前言
这篇文章是《漫谈分布式》系列文章的第三篇,主要内容为分布式系统中划分数据的方式和分区的再平衡策略。
数据划分 Partitioning
上一篇文章《漫谈分布式:数据复制》 提到数据复制可以提高系统的可用性。但是当数据量过大,复制整个数据集显然不现实,此时需要将数据进行划分(partitioning),也称为 sharding。数据划分带来最大的好处是提高了系统的扩展性,将数据划分到不同的节点,请求因此可以分流到不同的节点中去,提高了整个系统的吞吐量。
数据划分一般会结合数据复制,每个节点既可能为某个分区的 leader,同时还可能是其他分区的 follower:
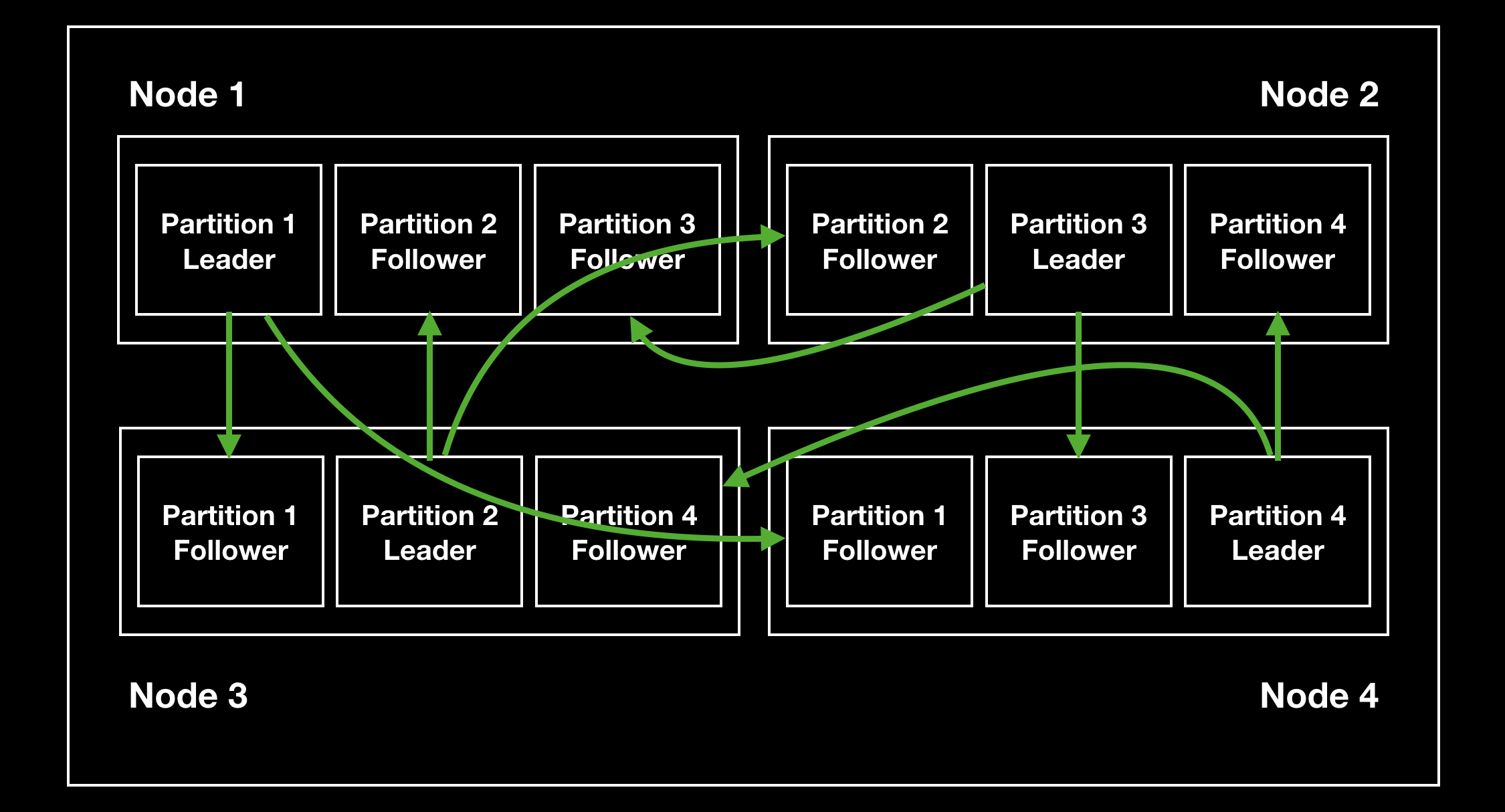
Key-Value 类数据的划分
针对 key-value 类型数据的划分,有按 key 值范围和对 key 做哈希的方式。
按 key 值范围划分
将 key 的取值范围区间按顺序切分成几个分区,类似字典的首字母索引:
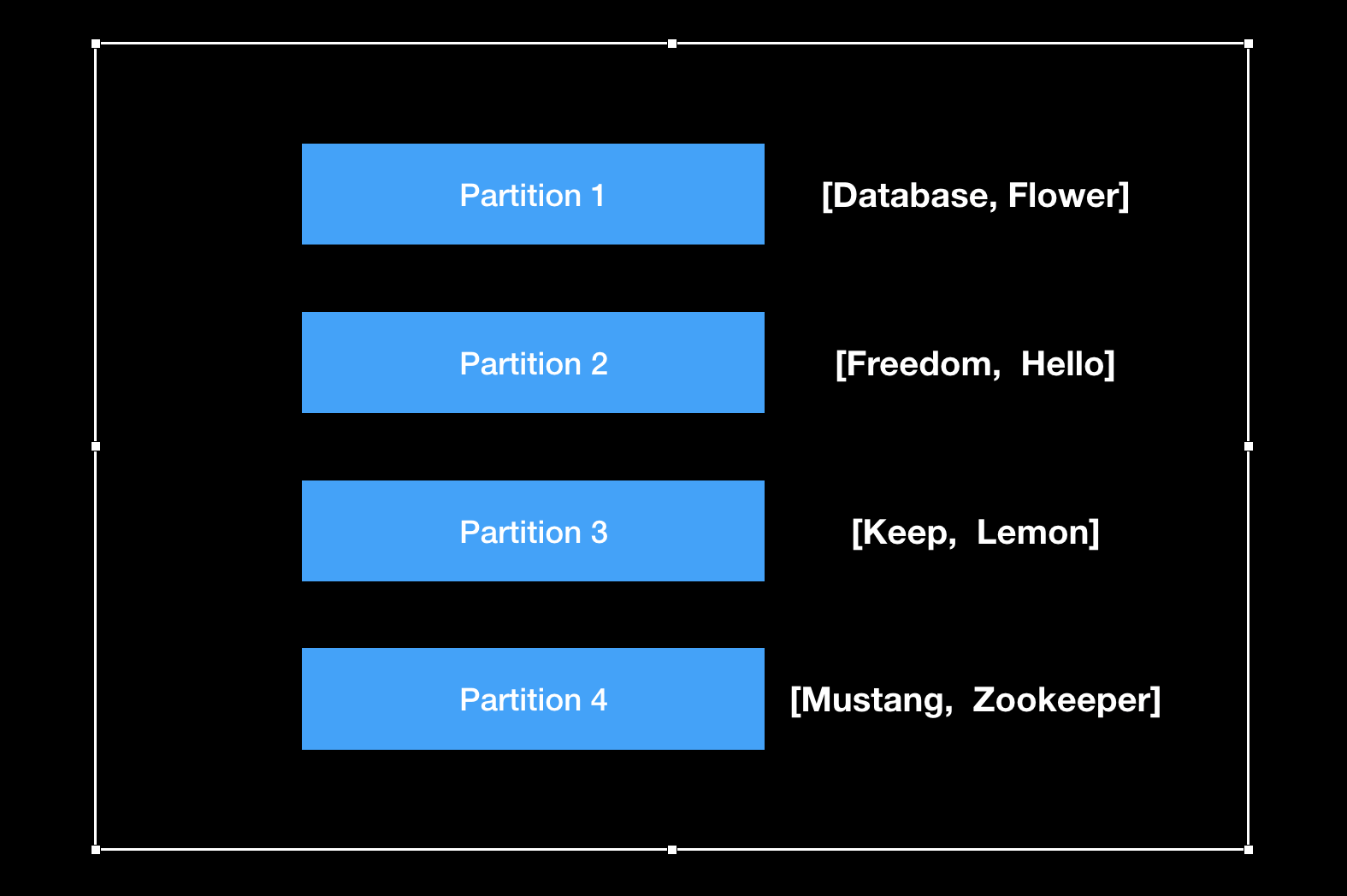
每个分区的区间范围可以是手动指定,或者由数据库自动调整。下文会讨论数据分区的再平衡策略。
按 key 的取值范围划分,需要谨慎选择所切分的 key 以避免造成数据热点,导致请求集中落到小部分数据分区中,失去数据划分的意义。
对 key 做哈希划分
选择合适的哈希函数对 key 进行哈希路由到不同的分区,这种方式可以使数据更均匀的分布:
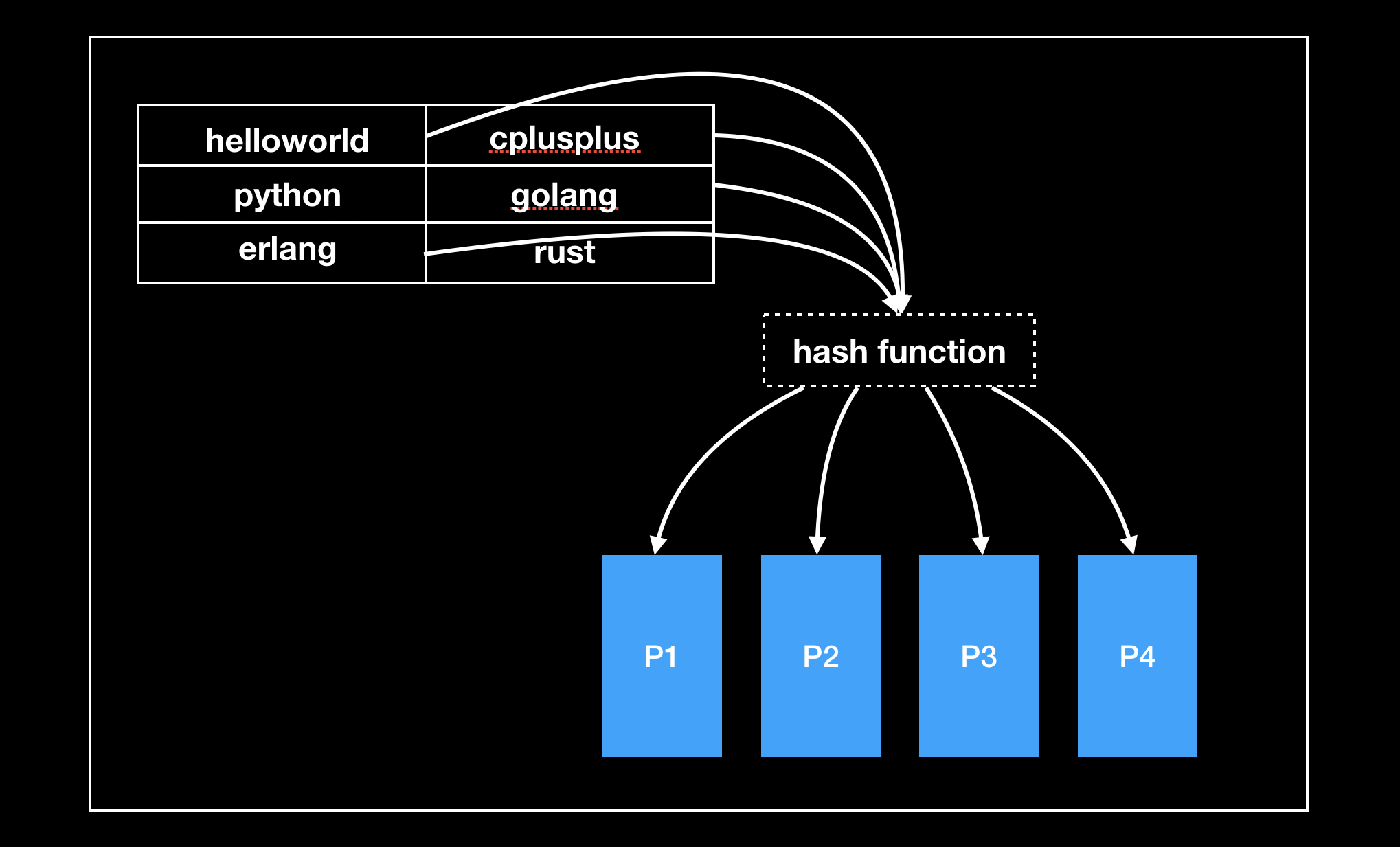
关于哈希函数,Cassandra 采用 Murmur3,MongoDB 使用 MD5,Voldemort 使用 Fowler–Noll–Vo。
使用哈希来做数据划分,在节点缩扩容时数据分布的规则会被打乱,需要做大量的数据迁移。而一致性哈希解决了这个问题,新增节点时,只影响一小部分数据区间的映射规则:
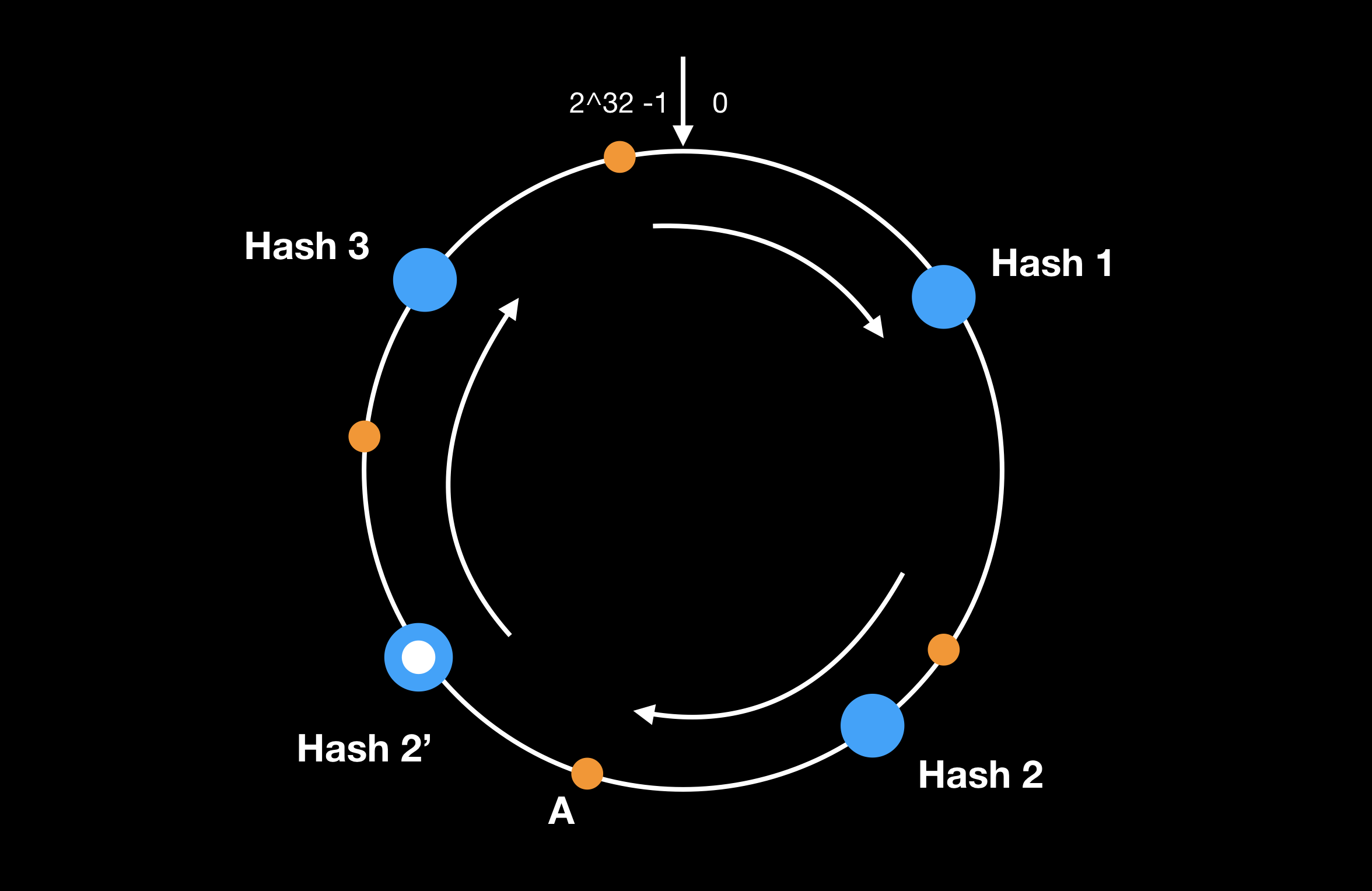
如上图,新增了节点 Hash 2’,则仅需要将位于 [Hash 2, Hash 2’] 这段区间的数据迁移到 Hash 2’ 节点上,其他数据无影响。
采用哈希的方式来切分数据最大的问题是范围查询会很低效,查询请求需要发给所有数据分区。MongoDB 就采取了哈希的方式,见New Hash-Based Sharding Feature in MongoDB 2.4。Cassandra 则采用了范围和哈希结合的方式。关于 cassandra 可以参阅论文 Cassandra – A Decentralized Structured Storage System 和 Facebook’s Cassandra paper, annotated and compared to Apache Cassandra 2.0。
热点问题
如果是某个 key 访问特别频繁,通过数据分区是无法解决的。常用的方案是在应用层为 key 拼上随机值,让数据分散到多个分区,以减轻对单个数据分区的访问压力。但随之带来的是读操作的额外开销,读请求需要发给多个数据分区然后由应用层对结果进行合并。
分区再平衡策略
静态分区
静态分区会提前定好分区数量(大于节点的数量)和分区的取值区间范围,每个节点分配一定数量的分区:
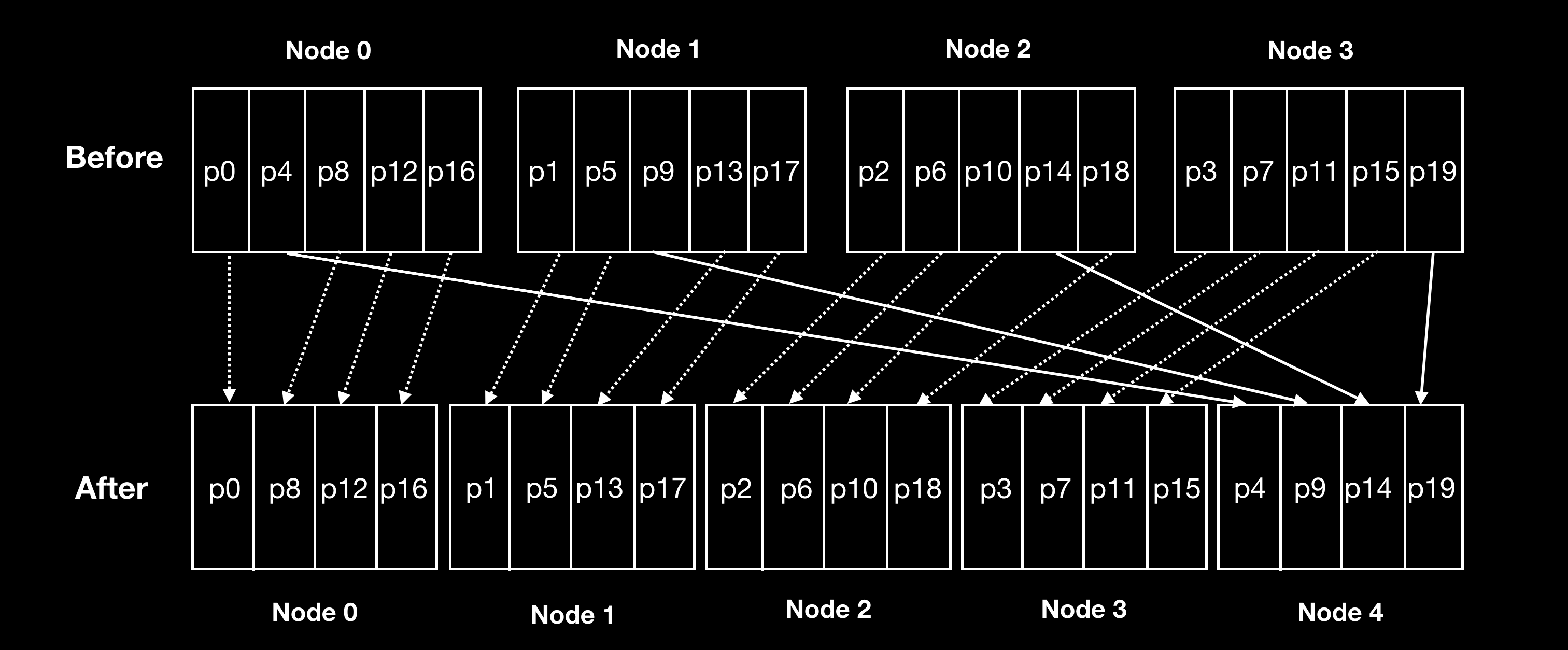
再平衡的过程中, key 到分区的映射规则无需修改(因为分区总数是固定的),唯一有变化的是分区和节点的映射关系。节点缩扩容时只需要迁移分区的数据到新节点上即可。Riak、Elasticsearch、Couchbase 和 Voldemort 都采用了这个方案。
静态分区策略下,分区总数是固定的。因此制定分区的总数目变得非常有挑战,需要预估整个数据库的数据总量。如果分区总数目太少,导致分区存储的数据量过大,数据迁移就会很耗时。另一方面,如果分区数目过多,则每次节点缩扩容时需要迁移大量的分区。
动态分区
静态分区方案由于分区的数量和区间范围都是预先定好的无法动态修改,容易造成分区数据不均匀的问题,尤其是按 key 范围来划分数据的时候(哈希的方式会比较均衡)。因此采用按 key 范围做切分的数据库,例如 HBase、RethinkDB 采用的是动态分区的方案,在分区数据量超过一定阈值时,切分成两个分区。如果分区数据量低于一定阈值,将和相邻的分区进行合并。可以参考 Apache HBase Region Splitting and Merging
按节点分区
第三种策略,每个节点的分区数量是固定的。假设每个节点预设的分区数量为 N,节点扩容时将随机挑选 N 个分区进行分裂,分裂一半数据迁移到新扩容的节点中。Cassandra 就采用了该策略,可以参阅论文 Rethinking Topology in Cassandra。