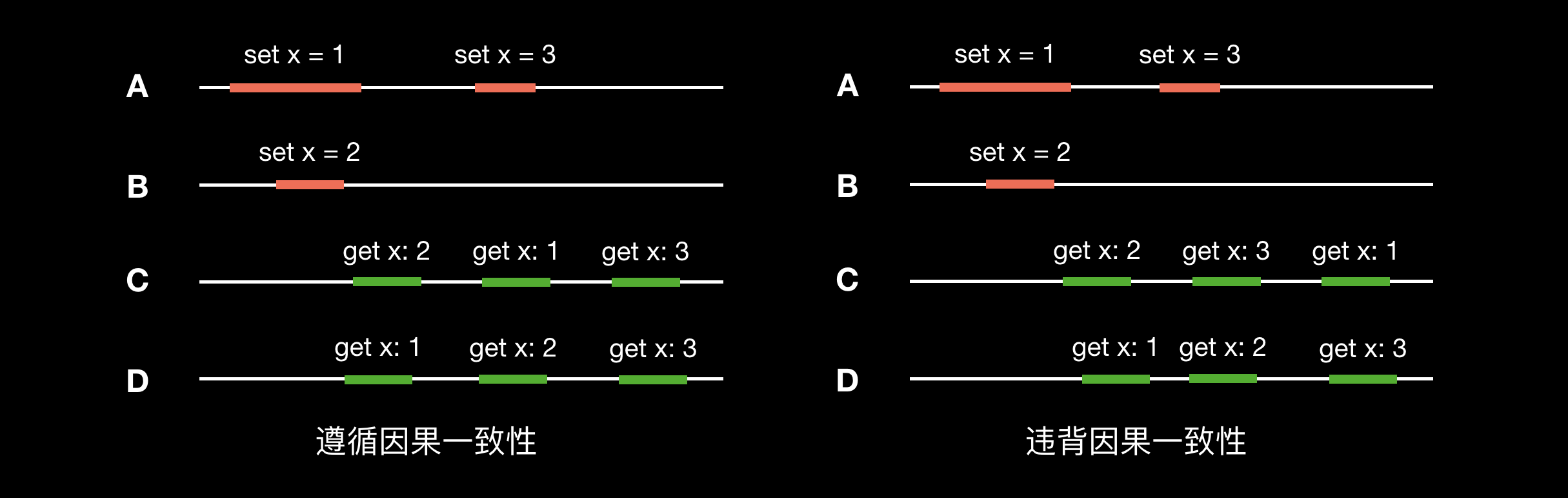
左图中,A 节点上事件 x = 3 发生在 x = 1 之后,C 和 D 节点观察到的顺序也是如此,因此遵循因果一致性。右图 C 节点事件 x = 1 发生在 x = 3 之后(可能发生了读回退),违背了因果关系,因此不遵循因果一致性。
有些业务并不要求所有节点数据一致,只要求基于单个用户满足一致性,即以客户为中心来归类:
- 单调读一致性 Monotonic read consistency
- 单调写一致性 Monotonic write consistency
- 写后读一致性 Read-your-writes consistency
- 读后写一致性 Writes-follows-reads consistency
业界通常按一致性的强弱程度划分三类:
- 弱一致性:After a write, reads may or may not see it
- 最终一致性:After a write, reads will eventually see it
- 强一致性:After a write, reads will always see it
参考文献:
Chain Replication
参考资料:
-
Chain Replication for Supporting High Throughput and Availability
-
Object Storage on CRAQ: High-throughput chain replication for read-mostly workloads
Conflict-free replicated datatypes
参考资料:
- A Comprehensive Study of Convergent and Commutative Replicated Data Types
- CRDTs: An UPDATE (or Maybe Just a PUT)
- A Bluffers Guide to CRDTs in Riak
- A Conflict-Free Replicated JSON Datatype
- CRDT for Data Consistency in Distributed Environment
Mergeable persistent data structures
参考资料:
Operational transformation
参考资料:
Version vector 和 vector clock
Version vector 有时也称为 vector clock,但两者并不是同个概念,关于两者的区别可以参阅:
- Dotted Version Vectors: Logical Clocks for Optimistic Replication
- Version Vectors are not Vector Clocks
- Detecting Causal Relationships in Distributed Computations:In Search of the Holy Grai
Version vector 用于发现冲突,crdt 用于解决冲突。