背景
在游戏后台中,路由是一个比较重要的模块。路由作为中间层,可以解耦服务调用方和服务响应方:
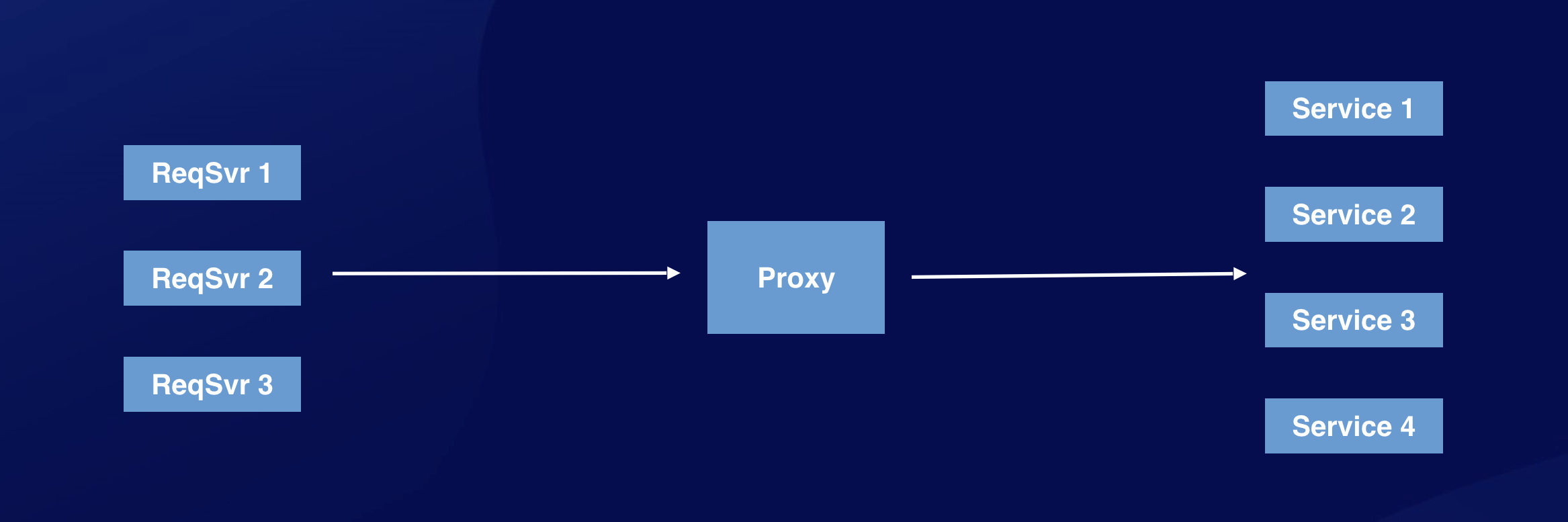
常见的路由方式包括随机、轮询、一致性哈希、取模、主(备)等,同时还可以在路由层实现负载均衡的能力。以战斗服为例,后台架构通常如下:
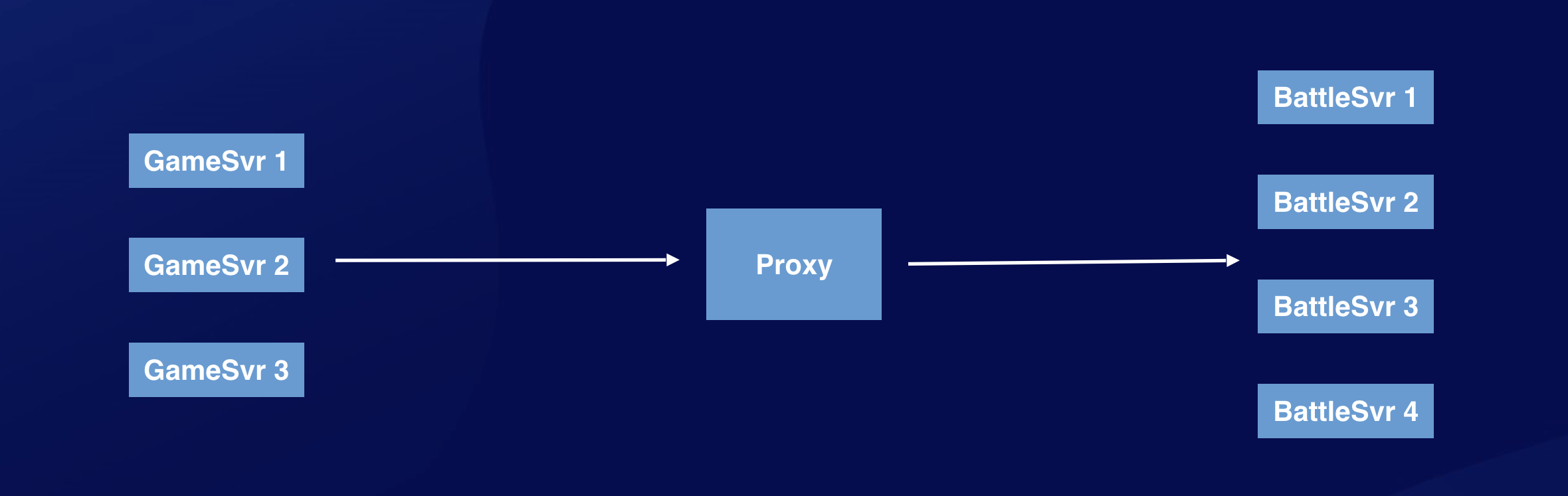
因为 BattleSvr 是带状态的。通常我们会将房间 Id 做为 key 值,采用一致性哈希的方式路由,保证同一个房间 Id 的消息始终路由到同一台 BattleSvr 上。
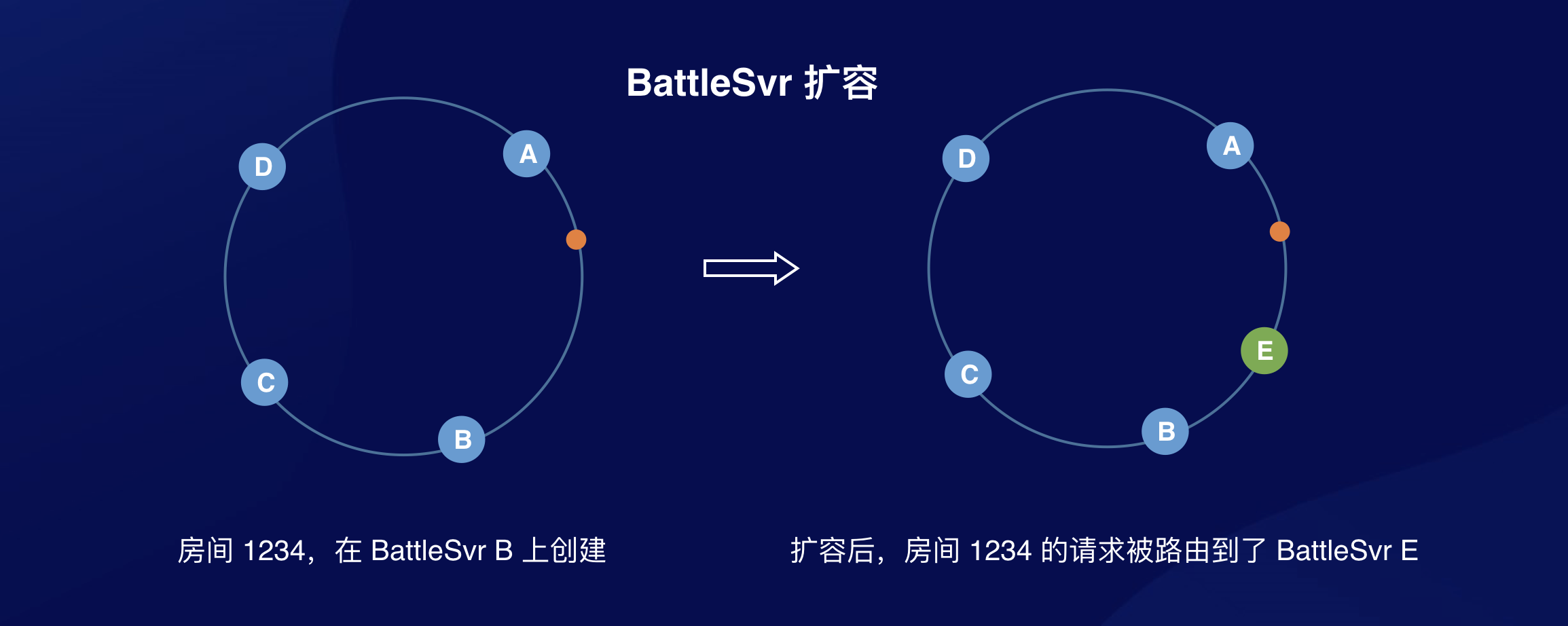
听起来完全没有问题,实现上也很简单。但如果游戏上线后非常火爆,BattleSvr 需要扩容,会发生什么?
如果 BattleSvr 扩容了的话,会有一部分房间的消息被路由到新加入的 BattleSvr 上:
针对这个场景,比较常见的解决方案是把房间的路由管理交给一个专门的 BattleMgr 服务去管理,由 BattleMgr 去维护映射关系:
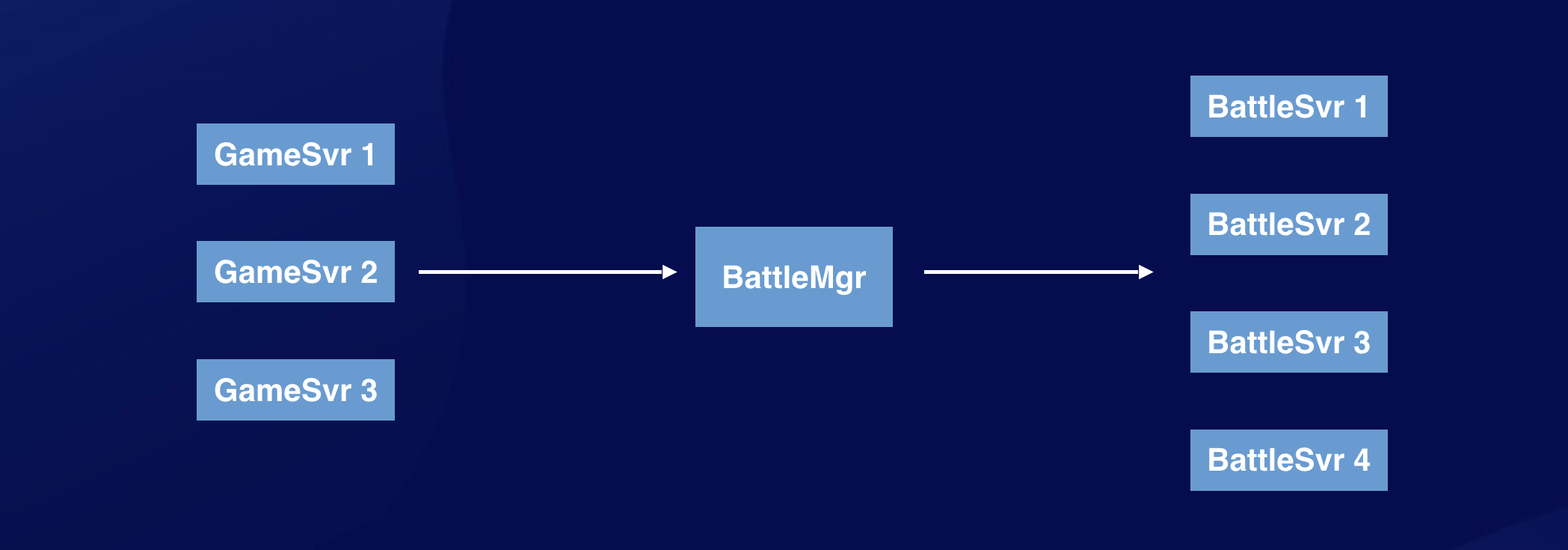
这样的缺点是不够通用,比如我有新的需求,需要加一个聊天室模块,也需要再专门部署一套聊天房间的 Mgr 进行管理。
是否可以抽出一个通用的路由层来实现这样的功能呢?
通用 Proxy 的接口
通用 Proxy,在后端服务缩扩容时,应该具备下面两个能力:
- 已有的路由关系维持不变
- 新的路由请求可以分流到新的后端服务
Proxy 作为中间层,不关心后端服务的具体逻辑,只能通过不同的接口来区分“新“和“已有“的路由请求。
因此,路由层应该提供两个接口:
- CreateRouteByHashId:根据 HashId,从后端 Service 中根据策略选择其中一个节点进行路由
- RouteByHashId:根据已有的路由关系进行路由
为满足第一个能力,HashId 到后端服务的路由映射,需要持久化到路由 DB。
挑战和难点
高性能:为了提高 Proxy 的性能,同时减轻对路由 DB 的压力,Proxy 需要在内存里对路由映射关系做缓存。命中缓存时直接路由消息,无需到路由 DB 查找。
高可用:为了保证 Proxy 的可用性和高性能,Proxy 由一组 ProxySvr 构成。
从本质上说,Proxy 就像是一层分布式缓存:
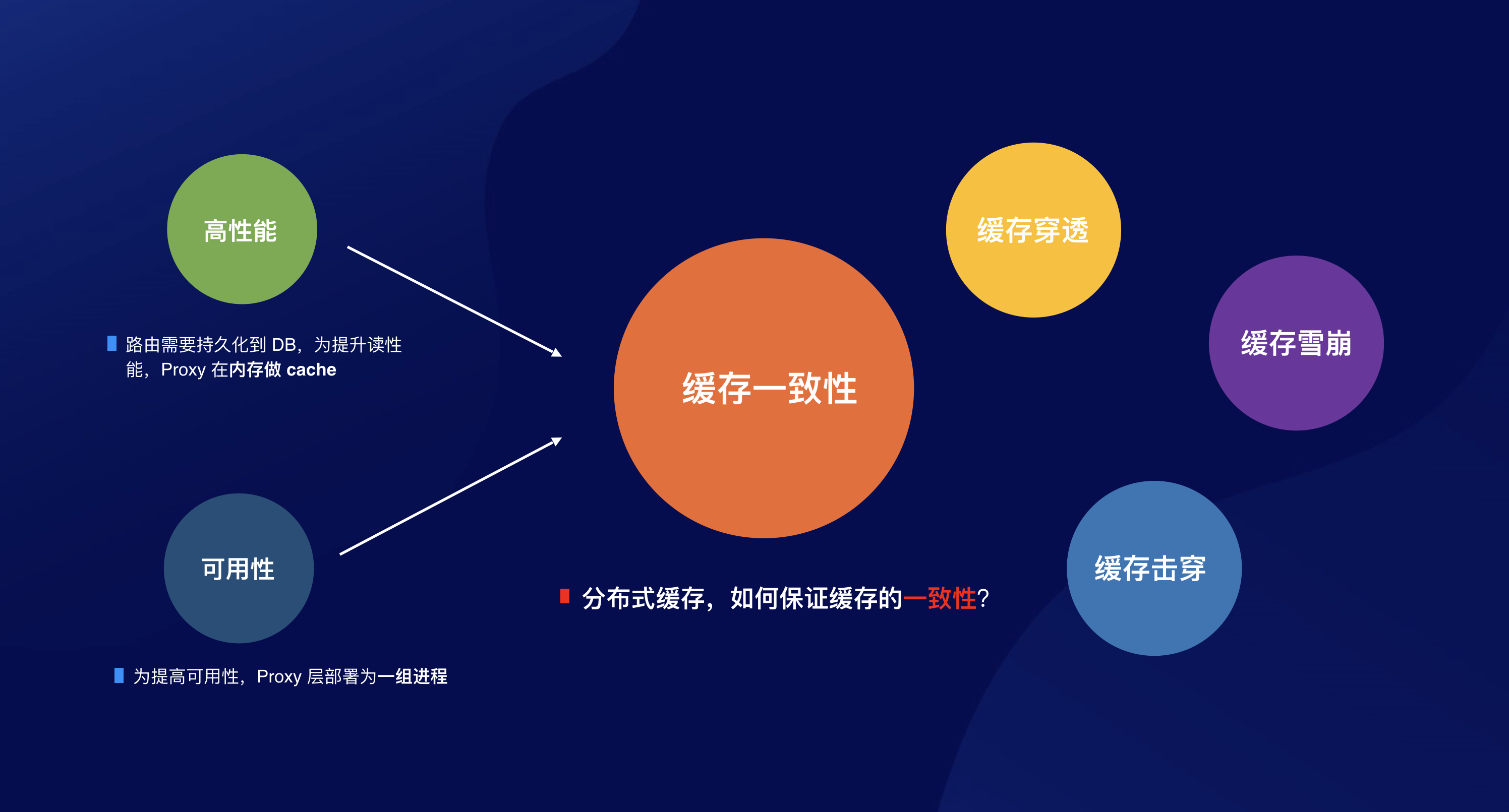
那么问题来了,如何保证分布式缓存的一致性?考虑下面场景:
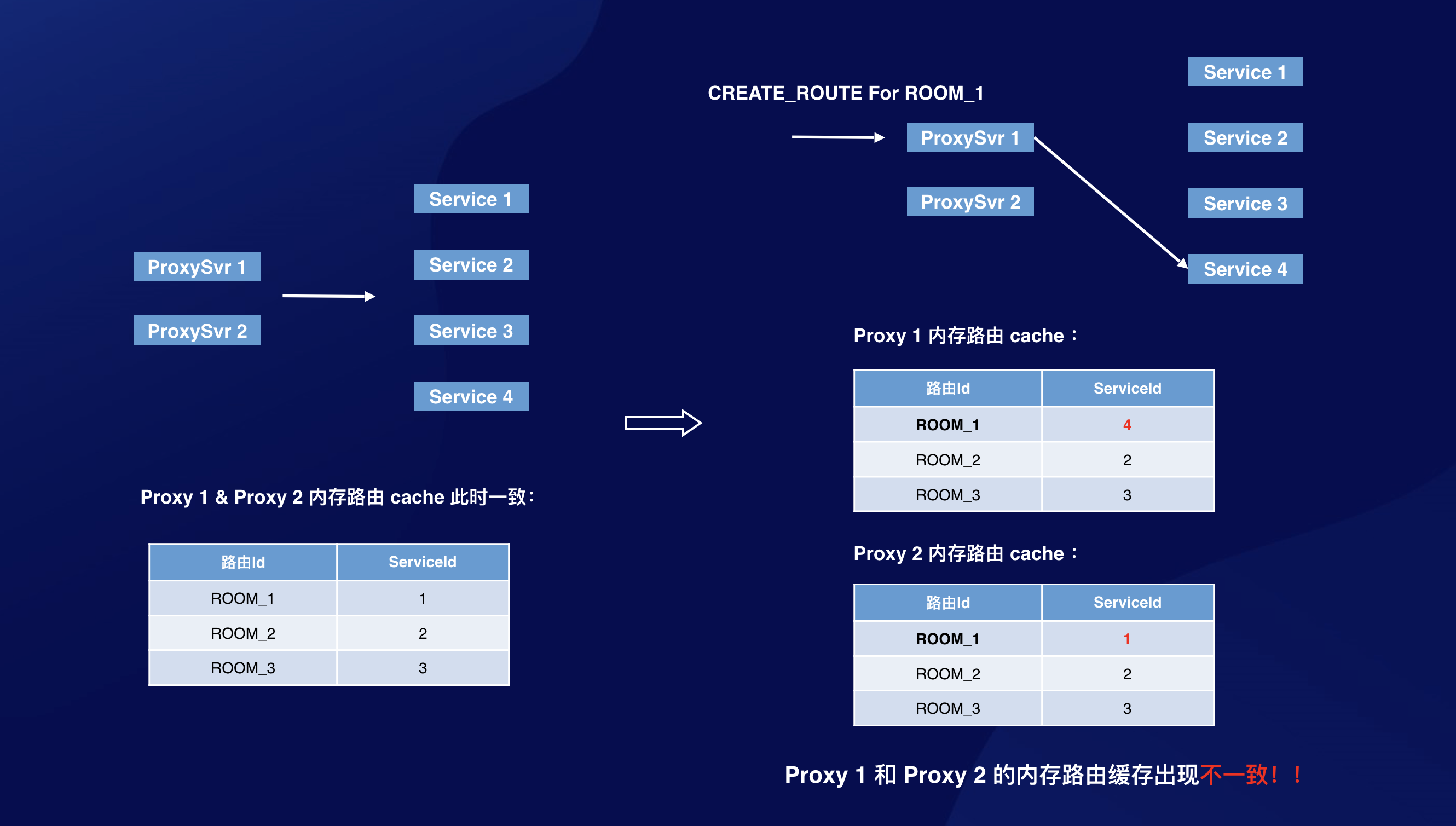
Proxy 1 和 Proxy 2 的路由缓存出现了不一致!Proxy 2 对 ROOM_1 的路由缓存已经失效。
针对这个问题,脑海里浮现的第一个方案是,创建的时候,我广播一下,通知其他 ProxySvr,这个 HashId 的路由映射失效了(为什么这里是通知路由失效,而不是广播新路由?因为我有可能持久化到路由 DB 时返回失败):
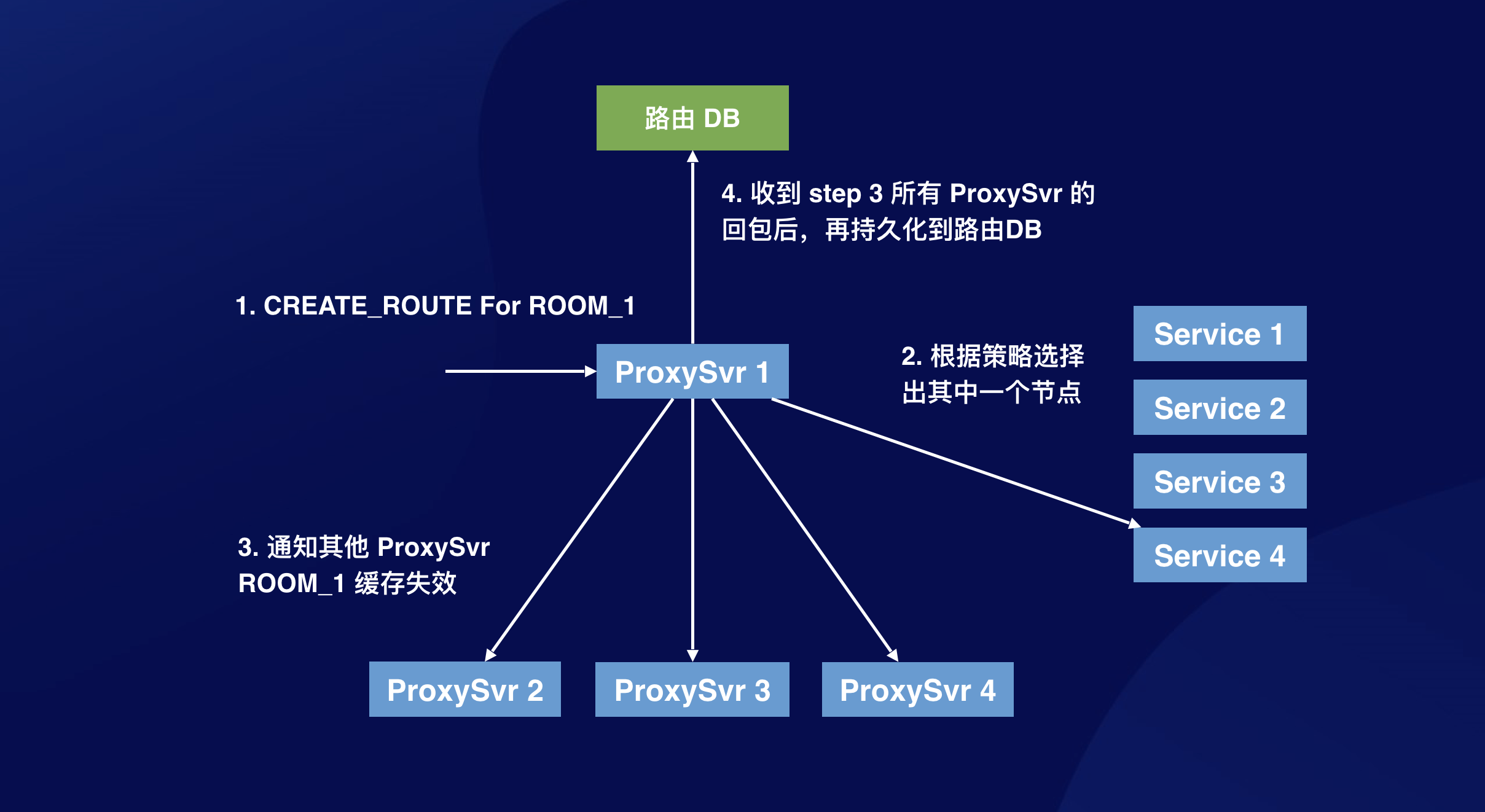
这个方法足够简单,也能解决问题。但存在什么缺陷呢?首先,CreateRouteByHash 增加了一轮 RTT(上图中的第三步),并且这个步骤是关键路径。如果通知消息丢失了或者某台 ProxySvr 没有回包,为了保证一致性,CreateRouteByHash 请求只能不处理,返回失败。这意味着 Proxy 的可用性鲁棒性降低了。另外,这个方案还有一个致命问题,step 3 和 step 4 存在时间差,如果 step 3 后 step 4 前有查询请求,又会把 step 3 中通知失效的路由缓存重新加回去。
这个方案走不通,那我同一个 HashId 始终发给同一台 ProxySvr(比如采用一致性哈希的路由方式),不就解决了吗?虽然是分布式的,但每个 ProxySvr 处理的 HashId 号段互相独立,也就从根本上规避了不一致的问题:
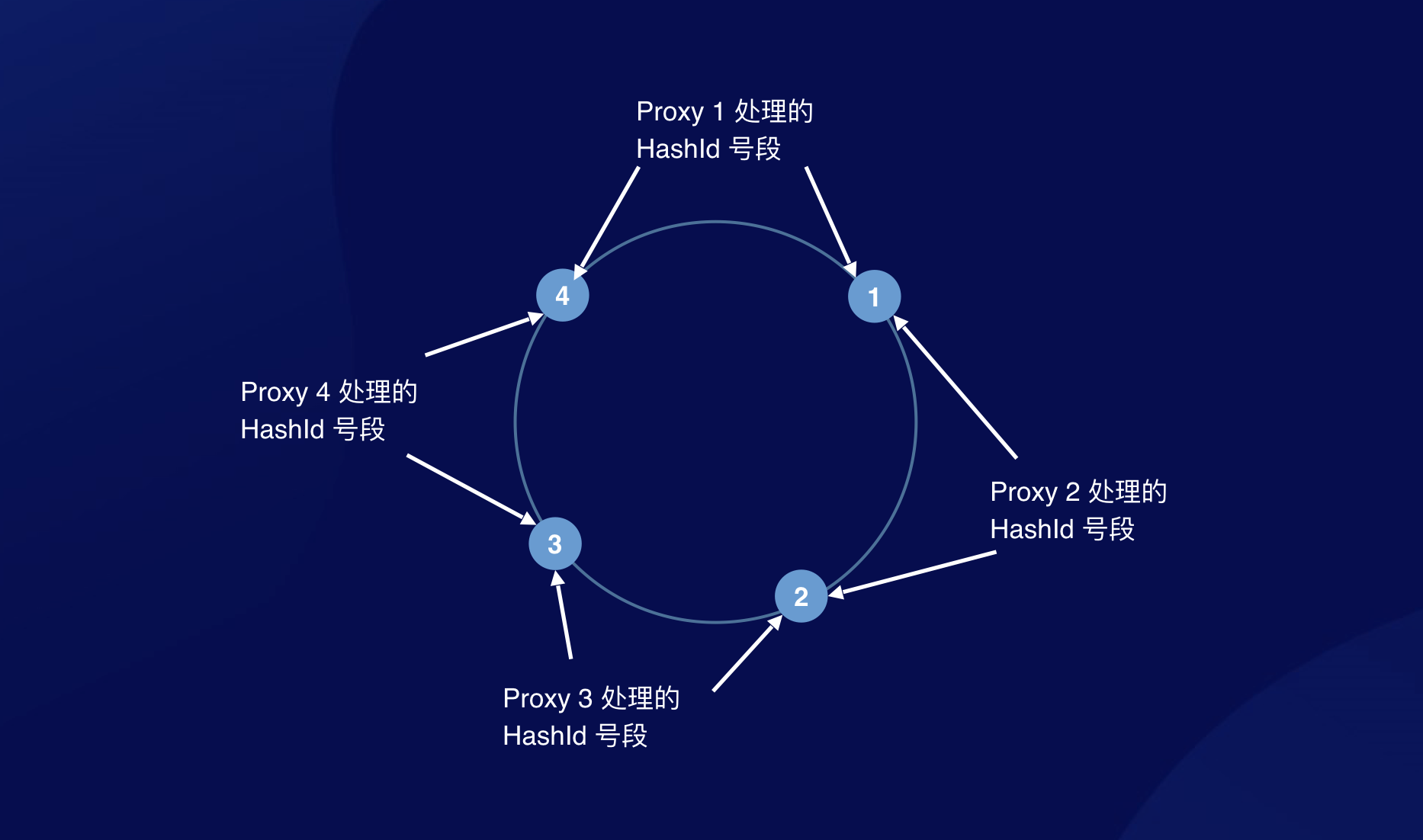
这个方案听起来好像没什么问题。但是,万一,Proxy 自己也需要扩容呢?
先分析下缩扩容是否会引起问题:
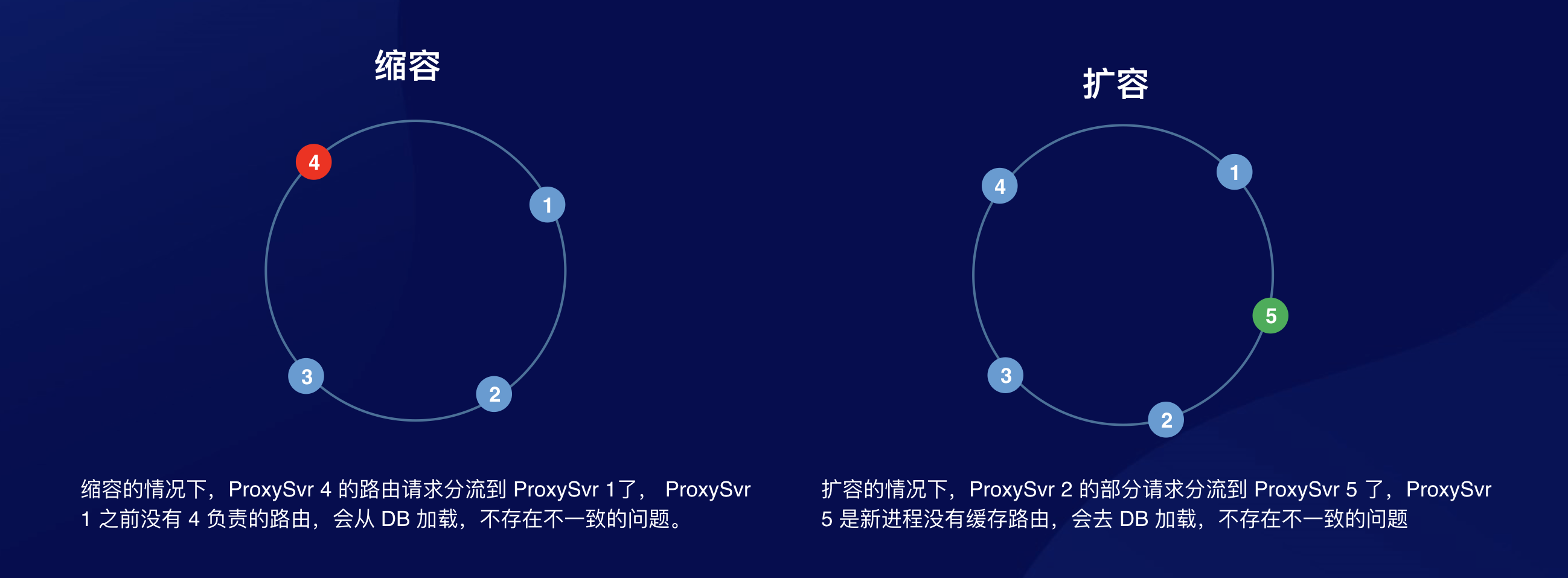
看起来万事大吉,但实际上…
分布式系统下的不确定性
分布式系统下,网络延时不可控,消息传输不可靠,考虑下面场景:
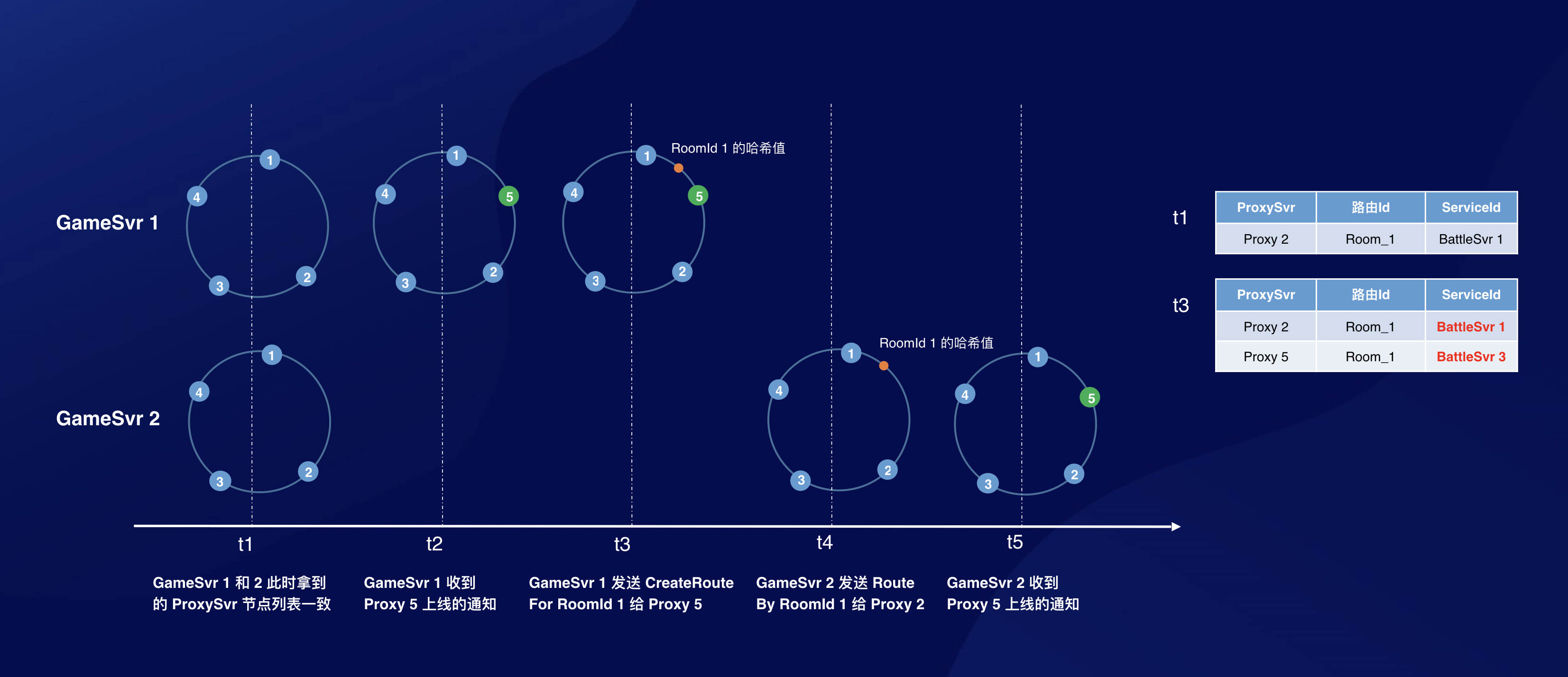
此时 Proxy 2 和 Proxy 5 的路由缓存出现了不一致。问题的本质在于,路由请求的分发策略和 Proxy 节点列表信息强相关,由于网络存在延迟,传输不可靠。每个节点收到消息存在时间差。在 Proxy 节点发生变化(缩扩容)期间,存在中间状态,此期间各个节点拿到的 Proxy 节点列表可能不一致,导致同一个 HashId 的路由请求可能分发到不同的 ProxySvr 上。
一致性算法和二阶段提交
一致性算法,比如 Raft,提供了 Membership Change 的机制,但在这个场景下,并不适用。在 Proxy 缩扩容时,我们并不希望把服务调用方(例如上图中的 GameSvr)牵扯进来。
二阶段提交则是另一个解决分布式系统下一致性问题的算法。
我们再次分析下问题的本质:
-
为保证 Proxy 路由缓存的一致性,我们采用的做法是让各个 ProxySvr 处理的 HashId 互不重复。实现的方法是通过一致性哈希的方式(取模不建议,后面会说明),确保相同的 HashId 只会分发给同一个 ProxySvr。
- 实现 1 的前提是,请求方拿到的 ProxySvr 节点列表信息是一致的。如果有部分 GameSvr 拿到的 ProxySvr 节点信息列表不一致,就可能导致同一个 HashId 被分发给不同的 ProxySvr(见“分布式系统下的不确定性”小节中的示例图)。
- 如果 ProxySvr 缩扩容,所有节点需要“同一时刻“更新 ProxySvr 的节点列表信息。
- 但由于分布式网络存在延迟和不可靠,“同一时刻”是不可能实现的,系统中势必存在新老状态并存的时期。既然这个中间状态无法避免,就需要保证在中间状态时,系统不出错。
于是我们的标准就从“同时” 降低为 “中间状态不出错“。
如何实现中间状态不出错?首先我们希望把请求方解耦,允许请求方出错:
- 如果 ProxySvr 收到不归自己管理的 hashId 的路由请求,需要转发给对应的 ProxySvr
另外我们想办法让 ProxySvr 在中间状态时保证一致性:
- 中间状态时,不走缓存,每次都从路由 DB 去查询路由关系
于是可以把缩扩容的流程简单分为三个步骤:
- 通知各个 ProxySvr 进入中间状态。
- 确认各个 ProxySvr 已经进入中间状态,开始更新 ProxySvr 节点列表信息(中间状态都走 DB,节点信息更新的先后顺序不会影响缓存一致性)。
- 确认各个 ProxySvr 节点信息已经更新,通知变更完成,结束中间状态。
三阶段 Rehash
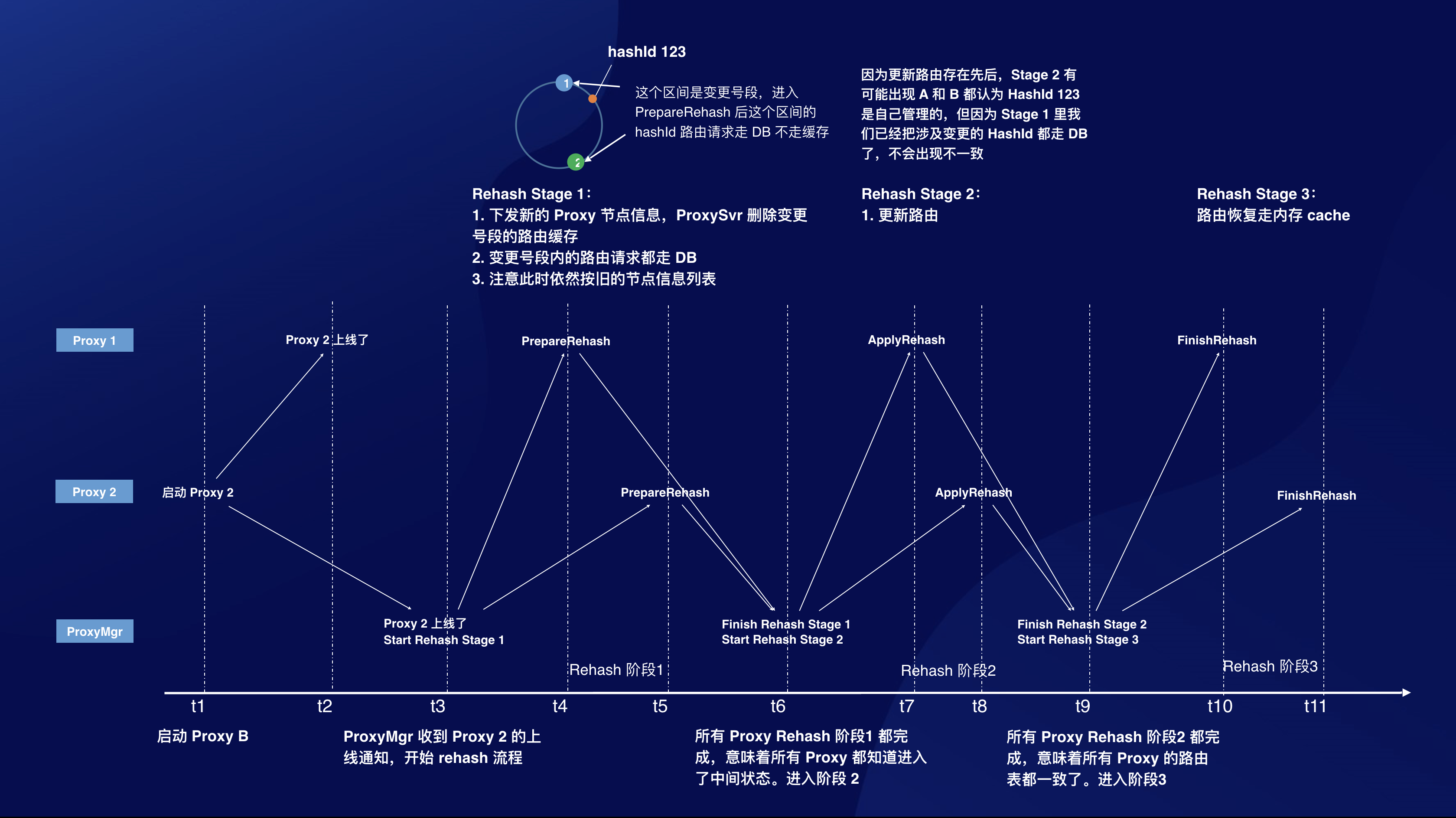
我将这个流程命名为“三阶段 Rehash”,详细的流程如下:
- 通知 ProxySvr 准备更新节点列表,下发最新的节点列表。此时 ProxySvr 根据最新的节点列表和当前节点列表,计算出变更号段,变更号段内的路由请求,不读缓存,每次都查路由 DB(进入中间状态)。
- 等待所有 ProxySvr 都确认已经进入中间状态。
- 通知 ProxySvr 更新 Proxy 节点信息列表,此时按新的节点信息列表处理路由请求,不归自己管的进行转发,变更号段内的依然走 DB 不走缓存。
- 等待所有 ProxySvr 都确认已经更新节点信息列表。
- 通知 ProxySvr 节点信息列表更新完成。ProxySvr 收到通知后,路由请求恢复走内存缓存的方式(结束中间状态)。
这就是一个三阶段 Rehash 的算法,和二阶段提交类似,我们需要引入一个协调者(下图中的 ProxyMgr),来完成三阶段 Rehash。详细流程图如下:
细节和优化
实现上还有些细节需要注意:
-
收到 Proxy 节点信息更新时,需要删掉待变更号段内的路由缓存。为什么?考虑如下场景:
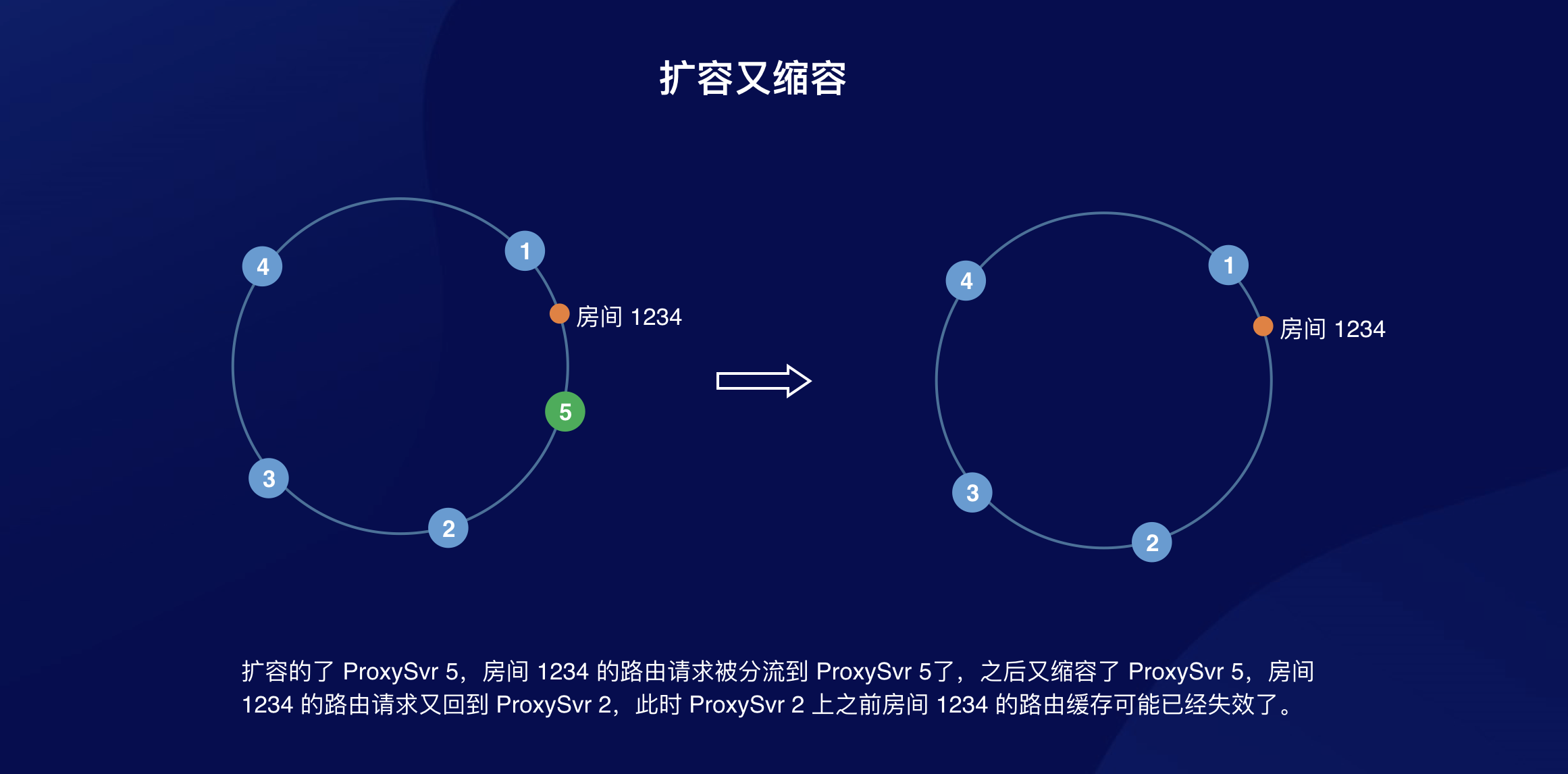 因此在 Proxy 节点更新的时候,需要把已经不归自己管理的 Hash 号段清理掉。
因此在 Proxy 节点更新的时候,需要把已经不归自己管理的 Hash 号段清理掉。 -
如何高效清理?
最粗暴的方法是遍历所有缓存的路由信息。效率更高的做法可以采用惰性删除法,缓存已经失效的号段,从缓存读的时候发现该 hashId 所属的号段已经失效,则去 DB 查询。采用这个方案,随着扩容缩扩容,失效号段缓存会不会越积越多呢?也不会,Proxy 的路由缓存只缓存 5分钟,失效号段也只需要缓存 5 分钟即可。
上面我有提到不建议采用取模的方式,也是因为这里,一致性哈希的方式可以缓存失效号段,取模的方式就做不到了。
有状态到无状态
至此,文章中描述了如何搭建高可用保证一致性的分布式路由层,目前来看,这套方案最大的缺点在于路由层是有状态的,请求方需要拿到 Proxy 的节点列表信息,同样用 HashId 以一致性哈希的方式去发送请求,这给我们的系统带来了一些耦合。虽然在我们自己项目中实现很方便,但如果提供给外部的使用方,就不太现实了。
实际上,我们的路由层对外可以是无状态的,前面分析的时候已经提过,我们允许请求方出错。ProxySvr 收到不归自己管理的 hashId 的路由请求,会转发给对应的 ProxySvr。因此业务方可以随机发给任意 ProxySvr,ProxySvr 返回给业务这个 HashId 对应的 ProxySvr 地址,业务方可以在本地缓存这个映射关系。这样的话,整套方案对于使用方来说就是无状态的了。